



O que é regressão logística?
A regressão logística é uma técnica de análise de dados que usa matemática para encontrar as relações entre dois fatores de dados. Em seguida, essa relação é usada para prever o valor de um desses fatores com base no outro. A previsão geralmente tem um número finito de resultados, como sim ou não.
Por exemplo, digamos que você deseje adivinhar se o visitante do seu site clicará no botão de finalização de compra no carrinho de compras ou não. A análise de regressão logística analisa o comportamento anterior do visitante, como o tempo gasto no site e o número de itens no carrinho. Ela determina que, anteriormente, se os visitantes passassem mais de cinco minutos no site e adicionassem mais de três itens ao carrinho, eles clicavam no botão de finalização de compra. Usando essas informações, a função de regressão logística pode prever o comportamento de um novo visitante do site.
Por que a regressão logística é importante?
A regressão logística é uma técnica importante no campo da inteligência artificial e do machine learning (IA e ML). Os modelos de ML são programas de software que podem ser treinados para executar tarefas complexas de processamento de dados sem intervenção humana. Os modelos de ML criados usando regressão logística ajudam as organizações a extrair insights práticos de seus dados comerciais. Esses insights podem ser usados para análise preditiva a fim de reduzir custos operacionais, aumentar a eficiência e escalar mais rapidamente. Por exemplo, as empresas podem descobrir padrões que melhoram a retenção de funcionários ou geram um design de produto mais lucrativo.
Abaixo, veja alguns benefícios do uso da regressão logística em relação a outras técnicas de ML.
Simplicidade
Os modelos de regressão logística são matematicamente menos complexos do que outros métodos de ML. Portanto, você pode implementá-los mesmo que ninguém na sua equipe tenha conhecimento profundo de ML.
Velocidade
Os modelos de regressão logística podem processar grandes volumes de dados em alta velocidade porque exigem menos capacidade computacional, como memória e capacidade de processamento. Por isso, são ideais para que as organizações que estão começando com projetos de ML obtenham alguns progressos rápidos.
Flexibilidade
Use a regressão logística para encontrar respostas para perguntas que têm dois ou mais resultados finitos. Também é possível usá-la para pré-processar dados. Por exemplo, você pode classificar dados com um grande intervalo de valores, como transações bancárias, em um intervalo menor e finito de valores usando regressão logística. Em seguida, processe esse conjunto de dados menor usando outras técnicas de ML para obter uma análise mais precisa.
Visibilidade
A análise de regressão logística oferece aos desenvolvedores maior visibilidade dos processos internos de software do que outras técnicas de análise de dados. Também facilita a solução de problemas e a correção de erros, pois os cálculos são menos complexos.
Quais são as aplicações da regressão logística?
A regressão logística tem várias aplicações no mundo real em muitos setores diferentes.
Manufatura
As empresas de manufatura usam a análise de regressão logística para estimar a probabilidade de falha de peças em máquinas. Em seguida, planejam programações de manutenção com base nessa estimativa para minimizar falhas futuras.
Saúde
Pesquisadores da área de medicina planejam tratamento e cuidados preventivos estimando a probabilidade de doença em pacientes. Eles usam modelos de regressão logística para comparar o impacto do histórico familiar ou dos genes nas doenças.
Financeiro
As empresas financeiras precisam analisar as transações financeiras em busca de fraude e avaliar os pedidos de empréstimo e os pedidos de seguro quanto a riscos. Esses problemas são adequados para um modelo de regressão logística porque têm resultados discretos, como alto risco ou baixo risco e fraudulentos ou não fraudulentos.
Marketing
As ferramentas de publicidade online usam o modelo de regressão logística para prever se os usuários clicarão em um anúncio. Como resultado, os profissionais de marketing podem analisar as respostas dos usuários a diferentes palavras e imagens e criar anúncios de alta performance que terão interação dos clientes.
Como funciona a análise de regressão?
