Amazon Web Services 한국 블로그
Amazon AppFlow 출시 – SaaS 데이터 연동 및 자동화 서비스 (서울 리전 포함)
서비스형 소프트웨어(SaaS) 애플리케이션은 우리 고객에게 더욱 중요성이 커지고 있으며, 도입 속도도 급격히 빨라지고 있습니다. 이런 소프트웨어 사용 방식은 여러 가지 장점이 있지만, 데이터가 여러 위치에 저장된다는 문제가 있습니다. 이 데이터에서 의미 있는 분석 정보를 얻으려면 분석할 수단이 필요하지만, 데이터가 서로 고립된 위치에 흩어져 저장된다면 분석이 어려울 수 있습니다.
일반적으로 개발자는 SaaS 애플리케이션과 AWS 서비스 간에 데이터를 전달하여 분석할 수 있는 맞춤형 통합을 개발하는 데 엄청난 시간을 할애하고, 이런 작업은 보통 완료하기까지 몇 개월이 걸립니다. 데이터 요구 사항이 바뀐다면 복잡하고 비용이 많이 들어가는 과정을 거쳐 통합을 수정해야 합니다. 엔지니어링 인력이 풍부하지 않은 기업은 애플리케이션에서 직접 데이터를 가져오고 내보내야 할 수도 있습니다. 이는 시간이 오래 걸리고, 데이터 유출의 위험이 있으며, 인간의 실수가 발생할 가능성이 있습니다.
오늘은 이런 문제를 해결해줄 Amazon AppFlow라는 새로운 서비스 출시 소식을 알려드리려고 합니다. Amazon AppFlow를 사용하면 AWS 서비스와 Salesforce, Zendesk, ServiceNow와 같은 SaaS 애플리케이션 사이의 데이터 흐름을 자동화할 수 있습니다. SaaS 애플리케이션 관리자, 비즈니스 분석가, BI 전문가들은 IT 부서에서 통합 프로젝트를 완료할 때까지 몇 개월이나 기다릴 필요 없이 대부분 통합을 신속히 구현할 수 있습니다.

SaaS 애플리케이션에서 AWS 서비스로 데이터를 옮겨줄 뿐만 아니라, AWS 서비스에서 SaaS 애플리케이션으로 데이터를 보낼 수도 있습니다. AWS는 보안을 가장 중요하게 생각하기 때문에 모든 데이터는 암호화되어 전송됩니다. 일부 SaaS 애플리케이션은 AWS PrivateLink와 통합해서 보안과 개인정보 보호를 한층 더 강화할 수 있습니다. AWS PrivateLink를 적용한 상태에서 SaaS 애플리케이션과 AWS 사이에 데이터를 전송하면 트래픽이 공개 인터넷을 통하지 않고 Amazon 네트워크에 머물게 됩니다. SaaS 애플리케이션에서 지원할 경우, Amazon AppFlow가 자동으로 이 연결을 설정합니다. 누구나 쉽게 비공개 데이터를 전송하고 인터넷상의 공격에서 발생하는 위협과 민감한 데이터 유출 위험을 최소화할 수 있습니다.
정기적으로, 비즈니스 이벤트가 있을 때, 또는 원하는 때에 데이터가 전송되도록 예약해서 신속하고 유연하게 데이터를 공유할 수 있습니다.
신규 서비스의 기능을 보여드리려면 간단한 플로우를 설정하는 방법을 보여드리는 게 좋겠다는 생각이 들었습니다. 웹 커뮤니티 관리자로서 저는 영국과 아일랜드에서 Slack 작업 영역을 운영합니다. Slack이 Amazon AppFlow에서 지원하는 SaaS 애플리케이션이기 때문에 대화 데이터 일부를 S3로 가져오는 걸 보여드리기로 했습니다. 대화 데이터를 S3에 가져오고 나면 Amazon Athena를 사용해서 분석한 다음, Amazon QuickSight를 사용해서 시각 자료를 생성할 수 있습니다.
먼저 Amazon AppFlow 콘솔로 이동해서 [플로우 생성] 버튼을 클릭합니다.
다음에는 플로우 이름과 플로우 설명을 입력합니다. 또한, 데이터 암호화 옵션은 몇 가지가 있습니다. 기본적으로 모든 데이터는 암호화된 상태로 전송되고 S3에서는 저장된 데이터도 암호화됩니다. 직접 암호화 키를 입력하는 옵션이 있지만, 이 데모에서는 계정에서 기본적으로 제공되는 키를 사용하겠습니다.
이 단계에서는 리소스에 태그를 입력하는 옵션도 제공됩니다. 저는 계정에 있는 데모 인프라에 Demo라는 태그를 붙이는 습관이 있습니다. 어떤 리소스를 삭제할 수 있는지 쉽게 구분할 수 있기 때문입니다.

