Amazon SageMaker Data Wrangler
A maneira mais rápida e fácil de preparar dados para machine learning, agora no SageMaker Canvas
Por que usar o SageMaker Data Wrangler?
O Amazon SageMaker Data Wrangler reduz o tempo de preparação de dados tabulares, de imagem e de texto de semanas para minutos. Com o SageMaker Data Wrangler, é possível simplificar a preparação de dados e a engenharia de atributos por meio de uma interface visual e de linguagem natural. Selecione, importe e transforme dados rapidamente com SQL e mais de 300 transformações incorporadas sem escrever código. Gere relatórios intuitivos sobre a qualidade dos dados para detectar anomalias nos tipos de dados e estimar o desempenho do modelo. Escale para processar petabytes de dados.
Benefícios do SageMaker Data Wrangler
Como funciona?
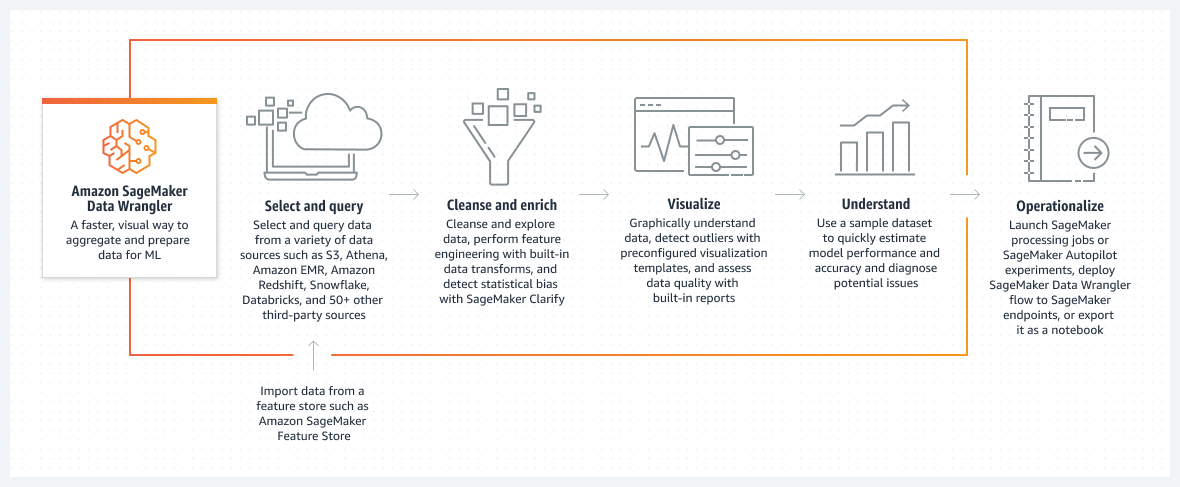
Como funciona

Título 1: Amazon SageMaker Data Wrangler
Texto da descrição: Uma maneira mais rápida e visual de agregar e preparar dados para ML
Título 2: selecionar e consultar
Texto da descrição: selecione e consulte dados de uma variedade de fontes de dados, como Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks e mais de 50 outras fontes de terceiros
Subdescrição: Importar dados de um recurso de armazenamento, como o Amazon SageMaker Feature Store
Título 3: Limpar e enriquecer
Texto da descrição: Limpe e explore dados, realize engenharia de recursos com transformações de dados integradas e detecte tendências estatísticas com o SageMaker Clarify
Título 4: Visualizar
Texto da descrição: Entenda os dados graficamente, detecte discrepâncias com modelos de visualização pré-configurados e avalie a qualidade dos dados com relatórios integrados
Título 5: Entender
Texto da descrição: Use um conjunto de dados de amostra para estimar rapidamente a performance e a precisão do modelo e diagnosticar possíveis problemas
Título 6: Operacionalizar
Texto da descrição: inicie tarefas de processamento do SageMaker ou experimentos do SageMaker Autopilot, implante o fluxo do SageMaker Data Wrangler nos endpoints do SageMaker ou exporte-o como um notebook.
Acesse, selecione e consulte dados mais rápido
Com o SageMaker Data Wrangler, você pode acessar rapidamente dados tabulares, de texto e de imagem de serviços da Amazon, como o S3, o Athena, o Redshift e mais de 50 fontes de terceiros. É possível selecionar dados com o criador de consultas visuais, gravar consultas SQL ou importar dados diretamente em vários formatos, como CSV e Parquet.

