- AWS Solutions Library›
- Guidance for Airport Data Management on AWS
Guidance for Airport Data Management on AWS
Enhance the traveler experience and optimize airport operations with a data management solution built on AWS
Overview
How it works
Enhanced traveler experience
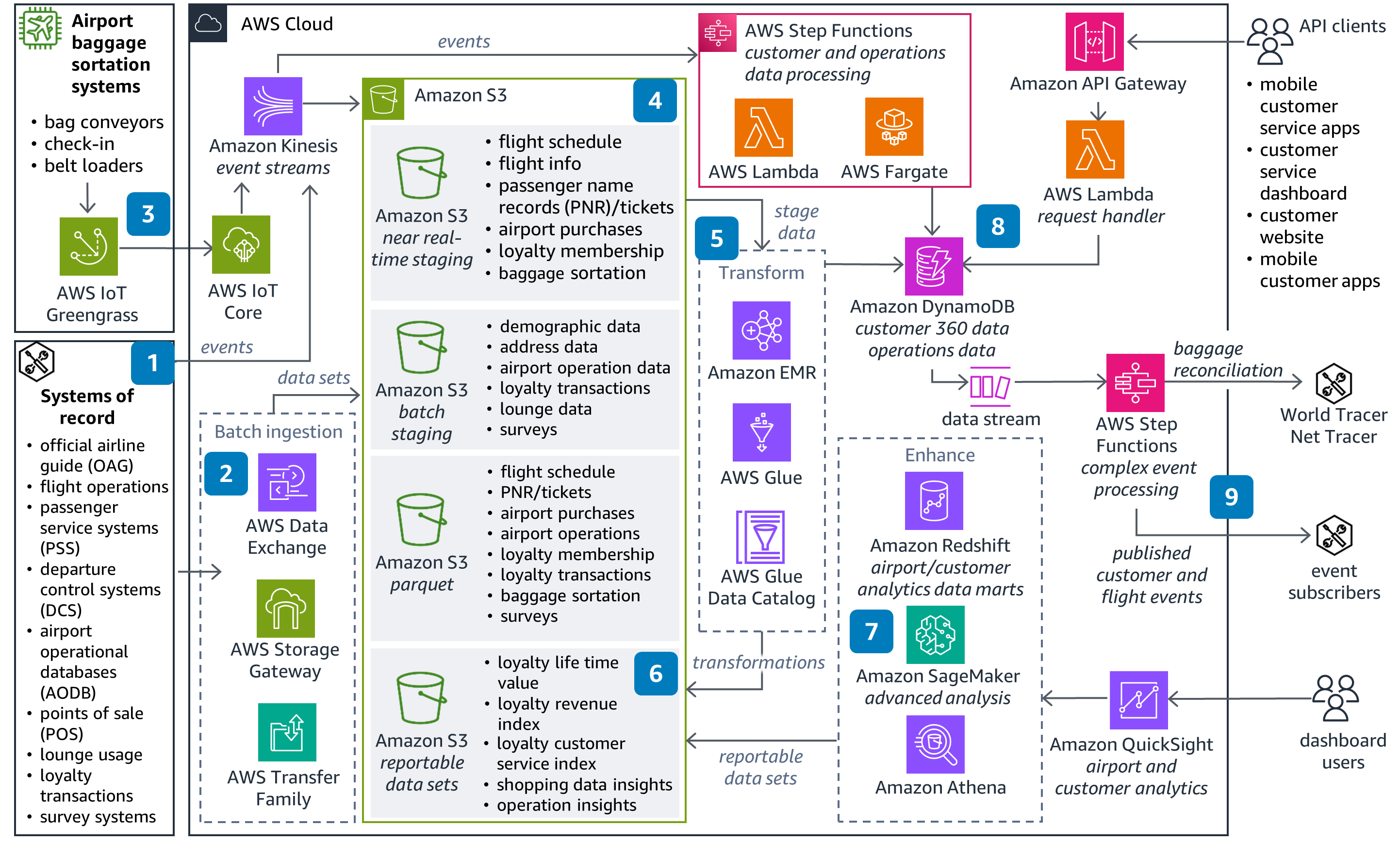
This diagram shows how to build a data management system that will generate meaningful insights with information from airlines and vendors to enhance the traveler experience.
