Amazon Web Services 한국 블로그
Amazon SageMaker RL – 강화 학습 서비스 출시 (서울 리전 포함)
지난 몇 년간 기계 학습(Machine Learning)은 많은 관심을 받아왔으며, 의료 영상 분석부터 무인 주행 트럭까지 ML 모델을 통해 할 수 있는 복잡한 작업의 목록은 꾸준히 증가하고 있습니다. 이러한 최근 기계학습 기술은 어떤 방법이 있을까요?
간단히 말해 다음과 같은 3가지 방법으로 모델을 훈련할 수 있습니다.
- 지도 학습(Supervised Learning): 레이블이 지정된 데이터 세트(샘플 및 답변이 포함된 데이터 세트)에서 알고리즘을 실행합니다. 모델은 정답을 올바르게 예측하는 방법을 서서히 학습하게 됩니다. 지도 학습의 예로는 회귀와 분류가 있습니다.
- 비지도 학습(Unsupervised Learning): 레이블이 지정되지 않은 데이터 세트(샘플만 포함된 데이터 세트)에서 알고리즘을 실행합니다. 비지도 학습에서 모델은 데이터의 패턴을 지속적으로 학습하고 그에 따라 샘플을 구성합니다. 비지도 학습의 예로는 클러스터링 및 주제 모델링이 있습니다.
- 강화 학습(Reinforcement Learning): 이 방법은 앞의 두 가지 방식과는 많이 다릅니다. 강화 학습에서는 컴퓨터 프로그램(에이전트라고 함)이 환경과 상호 작용합니다. 대부분 이 상호 작용은 시뮬레이터에서 일어납니다. 에이전트는 수행한 행동에 대해 긍정적이거나 부정적인 보상을 받습니다. 보상은 장려되는 행동의 숫자 표현을 출력하는 사용자 정의 함수로 계산됩니다. 에이전트는 긍정 보상을 최대화하려고 함으로써 의사 결정에 대한 최적의 전략을 학습합니다.
AWS re:Invent 2017에서 출시된 Amazon SageMaker는 ML 모델을 빠르게 구축하고 훈련하고 배포하는 데 도움이 됩니다. 오늘 출시되는 Amazon SageMaker RL은 Amazon SageMaker의 장점을 강화 학습으로 확대하여 모든 개발자 및 데이터 과학자가 ML에 대한 전문 지식 없이도 강화 학습을 손쉽게 활용할 수 있게 되었습니다.
강화 학습에 대한 기본 정보
RL(Reinforcement Learning: 강화 학습)을 처음부터 이해하기는 쉽지 않을 수 있으니 한 가지 예를 들어 설명하도록 하겠습니다. 여기 미로 탐색을 학습하는 에이전트가 있습니다. 시뮬레이터는 에이전트가 특정 방향으로 이동하는 것을 허용하지만 벽을 통과하는 것은 차단합니다. 에이전트는 RL을 사용하여 정책을 학습하고 점점 더 관련된 행동을 취하기 시작합니다.
RL 모델은 경우 레이블이 지정된 미로의 미리 정의된 세트(지도 학습에서 사용됨)에서 훈련되지 않습니다. 대신 에이전트는 환경(현재 미로)을 한 번에 한 단계씩 검색하고, 한 단계를 더 이동하여 보상을 받습니다. 막다른 길에 다다르면 부정 보상이 제공되고 출구에 한 단계 더 가까워지면 긍정 보상이 제공됩니다. 다수의 서로 다른 미로가 처리되면 에이전트가 행동/보상 데이터 요소를 학습하고 다음 번에 더 나은 의사 결정을 내리도록 모델을 훈련합니다. RL의 핵심은 이 탐색 및 훈련 주기입니다. 충분한 미로와 충분한 훈련 시간을 제공하면 모든 미로를 탐색하는 방법을 충분히 빠르게 파악할 수 있습니다.
