



การเรียนรู้แบบเสริมแรงคืออะไร
การเรียนรู้แบบเสริมแรง (RL) เป็นเทคนิคแมชชีนเลิร์นนิง (ML) ที่ฝึกฝนซอฟต์แวร์ให้ทำการตัดสินใจเพื่อให้ได้ผลลัพธ์ที่เหมาะสมที่สุด โดยเลียนแบบกระบวนการเรียนรู้แบบลองผิดลองถูกที่มนุษย์ใช้เพื่อบรรลุเป้าหมาย การกระทำของซอฟต์แวร์ที่ทำงานไปสู่เป้าหมายของคุณได้รับการเสริมแรง ในขณะที่การกระทำที่เบี่ยงเบนไปจากเป้าหมายจะถูกมองข้าม
อัลกอริทึม RL ใช้กระบวนทัศน์รางวัลและการลงโทษขณะที่พวกเขาประมวลผลข้อมูล อัลกอริทึมเรียนรู้จากข้อเสนอแนะของแต่ละการกระทำและค้นพบเส้นทางการประมวลผลที่ดีที่สุดเพื่อให้บรรลุผลสุดท้ายด้วยตนเอง อัลกอริทึมยังสามารถอดทนรอคอยได้ กลยุทธ์โดยรวมที่ดีที่สุดอาจส่งผลเสียระยะสั้น ดังนั้นวิธีที่ดีที่สุดที่อัลกอริทึมค้นพบอาจมีถึงการลงโทษบางอย่างหรือการถอยหลังระหว่างดำเนินการ RL เป็นวิธีการที่มีประสิทธิภาพในการช่วยให้ระบบปัญญาประดิษฐ์ (AI) บรรลุผลลัพธ์ที่ดีที่สุดในสภาพแวดล้อมที่ไม่เคยพบ
ประโยชน์ของการเรียนรู้แบบเสริมแรงคืออะไร
มีประโยชน์มากมายในการใช้การเรียนรู้แบบเสริมแรง (RL) อย่างไรก็ตาม สามข้อต่อไปนี้เป็นประโยชน์ที่โดดเด่น
เป็นเลิศในสภาพแวดล้อมที่ซับซ้อน
อัลกอริทึม RL สามารถนำมาใช้ในสภาพแวดล้อมที่ซับซ้อนที่มีกฎระเบียบและการอ้างอิงมากมาย ในสิ่งแวดล้อมเดียวกัน มนุษย์อาจไม่สามารถกำหนดเส้นทางที่ดีที่สุดที่จะใช้ แม้จะมีความรู้ด้านสิ่งแวดล้อมที่เหนือกว่า แต่อัลกอริทึม RL แบบไร้แบบจำลองปรับตัวได้อย่างรวดเร็วให้เข้ากับสภาพแวดล้อมที่เปลี่ยนแปลงอย่างต่อเนื่องและหากลยุทธ์ใหม่เพื่อเพิ่มประสิทธิภาพผลลัพธ์
ต้องการปฏิสัมพันธ์ของมนุษย์น้อยลง
ในอัลกอริทึม ML แบบดั้งเดิม มนุษย์จะต้องระบุประเภทข้อมูลเพื่อกำกับขัอัลกอริทึม เมื่อคุณใช้อัลกอริทึม RL สิ่งนี้ไม่จำเป็น มันเรียนรู้ด้วยตัวเอง ในขณะเดียวกันก็เสนอกลไกในการผสานรวมข้อเสนอแนะของมนุษย์ ทำให้เกิดระบบที่ปรับตัวให้เข้ากับความชอบ ความเชี่ยวชาญ และการแก้ไขต่างๆ ของมนุษย์ได้
เพิ่มประสิทธิภาพสำหรับเป้าหมายระยะยาว
RL โดยลักษณะของตัวเองแล้วจะมุ่งเน้นไปที่การได้รางวัลสูงสุดในระยะยาว ซึ่งทำให้มันเหมาะสมกับสถานการณ์ที่การกระทำมีผลเป็นเวลานาน เหมาะอย่างยิ่งสำหรับสถานการณ์ในโลกจริงที่ข้อเสนอแนะไม่สามารถมีได้ทันทีสำหรับทุกขั้นตอน เนื่องจากมันสามารถเรียนรู้จากรางวัลที่ล่าช้าได้