Optimizing operations
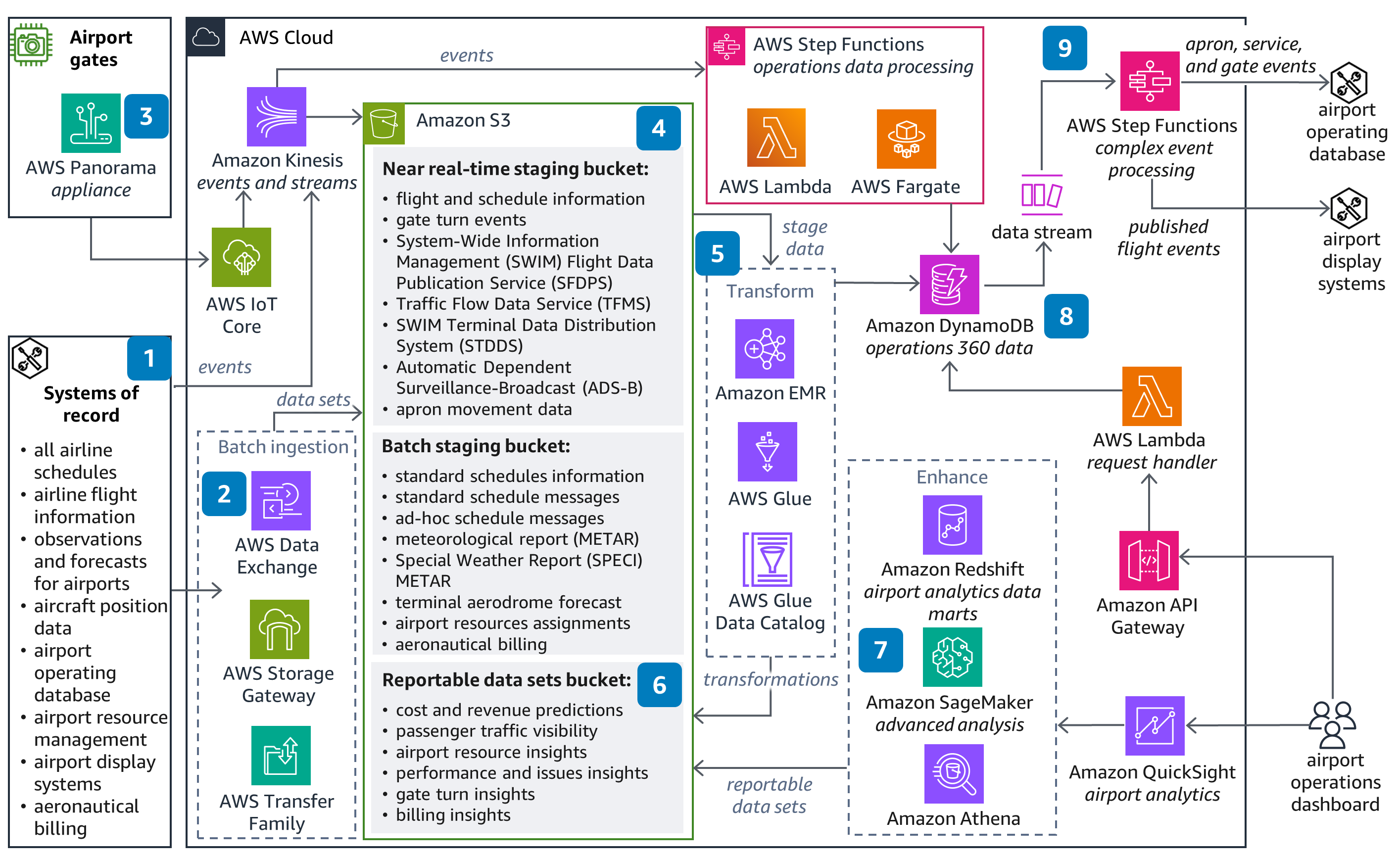
This diagram shows how to build a data management system to monitor airport operations in near real-time. It can be used to predict costs, revenue, turnaround times, and potential delays using open data standards, purpose-built databases, and an extensive serverless architecture.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
To safely operate this Guidance, use Amazon CloudFormation and deploy in your cloud environment. CloudFormation helps you scale your infrastructure and manage your resources through a single operation. We also recommend you use Amazon CloudWatch to increase your observability with application and service-level metrics, personalized dashboards, and logs.
For secure authentication and authorization, this Guidance uses AWS Identity and Access Management (IAM) roles that control people and machine access. In addition, file transfers into Amazon S3 are secured through the services' native security features.
To protect resources in this Guidance, all data is encrypted both in motion and at rest. You can also use customer-controlled AWS Key Management Service (AWS KMS) for encryption.
The serverless components in this Guidance are highly available and automatically scale based on usage, ensuring you have a reliable application-level architecture. With Amazon S3 Select, you can use structured query language (SQL) to filter the contents of an Amazon S3 object and retrieve only the subset of data that you need. Athena allows you to analyze data wherever it lives, while QuickSight powers you with unified business intelligence.
To optimize this Guidance, consider adjusting the data input with direct integrations into your own systems through Lambda or AWS Marketplace connectors. A connector is an optional code package that assists with access to data stores that you can subscribe to. You can subscribe to several connectors offered in AWS Marketplace. You can also add more data relevant to your business needs through AWS Data Exchange and adjust the AWS Glue crawler to construct modified data sets to use for forecasting.
With this Guidance, you benefit from Amazon S3 for inexpensive storage. And with the serverless applications, such as AWS Glue and Lambda, you are charged only for usage. The managed serverless services in this Guidance offer a pay-as-you-go approach where you pay only for the individual services you need, for as long as you need them. The AWS Billing Console and AWS Budgets can help you monitor spending and control costs.
By default, the resources in this Guidance are only activated when there are changes in Amazon S3 buckets, ensuring that this Guidance scales to continually match the load with only the minimum resources required. And with the managed services and dynamic scaling that this Guidance deploys, you minimize the environmental impact of the backend services.
Disclaimer
The sample code; software libraries; command line tools; proofs of concept; templates; or other related technology (including any of the foregoing that are provided by our personnel) is provided to you as AWS Content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content in your production accounts, or on production or other critical data. You are responsible for testing, securing, and optimizing the AWS Content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages