Comment a été ce contenu ?
- Apprendre
- Création d’applications d’IA générative pour votre start-up
Création d’applications d’IA générative pour votre start-up
Les récentes avancées de l’IA générative améliorent les outils susceptibles d’aider les start-ups dans la création, la mise à l’échelle et l’innovation rapides. Cette adoption généralisée et cette démocratisation du machine learning (ML), en particulier avec l’ architecture du réseau neuronal de transformation, constituent un point d’inflexion technologique passionnant. Avec les bons outils, les start-ups peuvent développer de nouvelles idées ou adapter leurs produits existants afin de tirer parti des avantages de l’IA générative pour leurs clients.
Êtes-vous prêt à créer une application d’IA générative pour votre start-up ? Passons d’abord en revue les concepts, les idées fondamentales et les approches courantes relatifs à la création d’applications d’IA générative.
Que sont les applications d’IA générative ?
Les applications d’IA générative sont des programmes basés sur un type d’IA capable de créer de nouveaux contenus et idées, notamment des conversations, des histoires, des images, des vidéos, du code et de la musique. Comme toutes les applications d’IA, les applications d’IA générative sont alimentées par des modèles de ML pré-entraînés sur de grandes quantités de données, communément appelés modèles de fondation (FM).
Amazon CodeWhisperer est un exemple d’application d’IA générative. Il s’agit d’un assistant de codage d’IA qui aide les développeurs à créer des applications plus rapidement et de manière plus sécurisée en fournissant des suggestions de code d’ensemble de lignes et de fonctions complètes dans votre environnement de développement intégré (IDE). CodeWhisperer est entraîné sur des milliards de lignes de code et peut générer instantanément des suggestions de code allant d’extraits à des fonctions complètes, suivant vos commentaires et le code existant. Les start-ups peuvent employer les crédits AWS Activate avec le niveau professionnel CodeWhisperer ou commencer par le niveau Individual, qui propose une utilisation gratuite.
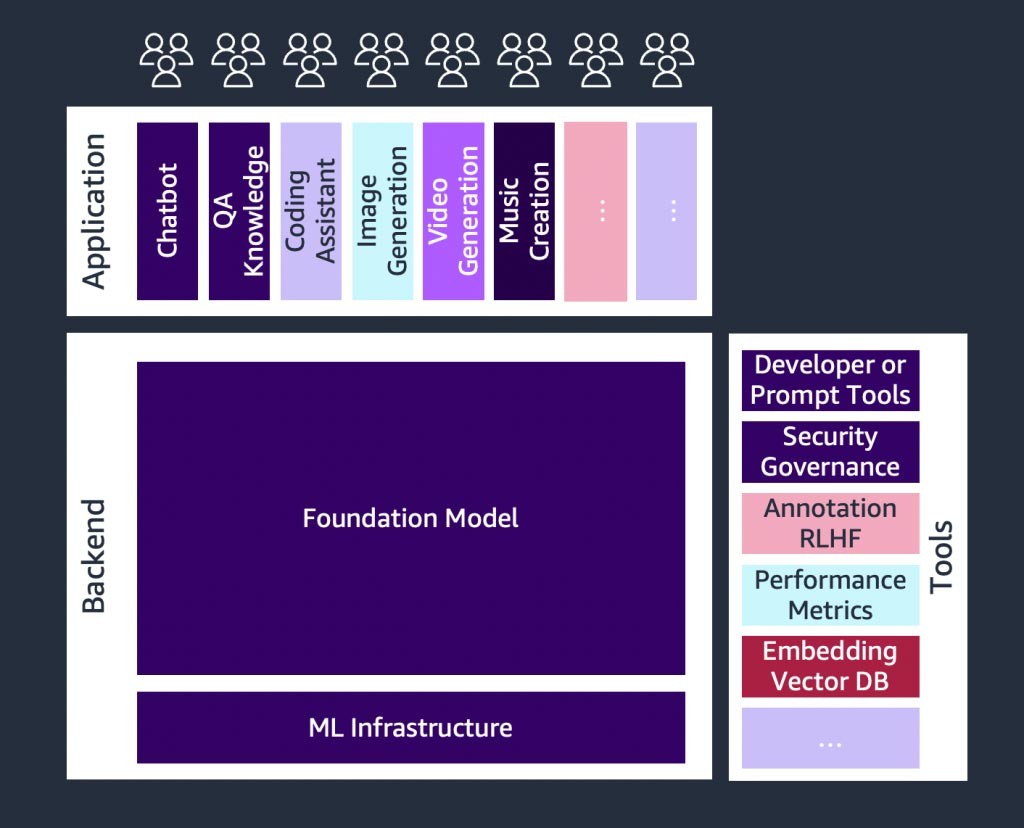
Le paysage en évolution rapide de l’IA générative
Une croissance rapide s’observe dans les start-ups d’IA générative, ainsi que dans les start-ups spécialisées dans la création d’outils visant à en simplifier l'adoption. Des outils tels que LangChain, un cadre open source permettant de développer des applications alimentées par des modèles de langage, rendent l’IA générative plus accessible à un plus grand nombre d’organisations, ce qui accélère son adoption. Ces outils incluent également l’ingénierie de requête, l’augmentation de services (tels que les outils d’intégration ou les bases de données vectorielles), la surveillance des modèles, la mesure de la qualité des modèles, les barrières de protection, l’annotation des données, l’apprentissage par renforcement à partir de la rétroaction humaine (RLHF) et plus encore.
