Автоматическое создание модели машинного обучения
с помощью Amazon SageMaker Autopilot
Amazon SageMaker – это полностью управляемый сервис, который предоставляет каждому разработчику и специалисту по работе с данными возможность быстро создавать, обучать и развертывать модели машинного обучения (ML).
При прохождении этого учебного пособия вы автоматически создадите модели машинного обучения, не написав ни одной строчки кода. Работа будет выполняться с использованием Amazon SageMaker Autopilot, возможности автоматизации ML, которая позволяет автоматически создавать оптимальные модели машинного обучения для классификации и регрессии с сохранением полного контроля и прозрачности.
Из этого учебного пособия вы узнаете как выполнить следующие операции.
- Создать аккаунт AWS
- Настроить Amazon SageMaker Studio для получения доступа к Amazon SageMaker Autopilot
- Загрузить публичный пакет данных с помощью Amazon SageMaker Studio
- Создать обучающий эксперимент с помощью Amazon SageMaker Autopilot
- Изучить различные стадии обучающего эксперимента
- Выявить модель с наилучшими показателями из учебного эксперимента и выполнить ее развертывание
- Создавать прогнозы с помощью развернутой модели
В этом примере вы берете на себя обязанности разработчика, который работает в банке. Вам была поручена разработка модели машинного обучения, которая прогнозирует, будет ли клиент регистрироваться для получения депозитного сертификата (CD). Модель будет обучена по набору маркетинговых данных, содержащему демографическую информацию о клиентах, отзывы о маркетинговых мероприятиях и сведения о внешних факторах.
| Подробнее об этом учебном пособии | |
|---|---|
| Время | 10 минут
|
| Стоимость | Менее 10 USD |
| Пример использования | Machine Learning |
| Продукты | Amazon SageMaker |
| Аудитория | Разработчик |
| Уровень | Начинающий |
| Последнее обновление | 12 мая 2020 г. |
Шаг 1. Создание аккаунта AWS
Стоимость этого семинара составляет менее 10 USD. Подробнее см. на странице цен на Amazon SageMaker Studio.
Уже есть аккаунт? Вход
Шаг 2. Настройка Amazon SageMaker Studio
Выполните следующие шаги, чтобы подключиться к Amazon SageMaker Studio и получить доступ к Amazon SageMaker Autopilot.
Примечание. Подробнее см. разделе Get Started with Amazon SageMaker Studio документации по Amazon SageMaker.
а) Войдите в консоль Amazon SageMaker.
Примечание. В верхнем правом углу выберите регион AWS, в котором доступен сервис Amazon SageMaker Studio. Список регионов см. в разделе Onboard to Amazon SageMaker Studio.


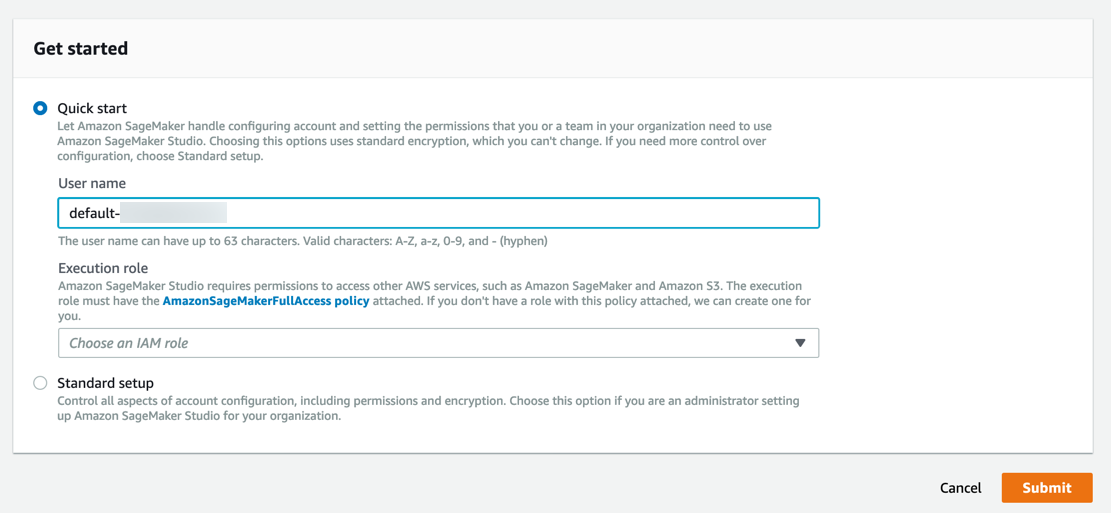
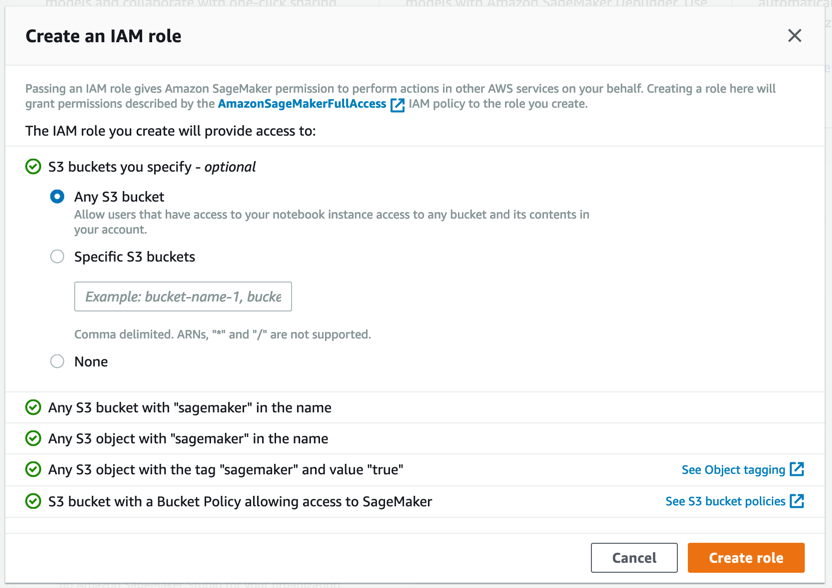
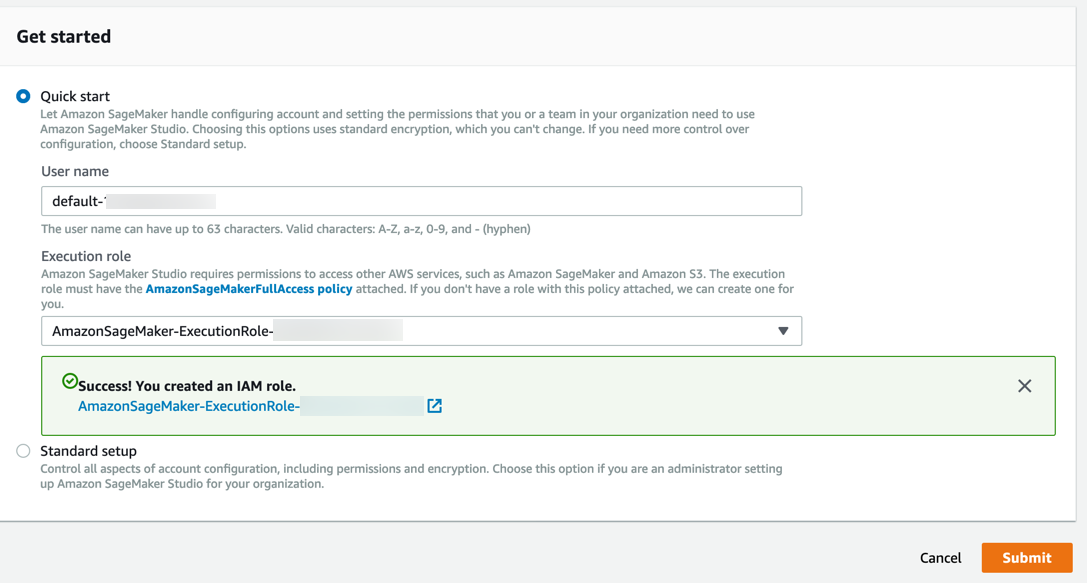
Amazon SageMaker создаст роль с требуемыми разрешениями и назначит ее вашему инстансу.
