



O que é rotulagem de dados?
Em machine learning, a rotulagem de dados é o processo de identificar dados brutos (imagens, arquivos de texto, vídeos etc.) e adicionar um ou mais rótulos significativos e informativos para fornecer contexto para que um modelo de machine learning possa aprender com ele. Por exemplo, os rótulos podem indicar se uma foto contém um pássaro ou um carro, quais palavras foram pronunciadas em uma gravação de áudio ou se um raio-x contém um tumor. A rotulagem de dados é necessária para uma variedade de casos de uso, incluindo visão computacional, processamento de linguagem natural e reconhecimento de fala.
Como funciona a rotulagem de dados?
Atualmente, a maioria dos modelos práticos de machine learning utiliza o aprendizado supervisionado, que aplica um algoritmo para mapear uma entrada para uma saída. Para que o aprendizado supervisionado funcione, você precisa de um conjunto de dados rotulado com o qual o modelo possa aprender para tomar decisões corretas. A rotulagem de dados geralmente começa solicitando aos humanos que façam julgamentos sobre um determinado dado não rotulado. Por exemplo, os rotuladores podem ser solicitados a marcar todas as imagens em um conjunto de dados em que a afirmação “a foto contém um pássaro” é verdadeira. A marcação pode ser tão aproximada quanto um simples sim/não ou tão granular quanto identificar os pixels específicos na imagem associada ao pássaro. O modelo de machine learning usa rótulos fornecidos por humanos para aprender os padrões subjacentes em um processo chamado de “treinamento de modelos”. O resultado é um modelo treinado que pode ser usado para fazer previsões sobre novos dados.
No machine learning, um conjunto de dados devidamente rotulado que você usa como padrão objetivo para treinar e avaliar um determinado modelo geralmente é chamado de “verdade básica”. Como a precisão do seu modelo treinado dependerá da precisão da sua verdade básica, é essencial dedicar tempo e recursos para garantir uma rotulagem de dados altamente precisa.
Quais são alguns tipos comuns de rotulagem de dados?
Visão por computação
Ao criar um sistema de visão computacional, primeiro você precisa rotular imagens, pixels ou pontos-chave ou criar uma borda que envolva totalmente uma imagem digital, conhecida como caixa delimitadora, para gerar seu conjunto de dados de treinamento. Por exemplo, você pode classificar imagens por tipo de qualidade (como imagens de produtos versus imagens de estilo de vida) ou conteúdo (o que realmente está na própria imagem), ou pode segmentar uma imagem no nível do pixel. Em seguida, pode usar esses dados de treinamento para criar um modelo de visão computacional, que pode ser usado para categorizar imagens automaticamente, detectar a localização de objetos, identificar pontos-chave em uma imagem ou segmentar uma imagem.
Processamento de linguagem natural
O processamento de linguagem natural exige que você primeiro identifique manualmente seções importantes do texto ou o marque com rótulos específicos para gerar seu conjunto de dados de treinamento. Por exemplo, talvez você queira identificar o sentimento ou a intenção de uma sinopse de texto, identificar partes do discurso, classificar substantivos próprios, como lugares e pessoas, e identificar texto em imagens, PDFs ou outros arquivos. Para fazer isso, você pode desenhar caixas delimitadoras ao redor do texto e depois transcrever manualmente o texto no seu conjunto de dados de treinamento. Modelos de processamento de linguagem natural são usados para análise de sentimentos, reconhecimento de nomes de entidades e reconhecimento óptico de caracteres.
Processamento de áudio
O processamento de áudio converte todos os tipos de sons, como fala, ruídos da vida selvagem (latidos, assobios ou chilreios) e sons de construção (vidros quebrando, digitalizações ou alarmes) em um formato estruturado para que possa ser usado no machine learning. O processamento de áudio geralmente exige que você primeiro o transcreva manualmente em texto escrito. A partir daí, é possível descobrir informações mais detalhadas sobre o áudio adicionando etiquetas e categorizando o áudio. Esse áudio categorizado se torna seu conjunto de dados de treinamento.
Quais são algumas das melhores práticas para rotulagem de dados?
Existem muitas técnicas para melhorar a eficiência e a precisão da rotulagem de dados. Algumas delas incluem:
- Interfaces de tarefas intuitivas e simplificadas para ajudar a minimizar a carga cognitiva e a mudança de contexto para rotuladores humanos.
- Consenso dos rotuladores para ajudar a combater erros/tendenciosidades de anotadores individuais. O consenso dos rotuladores envolve o envio de cada objeto do conjunto de dados para vários anotadores e, em seguida, a consolidação de suas respostas (chamadas de “anotações”) em um único rótulo.