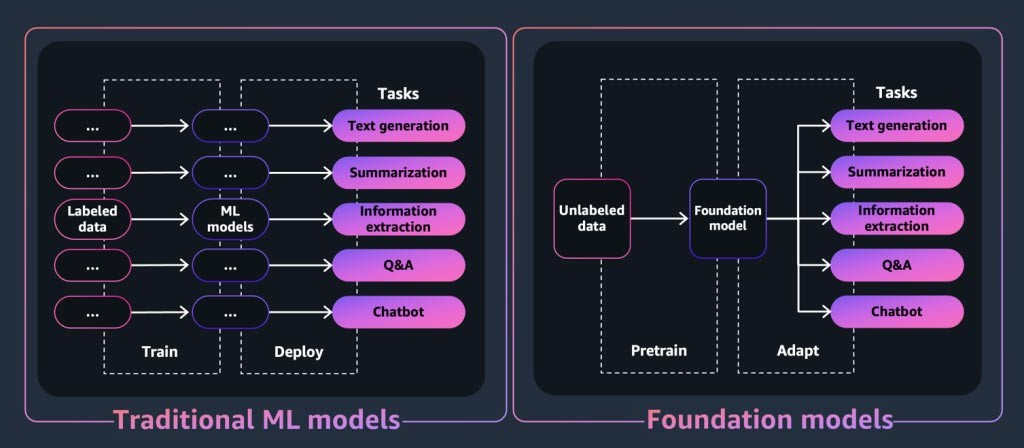
Présentation des modèles de fondation
Les modèles de fondation sont au cœur des applications ou des outils d’IA générative. Il s’agit d’une classe de puissants modèles de machine learning qui se différencient par leur capacité à être pré-entraînés sur de grandes quantités de données afin d’effectuer un large éventail de tâches en aval. Ces tâches incluent la génération de texte, la synthèse, l’extraction d’informations, les questions-réponses ou les chatbots. En revanche, les modèles ML traditionnels sont entraînés pour effectuer une tâche spécifique à partir d’un jeu de données.
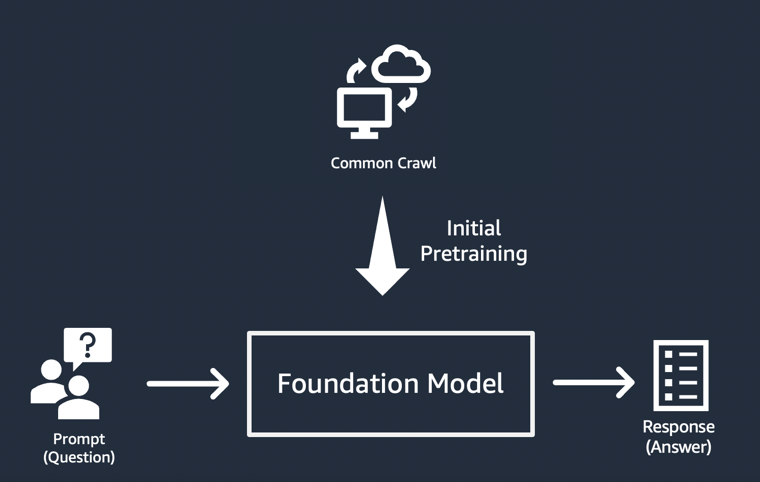
Alors, comment un modèle de fondation « génère-t-il » les résultats qui font la réputation des applications d’IA générative ? Ces capacités résultent de modèles d’apprentissage et de relations qui permettent au FM de prédire l’élément ou les éléments suivants d’une séquence ou d’en générer un nouveau :
- Dans les modèles de génération de texte, les FM produisent le mot ou la phrase suivant ou la réponse à une question.
- Pour les modèles de génération d'images, les FM produisent une image basée sur le texte.
- Pour une entrée d’image, les FM produisent l’image, l’animation ou l’image 3D pertinente ou agrandie suivante.
Dans chaque cas, le modèle commence par un vecteur de départ dérivé d’une « instruction » : les instructions décrivent la tâche que le modèle doit effectuer. La qualité et le détail (également appelés « contexte ») de l’instruction déterminent la qualité et la pertinence du résultat.
La mise en œuvre la plus simple des applications d’IA générative
L’approche la plus simple pour créer une application d’IA générative consiste à utiliser un modèle de fondation adapté aux instructions et à fournir une instruction pertinente (« ingénierie de requête ») à l’aide de l’apprentissage sans exemple ou avec quelques exemples. Un modèle adapté aux instructions (tel que FLAN T5 XXL, Open-Llama ou Falcon 40B Instruct) utilise sa compréhension des tâches ou des concepts connexes pour générer des prédictions à la suite d’instructions. Voici quelques exemples d’instructions :
Apprentissage sans exemple
Titre : \« De nouvelles installations en vue pour l’université » \\n Imaginez l’article à partir du titre fictif ci-dessus.\n
Apprentissage avec quelques exemples
Génial ! // Positif
Terrible ! // Négatif
Ce film était nul ! // Négatif
Quelle horrible émission ! //
RÉPONSE : négatif
Les start-ups, en particulier, peuvent tirer parti du déploiement rapide, de la réduction au minimum des besoins en données et de l’optimisation des coûts résultant de l’utilisation d’un modèle adapté aux instructions.
Pour en savoir plus sur les facteurs à prendre en compte lors du choix d’un modèle de fondation, consultez Sélection du modèle de fondation approprié pour votre start-up.
Personnalisation des modèles de fondation
Le recours à l’ingénierie de requête sur les modèles adaptés aux instructions ne permet pas de résoudre tous les cas d’utilisation. Voici des exemples de raisons de personnaliser un modèle de fondation pour votre start-up :
- Ajout d’une tâche spécifique (telle que la génération de code) au modèle de fondation
- Génération de réponses en fonction du jeu de données exclusif de votre entreprise
- Recherche de réponses générées à partir de jeux de données de meilleure qualité que ceux utilisés pour pré-entraîner le modèle
- Réduction des « hallucinations », c’est-à-dire les résultats qui ne sont ni corrects ni raisonnables sur le plan factuel
Il existe trois techniques courantes pour personnaliser un modèle de fondation.
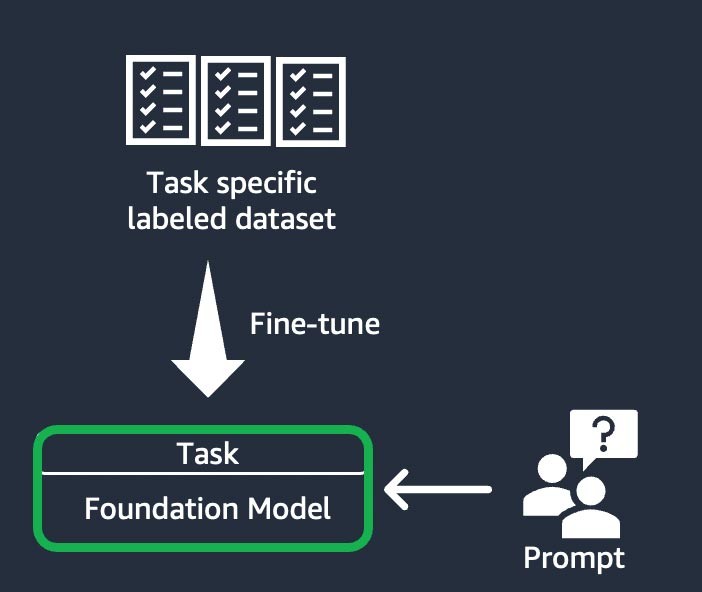
Affinage basé sur des instructions
Cette technique consiste à entraîner le modèle de fondation à effectuer une tâche spécifique, en fonction d’un jeu de données étiqueté propre à la tâche. Un jeu de données étiqueté se compose de paires d’instructions et de réponses. Cette technique de personnalisation est avantageuse pour les start-ups qui souhaitent personnaliser leur FM rapidement et avec un jeu données minimal : l’entraînement nécessite moins de jeux de données et d’étapes. Les pondérations du modèle sont mises à jour en fonction de la tâche ou de la couche que vous affinez.
Adaptation au domaine (également connue sous le nom de « pré-entraînement poussé »)
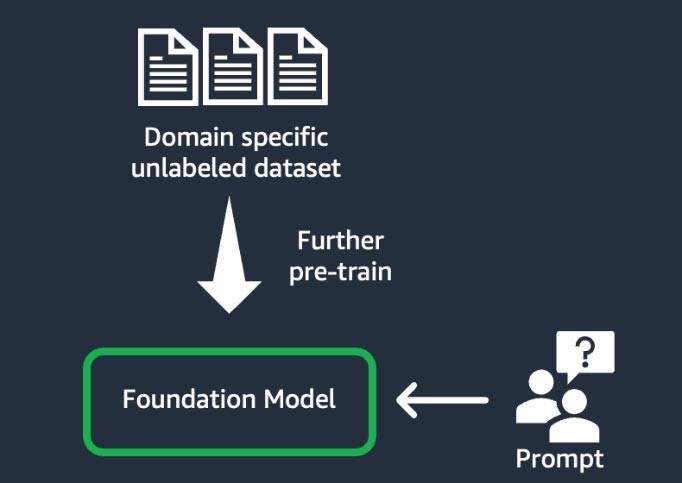
Cette technique consiste à entraîner le modèle de fondation à l’aide d’un vaste « corpus » (c’est-à-dire un ensemble de supports d’entraînement) de données non étiquetées spécifiques à un domaine (connue sous le nom d’« apprentissage auto-supervisé »). Cette technique convient aux cas d’utilisation qui incluent un jargon spécifique à un domaine et des données statistiques inédites dans le modèle de fondation existant. Par exemple, les start-ups qui développent une application d’IA générative pour travailler avec des données exclusives du domaine de la finance peuvent tirer parti du pré-entraînement poussé du FM sur le vocabulaire personnalisé et de la « création de jetons », un processus qui consiste à décomposer du texte en plus petites unités appelées jetons.
Pour améliorer la qualité, certaines start-ups mettent en œuvre des techniques d’apprentissage par renforcement à partir de la rétroaction humaine (RLHF) dans le cadre de ce processus. De plus, un affinage en fonction des instructions est nécessaire pour peaufiner une tâche spécifique. Il s’agit d'une technique coûteuse et chronophage par rapport aux autres. Les pondérations du modèle sont mises à jour sur toutes les couches.
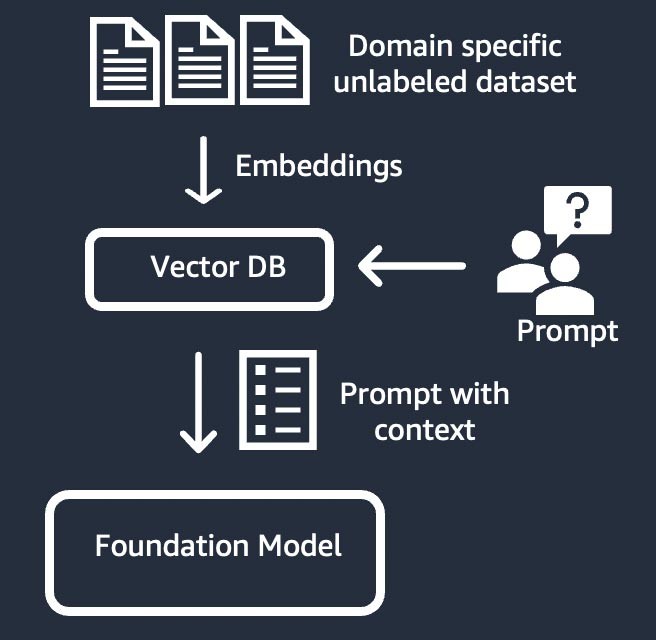
Extraction d’informations (également connue sous le nom de génération augmentée par extraction ou RAG, Retrieval-Augmented Generation)
Cette technique complète le modèle de fondation avec un système d’extraction d’informations basé sur une représentation vectorielle dense. Les connaissances du domaine fermé ou les données exclusives sont soumises à un processus d’intégration de texte pour générer une représentation vectorielle du corpus, avant leur stockage dans une base de données vectorielles. Un résultat de recherche sémantique basé sur la requête de l’utilisateur devient le contexte de l’instruction. Le modèle de fondation est utilisé pour générer une réponse en fonction de l’instruction avec le contexte. La pondération du modèle de fondation n’est pas mise à jour dans le cadre de cette technique.
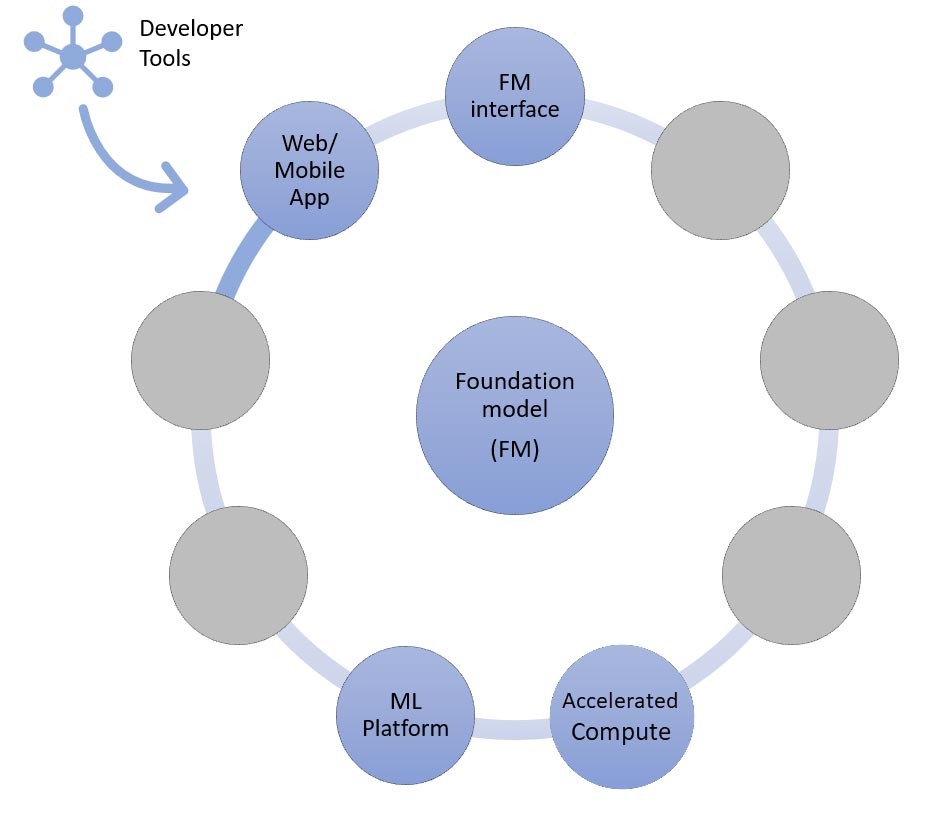
Composants d’une application d’IA générative
Dans les sections ci-dessus, nous avons examiné différentes approches que les start-ups peuvent adopter avec les modèles de fondation en matière de création d’applications d’IA générative. Voyons maintenant la place que ces modèles de fondation occupent parmi les composants types requis pour créer une application d’IA générative.
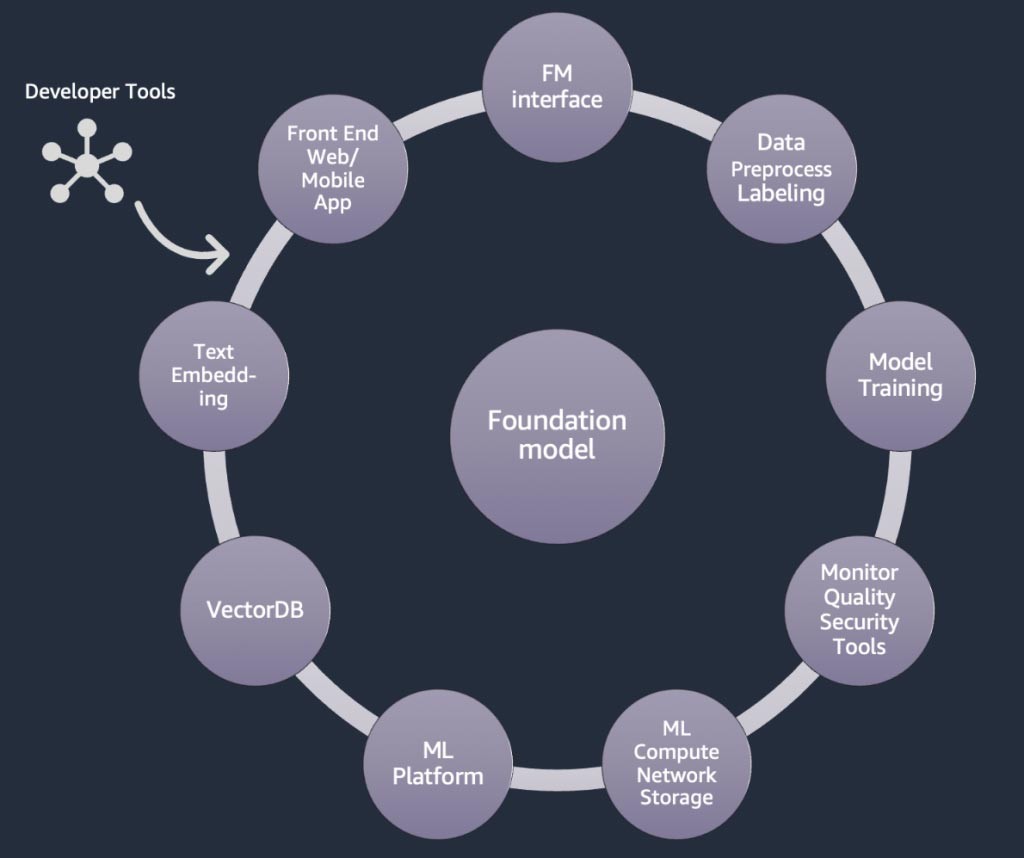
À la base se trouve un modèle de fondation (au centre). L’approche la plus simple décrite précédemment dans ce blog s’articule autour d’une application web ou mobile (en haut à gauche) qui accède au modèle de fondation via une API (en haut). Cette API consiste soit en un service géré par un fournisseur de modèles, soit en une interface auto-hébergée utilisant un modèle open source ou exclusif. Dans le cas de l’auto-hébergement, vous avez peut-être besoin d’une plateforme de machine learning prise en charge par des instances de calcul accéléré pour héberger le modèle.