RL은 복잡하고 예측 불가능한 환경에 특히 적합합니다. 이러한 환경은 시뮬레이션이 가능하지만 사전 데이터 세트를 구축하는 게 현실적으로 불가능하거나 엄청나게 높은 비용이 소요될 수 있습니다. 자율 차량, 게임, 포트폴리오 관리, 재고 관리, 로보틱스 또는 산업용 제어 시스템이 여기에 포함될 수 있습니다. 예를 들어 RL 기반 제어를 HVAC 시스템에 적용하면 일반적인 규칙 기반 시스템[1]에 비해 20~40%의 비용을 절감할 수 있다는 연구 결과가 있습니다. 당연히 에너지 절약을 통한 환경보호에도 크게 기여 할 수 있습니다.
Amazon SageMaker RL 소개
Amazon SageMaker RL은 Amazon SageMaker를 기반으로 구축되며 사전 패키징된 RL 도구 키트가 추가되고 모든 시뮬레이션 환경과 손쉽게 통합됩니다. 여러분의 기대대로 훈련 및 예측에 사용되는 인프라가 AWS에 의해 완벽하게 관리되므로 서버 관리 대신 RL 문제에 전적으로 집중할 수 있습니다.
오늘부터 SageMaker가 제공하는 컨테이너를 Open AI Gym, 인텔 Coach 및 Berkeley Ray RLLib를 포함하는 Apache MXNet 및 Tensorflow에 사용할 수 있습니다. Amazon SageMaker와 마찬가지로 다른 RL 라이브러리(예: TensorForce 또는 StableBaselines)를 사용하여 자체 사용자 지정 환경을 손쉽게 생성할 수 있습니다.
시뮬레이션 환경의 경우 Amazon SageMaker RL은 다음 옵션을 지원합니다.
- AWS RoboMaker 및 Amazon Sumerian에 대한 제1의 시뮬레이터
- Roboschool 또는 EnergyPlus 같은 Gym 인터페이스를 사용하여 개발된 Open AI Gym 환경 및 오픈 소스 시뮬레이션 환경
- Gym 인터페이스를 사용하여 고객이 개발한 시뮬레이션 환경
- MATLAB 및 Simulink 같은 상용 시뮬레이터(고객이 자체 라이선스를 관리해야 함)
Amazon SageMaker RL에는 Amazon SageMaker와 마찬가지로 Jupyter Notebook이 포함됩니다. Github에는 로보틱스, 운영 과학, 재무 등의 다양한 영역에 대한 단순 예제(cartpole, simple corridor)와 고급 예제가 공개되어 있습니다. 이러한 노트북을 손쉽게 확장하고 고유한 비즈니스 문제에 맞게 사용자 지정할 수 있습니다.
또한 같은 유형 또는 다른 유형의 조정을 사용하여 RL을 조정하는 방법을 보여주는 예제를 확인할 수도 있습니다. CPU에서 시뮬레이션을 실행하고 GPU에서 훈련하는 RL 애플리케이션이 많기 때문에 다른 유형의 조정 방법이 특히 중요합니다. 다른 네트워크에서 로컬 또는 원격으로 시뮬레이션 환경을 실행할 수도 있으며 필요한 모든 설정은 SageMaker가 수행합니다.
보기보다 쉬우니 걱정할 필요가 없습니다. 예제를 살펴보겠습니다.
SageMaker RL을 사용한 스케일링 예측 사례
자동 스케일링(Auto Scaling)을 사용하면 정의한 조건에 따라 자동으로 용량을 추가하거나 제거하여 서비스(예: Amazon EC2)를 동적으로 조정할 수 있습니다. 이 기능을 사용하려면 일반적으로 임계값, 경보, 조정 정책 등을 설정해야 합니다.
이제 일례로 Amazon EC2 용량을 조정할 때 RL 모델 및 사용자 지정 시뮬레이터를 통해 이 프로세스를 최적화하는 방법을 살펴보겠습니다. 간단한 설명을 위해 여기서는 가장 중요한 코드 조각만 강조해서 보여드리겠습니다. 전체 예제는 Github에서 확인할 수 있습니다.
여기서 핵심은 인스턴스 용량을 로그 프로필에 맞게 조정하는 것입니다. 프로비저닝 부족(트래픽 손실) 또는 프로비저닝 초과(비용 낭비) 없이 ‘딱 맞는’ 용량을 프로비저닝하는 것이 목표입니다.