ตัวอย่างเช่น การตัดสินใจเกี่ยวกับการใช้พลังงานหรือการเก็บรักษาอาจจะมีผลในระยะยาว RL สามารถใช้เพื่อเพิ่มประสิทธิภาพการใช้พลังงานและค่าใช้จ่ายในระยะยาวได้ ด้วยสถาปัตยกรรมที่เหมาะสม เจ้าหน้าที่ RL ยังสามารถนำกลยุทธ์การเรียนรู้ของพวกเขาไปใช้กับงานที่คล้ายกันแต่ไม่เหมือนกันได้
การเรียนรู้แบบเสริมแรงมีกรณีการใช้งานอะไรบ้าง
การเรียนรู้แบบเสริมแรง (RL) สามารถนำไปใช้ได้กับกรณีการใช้ในโลกจริงที่หลากหลาย เราจะยกตัวอย่างในส่วนถัดไป
การปรับการตลาดให้เหมาะกับแต่ละบุคคล
ในการประยุกต์ใช้งานเช่นระบบข้อเสนอแนะ RL สามารถปรับแต่งข้อเสนอแนะให้กับผู้ใช้แต่ละคนขึ้นอยู่กับการมีปฏิสัมพันธ์ของพวกเขา ซึ่งนำไปสู่ประสบการณ์ที่เหมาะกับแค่ละบุคคลมากขึ้น ตัวอย่างเช่น แอปพลิเคชันอาจแสดงโฆษณาให้กับผู้ใช้ตามข้อมูลประชากรบางอย่าง ด้วยการโต้ตอบกับโฆษณาแต่ละอัน แอปพลิเคชันจะเรียนรู้ว่าโฆษณาใดที่จะแสดงให้กับผู้ใช้เพื่อเพิ่มประสิทธิภาพการขายผลิตภัณฑ์
ความท้าทายในการเพิ่มประสิทธิภาพ
วิธีการเพิ่มประสิทธิภาพแบบดั้งเดิมแก้ปัญหาโดยการประเมินและเปรียบเทียบวิธีแก้ปัญหาที่เป็นไปได้ตามเกณฑ์บางอย่าง ในทางตรงกันข้าม RL นำการเรียนรู้จากปฏิสัมพันธ์มาใช้เพื่อหาทางออกที่ดีที่สุดหรือใกล้เคียงกับดีที่สุดเมื่อเวลาผ่านไป
ตัวอย่างเช่น ระบบการเพิ่มประสิทธิภาพการใช้จ่ายแบบคลาวด์ใช้ RL เพื่อปรับตามความต้องการทรัพยากรที่มีความผันผวน และเลือกประเภทอินสแตนซ์ ปริมาณ และการกำหนดค่าที่เหมาะสม มันทำการตัดสินใจตามปัจจัยเช่น โครงสร้างพื้นฐานของระบบคลาวด์ การใช้จ่ายและการใช้ประโยชน์ที่สามารถใช้ได้ในปัจจุบัน
การคาดการณ์ทางการเงิน
ไดนามิกของตลาดการเงินมีความซับซ้อน มีคุณสมบัติทางสถิติที่เปลี่ยนแปลงไปตามเวลา อัลกอริทึม RL สามารถเพิ่มประสิทธิภาพผลตอบแทนระยะยาวได้โดยพิจารณาตค่าใช้จ่ายการทำธุรกรรมและปรับให้เข้ากับการเปลี่ยนแปลงของตลาด
ตัวอย่างเช่น อัลกอริทึมสามารถสังเกตกฎและรูปแบบของการลงทุนในตลาดหุ้นก่อนที่จะทดสอบการกระทำและบันทึกรางวัลที่เกี่ยวข้อง โดยสร้างฟังก์ชั่นค่าอย่างมีไดนามิกและพัฒนากลยุทธ์เพื่อเพิ่มผลกำไรสูงสุด
การเรียนรู้แบบเสริมแรงทำงานอย่างไร