Selon la technique RAG, vous devez ajouter un point de terminaison d’intégration de texte et une base de données vectorielles (à gauche et en bas à gauche). Les deux sont fournis sous forme de service d’API ou sont auto-hébergés. Le point de terminaison d’intégration de texte est soutenu par un modèle de fondation, dont le choix dépend de la logique d’intégration et de la prise en charge de la création de jetons. Tous ces composants sont interconnectés à l’aide d'outils de développement, qui fournissent le cadre nécessaire au développement d’applications d’IA générative.
Pour finir, lors du choix des approches de personnalisation reposant sur l’affinage ou le pré-entraînement poussé d’un modèle de fondation (à droite), vous avez besoin de composants qui facilitent le pré-traitement et l’annotation des données (en haut à droite), ainsi que d’une plateforme de ML (en bas) pour exécuter la tâche d’entraînement sur des instances de calcul accéléré spécifiques. Certains fournisseurs de modèles prennent en charge l’affinage basé sur les API. Dans de tels cas, vous n’avez pas à vous soucier de la plateforme de ML ni du matériel sous-jacent.
Quelle que soit l’approche de personnalisation, vous souhaiterez peut-être également intégrer des composants qui fournissent des outils de surveillance et de sécurité ainsi que des indicateurs de qualité (en bas à droite).
Quels services AWS dois-je utiliser pour créer mon application d’IA générative ?
La figure 9 ci-dessous associe chaque composant avec le ou les services AWS correspondants. Notez qu’il s’agit d’un ensemble organisé de services AWS exploités avantageusement par les start-ups. Cependant, d’autres services AWS sont également disponibles.
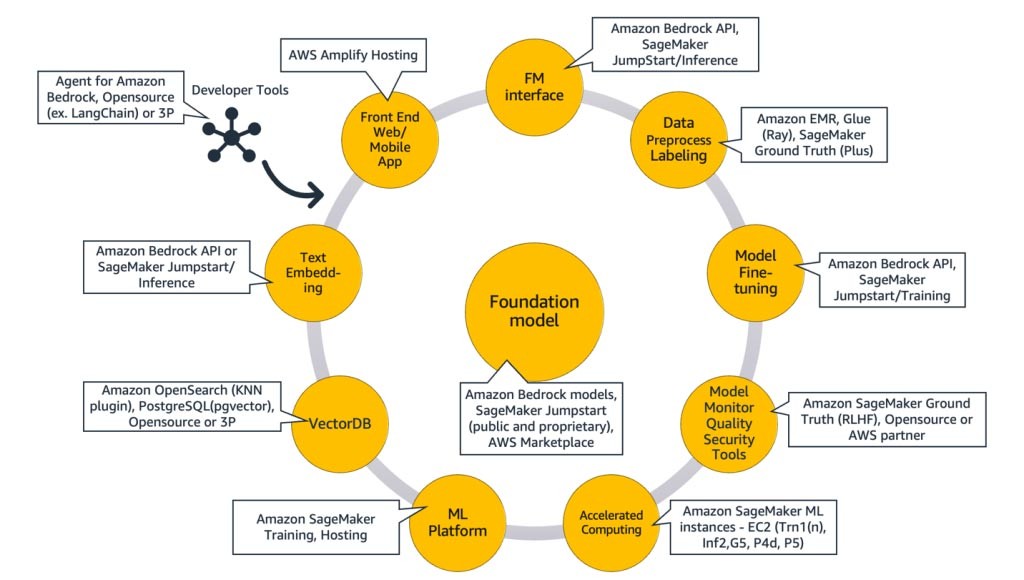
Dans le détail, je vais commencer par associer les services AWS aux composants courants d'une application d’IA générative. Je vais ensuite présenter les services AWS qui correspondent aux autres composants de la figure 9, en fonction des approches que vous utilisez pour mettre en œuvre votre application.
Composants courants
Les composants courants d’une application d’IA générative sont le modèle de fondation (FM), son interface et éventuellement la plateforme de machine learning (ML) et le calcul accéléré. Vous pouvez obtenir ces outils grâce aux offres gérées disponibles sur AWS :
Amazon Bedrock (modèle de fondation et composants d’interface)
Amazon Bedrock, un service entièrement géré qui met à disposition les modèles de fondation des principales start-ups d’IA (Jurassic d’AI21, Claude d’Anthropic, Command and Embedding de Cohere, modèles SDXL de Stability) et d’Amazon (modèles Titan Text et Embeddings), et ce, au moyen d’une API. Vous pouvez ainsi choisir parmi une large gamme de FM le modèle le mieux adapté à votre cas d’utilisation. Amazon Bedrock offre un accès par API ou sans serveur à un ensemble de modèles de fondation pour fournir trois fonctionnalités : intégration de texte, instruction/réponse et affinage (sur certains modèles).
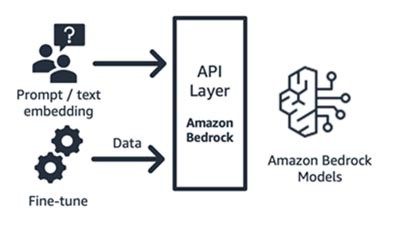
Amazon Bedrock est parfaitement adapté aux start-ups de consommation d’applications ou de modèles qui développent des services à valeur ajoutée (ingénierie de requête, génération augmentée par extraction, etc.) autour d’un modèle de fondation de leur choix. Le service utilise un modèle de tarification à l’utilisation, habituellement exprimé en unité de millions de jetons traités. Amazon Bedrock fait l’objet d’une disponibilité générale. Toutefois, certaines des fonctionnalités abordées dans ce blog sont en version préliminaire privée. Pour en savoir plus, cliquez ici.