RL과 관련된 설정은 다음과 같습니다.
- 환경에는 로드 프로필과 다수의 실행 중인 인스턴스가 있습니다.
- 각 단계에서 에이전트는 인스턴스를 추가하고 인스턴스를 제거하는 2가지 행동을 취할 수 있습니다. 인스턴스를 추가하면 더 많은 트랜잭션을 처리할 수 있지만 비용이 늘어나고 온라인으로 전환하는 데 몇 분이 걸립니다. 인스턴스를 제거하면 비용이 절감되지만 전체 처리 용량이 감소합니다.
- 보상은 인스턴스 실행 비용과 트랜잭션 완료의 가치를 조합한 것이며 용량이 부족할 경우 큰 패널티가 발생합니다.
시뮬레이션 설정
우선, 트래픽이 높은 웹 서버에서 관찰되는 것과 유사한 로드 프로필을 생성할 시뮬레이터가 필요합니다. 이를 위해 아주 단순한 Python 프로그램을 사용하겠습니다. 다음은 3일간의 분당 트랜잭션 수(tpm)를 보여주는 예제입니다. 대부분은 주기적이지만 예측되지 않는 급격한 스파이크가 발생합니다.
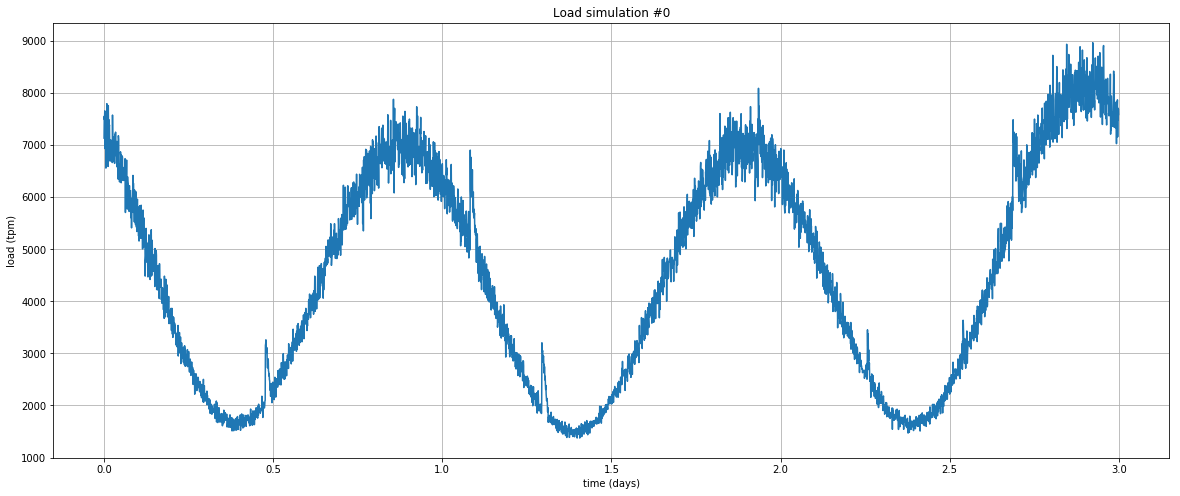
초기 상태는 다음과 같습니다.
config_defaults = {
"warmup_latency": 5, # 새 인스턴스가 사용 가능하게 되기까지는 5분이 걸림
"tpm_per_machine": 300, # 각 인스턴스는 평균적으로 분당 300개의 트랜잭션을 처리할 수 있음(tpm)
"tpm_sigma": 30, # 컴퓨터의 TPM 용량은 +/- 30 표준 편차로 변경 가능
"machine_cost": 0.05, # 인스턴스의 비용은 분당 0.05 달러임
"transaction_val": 0.90, # 성공한 트랜잭션은 1,000개당 0.90달러(CPM)
"downtime_cost": 200, # Downtime은 불완전한 트랜잭션보다 더 많은 200/min의 비즈니스 비용이 소요된다고 가정함
"downtime_percent": 99.5, # 가용성이 99.5% 이하로 떨어질 경우를 다운타임으로 정의
"initial_machines": 50, # 처음 준비되는 인스턴스의 수
"max_time_steps": 1000, # 에피소드당 최대 타임스탭 수
}
보상 계산
아주 간단합니다! 현재 로드를 현재 용량과 비교하고, 트랜잭션 손실의 비용을 차감하고, 0.5%를 초과하는 손실에 대해 큰 패널티를 적용합니다(상당히 엄격한 다운타임 정의임).
