生成式 AI 開箱終極攻略:如何在 Amazon SageMaker JumpStart 上使用 StableDiffusion XL

使用 Amazon SageMaker Studio 中的 Amazon SageMaker JumpStart 運行 Stable Diffusion XL
今天我們很高興宣佈,客戶現在可以透過 Amazon SageMaker JumpStart 使用 Stable Diffusion XL 1.0 (SDXL 1.0)。SDXL 1.0 是來自 Stability AI 的最新圖像生成模型。SDXL 1.0 的增強功能包括以各種長寬比本機生成 1024 像素的圖像。它專為專業用途而設計,並針對高分辨率的逼真圖像進行了校準。SDXL 1.0 提供了各種可立即用於營銷、設計和跨行業圖像生成用例的預設藝術風格。您可以輕鬆試用這些模型,並將它們與 SageMaker JumpStart 一起使用,SageMaker JumpStart 是一個機器學習 (ML) 中心,提供對算法、模型和 ML 解決方案,因此您可以加速 ML 建置與部署。
在這篇文章中,我們將介紹如何通過 SageMaker JumpStart 使用 SDXL 1.0 模型。
什麼是 Stable Diffusion XL 1.0 (SDXL 1.0)
SDXL 1.0 是 Stable Diffusion 的新版升級,也是圖像生成式 AI 的新領域新高度。SDXL 能夠生成令人驚嘆的圖像,包含複雜的概念和各種藝術風格,包括超越當今最佳圖像模型的逼真品質。與原始 Stable Diffusion 系列一樣,SDXL 高度可定制 (在參數方面),並且可以部署在 Amazon SageMaker 實例上。
以下是使用簡單提示生成的一隻獅子的圖像,我們將在本文後面探討。

SDXL 1.0 模型包括以下亮點:
- 表達自由 - 一流的逼真效果,以及在幾乎任何藝術風格中生成高品質藝術作品的能力。生成的圖像不受模型賦予的特定風格影響,確保了絕對的風格自由。
- 藝術智能 – 頂尖的能力可生成傳統上對圖像模型來說渲染困難的概念,如手和文字,或空間排列的物體和人物(例如紅色盒子疊在藍色盒子上)。
- 更簡單的提示 - 與其他生成式圖像模型不同,SDXL 只需幾個字就可以創建複雜、詳細和美觀的圖像。不再需要段落形式的限定詞。
- 更準確 - SDXL 中的提示不僅簡單,而且更符合提示的本意。SDXL 改進的 CLIP 模型能夠如此有效地理解文本,以至於像”紅色廣場”這樣的概念與"一個紅色的正方形"是不同的。Stable diffusion 的準確度允許僅使用文字輸入就能直接獲得最完美的圖像,甚至在使用 Stable Diffusion 著名的更高級功能或微調之前。
什麼是 SageMaker JumpStart
使用 SageMaker JumpStart,ML 從業人員可以從廣泛的最先進模型中進行選擇,用於內容撰寫、圖像生成、代程式碼生成、問題回答、文案撰寫、摘要、分類、信息檢索等用例。ML 從業人員可以將基礎模型部署到專用的 SageMaker 實例上,並使用 SageMaker 來自定義模型進行模型訓練和部署。現在可以在 Amazon SageMaker Studio 中發現 使用SDXL 模型,目前可在 us-east-1、us-east-2、us-west-2、eu-west-1、ap-northeast-1 和 ap-southeast-2 區域使用。
解決方案概述
在本文中,我們將演示如何將 SDXL 1.0 部署到 SageMaker,並使用文本生成圖像和圖像到圖像生成圖像。
SageMaker Studio 是一個基於網頁的整合式開發環境 (IDE),用於構建、訓練、調試、部署和監控 ML 模型。有關如何開始使用和設置 SageMaker Studio 的更多詳細信息,請參閱 Amazon SageMaker Studio。
進入 SageMaker Studio UI 後,訪問 SageMaker JumpStart 並搜索 Stable Diffusion XL。選擇 SDXL 1.0 模型卡片,它將打開一個筆記本範例。這意味著您只需支付運算成本。沒有相關的模型成本。相比於開源權重的 SDXL 1.0,閉源權重的 SDXL 1.0 提供了 SageMaker 優化的腳本和容器,能夠縮短推理時間,並且可以在較小規格的實例上運行。範例筆記本將引導您完成步驟,也將在討論如何發現和部署模型。
在以下部分中,我們將展示如何使用 SDXL 1.0 創建逼真的圖像,使用更短的提示以及在圖像中生成文本。Stable Diffusion XL 1.0 提供了增強的圖像構圖和臉部生成功能,可以產生有出色的視覺效果,和逼真的圖像。
Stable Diffusion XL 1.0 參數
SXDL 1.0 使用以下參數:
- cfg_scale - 擴散過程對於提示文字的嚴格遵循程度。
- height 和 width - 圖像的高度和寬度(以像素為單位)。
- steps - 要運行的擴散步數。
- seed - 隨機噪聲種子值。如果提供了種子值,生成的圖像將是確定性的。
- sampler - 用於去噪生成的擴散過程的採樣器。
- text_prompts - 用於生成的文本提示陣列。
- weight - 為每個提示提供特定權重。
有關更多信息,請參閱 Stability AI 的 text to image 文檔。
以下代碼是隨提示文本一起提供的輸入數據的範例
{
"cfg_scale": 7,
"height": 1024,
"width": 1024,
"steps": 50,
"seed": 42,
"sampler": "K_DPMPP_2M",
"text_prompts": [
{
"text": "A photograph of fresh pizza with basil and tomatoes, from a traditional oven",
"weight": 1
}
]
}
本文中的所有範例都基於可以在 Stability AI 的 GitHub 存儲庫中的 Stability Diffusion XL 1.0 範例筆記本找到。
使用 SDXL 1.0 生成圖像
在以下範例中,我們將重點關注 Stability Diffusion XL 1.0 模型的功能,包括卓越的照片級寫實效果效果、增強的圖像構圖, 以及生成逼真人臉的能力。我們還將探討顯著改善的視覺美學,從而產生令人賞心悅目的輸出結果。此外,我們將演示使用較短的提示文本,更輕鬆地創建描述性圖像。最後,我們將說明圖像中的文本現在更加清晰可讀,進一步增強了生成內容的整體品質。
以下範例展示了使用簡單提示獲取詳細圖像。只用了幾個字的提示,它就能夠創建出與提供的提示相似的複雜、詳細且美觀的圖像。
text = "photograph of latte art of a cat"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
seed=5,
height=640,
width=1536,
sampler="DDIM",
))
decode_and_show(output)

接下來,我們使用 style_preset 輸入參數 ,這個功能只有在 SDXL 1.0 中才提供。透過style_preset 參數,可以引導圖像生成模型朝著特定風格生成。
其他一些可用的 style_preset 參數包括 enhance、anime、photographic、digital-art、comic-book、fantasy-art、line-art、analog-film、neon-punk、isometric、low-poly、origami、modeling-compound、cinematic、3d-mode、pixel-art 和 tile-texture。這個預設風格預設選項會不定期更新,請參考最新版本的發佈說明和文件,以獲取最新資訊。
在此範例中,我們使用提示詞生成一個以 origami 風格的茶壺。該模型能夠以所提供的藝術風格生成高品質圖像。
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text="teapot")], style_preset="origami", seed = 3, height = 1024, width = 1024))

讓我們嘗試一些不同的風格預設和提示。下一個範例展示了使用 style_preset="photographic" 和提示 “portrait of an old and tired lion real pose” 生成肖像的預設風格。
text = "portrait of an old and tired lion real pose"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))

現在讓我們嘗試使用相同的提示(“portrait of an old and tired lion real pose”)但將風格預設設為 modeling-compound 。輸出圖像是一個獨特的圖像,不受任何特定風格的影響,確保了絕對的風格自由。

SDXL 1.0 的多重提示
正如我們所見,該模型的核心基礎之一是通過提示詞生成圖像的能力。SDXL 1.0 支持多重提示。通過多重提示,您可以通過為每個提示分配特定權重來將不同概念混合概念。如您在以下生成的圖像中所見,它具有一個高大明亮的綠色草叢的叢林背景。這幅圖像是使用以下提示生成的。您可以將其與我們之前的單一提示範例進行比較。
text1 = "portrait of an old and tired lion real pose"
text2 = "jungle with tall bright green grass"
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text1),
TextPrompt(text=text2, weight=0.7)],
style_preset="photographic",
seed=111,
height=640,
width=1536,
))
空間感知生成圖像和負面提示
接下來,我們看一下帶有詳細提示的海報設計。如我們之前看到的,多重提示允許您組合概念以創建新的獨特結果。
在這個範例中,展示了提示詞在構建主題位置、外觀、期望和環境方面的作用。模型還試圖通過負面提示避免產生失真或渲染不佳的圖像。生成的圖像顯示了具有空間排列的物體和主體。
text = "A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. But in the reflection, the cat sees not itself, but a mighty lion. The mirror illuminated with a soft glow against a pure white background."
negative_prompts = ['distorted cat features', 'distorted lion features', 'poorly rendered']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="enhance",
seed=43,
height=640,
width=1536,
steps=100,
cfg_scale=7,
negative_prompts=negative_prompts
))

讓我們嘗試另一個例子,我們保留相同的負面提示,但更改詳細的提示和風格預設。如您所見,生成的圖像不僅空間感很強,而且還根據詳細信息(像華麗的金色鏡子和主體反射)改變了風格預設。
text = "A cute fluffy white cat stands on its hind legs, peering curiously into an ornate golden mirror. In the reflection the cat sees itself."
negative_prompts = ['distorted cat features', 'distorted lion features', 'poorly rendered']
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="neon-punk",
seed=4343434,
height=640,
width=1536,
steps=150,
cfg_scale=7,
negative_prompts=negative_prompts
))

SDXL 1.0 的人臉生成
在這個例子中,我們展示了 SDXL 1.0 如何創建增強的圖像構圖和具有真實手部和手指等特徵的人臉生成。生成的圖像是一個由 AI 創建的明確雙手舉起的人物形象。請注意手指和姿勢的細節。如果僅由 AI 生成,此類圖像通常會顯得無定形,模糊的。
text = "Photo of an old man with hands raised, real pose."
output = deployed_model.predict(GenerationRequest(
text_prompts=[TextPrompt(text=text)],
style_preset="photographic",
seed=11111,
height=640,
width=1536,
steps=100,
cfg_scale=7,
))

使用 SDXL 1.0 生成文本
SDXL 適合於包括在圖像中生成文本的複雜圖像設計工作流程。這個提示範例展示了這一功能。觀察使用 SDXL 生成文本的清晰度,並注意到它採用了電影風格預設。
text = "Write the following word: Dream"
output = deployed_model.predict(GenerationRequest(text_prompts=[TextPrompt(text=text)],
style_preset="cinematic",
seed=15,
height=640,
width=1536,
sampler="DDIM",
steps=32,
))

從 SageMaker JumpStart 發現 SDXL 1.0
SageMaker JumpStart 為您加入和維護基礎模型,以便您可以訪問、自定義和將它們集成到您的機器學習的生命週期中。有些模型是開放權重模型,允許您訪問和修改模型權重和腳本,而有些是封閉權重模型,不允許您訪問它們以保護模型提供商的知識產權。封閉權重模型需要您從 AWS Marketplace 模型詳細信息頁面訂閱模型,而 SDXL 1.0 目前是一個封閉權重模型。在本節中,我們將介紹如何從 SageMaker Studio 發現、訂閱和部署封閉權重模型。
您可以通過在 SageMaker Studio 主頁面上的 “Prebuilt and automated solutions” 下選擇 “JumpStart” 來訪問 SageMaker JumpStart。
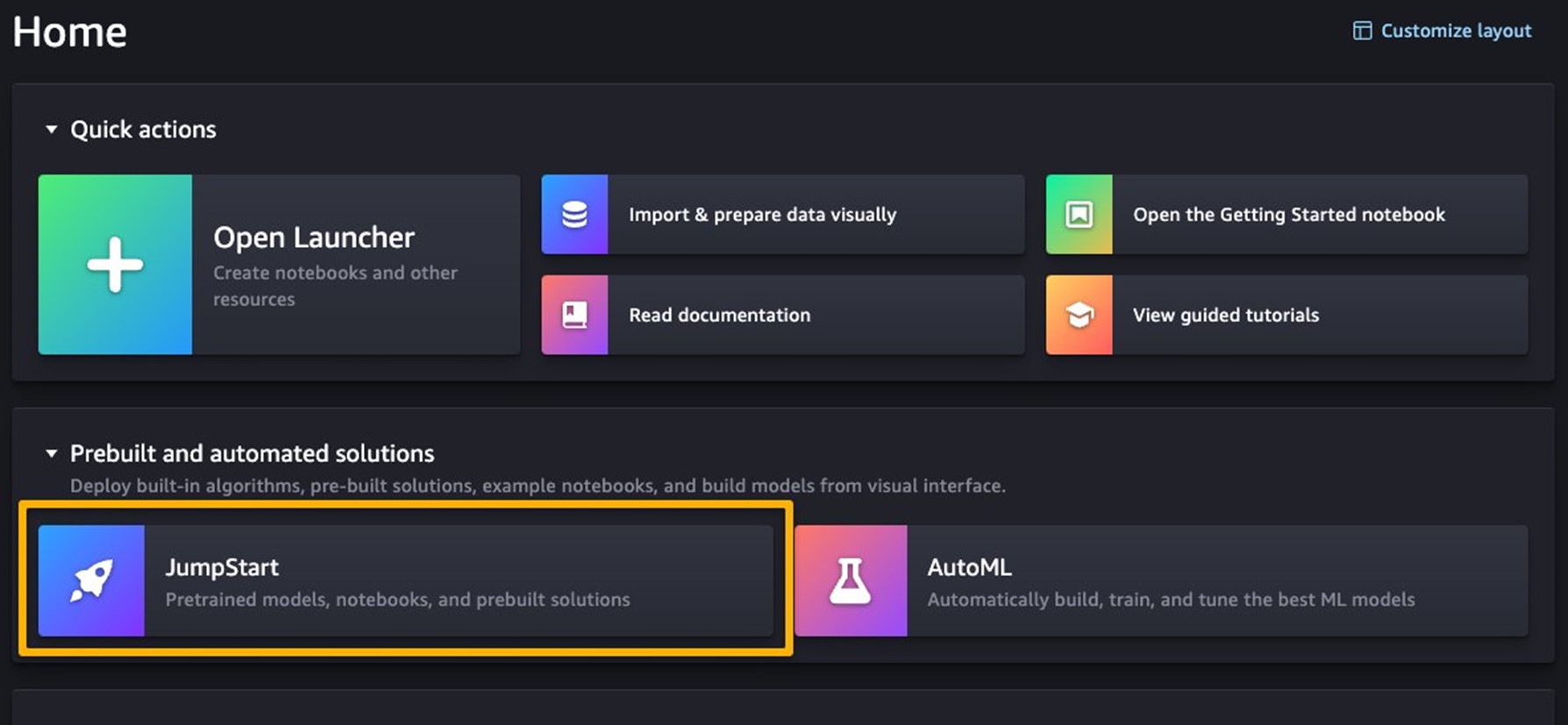
從 SageMaker JumpStart 登錄頁面,您可以瀏覽解決方案、模型、筆記本和其他資源。以下截圖顯示了登錄頁面的範例,列出了解決方案和基礎模型。