Amazon SageMaker JumpStart (modèle de fondation et composants d’interface)
AWS intègre des fonctionnalités d’IA générative à Amazon SageMaker Jumpstart : un hub de modèles de fondation qui contient à la fois des modèles accessibles au public et des modèles exclusifs, des solutions de démarrage rapide et des exemples de blocs-notes pour déployer et affiner les modèles. Lorsque vous déployez ces modèles, ils créent un point de terminaison d’inférence en temps réel auquel vous pouvez accéder directement à l'aide du kit SDK ou de l’API SageMaker. Vous pouvez aussi mettre en interface le point de terminaison du modèle de fondation de SageMaker avec AWS API Gateway et une logique de calcul légère dans une fonction AWS Lambda . Vous pouvez également tirer parti de certains de ces modèles pour intégrer du texte.
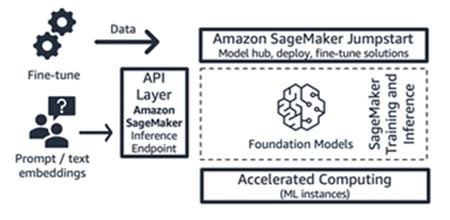
Le point de terminaison d'inférence et les tâches d'entraînement par affinage s'exécutent tous sur les instances de ML gérées de votre choix (voir Calcul accéléré dans la figure 9) en utilisant SageMaker comme plateforme de ML (voir Plateforme de machine learning dans la figure 9). SageMaker Jumpstart convient parfaitement aux start-ups de consommation d'applications ou de modèles qui souhaitent mieux contrôler leur infrastructure et qui possèdent des compétences et des connaissances modérées en ML et en infrastructure, respectivement. Le service utilise un modèle de tarification à l'utilisation, généralement exprimé en heures d'instance. Tous les modèles et solutions de cette offre font l'objet d'une disponibilité générale.
Entraînement et inférence Amazon SageMaker (plateforme de ML)
Les start-ups peuvent tirer parti des fonctionnalités d’entraînement et d’inférence d'Amazon SageMaker pour bénéficier de capacités avancées telles que l’entraînement distribué, l’inférence distribuée et les points de terminaison multimodèles, pour ne citer que ces quelques exemples. Vous pouvez importer des modèles de fondation depuis le hub de modèles de votre choix, par exemple SageMaker JumpStart, Hugging Face ou AWS Marketplace, ou vous pouvez créer de toutes pièces votre propre modèle de fondation.
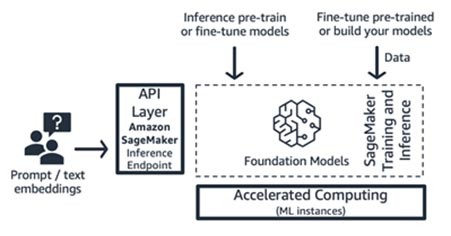
SageMaker convient parfaitement aux créateurs d’applications d’IA générative complètes (des fournisseurs de modèles aux consommateurs de modèles) ou aux fournisseurs de modèles dont les équipes possèdent des compétences avancées en ML et en prétraitement des données. SageMaker propose également un modèle de tarification à l’utilisation, généralement exprimé en heures d’instance.
AWS Trainium et AWS Inferentia (calcul accéléré)
En avril 2023, AWS a annoncé la disponibilité générale des instances Trn1n Amazon EC2 optimisées par AWS Trainium et des instances Inf2 Amazon EC2 alimentées par AWS Inferentia2. Vous pouvez tirer parti des accélérateurs sur mesure d’AWS (AWS Trainium et AWS Inferentia) en utilisant SageMaker comme plateforme de ML.
D’après les tests d'analyse comparative des charges de travail d’inférence, les instances Inf2 offrent des coûts inférieurs de 52 % par rapport aux instances Amazon EC2 comparables optimisées pour l'inférence. Je suggère d’examiner les cycles de développement rapides du kit SDK AWS Neuron, dans lesquels AWS ajoute environ chaque mois une nouvelle architecture de modèle à sa matrice de prise en charge à la fois pour l’entraînement et l’inférence.
Approches pour créer des applications d’IA générative
Examinons maintenant chacun des composants de la figure 9 du point de vue de la mise en œuvre.
Approche d’inférence d’apprentissage sans exemple ou avec quelques exemples
Comme nous l’avons vu ci-dessus, l’apprentissage sans exemple ou avec quelques exemples est l’approche la plus simple pour créer une application d’IA générative. Pour créer des applications basées sur cette approche, vous n’avez besoin que des services relatifs aux quatre composants courants (le modèle de fondation, son interface, la plateforme de ML et le calcul), de votre code personnalisé pour générer des instructions et d’une application web ou mobile frontale.
Pour en savoir plus sur la sélection d’un modèle de fondation via Amazon Bedrock ou Amazon SageMaker JumpStart, reportez-vous aux lignes directrices sur la sélection de modèles ici.
Le code personnalisé peut tirer parti d’outils de développement tels que LangChain pour les modèles et la génération d’instructions. La communauté LangChain a déjà ajouté la prise en charge des points de terminaison Amazon Bedrock, Amazon API Gateway et SageMaker. Pour rappel, vous pouvez également utiliser l’assistant de codage AWS Amazon CodeWhisperer pour améliorer l’efficacité des développeurs.
Les start-ups qui créent une application web ou une application mobile frontale peuvent facilement démarrer et effectuer une mise à l’échelle à l’aide d’ AWS Amplify et héberger ces applications web de manière rapide, sécurisée et fiable avec AWS Amplify Hosting.
Consultez cet exemple d’apprentissage sans exemple basé sur SageMaker Jumpstart.
L’approche d’extraction d’informations
Comme indiqué, l’une des façons dont votre start-up peut personnaliser les modèles de fondation consiste à les optimiser à l’aide d’un système d’extraction d’informations, plus communément appelé génération augmentée par extraction. Cette approche fait appel à tous les composants mentionnés dans l’apprentissage sans exemple et avec quelques exemples, au point de terminaison d’intégration de texte et à la base de données vectorielles.
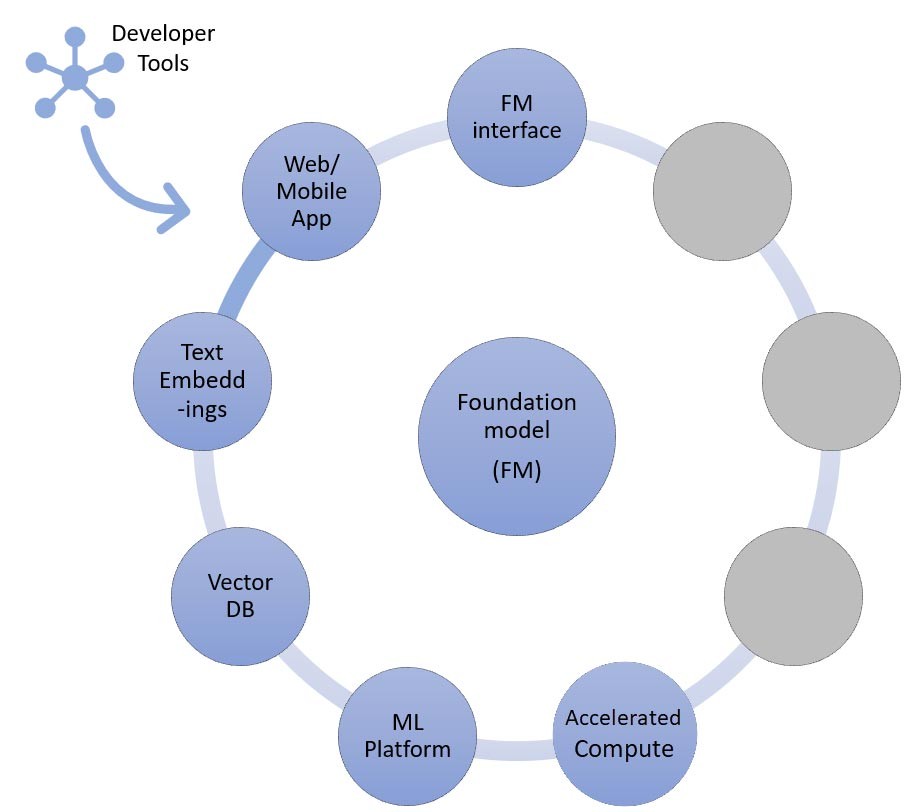
Les options de points de terminaison d’intégration de texte varient en fonction du service géré AWS que vous avez sélectionné :
- Amazon Bedrock offre un grand modèle de langage (LLM) d’intégration qui traduit les entrées de texte (mots, phrases ou éventuellement importantes unités de texte) en représentations numériques (appelées intégrations) contenant le sens sémantique du texte.
- Si vous utilisez SageMaker JumpStart, vous pouvez héberger un modèle d’intégration tel que GPT-J 6B ou tout autre LLM de votre choix à partir du hub de modèles. Le point de terminaison SageMaker peut être invoqué par le kit SDK SageMaker ou Boto3 pour traduire les entrées de texte en intégrations.
Les intégrations peuvent ensuite être stockées dans un entrepôt de données vectorielles afin de permettre des recherches sémantiques à l’aide de l’extension pgvector d’ Amazon RDS for PostgreSQL ou du plug-in k-NN d’ Amazon OpenSearch Service . Les start-ups choisissent l’un ou l’autre en fonction du service qui leur convient le mieux. Dans certains cas, elles utilisent des bases de données vectorielles natives de l’IA open source ou mises au point par les partenaires AWS. Pour obtenir des conseils sur la sélection de l’entrepôt de données vectorielles, je vous recommande de consulter l’article de log The role of vector datastores in IA générative applications.
Dans cette approche également, les outils de développement jouent un rôle central. Ils fournissent un cadre prêt à l’emploi simple, des modèles d’instructions et une large prise en charge des intégrations.
En guise de perspective, vous pouvez également tirer parti des agents d’Amazon Bedrock, une nouvelle fonctionnalité destinée aux développeurs qui peut gérer les appels d’API vers les systèmes de votre entreprise.
Consultez cet exemple d’utilisation de la génération augmentée par extraction avec des modèles de fondation d’Amazon SageMaker Jumpstart.
L’approche d’affinage ou de pré-entraînement poussé
À présent, nous allons associer les composants aux services AWS nécessaires à la dernière approche pour mettre en œuvre une application d’IA générative : affiner ou pré-entraîner un modèle de fondation. Cette approche implique tous les composants abordés dans le cadre de l’apprentissage sans exemple ou avec quelques exemples ainsi que le prétraitement des données et l’entraînement des modèles.