def _react_to_load(self):
self.capacity = int(self.active_machines * np.random.normal(self.tpm_per_machine, self.tpm_sigma))
if self.current_load <= self.capacity:
# 모든 트랜잭션이 성공
self.failed = 0
succeeded = self.current_load
else:
# 몇몇 트랜잭션이 실패
self.failed = self.current_load - self.capacity
succeeded = self.capacity
reward = succeeded * self.transaction_val / 1000.0 # CPM을 위해 천으로 나눔
percent_success = 100.0 * succeeded / (self.current_load + 1e-20)
if percent_success < self.downtime_percent:
self.is_down = 1
reward -= self.downtime_cost
else:
self.is_down = 0
reward -= self.active_machines * self.machine_cost
return reward시뮬레이션 단계 이동
에이전트가 RL 프레임워크로 시작되는 각 시간 단계를 통과하는 방법은 다음과 같습니다. 위에서 설명한 것과 같이 모델은 처음에 임의 행동을 예측하지만 몇 번의 훈련을 거친 후에는 훨씬 더 영리해집니다.
def step(self, action):
# 우선 먼저 대응한 후에 인스턴스 집합을 조정
turn_on_machines = int(action[0])
turn_off_machines = int(action[1])
self.active_machines = max(0, self.active_machines - turn_off_machines)
warmed_up_machines = self.warmup_queue[0]
self.active_machines = min(self.active_machines + warmed_up_machines, self.max_machines)
self.warmup_queue = self.warmup_queue[1:] + [turn_on_machines]
# 현재 부하에 반응하고 보상을 계산
self.current_load = self.load_simulator.time_step_load()
reward = self._react_to_load()
self.t += 1
done = self.t > self.max_time_steps
return self._observation(), reward, done, {}SageMaker를 통한 데이터 훈련
이제 다른 SageMaker 모델과 같은 방식으로 예제의 모델을 훈련할 수 있습니다. 이미지 이름(여기서는 인텔 Coach에 대한 TensorFlow 컨테이너), 인스턴스 유형 등을 전달합니다.
rlestimator = RLEstimator(role=role, framework=Framework.TENSORFLOW, framework_version='1.11.0', toolkit=Toolkit.COACH, entry_point="train-autoscale.py", train_instance_count=1, train_instance_type=p3.2xlarge) rlestimator.fit()
훈련 로그를 보면 처음에 에이전트가 훈련 없이 환경을 탐색하는 것을 알 수 있습니다. 이 단계를 가열 단계(heatup phase)라고 하며 학습할 초기 데이터 세트를 생성하는 데 사용됩니다.
## simple_rl_graph: Starting heatup
Heatup> Name=main_level/agent, Worker=0, Episode=1, Total reward=-39771.13, Steps=1001, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=2, Total reward=-3089.54, Steps=2002, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=3, Total reward=-43205.29, Steps=3003, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=4, Total reward=-24542.07, Steps=4004, Training iteration=0
...가열 단계가 완료되면 모델이 반복된 학습 주기(‘정책 훈련’) 및 학습한 내용을 기반으로 한 탐색(‘훈련’)을 수행합니다.
Policy training> Surrogate loss=-0.09095033258199692, KL divergence=0.0003891458618454635, Entropy=2.8382163047790527, training epoch=0, learning_rate=0.0003
Policy training> Surrogate loss=-0.1263471096754074, KL divergence=0.00145535240881145, Entropy=2.836780071258545, training epoch=1, learning_rate=0.0003
Policy training> Surrogate loss=-0.12835979461669922, KL divergence=0.0022696126252412796, Entropy=2.835214376449585, training epoch=2, learning_rate=0.0003
Policy training> Surrogate loss=-0.12992703914642334, KL divergence=0.00254297093488276, Entropy=2.8339898586273193, training epoch=3, learning_rate=0.0003
....
Training> Name=main_level/agent, Worker=0, Episode=152, Total reward=-54843.29, Steps=152152, Training iteration=1
Training> Name=main_level/agent, Worker=0, Episode=153, Total reward=-51277.82, Steps=153153, Training iteration=1
Training> Name=main_level/agent, Worker=0, Episode=154, Total reward=-26061.17, Steps=154154, Training iteration=1
모델이 설정된 epoch 수에 도달하면 훈련이 완료됩니다. 이 예에서는 18분간 훈련했습니다. 이제 모델의 학습 결과를 살펴보겠습니다.
![]()
데이터 훈련 진행 시각화
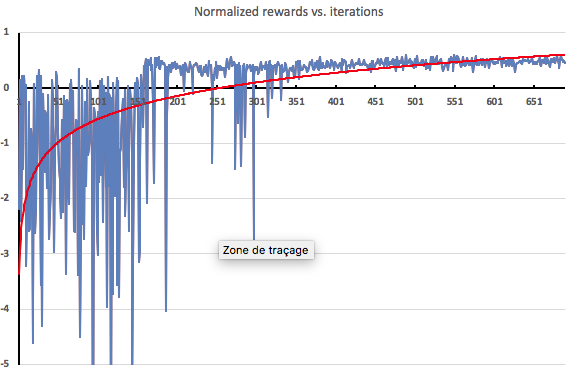
결과를 알아보는 방법 중 하나는 에이전트가 각 탐색 반복 후 받은 보상을 시각화 하는 것입니다. 예상한 대로 가열 단계(150회 반복)의 보상은 매우 좋지 않습니다. 에이전트가 전혀 훈련되지 않은 상태이기 때문입니다. 훈련이 적용되는 즉시 보상은 빠르게 개선됩니다.
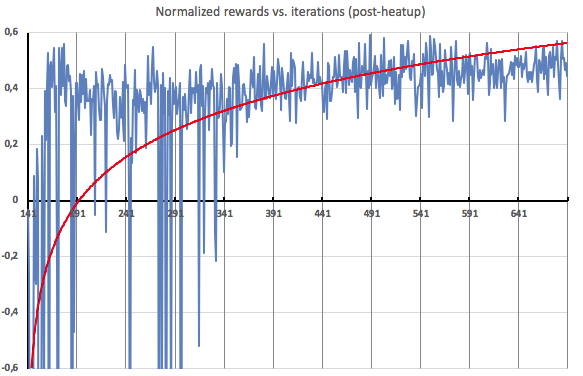
다음은 가열 후의 반복을 확대한 것입니다. 보시다시피 중간 즈음에는 꽤 일관적인 긍정 보상을 받기 시작하면서 에이전트가 검색되는 로드 프로필에 효율적인 조정을 적용하고 있음을 보여줍니다.
모델 배포해보기
모델이 만족할만한 성능을 내면 다른 SageMaker 모델과 마찬가지 방식으로 모델을 배포하고 새로 생성된 HTTPS 엔드포인트를 사용해 예측할 수 있습니다. 로봇을 훈련 중이라면 AWS Greengrass를 사용하여 엣지 디바이스에 배포할 수도 있습니다.
지금 이용 가능
이 글에서 유용한 정보를 얻으셨나요? 여기서 설명한 내용은 Amazon SageMaker RL의 기능 중 극히 일부에 불과합니다. 이 서비스는 Amazon SageMaker가 제공되는 모든 리전에서 지금 바로 사용할 수 있습니다. 서비스를 살펴보고 의견을 공유해 주십시오. 이 서비스를 사용해 혁신적인 모델을 구축할 수 있기를 바랍니다.
— Julien;
[1] “Deep Reinforcement Learning for Building HVAC Control”, T. Wei, Y. Wang and Q. Zhu, DAC’17, 2017년 6월 18~22일, 미국 텍사스 오스틴.
이 글은 AWS News Blog의 Amazon SageMaker RL – Managed Reinforcement Learning with Amazon SageMaker의 한국어 번역으로 정도현 AWS 테크니컬 트레이너가 감수하였습니다.