กระบวนการเรียนรู้ของอัลกอริทึมการเรียนรู้แบบเสริมแรง (RL) คล้ายกับการเรียนรู้แบบเสริมแรงของสัตว์และมนุษย์ในสาขาจิตวิทยาพฤติกรรม ตัวอย่างเช่น เด็กอาจค้นพบว่าพวกเขาได้รับการยกย่องจากผู้ปกครองเมื่อพวกเขาช่วยพี่น้องหรือทำความสะอาด แต่ได้รับปฏิกิริยาเชิงลบเมื่อโยนของเล่นหรือตะโกน ในไม่ช้าเด็กจะได้เรียนรู้ว่าชุดกิจกรรมใดส่งผลให้ได้รับรางวัลในท้ายที่สุด
อัลกอริทึม RL จะเลียนแบบกระบวนการเรียนรู้ที่คล้ายกัน โดยพยายามทำกิจกรรมต่าง ๆ เพื่อเรียนรู้ค่าลบและบวกที่เกี่ยวข้องเพื่อให้ได้ผลลัพธ์เป็นรางวัล
แนวคิดสำคัญ
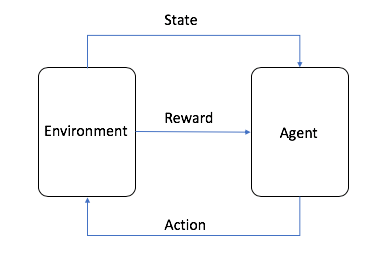
ในการเรียนรู้แบบเสริมแรง มีแนวคิดสำคัญบางประการที่ควรทำความคุ้นเคยด้วย ไม่ว่าจะเป็น:
- เจ้าหน้าที่ คืออัลกอริทึม ML (หรือระบบอิสระ)
- สภาพแวดล้อม คือพื้นที่ปัญหาแบบปรับเปลี่ยนได้พร้อมแอตทริบิวต์ต่าง ๆ เช่น ตัวแปร ค่าขอบเขต กฎ และการกระทำที่ถูกต้อง
- การกระทำเป็นขั้นตอนที่เจ้าหน้าที่ RL ดำเนินการเพื่อนำทางสภาพแวดล้อม
- สถานะ คือสภาพแวดล้อมในช่วงเวลาที่กำหนด
- รางวัล คือค่าบวก ค่าลบ หรือค่าศูนย์ กล่าวอีกนัยหนึ่งคือรางวัลหรือการลงโทษสำหรับการกระทำ
- รางวัลสะสม คือผลรวมของรางวัลทั้งหมดหรือมูลค่าสุดท้าย
พื้นฐานอัลกอริทึม
การเรียนรู้แบบเสริมแรงขึ้นอยู่กับกระบวนการตัดสินใจของ Markov ซึ่งเป็นการสร้างแบบจำลองทางคณิตศาสตร์ของการตัดสินใจที่ใช้ขั้นตอนเวลาที่ไม่ต่อเนื่อง ในทุกขั้นตอน เจ้าหน้าที่จะสร้างการกระทำใหม่ซึ่งส่งผลให้เกิดสภาพแวดล้อมใหม่ ในทำนองเดียวกัน สถานะปัจจุบันนั้นจะมาจากลำดับของการกระทำก่อนหน้านี้
เจ้าหน้าที่จะสร้างชุดกฎหรือนโยบายแบบ if-then ผ่านการทดลองและข้อผิดพลาดในการเคลื่อนย้ายผ่านสภาพแวดล้อม นโยบายจะช่วยตัดสินใจว่าการกระทำใดต่อไปที่ควรทำเพื่อรับรางวัลสะสมที่เหมาะสม เจ้าหน้าที่ต้องเลือกระหว่างการสำรวจสภาพแวดล้อมเพิ่มเติมเพื่อเรียนรู้รางวัลการกระทำของสถานะใหม่หรือเลือกการกระทำที่มีรางวัลสูงที่เรียนรู้จากสถานะที่กำหนด สิ่งนี้เรียกว่า การแลกเปลี่ยนระหว่างการสำรวจกับการแสวงหาผลประโยชน์
อัลกอริทึมการเรียนรู้แบบเสริมแรงมีประเภทอะไรบ้าง
มีอัลกอริทึมต่างๆ ที่ใช้ในการเรียนรู้แบบเสริมแรง (RL) – เช่น Q-learning, วิธีการไล่ระดับนโยบาย, วิธี Monte Carlo, และการเรียนรู้ความแตกต่างชั่วขณะ Deep RL คือการประยุกต์ใช้นิวรัลเน็ตเวิร์กลึกกับการเรียนรู้แบบเสริมแรง ตัวอย่างหนึ่งของอัลกอริทึม RL แบบลึกคือ Trust Region Policy Optimization (TRPO)
อัลกอริทึมทั้งหมดเหล่านี้สามารถแบ่งออกเป็นสองประเภทกว้างๆ
RL ตามแบบจำลอง
RL ตามแบบจำลองมักจะใช้เมื่อสภาพแวดล้อมถูกกำหนดอย่างชัดเจนและไม่เปลี่ยนแปลง และสภาพแวดล้อมที่การทดสอบในโลกจริงเป็นเรื่องยาก
ในตอนแรกเจ้าหน้าที่จะสร้างการแทน (แบบจำลอง) ของสภาพแวดล้อมภายใน โดยใช้กระบวนการนี้เพื่อสร้างรูปแบบนี้
- RL ตามแบบจำลองดำเนินการภายในสภาพแวดล้อมและบันทึกสถานะใหม่และรางวัลตอบแทน
- มันเชื่อมโยงการเปลี่ยนแปลงสถานะของการกระทำกับรางวัลตอบแทน
เมื่อแบบจำลองเสร็จสมบูรณ์ เจ้าหน้าที่จะจำลองลำดับการกระทำตามความน่าจะเป็นของรางวัลสะสมที่ดีที่สุด จากนั้นจะกำหนดค่าให้กับลำดับการกระทำนั้นๆ เจ้าหน้าที่จึงพัฒนากลยุทธ์ที่แตกต่างกันภายในสภาพแวดล้อมเพื่อให้บรรลุเป้าหมายสุดท้ายที่ต้องการ
ตัวอย่าง
ลองพิจารณาหุ่นยนต์ที่กำลังเรียนรู้ที่จะนำทางอาคารใหม่เพื่อไปยังห้องเฉพาะเจาะจงห้องหนึ่ง ในขั้นต้น หุ่นยนต์จะสำรวจได้อย่างอิสระและสร้างแบบจำลองภายใน (หรือแผนที่) ของอาคาร ตัวอย่างเช่น หุ่นยนต์อาจเรียนรู้ว่ามันพบลิฟต์หลังจากก้าวไปข้างหน้า 10 เมตรจากทางเข้าหลัก เมื่อหุ่นยนต์สร้างแผนที่ มันก็จะสามารถสร้างชุดของลำดับเส้นทางที่สั้นที่สุดระหว่างสถานที่ที่แตกต่างกันที่มันไปบ่อยในอาคาร
RL แบบไร้แบบจำลอง
RL แบบไร้แบบจำลองใช้ได้ดีที่สุดเมื่อสภาพแวดล้อมมีขนาดใหญ่ ซับซ้อน และไม่สามารถอธิบายได้โดยง่าย นอกจากนี้ยังเหมาะกับสภาพแวดล้อมที่ไม่รู้จักและมีการเปลี่ยนแปลงอยู่ และการทดสอบตามสภาพแวดล้อมที้ไม่ได้มาพร้อมกับข้อเสียอย่างมีนัยสำคัญ
เจ้าหน้าที่ไม่ได้สร้างแบบจำลองภายในของสภาพแวดล้อมและไดนามิกของมัน แต่จะใช้วิธีการลองผิดลองถูกภายในสภาพแวดล้อม เจ้าหน้าที่ให้คะแนนและบันทึกคู่สถานะและการกระทำ – และลำดับของคู่สถานะและการกระทำ – เพื่อพัฒนานโยบาย
ตัวอย่าง
ลองพิจารณารถยนต์ขับเคลื่อนด้วยตนเองที่ต้องการนำทางไปตามการจราจรในเมือง ถนน รูปแบบการจราจร พฤติกรรมคนเดินเท้า และปัจจัยอื่นๆ นับไม่ถ้วนสามารถทำให้สภาพแวดล้อมมีไดนามิกและมีความซับซ้อนสูง ทีม AI ฝึกอบรมรถในสภาพแวดล้อมจำลองในขั้นเริ่มต้น รถจะกระทำตามสถานะปัจจุบันและได้รับรางวัลหรือบทลงโทษ