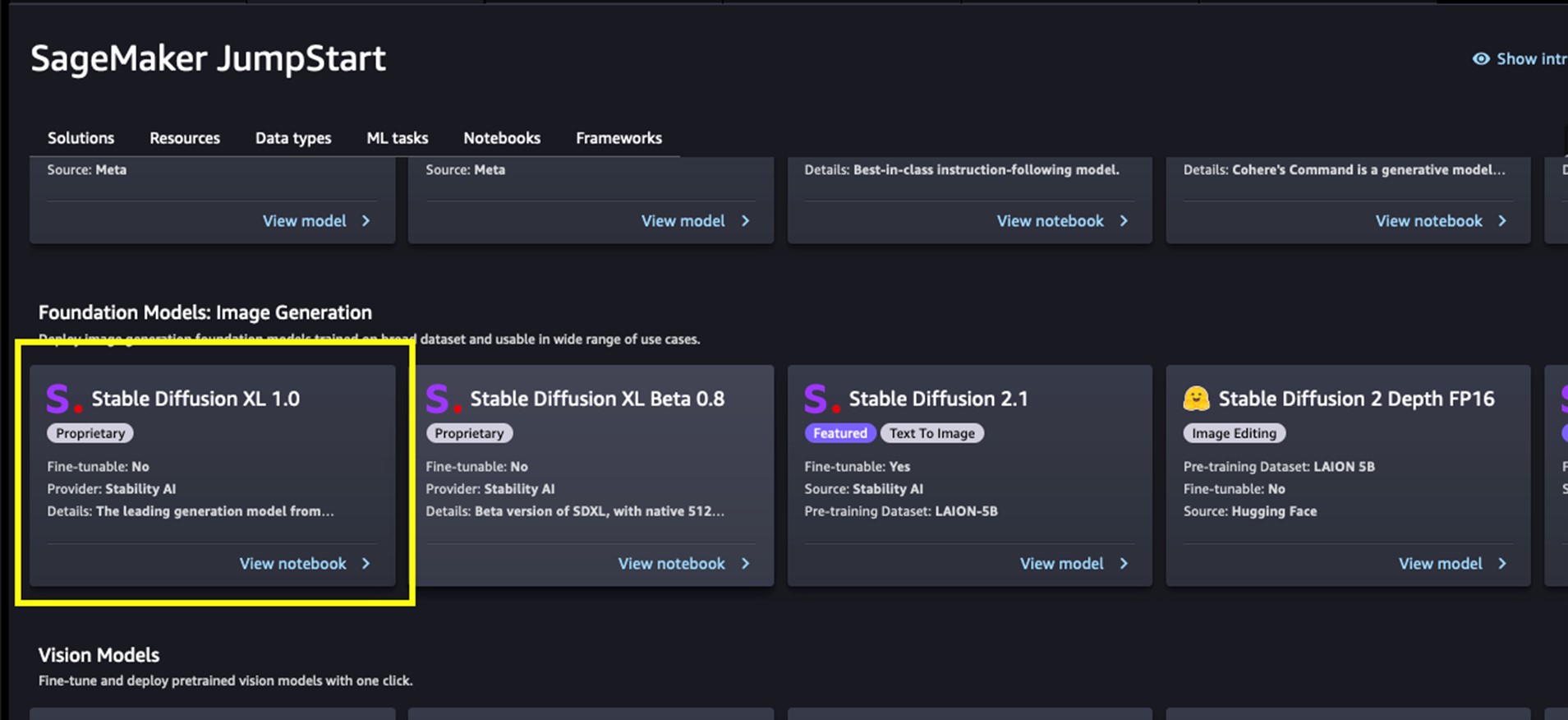
每個模型都有一個模型卡片,如下面的截圖所示,其中包含模型名稱、是否可微調、提供者名稱和關於模型的簡短描述。您可以在 Foundation Model: Image Generation 轉盤中找到 Stable Diffusion XL 1.0 模型,或在搜索框中搜索它。
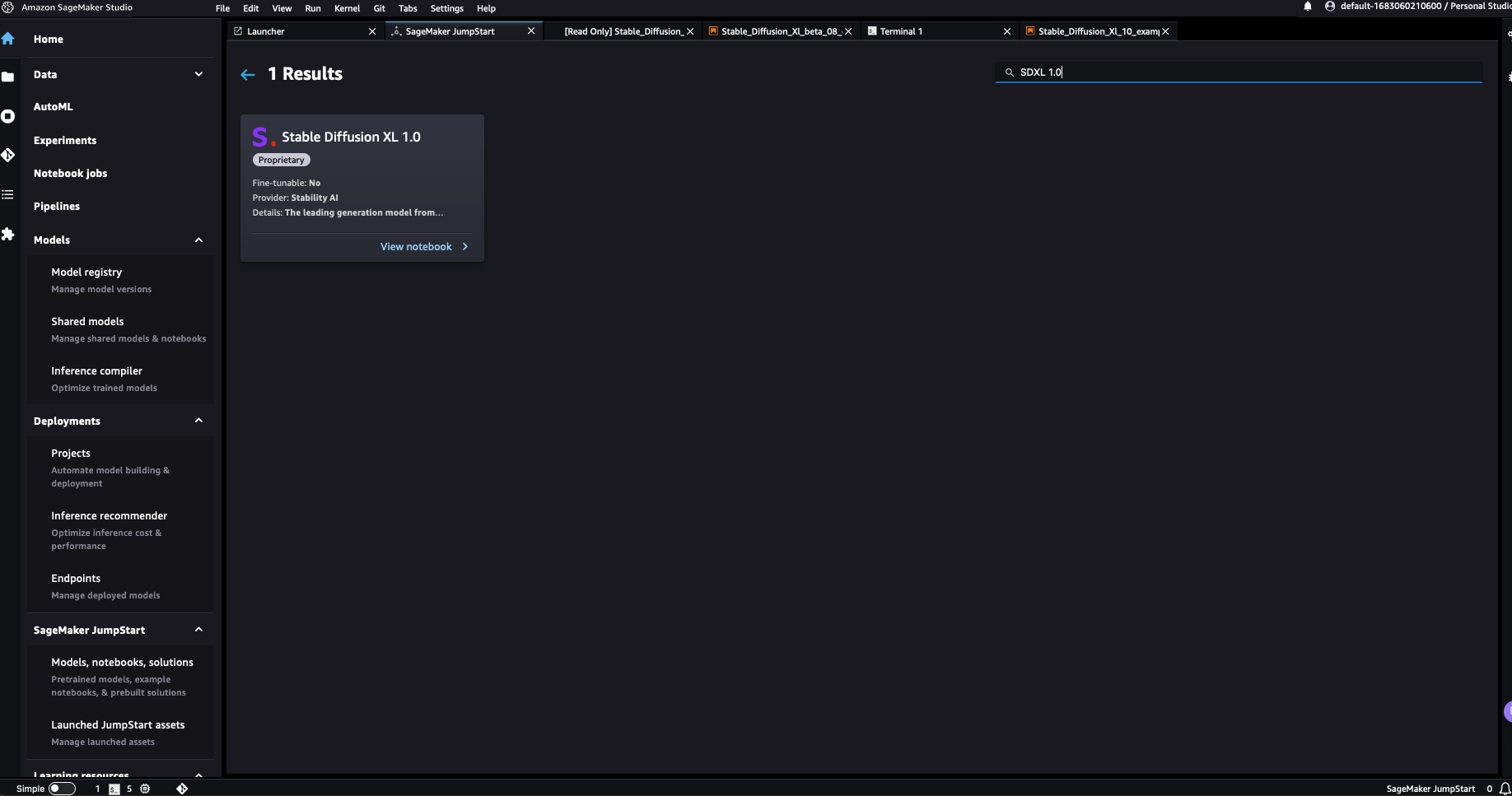
您可以選擇 Stable Diffusion XL 1.0 打開一個範例筆記本,其中介紹了如何使用 SDXL 1.0 模型。範例筆記本以唯讀模式打開;您需要選擇 Import notebook 才能運行它。

導入筆記本後,您需要選擇適當的筆記本環境(映像、內核、實例類型等),然後再運行代碼。
從 SageMaker JumpStart 部署 SDXL 1.0
在本節中,我們將介紹如何訂閱和部署模型。
1. 使用 SageMaker JumpStart 中範例筆記本中提供的鏈接,在 AWS Marketplace 上打開模型列表頁面。
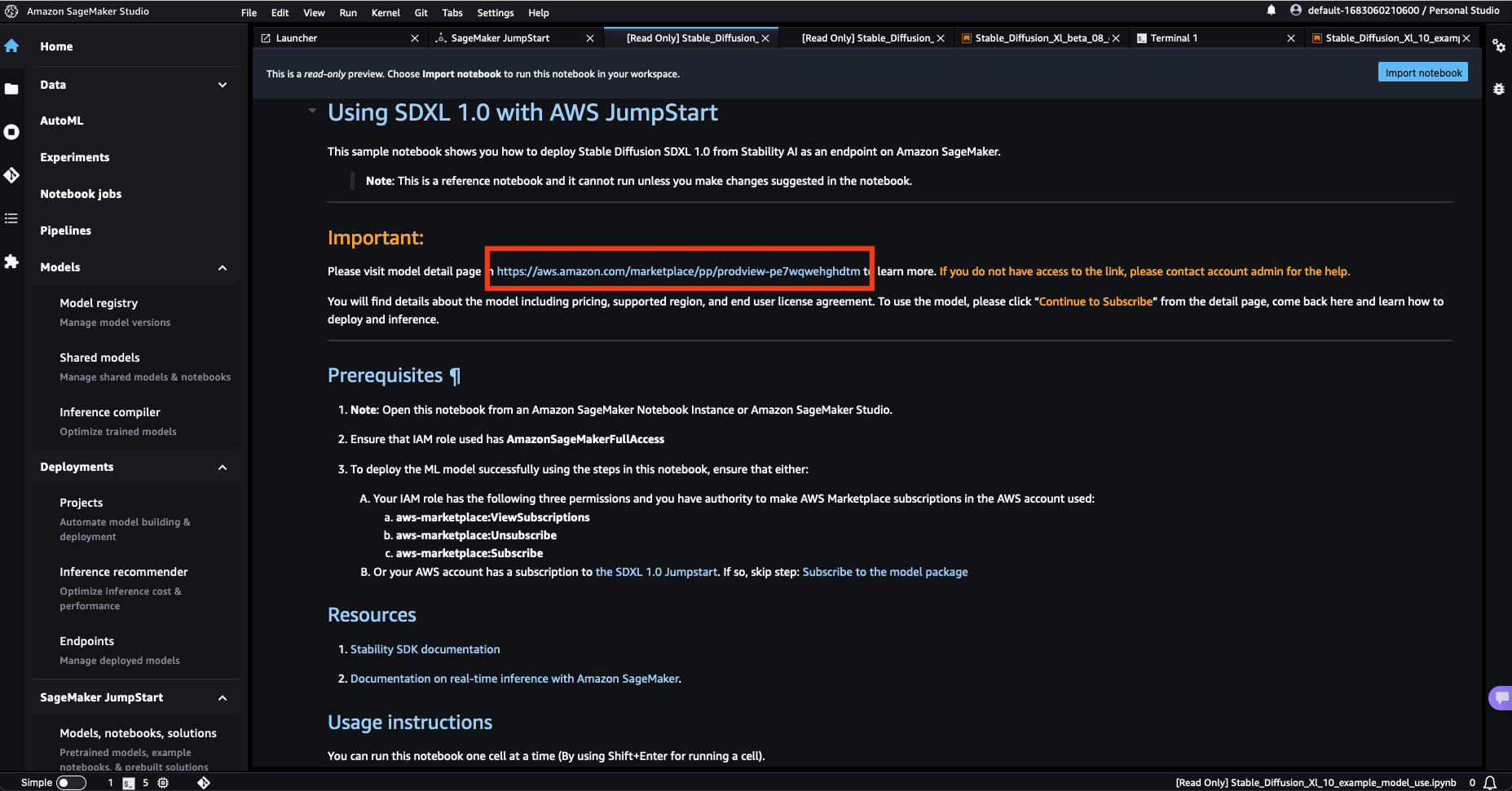
2. 在 AWS Marketplace 列表中,選擇 Continue to subscribe。
如果您沒有查看或訂閱模型所需的權限,請聯繫您的 AWS 管理員或採購聯絡人。許多企業可能會限制 AWS Marketplace 權限,以控制某人在 AWS Marketplace 管理門戶中可以採取的操作。
3. 選擇 Continue to Subscribe。
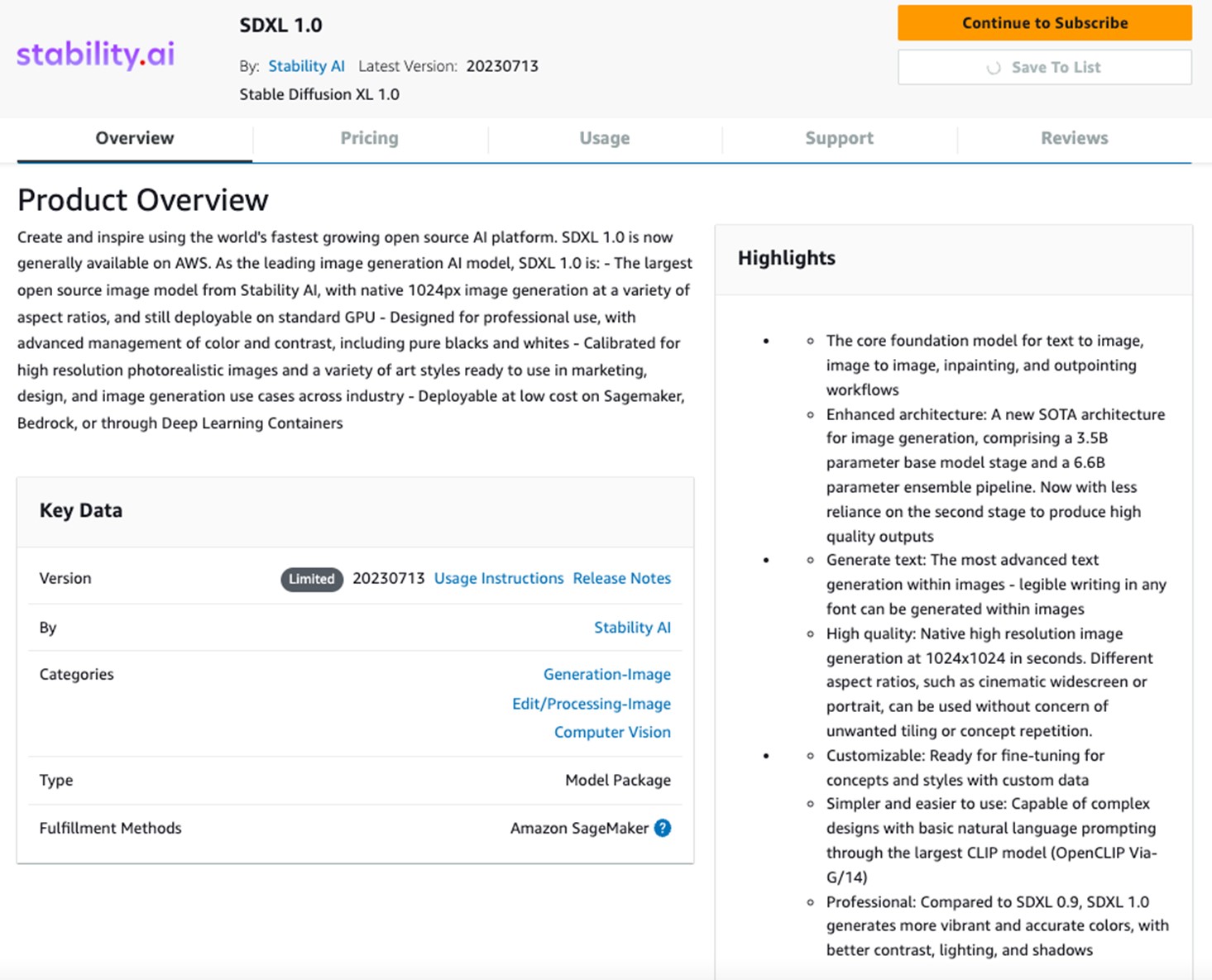
4. 在 Subscribe to this software 頁面上,查看定價詳情和最終用戶許可協議 (EULA)。如果可以接受,請選擇 Accept offer。
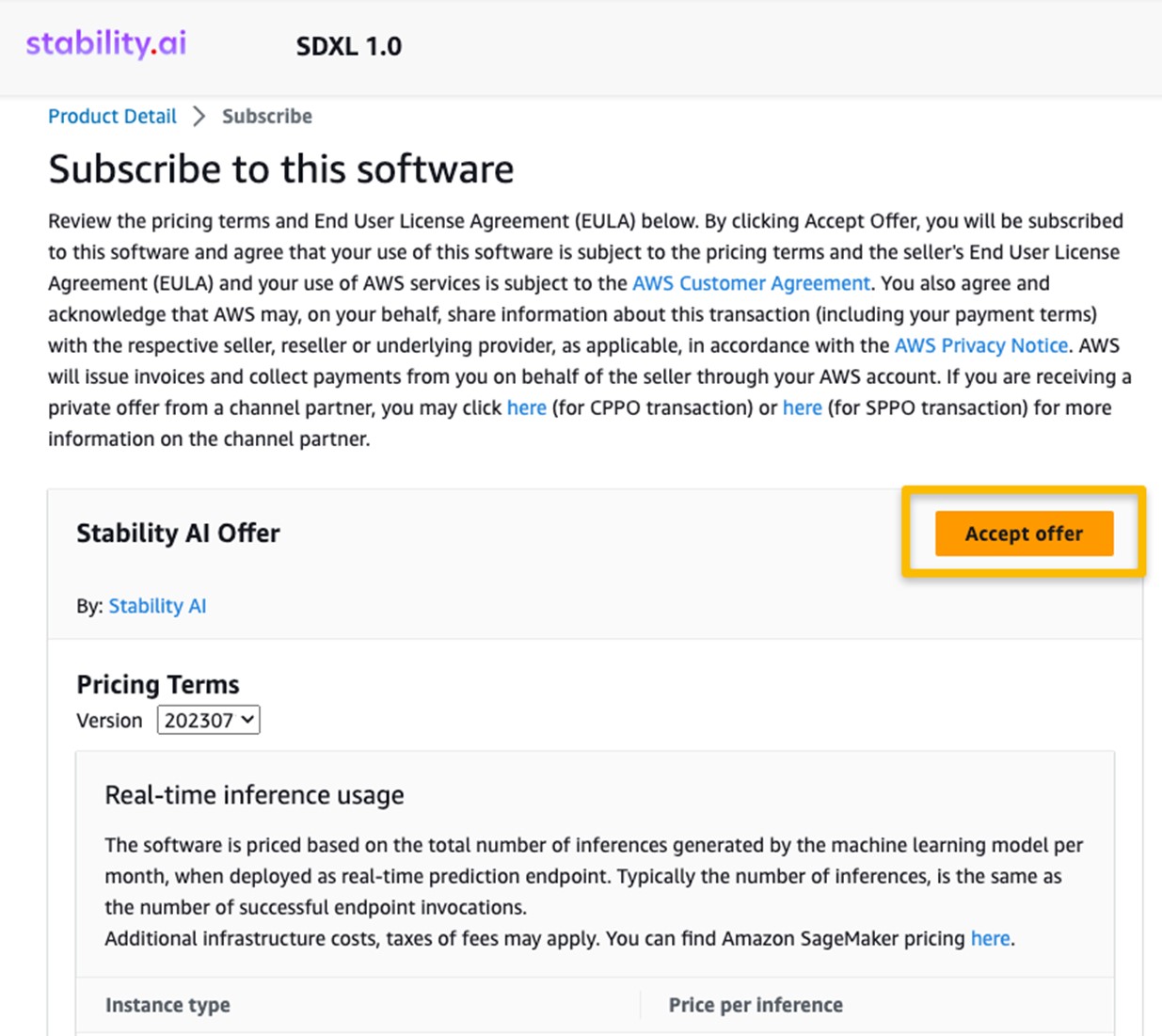
5. 選擇 Continue to configuration 開始配置您的模型。
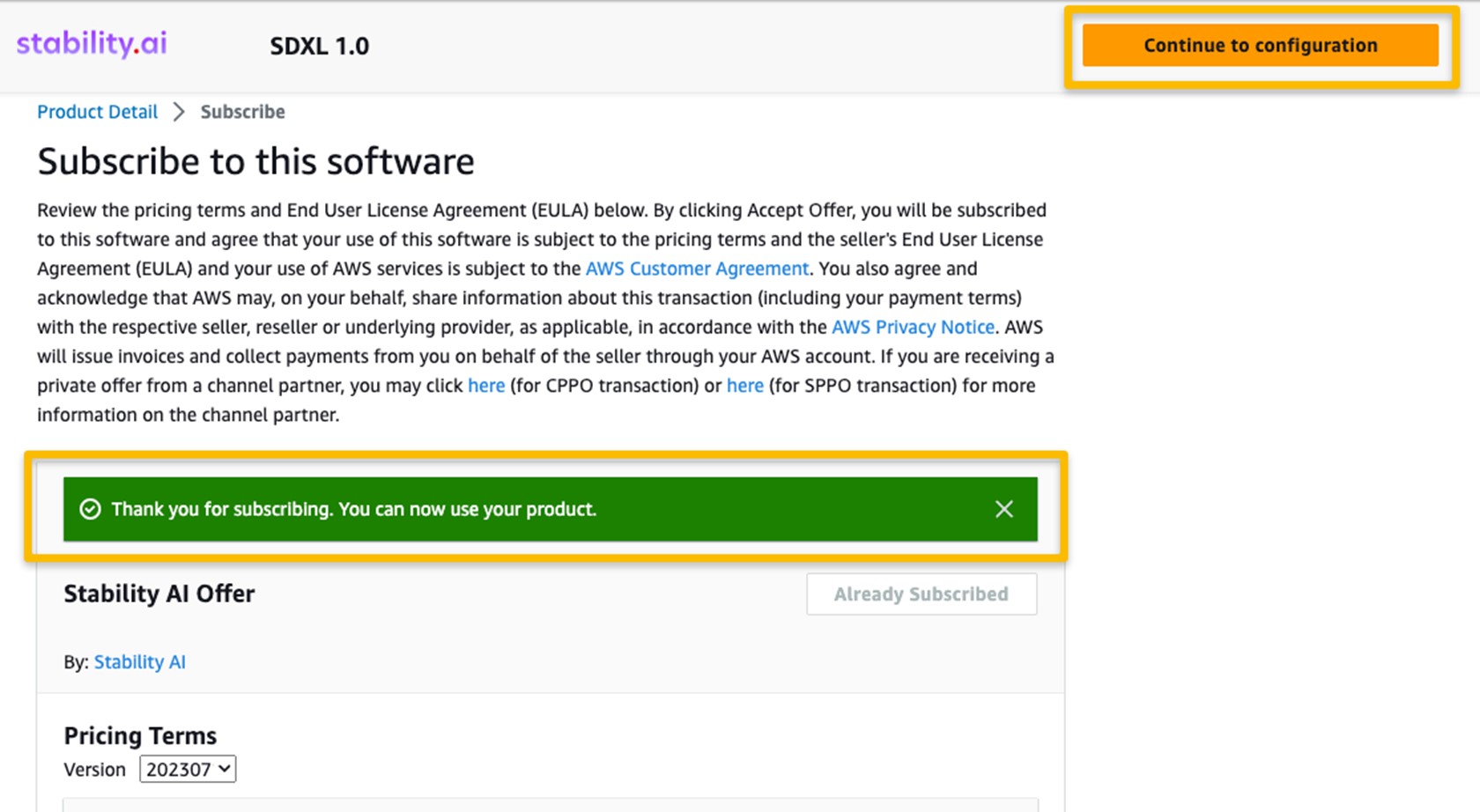
6. 選擇一個支持的區域。
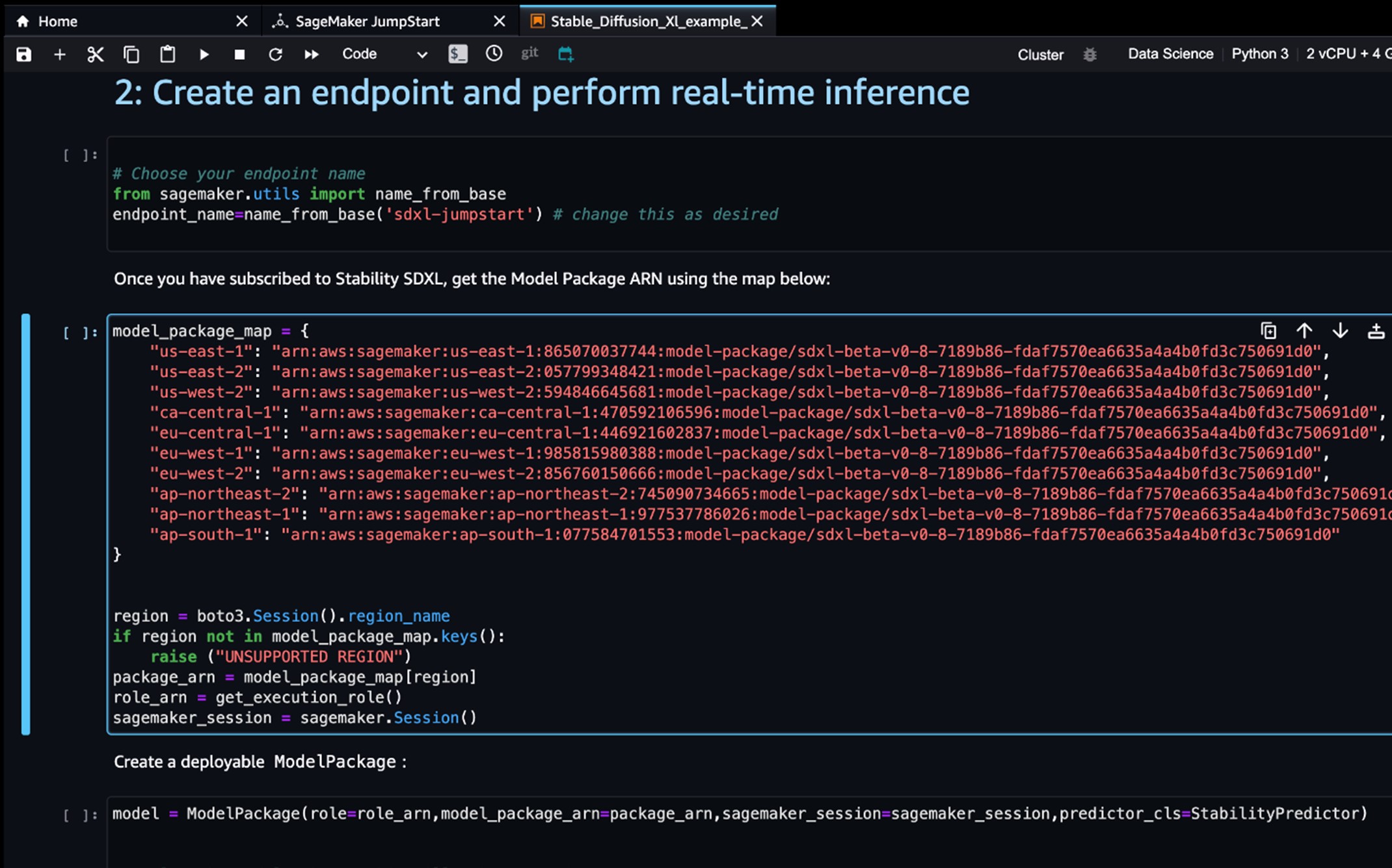
您將看到顯示的產品 ARN。這是您在使用 Boto3 創建可部署模型時需要指定的模型包 ARN。
7. 複製與您所在區域對應的 ARN,並在筆記本的單元格說明中指定相同的 ARN。
ARN 信息可能已經在範例筆記本中提供。
8. 現在您可以開始按照範例筆記本操作了。
您也可以繼續從 AWS Marketplace 進行操作,但我們建議您在 SageMaker Studio 中按照範例筆記本進行操作,以更好地理解部署的工作原理。
清理
完成工作後,您可以刪除端點以釋放與之關聯的 Amazon Elastic Compute Cloud (Amazon EC2) 實例並停止計費。
使用 AWS CLI 獲取您的 SageMaker 端點列表,如下所示:
!aws sagemaker list-endpoints
然後刪除端點:
deployed_model.sagemaker_session.delete_endpoint(endpoint_name)
結論