A regressão logística é uma das várias técnicas de análise de regressão diferentes que os cientistas de dados costumam usar no machine learning (ML). Para entender a regressão logística, primeiro devemos entender a análise de regressão básica. Abaixo, veja um exemplo de análise de regressão linear para demonstrar como funciona a análise de regressão.
Identificar a pergunta
Toda análise de dados começa com uma pergunta comercial. Para regressão logística, é necessário enquadrar a pergunta para obter resultados específicos:
- Os dias chuvosos afetam nossas vendas mensais? (sim ou não)
- Que tipo de atividade de cartão de crédito o cliente está realizando? (autorizada, fraudulenta ou potencialmente fraudulenta)
Coletar histórico de dados
Depois de identificar a pergunta, é necessário identificar os fatores de dados envolvidos. Em seguida, você coletará dados anteriores para todos os fatores. Por exemplo, para responder à primeira pergunta exibida acima, você pode coletar o número de dias chuvosos e seus dados de vendas mensais para cada mês nos últimos três anos.
Treinar o modelo de análise de regressão
Você processará os dados históricos usando o software de regressão. O software processará os diferentes pontos de dados e os conectará matematicamente usando equações. Por exemplo, se o número de dias chuvosos em três meses for 3, 5 e 8 e o número de vendas nesses meses for 8, 12 e 18, o algoritmo de regressão conectará os fatores à equação:
Número de vendas = 2*(número de dias chuvosos) + 2
Fazer previsões para valores desconhecidos
Para valores desconhecidos, o software usa a equação para fazer uma previsão. Se você souber que choverá por seis dias em julho, o software estimará o valor de venda de julho como 14.
Como funciona o modelo de regressão logística?
Para entender o modelo de regressão logística, vamos primeiro entender equações e variáveis.
Equações
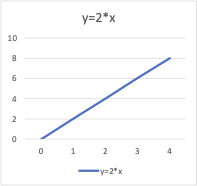
Em matemática, as equações fornecem a relação entre duas variáveis: x e y. É possível usar essas equações, ou funções, para traçar um gráfico ao longo dos eixos x e y colocando valores diferentes dex e y. Por exemplo, se traçar o gráfico para a função y = 2*x, você obterá uma linha reta, conforme mostrado abaixo. Portanto, essa função também é chamada de função linear.
Variáveis
Em estatística, as variáveis são os fatores de dados ou atributos cujos valores variam. Para qualquer análise, certas variáveis são variáveis independentes ou explicativas. Esses atributos são a causa de um resultado. Outras variáveis são dependentes ou variáveis de resposta, cujos valores dependem das variáveis independentes. Em geral, a regressão logística explora como as variáveis independentes afetam uma variável dependente, observando os valores de dados históricos de ambas as variáveis.
No exemplo acima, o x é chamado de variável independente, variável preditora ou variável explicativa porque tem um valor conhecido. O y é chamado de variável dependente, variável de resultado ou variável de resposta porque seu valor é desconhecido.
Função de regressão logística
A regressão logística é um modelo estatístico que usa a função logística, ou função logit, em matemática como a equação entre x e y. A função logit mapeia y como uma função sigmoide de x.
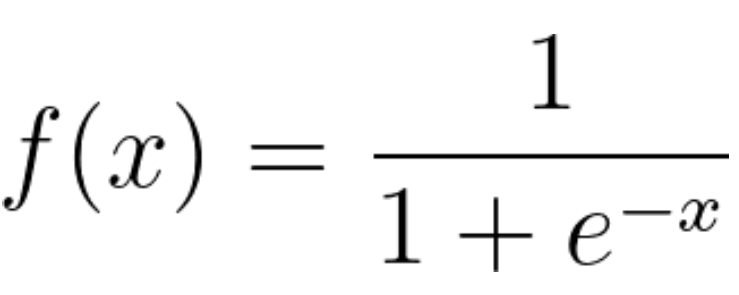
Se traçar essa equação de regressão logística, você obterá uma curva S, conforme mostrado abaixo.