เมื่อเวลาผ่านไป โดยการขับรถหลายล้านไมล์ในสถานการณ์เสมือนจริงที่แตกต่างกัน รถจะเรียนรู้ว่าการกระทำใดที่ดีที่สุดสำหรับแต่ละสถานะโดยไม่ต้องสร้างแบบจำลองไดนามิกทั้งหมดของการจราจรทัอย่างชัดเจน เมื่อนำมาใช้ในโลกจริง รถจะใช้นโยบายที่ได้เรียนรู้มา แต่ยังคงปรับแต่งมันด้วยข้อมูลใหม่
อะไรคือความแตกต่างระหว่างแมชชีนเลิร์นนิงแบบเสริมแรง มีผู้ดูแล และไม่มีผู้ดูแล
ในขณะที่การเรียนรู้แบบมีผู้ดูแล การเรียนรู้แบบไม่มีผู้ดูแล และการเรียนรู้แบบเสริมแรง (RL) ล้วนเป็นอัลกอริธึม ML ในด้าน AI แต่ก็มีความแตกต่างระหว่างทั้งสาม
อ่านเกี่ยวกับการเรียนรู้แบบมีผู้ดูแลและแบบไม่มีผู้ดูแล »
การเรียนรู้แบบเสริมแรงเทียบกับการเรียนรู้แบบมีผู้ดูแล
ในการเรียนรู้แบบมีผู้ดูแล คุณกำหนดทั้งอินพุตและเอาต์พุตที่เกี่ยวข้องที่คาดหวัง ตัวอย่างเช่น คุณสามารถจัดสรรชุดรูปภาพที่มีป้ายกำกับว่าสุนัขหรือแมว จากนั้นอัลกอริทึมจะระบุรูปภาพสัตว์รูปใหม่ว่าเป็นสุนัขหรือแมว
อัลกอริธึมการเรียนรู้แบบมีผู้ดูแลจะเรียนรู้รูปแบบและความสัมพันธ์ระหว่างคู่อินพุตและเอาต์พุต จากนั้นพวกมันจะคาดการณ์ผลลัพธ์ตามข้อมูลอินพุตใหม่ จำเป็นต้องมีผู้ดูแล ซึ่งโดยทั่วไปแล้วจะเป็นมนุษย์ เพื่อติดป้ายกำกับบันทึกข้อมูลแต่ละรายการในชุดข้อมูลการฝึกอบรมด้วยเอาต์พุต
ในทางตรงกันข้าม RL มีเป้าหมายสุดท้ายที่กำหนดไว้อย่างชัดเจนในรูปแบบของผลลัพธ์ที่ต้องการ แต่ไม่มีผู้ดูแลคอยติดป้ายกำกับข้อมูลที่เกี่ยวข้องไว้ล่วงหน้า ในระหว่างการฝึกอบรม แทนที่จะพยายามวางแผนอินพุตกับเอาท์พุตที่ทราบ กลับวางแผนอินพุตกับผลลัพธ์ที่เป็นไปได้ ด้วยการให้รางวัลแก่พฤติกรรมที่ต้องการ คุณจะให้ความสำคัญกับผลลัพธ์ที่ดีที่สุด
การเรียนรู้แบบเสริมแรงเทียบกับการเรียนรู้แบบไม่มีผู้ดูแล
อัลกอริธึมการเรียนรู้แบบไม่มีผู้ดูแลจะได้รับอินพุตโดยไม่มีเอาต์พุตที่ระบุในระหว่างกระบวนการฝึกอบรม พวกเขาค้นหารูปแบบและความสัมพันธ์ที่ซ่อนอยู่ภายในข้อมูลโดยใช้วิธีการทางสถิติ ตัวอย่างเช่น คุณสามารถให้เอกสารไว้ชุดหนึ่ง และอัลกอริทึมอาจจัดกลุ่มชุดเอกสารนั้นเป็นหมวดหมู่ต่างๆ ที่อัลกอริทึมระบุตามคำในข้อความ คุณจะไม่ได้รับผลลัพธ์ที่เฉพาะใดๆ ผลลัพธ์จะอยู่ในช่วง
ตรงกันข้าม RL มีเป้าหมายสุดท้ายที่กำหนดไว้ล่วงหน้า แม้ว่าจะใช้แนวทางการสำรวจ แต่การสำรวจก็ได้รับการตรวจสอบและปรับปรุงอย่างต่อเนื่องเพื่อเพิ่มความน่าจะเป็นที่จะบรรลุเป้าหมายสุดท้าย สามารถสอนตัวเองให้เข้าถึงผลลัพธ์ที่เฉพาะเจาะจงได้
