AWS 기술 블로그
Category: Amazon Machine Learning
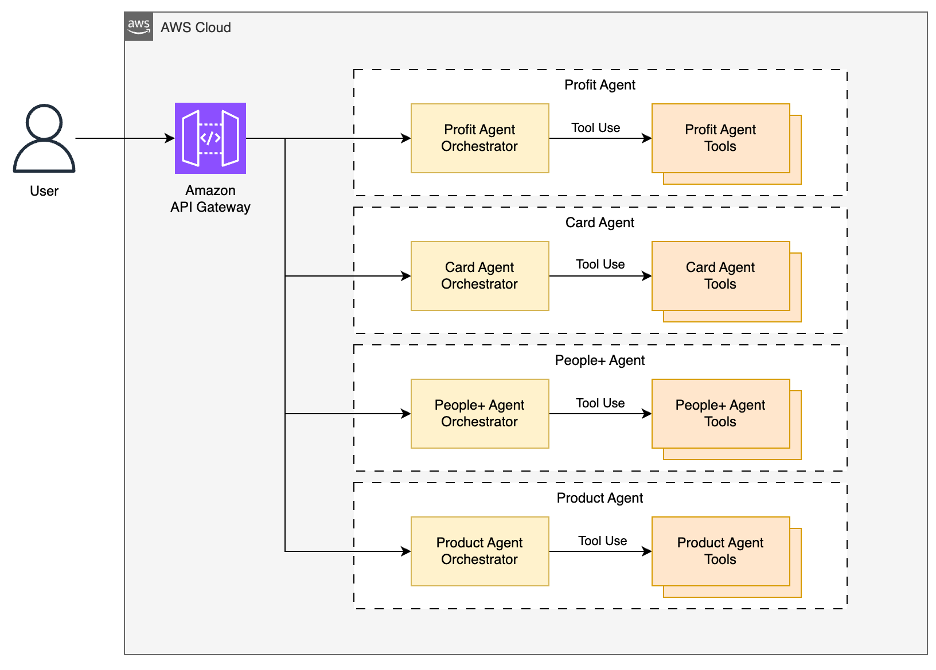
KCC의 Amazon Bedrock Tool Use를 활용한 Multi Agent 플랫폼 구축 사례
/* 이 블로그는 KCC 의 박상찬님이 블로그 주요 저자로 작성 해주셨습니다. */ KCC는 건축자재, 도료, 첨단소재(실리콘 등) 분야에서 국내외 시장을 선도하는 대기업으로, 1958년 설립 이후 내장재, 단열재, 도료, 판유리 등 다양한 건축 및 산업자재를 생산하며 업계 1위의 시장지위를 확보하고 있습니다. 최근 KCC는 글로벌 실리콘 기업 인수를 통해 실리콘 사업을 확대하고, 동시에 전기차 등 미래 산업을 […]

Smart Agentic AI 구축을 위한 데이터베이스 설계
들어가며 에이전트 서비스 특히, MCP(Model Context Protocol) 서버가 새로운 메인 트렌드로 부상하고 있습니다. 많은 것들이 빠르게 변하고, 그 변화에 적응하기 조차 어려운 시대가 되었습니다. 이 블로그에서는 에이전트 서비스들의 근간에 흐르는 데이터에 초점을 맞추고자 합니다. 에이전트 아키텍쳐는 여러가지 종류가 있습니다. 비동기 Pub/Sub 메시징 기반의 멀티에이전트 프레임워크인 AutoGen, 오늘 중점적으로 논의할 그래프 기반의 워크플로우를 자유롭게 정의하는 LangGraph, […]

경농의 스마트팜 지원을 위한 농업 AI 챗봇
경농 소개 (주)경농은 1957년 설립 이후 한국농업의 혁신을 이끈 대표 농산업 전문 기업입니다. 70년간의 역사와 전통을 바탕으로 비료와 작물보호제를 비롯해 종자, 신선도유지제, 친환경자재 등 농산업 전반을 아우르며, 이러한 기술력을 바탕으로 2022년 스마트팜 전문 브랜드 ‘시그닛(SIGNIT)’을 출범했습니다. 시그닛 브랜드는 스마트팜의 ▲자동화 ▲정밀농업 ▲무인관리 3가지 핵심기술을 통합해 국내 맞춤형 스마트팜 기술을 보급해 지속가능한 첨단 농업생태계를 구축하고 있습니다. […]
Amazon Bedrock을 활용한 Omelet의 경로 최적화 AI 에이전트, TOAST
/* 이 블로그는 Omelet 사의 Juni Lee 님, Seunghyun Kang 님, Jiwoo Son 님이 주 블로그 저자로 글을 써 주셨습니다. */ Omelet은 KAIST 교수진이 창업한 스타트업으로, 산업 현장의 복잡한 의사결정 문제를 해결하기 위해 최적화 알고리즘과 머신러닝을 결합한 AI 기반 솔루션을 개발하고 있습니다. 예를 들어 수많은 배송지와 차량, 시간 제약 등을 고려하여 효율적인 물류 경로를 도출하거나, […]

Amazon Bedrock을 활용한 MCP 허브 아키텍처로 기업의 AI 시스템 비즈니스 민첩성 가속화
이 게시글은 AWS Artificial Intelligence Blog의 “Accelerating AI innovation: Scale MCP servers for enterprise workloads with Amazon Bedrock by Xan Huang“ 를 번역 및 편집 하였습니다. 생성형 AI는 새로운 도구, 서비스 및 모델이 자주 출시되면서 빠른 속도로 발전하고 있습니다. Gartner에 따르면, 에이전트 AI는 2025년 주요 기술 트렌드 중 하나이며, 조직들은 기업 환경에서 에이전트를 활용하는 방법에 […]

Amazon Bedrock을 이용한 지능형 쇼핑 어시스턴트 구현하기
배경 생성형 AI가 공개된 이후로 쇼핑 경험 전환에 사용하려는 시도가 다양하게 있었습니다. 이제 단순히 상품을 검색하고 구매하는 경험을 넘어 탐색형 쇼핑으로 나아가는 과도기라고 할 수 있습니다. AI 검색을 지향하는 Perplexity에서 2024년 11월에 쇼핑 어시스턴트 기능을 출시하기도 했으며 Amazon.com에서는 Rufus를 출시했습니다. Amazon Rufus는 생성형 AI 기반 쇼핑 어시스턴트로, 고객이 상품을 검색하고, 비교하고, 추천을 받고, 구매 결정을 […]

Amazon OpenSearch Service의 AI Search Flow를 활용한 손쉬운 AI 기반 검색 기능 구현
“이 게시글은 AWS Big Data Blog의 “Amazon OpenSearch Service launches flow builder to empower rapid AI search innovation by Dylan Tong” 글을 편집, 번역하였습니다. 이제 Amazon OpenSearch Service의 OpenSearch 2.19+ 도메인에서 AI Search Flow 빌더에 액세스하여 AI 검색 애플리케이션을 더 빠르게 구축할 수 있습니다. 시각적 디자이너를 통해 색인과 검색 중에 수행되는 AI 기반 데이터 전처리 […]

무신사의 AI 기반 상품 추천 및 검색 시스템 구현 사례
무신사는 2001년 온라인 패션 커뮤니티로 시작하여 현재 약 1,500만 명의 회원을 보유한 국내 최대 패션 플랫폼으로 성장했습니다. 무신사 스토어에는 스트릿, 캐주얼, 디자이너, 하이엔드, 명품 등 다양한 브랜드가 입점해 있으며, 고객 맞춤형 쇼핑 경험을 제공합니다. 무신사는 패션 매거진, 오프라인 편집숍 등 다양한 사업을 전개하여 패션 생태계 전반을 아우르고 있으며, 최근에는 여성 패션, 라이프스타일, 뷰티 등으로 카테고리를 […]

기업간 전자 문서 교환을 위한 AWS상에서의 EDI처리 자동화
EDI(전자 데이터 교환)는 기업 간에 비즈니스 문서와 정보를 표준화된 전자 형식으로 교환하는 시스템으로, 국내외에서도 다양한 분야에 도입되면서, 온라인 전자상거래, 주문 관리, ERP 등 다양한 시스템과의 연계도 활발해지고 있습니다. 하지만 아직도 많은 산업에서 내부 프로세스, 비용, 보안, 인력 부담, 그리고 기술적 문제등의 이유로 도입이 더딘 상태입니다. 대표적인 예시로 미국 건강보험품질위원회(CAQH)에 따르면 매년 보험금 청구의 약 10%, […]

당근페이의 Amazon Bedrock 기반 Text-to-SQL로 완성하는 데이터 혁신, Part 2: 데이터 수집과 관리, 향후 계획
지난 1부에서는 전반적인 아키텍처와 동작 방식에 대해서 소개했습니다. 이번 2부에서는 브로쿼리 답변 정확도에 중요한 영향을 미치는 메타데이터의 수집 및 관리하는 방법과 향후 계획에 대해 다룹니다. 1부 다시보기 : Part 1: 브로쿼리 개요와 아키텍처 데이터 수집 <데이터 수집 구조> 1부에서 언급한 바와 같이, 충분하고 적절한 컨텍스트를 전달하기 위해서는 양질의 데이터가 필수적입니다. 브로쿼리가 활용 가능한 데이터를 크게 […]