Gere insights de dados e compreenda a qualidade dos dados
O SageMaker Data Wrangler fornece um relatório de insights e da qualidade dos dados que verifica automaticamente a qualidade dos dados (como valores ausentes, linhas duplicadas e tipos de dados) e ajuda a detectar anomalias (como discrepâncias, desbalanceamento de classe e vazamentos de dados) em seus dados. Após verificar a qualidade dos dados com eficiência, é possível aplicar rapidamente o conhecimento do domínio para processar conjuntos de dados para o treinamento do modelo de ML.

Entenda seus dados com visualizações
O SageMaker Data Wrangler ajuda você a compreender seus dados por meio de modelos de visualização integrados robustos, como histogramas, gráficos de dispersão, importância de atributos e correlações. Acelere a exploração de dados com relatórios intuitivos de qualidade de dados que detectam anomalias em todos os tipos de dados e fornecem recomendações para melhorar a qualidade dos dados.

Transforme dados com mais eficiência
O SageMaker Data Wrangler oferece mais de 300 transformações PySpark predefinidas e uma interface de linguagem natural para preparar dados tabulares, de séries temporais, de texto e de imagem sem codificação. Casos de uso comuns, como vetorização de texto, caracterização de data e hora, codificação, balanceamento de dados ou aumento de imagens, são abordados. Você também pode criar transformações personalizadas no PySpark, SQL e Pandas ou usar a interface de linguagem natural para gerar código. Uma biblioteca integrada de fragmentos de código simplifica a gravação de transformações personalizadas.

Entenda o poder preditivo de seus dados
O SageMaker Data Wrangler fornece uma análise rápida de modelos para estimar o poder preditivo de seus dados. Você obtém a precisão de modelos estimados, a importância de atributos e uma matriz de confusão para ajudar na validação da qualidade de dados antes de treinar os modelos.

Automatize e implante fluxos de trabalho de preparação de dados para ML
O SageMaker Data Wrangler permite que você escale para preparar petabytes de dados sem codificar o PySpark ou gerar clusters. Inicie trabalhos de processamento diretamente da interface do usuário ou integre a preparação de dados aos fluxos de trabalho de ML exportando-os para o SageMaker Feature Store ou integrando-os ao SageMaker Pipelines. Você também pode exportar fluxos de dados como cadernos Jupyter ou script Python para replicação programática de suas etapas de preparação de dados.