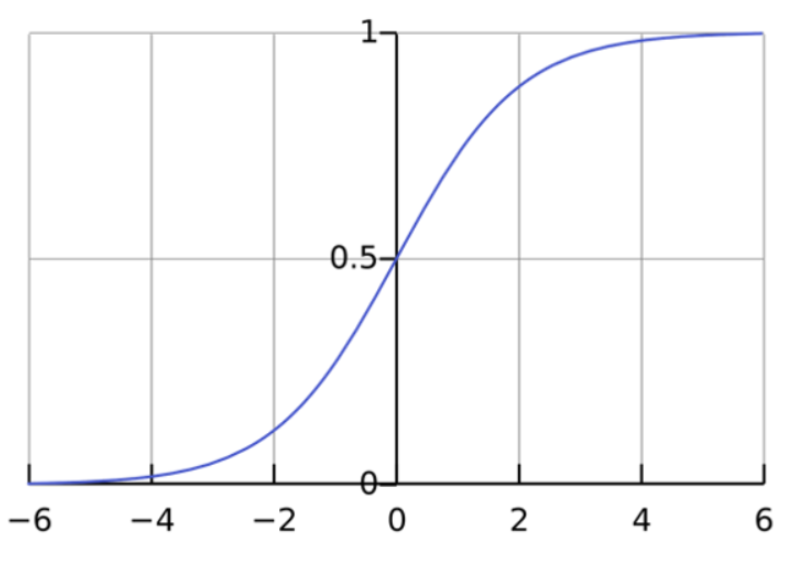
Como você pode ver, a função logit retorna somente valores entre 0 e 1 para a variável dependente, quaisquer que sejam os valores da variável independente. É assim que a regressão logística estima o valor da variável dependente. Os métodos de regressão logística também modelam equações entre múltiplas variáveis independentes e uma variável dependente.
Análise de regressão logística com múltiplas variáveis independentes
Em muitos casos, múltiplas variáveis explicativas afetam o valor da variável dependente. Para modelar esses conjuntos de dados de entrada, as fórmulas de regressão logística assumem uma relação linear entre as diferentes variáveis independentes. É possível modificar a função sigmoide e calcular a variável de saída final como
y = f(β0 + β1x1 + β2x2+… βnxn)
O símbolo β representa o coeficiente de regressão. O modelo logit pode calcular esses valores de coeficiente de forma reversa quando você fornece um conjunto de dados experimental grande o suficiente com valores conhecidos de variáveis dependentes e independentes.
Probabilidades de log
O modelo logit também pode determinar a razão entre sucesso e falha ou registrar probabilidades. Por exemplo, se você jogar pôquer com seus amigos e vencer quatro de dez partidas, suas chances de ganhar serão quatro sextos, ou quatro de seis, que é a proporção entre seu sucesso e fracasso. A probabilidade de ganhar, por outro lado, é de quatro em dez.
Matematicamente, suas chances em termos de probabilidade são p/(1 - p), e suas chances de log são log (p/(1 - p)). Você pode representar a função logística como probabilidades de log, conforme mostrado abaixo:
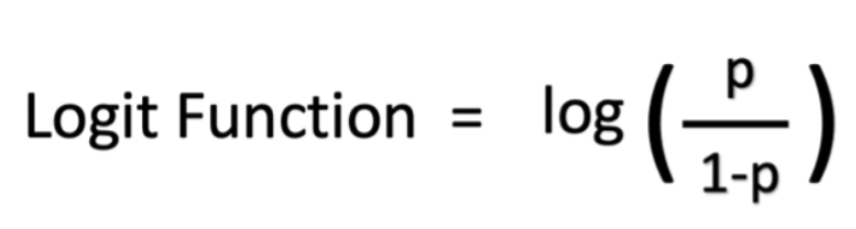
Quais são os tipos de análise de regressão logística?
Há três abordagens para análise de regressão logística com base nos resultados da variável dependente.
Regressão logística binária
A regressão logística binária funciona bem para problemas de classificação binária que tenham apenas dois resultados possíveis. A variável dependente pode ter apenas dois valores, como sim e não ou 0 e 1.
