- 机器学习›
- Amazon SageMaker AI›
- Amazon SageMaker 推理
什么是 Amazon SageMaker 推理?
SageMaker 推理功能的优势
多种推理选项
实时推理
实时推理
无服务器推理
无服务器推理
异步推理
异步推理
批量转换
批量转换
支持大多数机器学习框架和模型服务器
Amazon SageMaker 推理支持一些最常用的机器学习框架(例如 TensorFlow、PyTorch、ONNX 和 XGBoost)的内置算法和预构建的 Docker 映像。如果所有预构建的 Docker 映像都无法满足您的需求,则可以构建自己的容器,以与 CPU 支持的多模型终端节点一起使用。SageMaker 推理支持广受欢迎的模型服务器,例如 TensorFlow Serving、TorchServe、NVIDIA Triton、AWS 多模型服务器。
Amazon SageMaker AI 提供专门的深度学习容器(DLC)、库和工具,用于模型并行和大型模型推理(LMI),以帮助您提高基础模型的性能。使用这些选项,您可以针对几乎所有使用案例快速部署模型,包括基础模型(FM)。
以低成本实现高推理性能
以低成本实现高推理性能
Amazon SageMaker AI 的新推理优化工具包可将生成式人工智能模型(例如 Llama 3、Mistral 和 Mixtral 模型)的吞吐量提高大约 2 倍,同时将成本降低多达 50%。例如,使用 Llama 3-70B 模型,在不进行任何优化的情况下,在 ml.p5.48xlarge 实例上最多可以达到大约 2400 个令牌/秒,而之前的速度约为 1200 个令牌/秒。您可以选择一种模型优化技术(例如 Speculative Decoding、Quantization 和 Compilation)或者将几种技术结合使用,将它们应用到您的模型中,运行基准以评估这些技术对输出质量和推理性能的影响,只需单击几下鼠标即可部署模型。
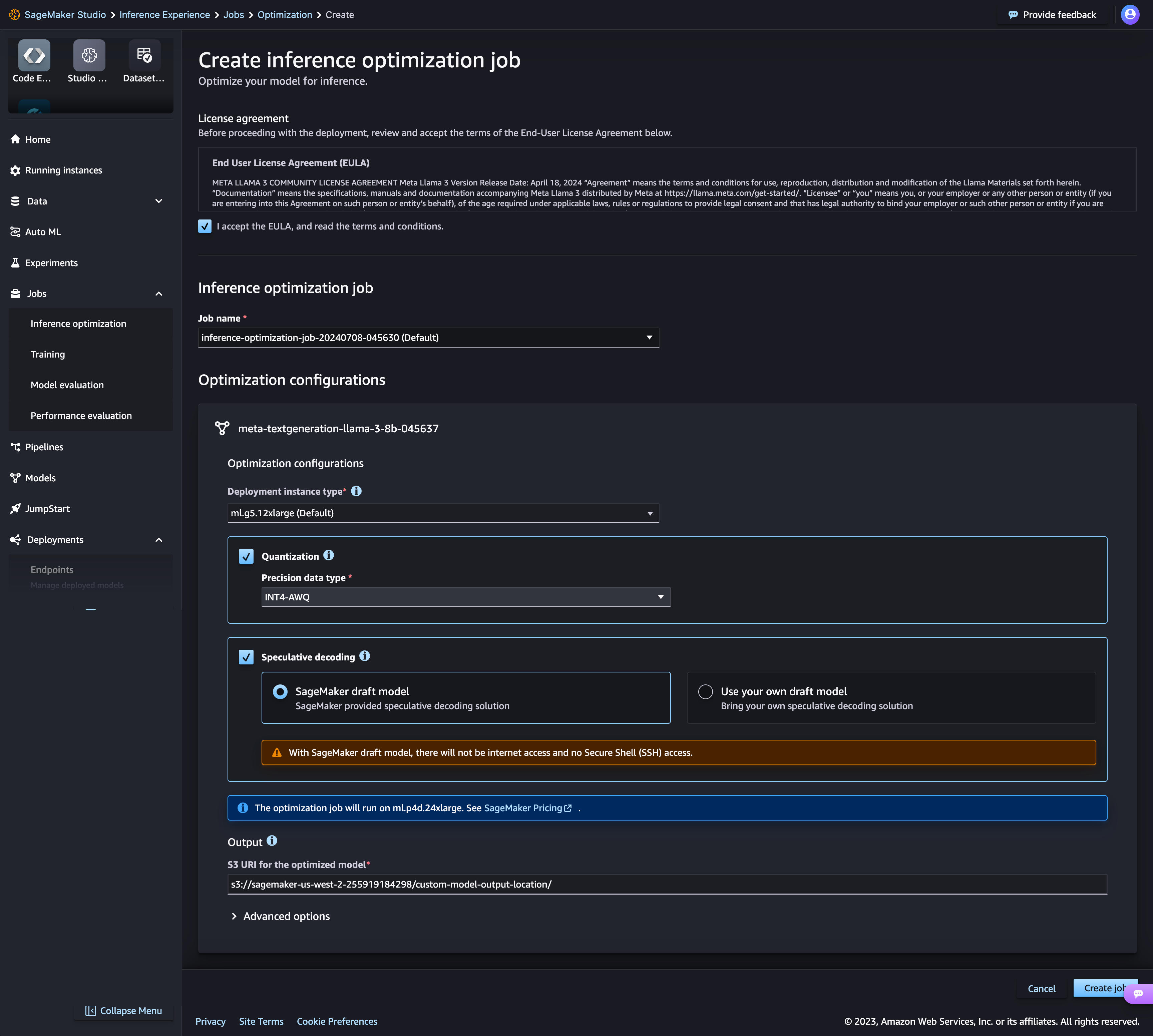
在性能最高的基础设施上部署模型或采用无服务器架构