Clientes
“Na INVISTA, somos movidos pela transformação e buscamos desenvolver produtos e tecnologias que beneficiem os clientes em todo o mundo. Na nossa visão, ML é uma forma de aprimorar a experiência do cliente. Entretanto, com conjuntos de dados que abrangem centenas de milhões de linhas, precisávamos de uma solução que nos ajudasse a preparar dados e a desenvolver, implantar e gerenciar modelos de ML em grande escala. Com o Amazon SageMaker Data Wrangler, podemos selecionar, limpar, explorar e compreender nossos dados de forma interativa, capacitando nossa equipe de ciência de dados para criar pipelines de engenharia de atributos que podem ser escalados com facilidade para conjuntos de dados que abrangem centenas de milhões de linhas. Com o Amazon SageMaker Data Wrangler, podemos operacionalizar nossos fluxos de trabalho de ML com mais rapidez.”
Caleb Wilkinson, antigo líder do setor de ciência de dados da INVISTA
“Ao usar ML, a 3M está aprimorando produtos testados e comprovados, como papéis abrasivos, e impulsionando a inovação em diversos outros espaços, incluindo o setor de saúde. À medida que planejamos escalar ML para mais áreas da 3M, percebemos a quantidade de dados e modelos em rápido crescimento, praticamente dobrando a cada ano. Estamos entusiasmados com os novos atributos do SageMaker porque eles nos ajudarão a realizar a escalabilidade. O Amazon SageMaker Data Wrangler facilita muito a preparação de dados para treinamento de modelos, e o Amazon SageMaker Feature Store eliminará a necessidade de criar os mesmos atributos de modelo repetidamente. Por fim, o Amazon SageMaker Pipelines nos ajudará a automatizar a preparação de dados, o desenvolvimento de modelos e a implantação de modelos em um fluxo de trabalho completo para que possamos acelerar o tempo de entrada no mercado para os nossos modelos. Nossos pesquisadores estão ansiosos para aproveitar a nova velocidade da ciência na 3M.”
David Frazee, antigo diretor técnico da 3M Corporate Systems Research Lab
“O Amazon SageMaker Data Wrangler nos possibilita começar a trabalhar para atender às nossas necessidades de preparação de dados com uma avançada coleção de ferramentas de transformação que aceleram o processo de preparação de dados de ML necessário para lançar novos produtos no mercado. Por sua vez, nossos clientes se beneficiam da taxa em que escalamos modelos implantados, permitindo-nos entregar resultados mensuráveis e sustentáveis que atendem às necessidades de nossos clientes em questão de dias, em vez de meses.”
Frank Farrall, diretor e chefe de plataformas e ecossistemas de IA da Deloitte
“Como um parceiro de consultoria premier da AWS, nossas equipes de engenharia estão trabalhando em estreita colaboração com a AWS para desenvolver soluções inovadoras para ajudar nossos clientes a melhorar continuamente a eficiência de suas operações. O ML é o núcleo de nossas soluções inovadoras, mas nosso fluxo de trabalho de preparação de dados envolve técnicas sofisticadas de preparação de dados que, como resultado, demoram um tempo considerável para serem operacionalizadas em um ambiente de produção. Com o Amazon SageMaker Data Wrangler, nossos cientistas de dados podem concluir cada etapa do fluxo de trabalho de preparação de dados, incluindo seleção, limpeza, exploração e visualização de dados, o que nos ajuda a acelerar o processo de preparação de dados e prepará-los com facilidade para ML. Com o Amazon SageMaker Data Wrangler, podemos preparar dados para ML mais rapidamente.”
Shigekazu Ohmoto, diretor administrativo empresarial sênior da NRI Japan
“À medida que nossa presença no mercado de gerenciamento de saúde populacional continua a se expandir para mais pagadores da área de saúde, provedores, gerentes de benefícios farmacêuticos e outras organizações de saúde, precisávamos de uma solução para automatizar processos completos para fontes de dados que impulsionam nossos modelos de ML, incluindo dados de reclamações, de inscrições e de farmácia. Com o Amazon SageMaker Data Wrangler, podemos acelerar o tempo necessário para agregar e preparar dados para ML usando um conjunto de fluxos de trabalho mais fáceis de validar e reutilizar. Isso melhorou drasticamente o tempo de entrega e a qualidade de nossos modelos, aumentou a eficácia de nossos cientistas de dados e reduziu em quase 50% o tempo de preparação de dados. Além disso, o SageMaker Data Wrangler nos ajudou a economizar várias iterações de ML e níveis significativos de tempo de GPU, acelerando todo o processo de ponta a ponta para nossos clientes, pois podemos desenvolver data marts com milhares de atributos, incluindo farmácia, códigos de diagnóstico, consultas de emergência, internações, bem como dados demográficos e outros determinantes sociais. Com o SageMaker Data Wrangler, podemos transformar nossos dados com eficiência superior para criar conjuntos de dados de treinamento, gerar insights de dados em conjuntos de dados antes de executar modelos de ML e preparar dados reais para inferências e previsões em grande escala.”
Lucas Merrow, CEO da Equilibrium Point IoT
Comece a usar o SageMaker Data Wrangler
Blogs
Vídeos
AWS re:Invent 2023: Democratize ML with no code/low code using Amazon SageMaker Canvas (AIM217)
AWS re:Invent 2023: New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company (AIM363)
Novidades
- Data (do mais recente ao mais antigo)