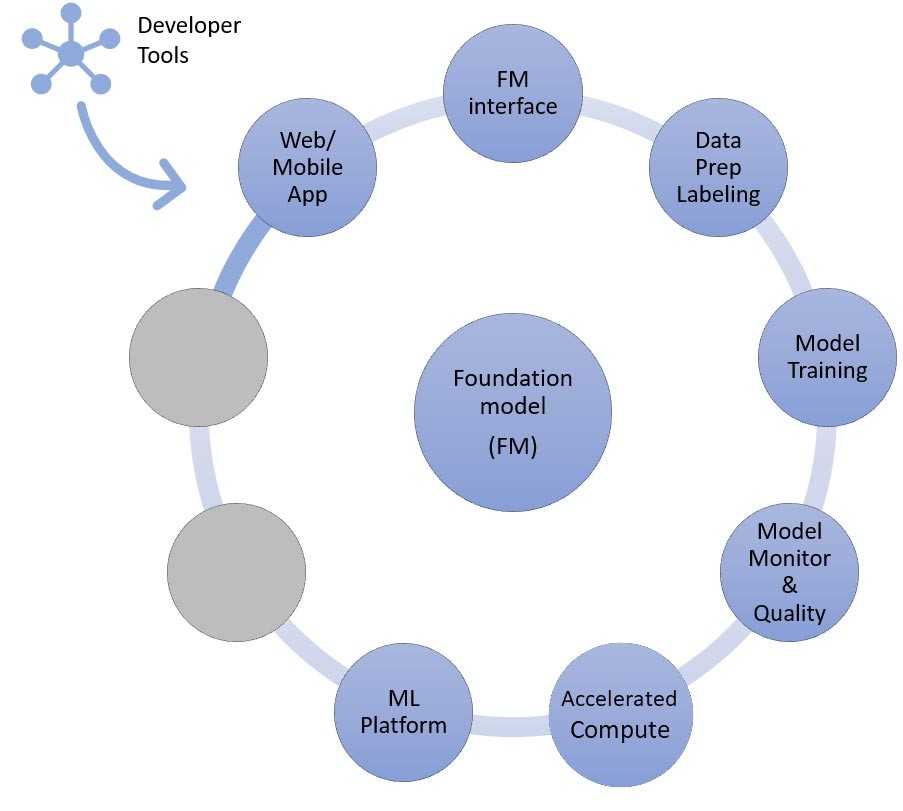
La préparation des données (parfois appelée prétraitement ou annotation) est particulièrement importante lors de l’affinage, lorsque vous avez besoin de plus petits jeux de données étiquetés. Les start-ups peuvent démarrer facilement à l’aide d’ Amazon SageMaker Data Wrangler. Ce service permet de réduire de plusieurs semaines à quelques minutes le temps nécessaire pour regrouper et préparer les données tabulaires et d’images pour le machine learning. Vous pouvez également tirer parti de la fonctionnalité de pipeline d’inférence de ce service pour associer le flux de travail de prétraitement aux tâches d’entraînement ou d’affinage.
Si votre start-up a besoin de pré-traiter un énorme corpus de jeux de données non structurés et non étiquetés dans votre lac de données sur Amazon S3, plusieurs options s’offrent à vous :
- Si vous recourez à Python et à des bibliothèques Python courantes, il est recommandé d’utiliser AWS Glue pour Ray. AWS Glue emploie Ray, un cadre de calcul unifié open source servant à mettre à l’échelle les charges de travail Python.
- Amazon EMR peut également aider à traiter de grandes quantités de données à l’aide d'outils open source comme Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi et Presto.
Pour ce qui est du volet d’entraînement de modèles de cette approche, Amazon Bedrock vous permet de personnaliser en privé les FM avec vos propres données. Le service gère vos FM à grande échelle sans avoir à s’occuper de l’infrastructure (c’est la méthode d’affinage basée sur l’API). L’approche SageMaker JumpStar fournit également une solution de démarrage rapide permettant d’affiner en privé (sur certains modèles) les instructions ou l’adaptation au domaine à l’aide de vos propres données. Vous pouvez modifier le script d’entraînement groupé de SageMaker JumpStart en fonction de vos besoins ou importer vos propres scripts d’entraînement pour les modèles open source et les soumettre en tant que tâche d’entraînement de SageMaker. Si vous devez effectuer un pré-entraînement poussé du modèle (généralement pour les modèles open source), vous pouvez utiliser les bibliothèques d’entraînement distribué de SageMaker pour accélérer et utiliser efficacement toutes les GPU d’une instance de ML.
En outre, vous pouvez également envisager d’utiliser la génération de données entièrement gérée, les services d’annotation de données et le développement de modèles avec la technique d’apprentissage par renforcement à partir de la rétroaction humaine à l’aide d’ Amazon SageMaker Ground Truth Plus.
Exemple d’architecture
Alors, à quoi ressemblent tous ces composants lors de la réalisation d’un cas d’utilisation de l’IA générative ? Chaque start-up a un cas d’utilisation différent et des approches uniques pour résoudre des problèmes concrets. Cependant, l’un des thèmes récurrents ou des points de départ communs en ce qui concerne la création d’applications d’IA générative réside dans l’approche de génération augmentée par extraction. Après avoir connecté tous les services AWS décrits ci-dessus, nous obtenons une architecture similaire à ceci :
Pipeline d’ingestion : les données spécifiques au domaine ou exclusives sont pré-traitées sous forme de données texte. Elles sont traitées par lots (stockées dans Amazon S3) ou diffusées en continu (à l’aide d’ Amazon Kinesis) au fur et à mesure de leur création ou de leur mise à jour dans le cadre du processus d’intégration, puis stockées dans une représentation vectorielle dense.

Pipeline d’extraction : l’interrogation par un utilisateur des données exclusives stockées sous forme de représentation vectorielle entraîne l’extraction des documents associés à l’aide de la méthode des k plus proches voisins (k-NN) ou de la recherche sémantique. Ces documents sont ensuite décodés à nouveau en texte clair. La sortie sert de contexte riche et dense à l’instruction.

Pipeline de génération de résumés : le contexte est ajouté à l’instruction avec la requête utilisateur d’origine pour obtenir un aperçu ou un résumé du document extrait.

Toutes ces couches peuvent être créées avec quelques lignes de code à l’aide d'outils de développement tels que LangChain.
Conclusion
Voici une façon de créer une application d’IA générative de bout en bout à l’aide des services AWS. Les services AWS que vous sélectionnez varient en fonction de votre cas d’utilisation ou de votre approche de personnalisation. Restez informé des versions, solutions et blogs d’AWS les plus récents sur l’IA générative en ajoutant ce lien à vos favoris.
Créons des applications d'IA générative sur AWS ! Lancez votre parcours vers l'IA générative avec AWS Activate, un programme gratuit spécialement conçu pour les startups et les entrepreneurs en herbe qui fournit les ressources nécessaires pour démarrer sur AWS.

Hrushikesh Gangur
Hrushikesh Gangur est l'un des principaux architectes de solutions pour les startups d'intelligence artificielle et de machine learning. Il possède une expertise à la fois dans le machine learning et les services de mise en réseau d’AWS. Il aide les startups à créer une IA générative, des véhicules autonomes et des plateformes de ML afin de leur permettre de gérer leur activité de manière efficiente et efficace sur AWS.
Comment a été ce contenu ?