Amazon SageMaker AI 提供 70 多种具有不同计算和内存级别的实例类型,包括基于 AWS Inferentia 的 Amazon EC2 Inf1 实例、由 AWS 设计和构建的高性能机器学习推理芯片以及 Amazon EC2 G4dn 等 GPU 实例。或者,选择 Amazon SageMaker 无服务器推理功能,轻松扩展到每个端点的数千个模型、每秒数百万个事务(TPS)吞吐量和低于 10 毫秒的开销延迟。

用于验证机器学习模型性能的影子测试
Amazon SageMaker AI 使用实时推理请求对照当前采用 SageMaker 部署的模型进行性能的影子测试来帮助您评估新模型。影子测试可以帮助您在潜在的配置错误和性能问题对最终用户造成影响前捕获它们。借助 SageMaker AI,您无需花费数周的时间来构建自己的影子测试基础设施。只需选择要测试的生产模型,SageMaker AI 就会自动在影子模式下部署新模型,并将生产模型收到的推理请求的副本实时路由到新模型。
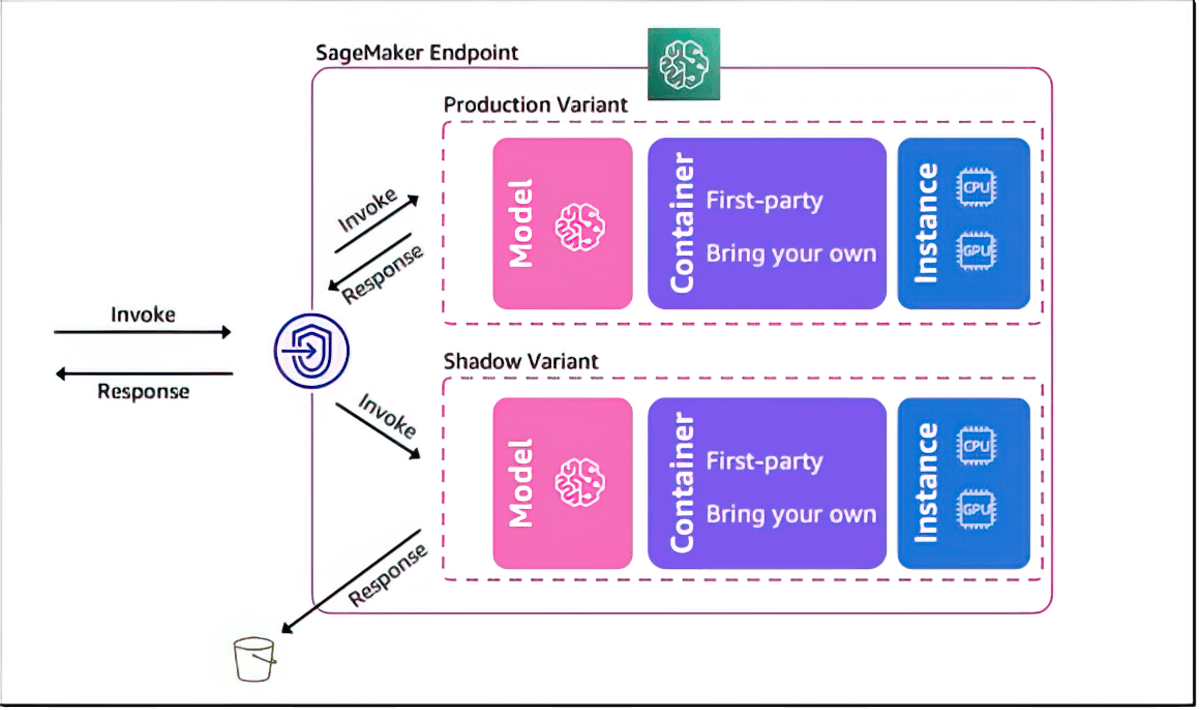
延迟改善和智能路由
您可以通过智能地将新的推理请求路由到可用的实例(而不是将请求随机路由到已经忙于提供推理请求的实例)来减少机器学习模型的推理延迟,从而使推理延迟平均降低 20%。
减轻运营负担,加快价值实现
完全托管式模型托管和管理
作为一项完全托管式服务,Amazon SageMaker AI 负责设置和管理实例、软件版本兼容性和补丁版本。它还为端点提供内置指标和日志,您可以使用这些指标和日志来监控和接收警报。

与 MLOps 功能进行内置集成
Amazon SageMaker AI 模型部署功能与 MLOps 功能原生集成,包括 SageMaker Pipelines(工作流自动化和编排)、SageMaker 项目(用于机器学习的 CI/CD)、SageMaker Feature Store(特征管理)、SageMaker Model Registry(用于跟踪谱系和支持自动化批准工作流的模型和构件目录)、SageMaker Clarify(偏差检测)和 SageMaker Model Monitor(模型和概念偏差检测)。因此,无论您是部署一个模型还是数万个模型,SageMaker AI 都可以帮助减少部署、扩展和管理机器学习模型的运营开销,同时更快地将其投入生产。