- Auditoria de rotulagem para verificar a precisão dos rótulos e atualizá-los conforme necessário.
- Aprendizado ativo para tornar a rotulagem dos dados mais eficiente usando machine learning para identificar os dados mais úteis a serem rotulados pelos humanos.
Como a rotulagem de dados pode ser feita de maneira eficiente?
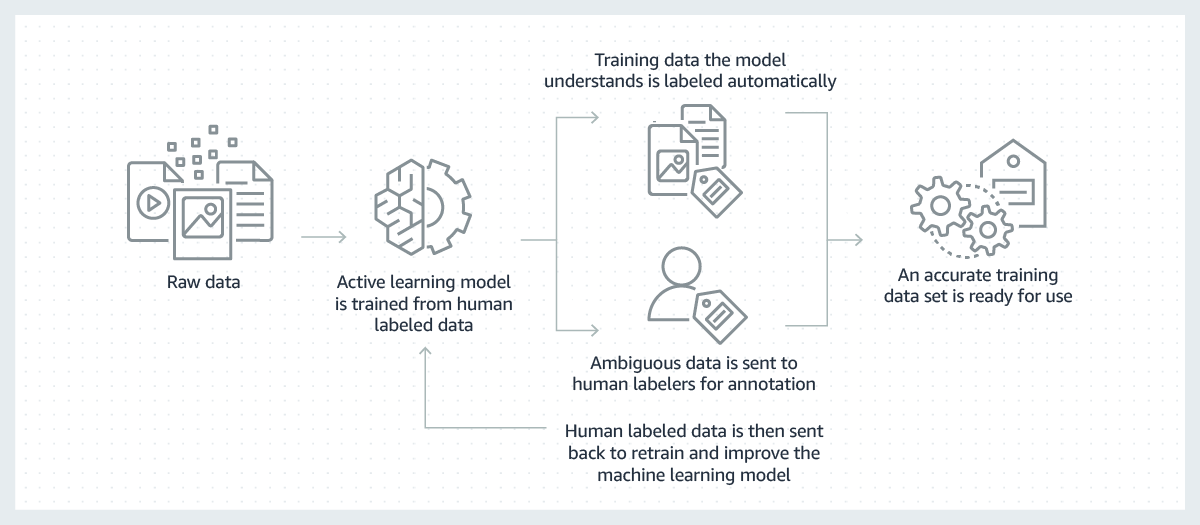
Modelos de machine learning de sucesso são desenvolvidos com base em grandes volumes de dados de treinamento de alta qualidade. Contudo, o processo de criação dos dados de treinamento necessários para desenvolver esses modelos geralmente é caro, complicado e demorado. A maioria dos modelos criados atualmente requer que uma pessoa rotule manualmente os dados de forma que permita que o modelo saiba como tomar as decisões corretas. Para superar esse desafio, a rotulagem pode se tornar mais eficiente usando um modelo de machine learning para rotular os dados automaticamente.
Nesse processo, um modelo de machine learning para rotular dados é primeiro treinado em um subconjunto dos seus dados brutos que foram rotulados por humanos. Quando o modelo de rotulagem tiver um alto grau de confiança nos resultados, com base no que aprendeu até então, ele aplicará automaticamente os rótulos aos dados brutos. Quando o modelo de rotulagem tiver pouca confiança nos resultados, ele passará os dados para que pessoas possam fazer a rotulagem. Os rótulos gerados por humanos são então retornados ao modelo de rotulagem para que este aprenda e melhore sua capacidade de rotular automaticamente o próximo conjunto de dados brutos. Com o tempo, o modelo poderá rotular cada vez mais dados automaticamente e acelerar substancialmente a criação de conjuntos de dados de treinamento.
Como a AWS pode atender aos seus requisitos de rotulagem de dados?
O Amazon SageMaker Ground Truth reduz significativamente o tempo e o trabalho necessários para criar conjuntos de dados de treinamento. O SageMaker Ground Truth oferece acesso a rotuladores humanos em áreas públicas e privadas e fornece a eles fluxos de trabalho e interfaces integrados para tarefas comuns de rotulagem. É fácil começar a usar o SageMaker Ground Truth. O Tutorial de introdução pode ser usado para criar seu primeiro trabalho de rotulagem em minutos.
Comece a usar a rotulagem de dados na AWS criando uma conta hoje mesmo.
Próximas etapas na AWS
Obtenha acesso instantâneo ao nível gratuito da AWS.