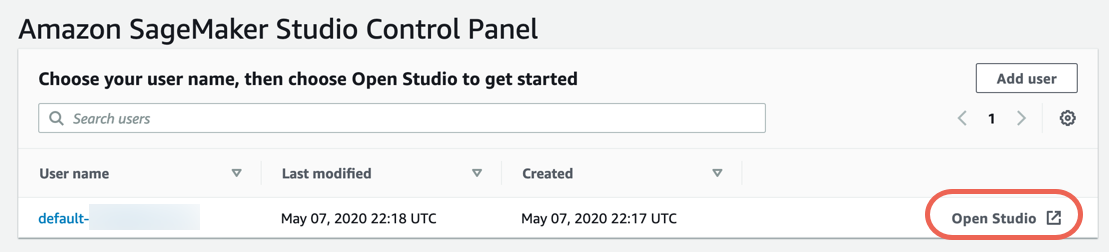
Шаг 3. Загрузка набора данных
Выполните следующие шаги, чтобы загрузить и исследовать набор данных.
Примечание. Подробнее см. в разделе Amazon SageMaker Studio tour документации по Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
г) Скопируйте приведенный ниже код, вставьте его в новую ячейку кода и нажмите Run (Исполнить).
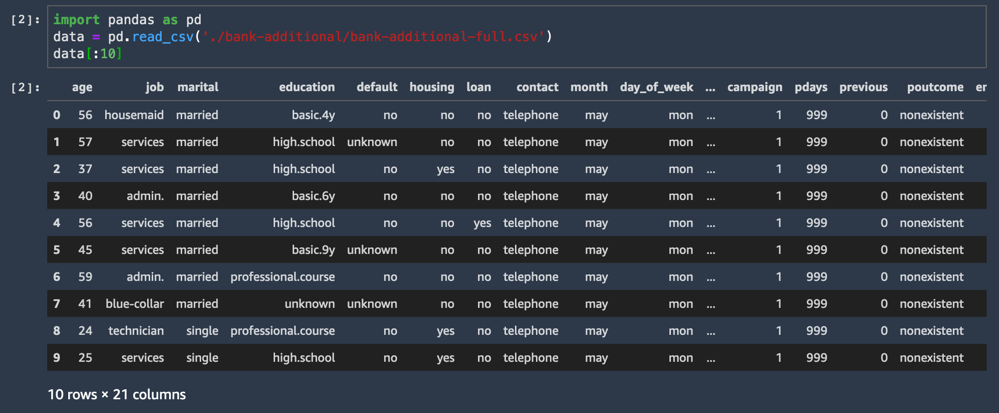
Набор данных при этом будет загружен в формате CSV, отобразятся первые десять строчек.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Один из столбцов набора данных называется y и обозначает положительный ответ на вопрос, принял клиент данное предложение или нет.
Обычно на этом шаге специалисты по работе с данными начинают изучать данные, создавать новые возможности и т. д. Благодаря Amazon SageMaker Autopilot выполнять эти дополнительные шаги не требуется. Просто загрузите табличные данные в файл со значениями, разделенными запятыми (например, из электронной таблицы или базы данных), выберите целевой столбец для прогнозирования, и Autopilot создаст прогнозирующую модель для вас.
г) Скопируйте приведенный ниже код, вставьте его в новую ячейку кода и нажмите Run (Исполнить).
На этом шаге набор данных в формате CSV загружается в корзину Amazon S3. Создавать корзину Amazon S3 не нужно; при загрузке данных сервис Amazon SageMaker автоматически создает в аккаунте корзину по умолчанию.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Готово! В выводе кода отобразится идентификатор URI корзины S3; выглядеть это будет приблизительно так:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvСохраните показанный идентификатор URI для S3 в своем блокноте. Он понадобится на следующем шаге.

Шаг 4. Создание эксперимента SageMaker Autopilot
Теперь, когда вы загрузили и подготовили набор данных в корзине Amazon S3, можно переходить к созданию эксперимента Amazon SageMaker Autopilot. Эксперимент – это набор заданий по обработке и обучению, связанных с одним проектом машинного обучения.
Выполните следующие шаги, чтобы создать новый эксперимент.
Примечание. Подробнее см. в разделе Create an Amazon SageMaker Autopilot Experiment in SageMaker Studio документации по Amazon SageMaker.
а) На левой навигационной панели Amazon SageMaker Studio выберите Experiments (Эксперименты) (значок в виде колбы) и нажмите кнопку Create Experiment (Создать эксперимент).
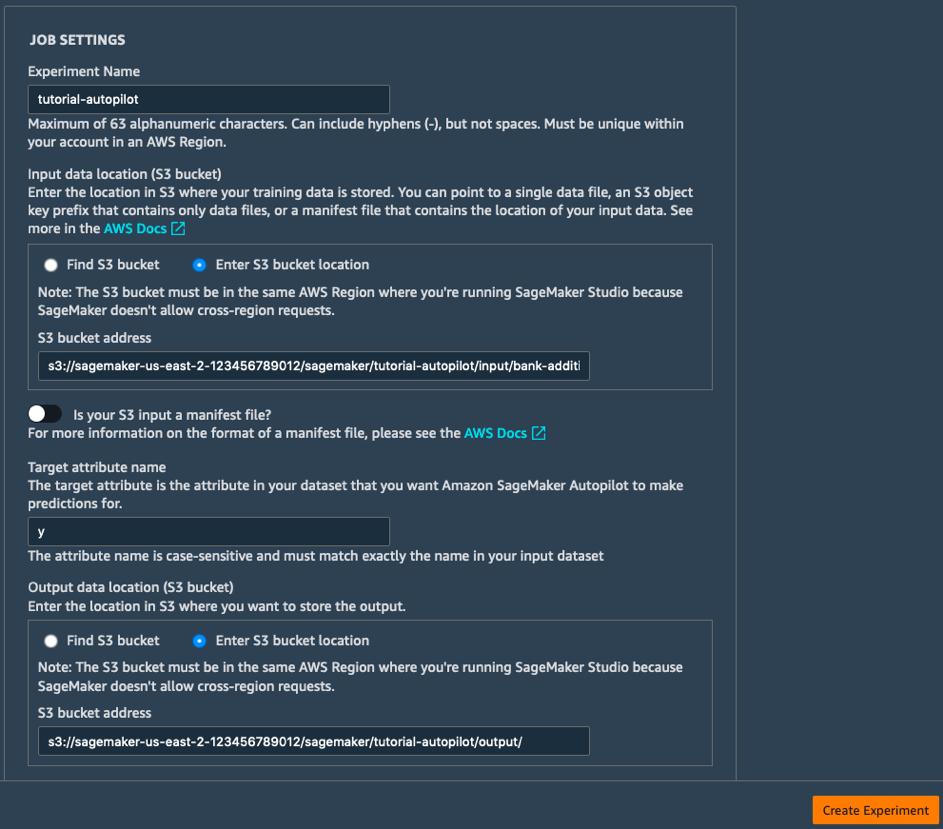
б) Заполните поля раздела Job Settings (Настройки задания), как указано ниже.
- Experiment Name (Название эксперимента): tutorial-autopilot
- S3 location of input data (Местоположение входных данных в S3): идентификатор URI для S3, который был показан ранее
(например, s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name (Имя целевого атрибута): y
- S3 location for output data (Местоположение выходных данных в S3): s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(обязательно замените [ACCOUNT‑NUMBER] на номер своего аккаунта)
в) Оставьте для всех остальных параметров значения по умолчанию и нажмите кнопку Create Experiment (Создать эксперимент).
Готово! Это действие запустит процесс создания эксперимента Amazon SageMaker Autopilot. Процесс сгенерирует модель, а также статистику, которую вы сможете просматривать в режиме реального времени в процессе выполнения эксперимента. После завершения эксперимента можно просмотреть испытания, отсортировать их по целевому показателю и, щелкнув правой кнопкой мыши, выполнить развертывание модели, чтобы использовать ее в других средах.
Шаг 5. Изучение этапов эксперимента SageMaker Autopilot
Во время проведения эксперимента можно узнать и изучить различные этапы эксперимента SageMaker Autopilot.
В этом разделе содержится подробная информация о следующих этапах эксперимента SageMaker Autopilot.
- Анализ данных
- Разработка возможности
- Настройка модели
Примечание. Подробную информацию см. в разделе SageMaker Autopilot Notebook Output.
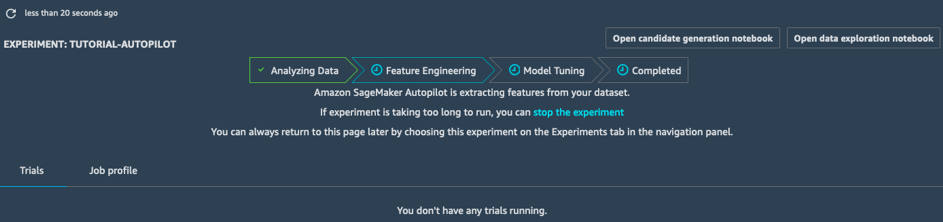
Анализ данных
На этапе анализа данных определяются типы проблем, которые необходимо решить (линейная регрессия, двоичная классификация, многоклассовая классификация). Затем предлагается десять потенциальных конвейеров. Конвейер объединяет этап предварительной обработки данных (обработка пропущенных значений, разработка новых возможностей и т. д.) и этап обучения модели с помощью алгоритма машинного обучения, соответствующего типу задачи. После завершения этого этапа задание переходит на этап разработки возможности.
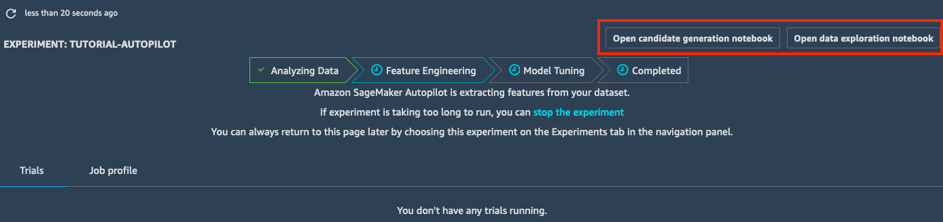
Разработка возможности
На этапе разработки возможности эксперимент создает обучающий и проверочный набор данных для каждого потенциального конвейера, сохраняя все артефакты в корзину S3. На этом этапе можно открыть и просмотреть два автоматически созданных блокнота.
- Блокнот просмотра данных содержит сведения и статистику по набору данных.
- Блокнот генерации потенциальных конвейеров содержит определения десяти конвейеров. По сути, это исполняемый блокнот: вы можете точно воспроизвести действия задания AutoPilot, понять, как строятся различные модели, и даже продолжить их доработку при желании.
С помощью этих двух блокнотов можно подробно изучить, как происходит предварительная обработка данных, а также построение и оптимизация моделей. Прозрачность – важная особенность Amazon SageMaker Autopilot.
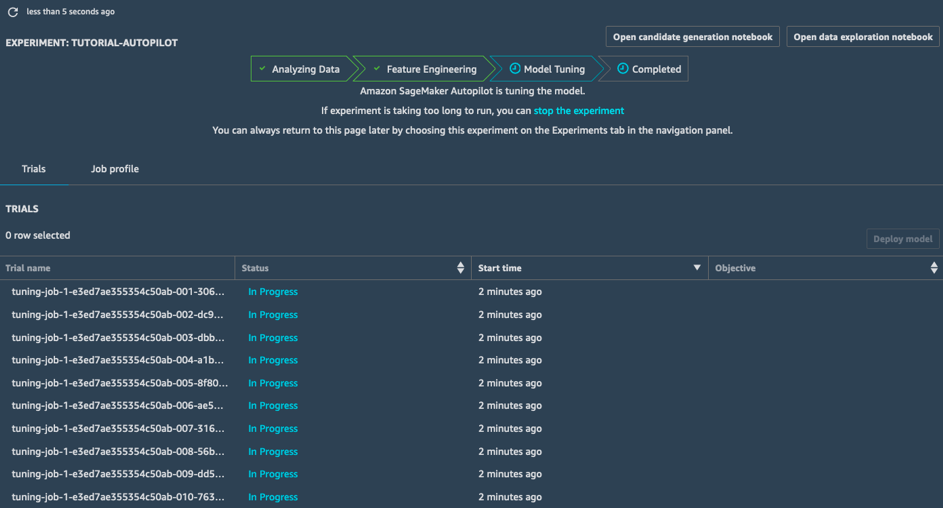
Настройка модели
На этапе настройки модели SageMaker Autopilot выполняет задание оптимизации гиперпараметров для каждого конвейера‑кандидата и соответствующего набора предварительно обработанных данных. В рамках связанных заданий по обучению исследуется широкий спектр значений гиперпараметров, что позволяет быстро получать высокопроизводительные модели.
После выполнения этого этапа работа SageMaker Autopilot завершается. Все задания можно просмотреть в SageMaker Studio.
Шаг 6. Развертывание лучшей модели
Теперь, когда эксперимент завершен, можно выбрать оптимально настроенную модель и выполнить ее развертывание по адресу, который находится под управлением Amazon SageMaker.
Чтобы выбрать оптимальное задание по настройке и выполнить развертывание модели, проделайте следующие действия.
Примечание. Дополнительную информацию см. в разделе Выбор и развертывание лучшей модели.
а) В списке Trials (Исследования) для своего эксперимента нажмите карет (^) рядом с пунктом Objective (Цель), чтобы отсортировать задания по настройке в убывающем порядке. Лучшее задание по настройке будет отмечено звездочкой.
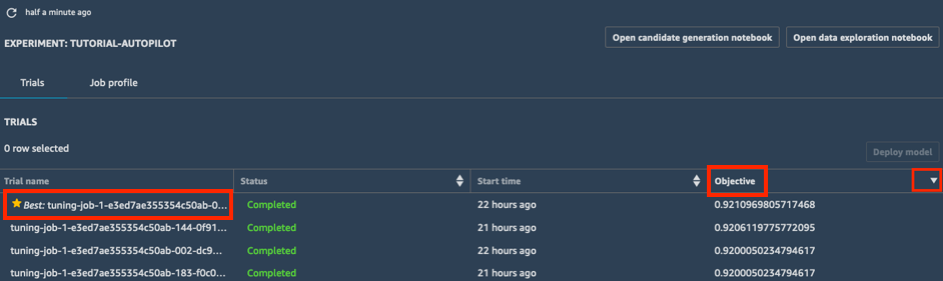
б) Выберите лучшее задание по настройке (отмеченное звездочкой) и нажмите Deploy model (Развертывание модели).
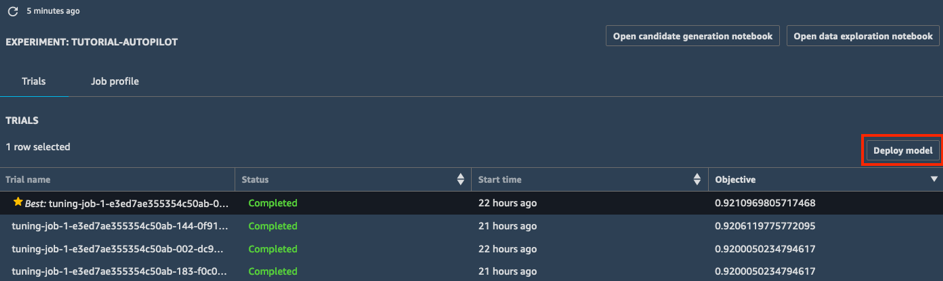
в) В поле Deploy model (Развертывание модели) присвойте адресу имя (например, tutorial-autopilot-best-model) и оставьте настройки по умолчанию. Нажмите Deploy model (Развертывание модели).
Будет выполнено развертывание модели по адресу HTTPS, который находится под управлением Amazon SageMaker.
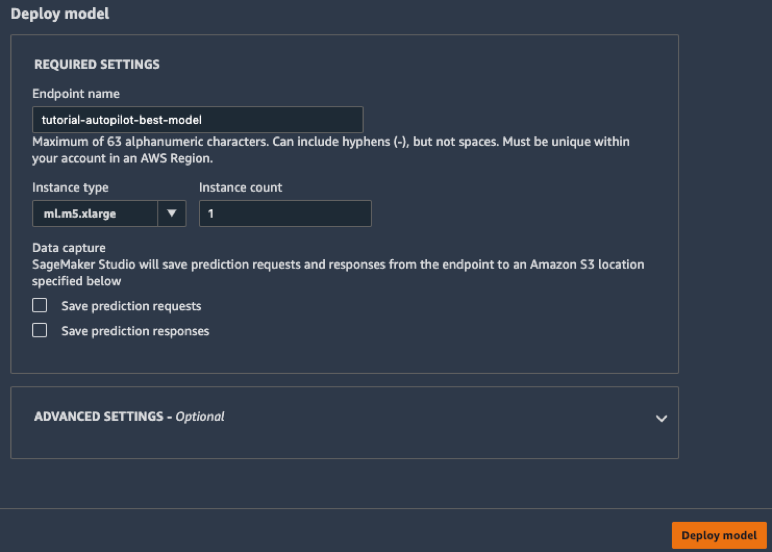
г) В панели инструментов слева нажмите значок Endpoints (Адреса). Вы увидите, что идет создание модели. Этот процесс занимает несколько минут. Как только статус адреса изменится на InService (Работает), можно отправлять данные и получать прогнозы.
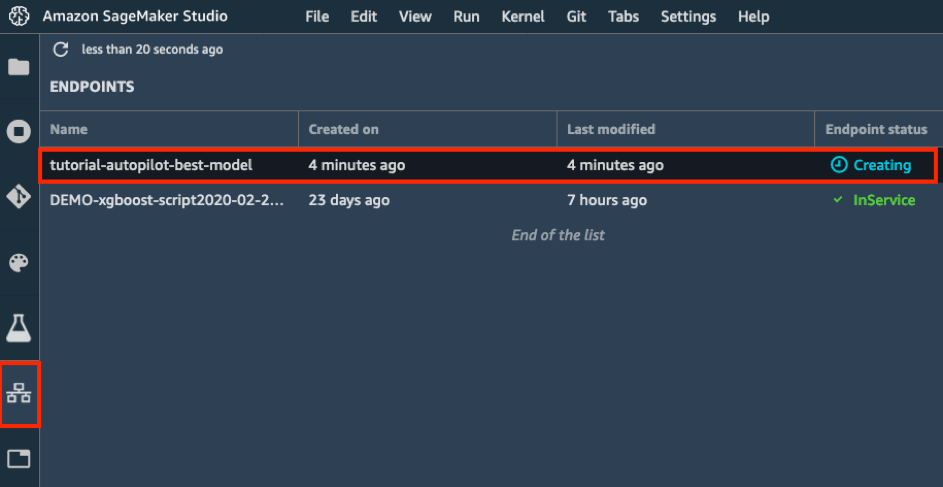
Шаг 7. Прогнозирование с использованием модели
После развертывания модели можно приступать к прогнозированию первых 2000 образцов в наборе данных. Для этого используется API invoke_endpoint в составе boto3 SDK. В процессе вычисляются важные метрики машинного обучения: доля правильных ответов алгоритма, точность, полнота и F‑мера.
Для прогнозирования с использованием модели выполните следующие действия.
Примечание. Подробнее см. в разделе Manage Machine Learning with Amazon SageMaker Experiments.
Скопируйте следующий код в блокнот Jupyter и нажмите Run (Исполнить).
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
В результате должны отобразиться указанные ниже выходные данные.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Это индикатор прогресса, показывающий количество спрогнозированных образцов.
Шаг 8. Очистка
На этом этапе нужно удалить ресурсы, которые использовались в ходе данного практического занятия.
Важно! Удаление неиспользуемых ресурсов позволяет сократить расходы и является рекомендованной мерой. Если не удалить ресурсы, в аккаунте будет начисляться плата.
Удалите использованный адрес. Для этого скопируйте следующий код в блокнот Jupyter и нажмите Run (Исполнить).
sess.delete_endpoint(endpoint_name=ep_name)Если вы хотите удалить все артефакты обучения (модели, наборы предварительно обработанных данных и т. д.), скопируйте в ячейку кода следующий код и нажмите Run (Исполнить).
Примечание. Обязательно замените ACCOUNT_NUMBER на номер своего аккаунта.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Поздравляем!
Вы автоматически создали модель машинного обучения с наибольшей долей правильных ответов алгоритма, используя Amazon SageMaker Autopilot.
Рекомендуемые дальнейшие шаги
Изучение образцов блокнотов машинного обучения
Обзор Amazon SageMaker Studio
Подробнее о возможностях Amazon SageMaker Autopilot
Если вы хотите получить подробную информацию, ознакомьтесь с публикацией в блоге или посмотрите серию видео, посвященных Autopilot.