ความท้าทายในการเรียนรู้แบบเสริมแรงคืออะไร
แม้ว่าแอปพลิเคชันการเรียนรู้แบบเสริมแรง (RL) อาจเปลี่ยนแปลงโลกได้ แต่การนำอัลกอริทึมเหล่านี้ไปใช้อาจไม่ง่ายเลย
การปฏิบัติจริง
การทดลองกับระบบการให้รางวัลและการลงโทษในการใช้งานจริงอาจไม่สามารถทำได้จริง ตัวอย่างเช่น การทดสอบโดรนในการใช้งานจริงโดยไม่ได้ทดสอบในเครื่องจำลองก่อน จะทำให้มีเครื่องบินเสียหายจำนวนมาก สภาพแวดล้อมในโลกแห่งความเป็นจริงเปลี่ยนแปลงบ่อยครั้ง อย่างมาก และมีการเตือนอย่างจำกัด อาจทำให้อัลกอริธึมมีประสิทธิภาพในทางปฏิบัติจริงได้ยากขึ้น
การตีความ
เช่นเดียวกับสาขาวิทยาศาสตร์อื่นๆ วิทยาศาสตร์ข้อมูลยังพิจารณาการวิจัยเชิงสรุปและการค้นพบเพื่อสร้างมาตรฐานและขั้นตอนต่างๆ นักวิทยาศาสตร์ข้อมูลชอบที่จะรู้ว่าได้ข้อสรุปเฉพาะสำหรับการพิสูจน์และการจำลองแบบอย่างไร
ด้วยอัลกอริธึม RL ที่ซับซ้อน สาเหตุที่ทำให้ลำดับขั้นตอนเฉพาะเกิดขึ้นอาจเป็นเรื่องยากที่จะระบุได้ การกระทำใดในลำดับที่นำไปสู่ผลลัพธ์สุดท้ายที่ดีที่สุด สิ่งนี้อาจเป็นเรื่องยากที่จะอนุมานได้ ซึ่งทำให้เกิดความท้าทายในการดำเนินการ
AWS สามารถช่วยเรียนรู้แบบเสริมแรงได้อย่างไร
Amazon Web Services (AWS) มีข้อเสนอมากมายที่ช่วยคุณพัฒนา ฝึกอบรม และปรับใช้อัลกอริทึมการเรียนรู้แบบเสริมแรง (RL) สำหรับแอปพลิเคชันจากการใช้งานจริง
ด้วย Amazon SageMaker นักพัฒนาและนักวิทยาศาสตร์ข้อมูลสามารถพัฒนาโมเดล RL ที่ปรับขนาดได้อย่างรวดเร็วและง่ายดาย ผสมผสานเฟรมเวิร์กดีปเลิร์นนิง (เช่น TensorFlow หรือ Apache MXNet) ชุดเครื่องมือ RL (เช่น RL Coach หรือ RLlib) และสภาพแวดล้อมเพื่อเลียนแบบสถานการณ์การใช้งานจริง คุณสามารถใช้เพื่อสร้างและทดสอบโมเดลของคุณได้
ด้วย AWS RoboMaker นักพัฒนาสามารถเรียกใช้ ปรับขนาด และจำลองอัตโนมัติด้วยอัลกอริธึม RL สำหรับหุ่นยนต์ได้โดยไม่ต้องใช้โครงสร้างพื้นฐานใดๆ
สัมผัสประสบการณ์จริงกับ AWS DeepRacer รถแข่งระบบอัตโนมัติขนาด 1/18 มีสภาพแวดล้อมระบบคลาวด์ที่ได้รับการกำหนดค่าอย่างสมบูรณ์ซึ่งคุณสามารถใช้ฝึกโมเดล RL และการกำหนดค่านิวรัลเน็ตเวิร์กได้
เริ่มต้นใช้งานการเรียนรู้แบบเสริมแรงบน AWS โดยสร้างบัญชีวันนี้