在這篇文章中中,我們向您展示了如何在 SageMaker Studio 中開始使用新的 SDXL 1.0 模型。通過這個模型,您可以利用 SDXL 提供的不同功能來創建逼真的圖像。由於基礎模型是預先訓練的,因此它們還可以幫助降低培訓和基礎設施成本,並支持根據您的使用案例進行定制。
關於Amazon Web Services
自 2006 年來,Amazon Web Services 一直在提供世界上服務最豐富、應用廣泛的雲端服務。AWS 不斷擴展可支持幾乎任何雲端工作負載的服務,為客戶提供超過 240 種功能全面的雲端服務,包括運算、儲存、資料庫、聯網、分析、機器學習與人工智慧、物聯網、行動、安全、混合雲、媒體,以及應用開發、部署和管理等方面,遍及 33 個地理區域內的 105 個可用區域(Availability Zones),並已公佈計畫在馬來西亞、墨西哥、紐西蘭、沙烏地阿拉伯和泰國等建立 6 個 AWS 地理區域、18 個可用區域。全球超過百萬客戶信任 AWS,包含發展迅速的新創公司、大型企業和政府機構。AWS 協助客戶強化自身基礎設施,提高營運上的彈性與應變能力,同時降低成本。欲瞭解更多 AWS 的相關資訊,請至: thinkwithwp.com。