Embora a função logística calcule um intervalo de valores entre 0 e 1, o modelo de regressão binária arredonda a resposta para os valores mais próximos. Geralmente, respostas abaixo de 0,5 são arredondadas para 0, e respostas acima de 0,5 são arredondadas para 1, para que a função logística retorne um resultado binário.
Regressão logística multinomial
A regressão multinomial pode analisar problemas que tenham vários resultados possíveis, desde que o número de resultados seja finito. Por exemplo, ela é capaz de prever se os preços das casas aumentarão em 25%, 50%, 75% ou 100% com base em dados populacionais, mas não pode prever o valor exato de uma casa.
A regressão logística multinomial funciona mapeando os valores dos resultados para diferentes valores entre 0 e 1. Como a função logística pode retornar um intervalo de dados contínuos, como 0,1, 0,11, 0,12 e assim por diante, a regressão multinomial também agrupa a saída para os valores mais próximos possíveis.
Regressão logística ordinal
A regressão logística ordinal, ou o modelo logit ordenado, é um tipo especial de regressão multinomial para problemas em que os números representam classificações em vez de valores reais. Por exemplo, você usaria a regressão ordinal para prever a resposta a uma pergunta de pesquisa que pede para os clientes classificarem seu serviço como ruim, regular, bom ou excelente com base em um valor numérico, como o número de itens que eles compram de você ao longo do ano.
Como a regressão logística é comparada a outras técnicas de ML?
As duas técnicas comuns de análise de dados são análise de regressão linear e aprendizado profundo.
Análise de regressão linear
Conforme explicado acima, a regressão linear modela a relação entre variáveis dependentes e independentes usando uma combinação linear. A equação de regressão linear é
y= β0X0 + β1X1 + β2X2+… βnXn+ ε, em que β1 para βn e ε são coeficientes de regressão.
Diferenças entre regressão logística e regressão linear
A regressão linear prevê uma variável dependente contínua usando determinado conjunto de variáveis independentes. Uma variável contínua pode ter um intervalo de valores, como preço ou idade. Portanto, a regressão linear pode prever valores reais da variável dependente. Ela pode responder a perguntas como “Qual será o preço do arroz daqui a dez anos?”.
Diferentemente da regressão linear, a regressão logística é um algoritmo de classificação. Ela não é capaz de prever valores reais para dados contínuos. Ela pode responder a perguntas como “O preço do arroz aumentará 50% em dez anos?”.
Aprendizado profundo
O aprendizado profundo usa redes neurais ou componentes de software que simulam o cérebro humano para analisar informações. Os cálculos de aprendizado profundo são baseados no conceito matemático de vetores.
Diferenças entre regressão logística e aprendizado profundo
A regressão logística é menos complexa e com menos uso intensivo de computação do que o aprendizado profundo. Mais importante ainda, por causa de sua natureza complexa e orientada por máquinas, os cálculos de aprendizado profundo não podem ser investigados nem modificados pelos desenvolvedores. Por sua vez, os cálculos de regressão logística são transparentes e mais fáceis de solucionar.
Como executar a análise de regressão logística na AWS?
É possível executar a regressão logística na AWS usando o Amazon SageMaker. O SageMaker é um serviço de machine learning (ML) totalmente gerenciado com algoritmos integrados para regressão linear e regressão logística, entre vários outros pacotes de software estatístico.
- Todo cientista de dados pode usar o SageMaker para preparar, criar, treinar e implantar modelos de regressão logística rapidamente.
- O SageMaker remove o trabalho pesado de cada etapa do processo de regressão logística para facilitar o desenvolvimento de modelos de alta qualidade.
- O SageMaker fornece todos os componentes necessários para a regressão logística em um único conjunto de ferramentas. Assim, você pode colocar os modelos em produção de forma mais rápida, fácil e a um custo menor.
Comece com a regressão logística criando uma conta da AWS hoje mesmo.
Próximas etapas na AWS
Obtenha acesso instantâneo ao nível gratuito da AWS.