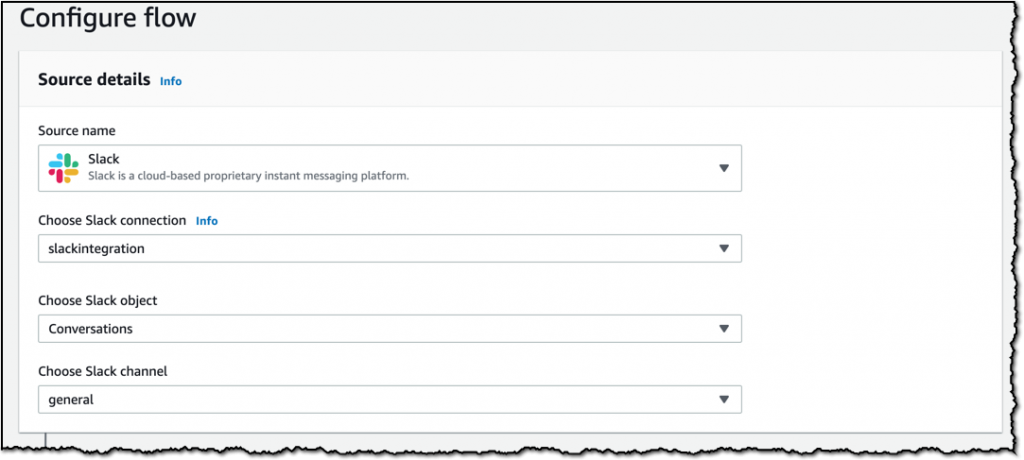
다음 단계에서는 데이터 소스를 선택합니다. 저는 Slack을 선택하였고 마법사를 통해 Slack 작업 영역과 연결합니다. 또한, Slack 작업 영역으로 가져올 데이터를 선택해야 합니다. 저는 Slack 내 #general 채널에 있는 Conversations 객체를 선택했습니다. 그러면 general 채널에 게시된 모든 메시지를 가져와서 대상으로 전송합니다. 그 대상은 다음 단계에서 구성합니다.
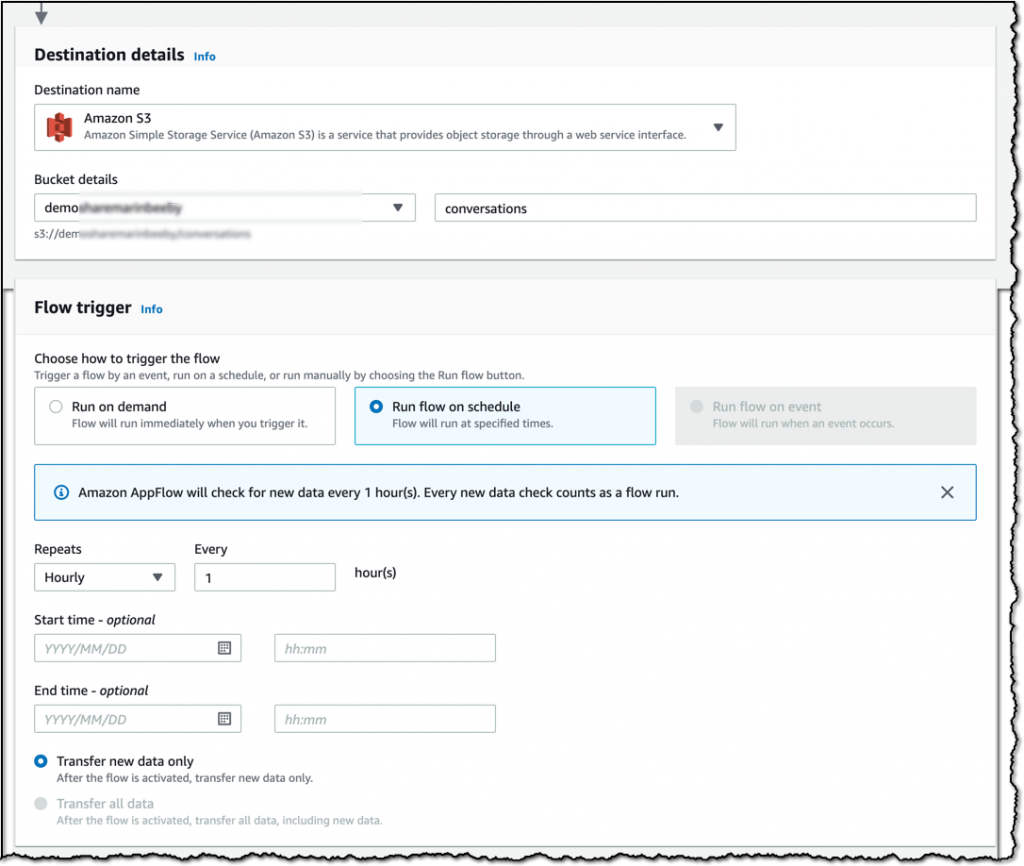
제가 선택할 수 있는 대상은 몇 가지가 있지만 간단하게 S3 버킷으로 데이터를 전송하겠습니다. 이번 단계에서는 데이터를 가져올 빈도도 설정합니다. 데이터를 1시간마다 조회하려면 [규칙적으로 플로우 실행]을 선택하고 필요한 구성을 설정합니다. Slack은 원하는 때에, 또는 규칙적으로 트리거할 수 있습니다. 어떤 리소스는 특정 이벤트가 발생하면 트리거할 수도 있습니다. 예를 들어, Salesforce에서 잠재 고객을 전환하는 이벤트가 이에 해당합니다.
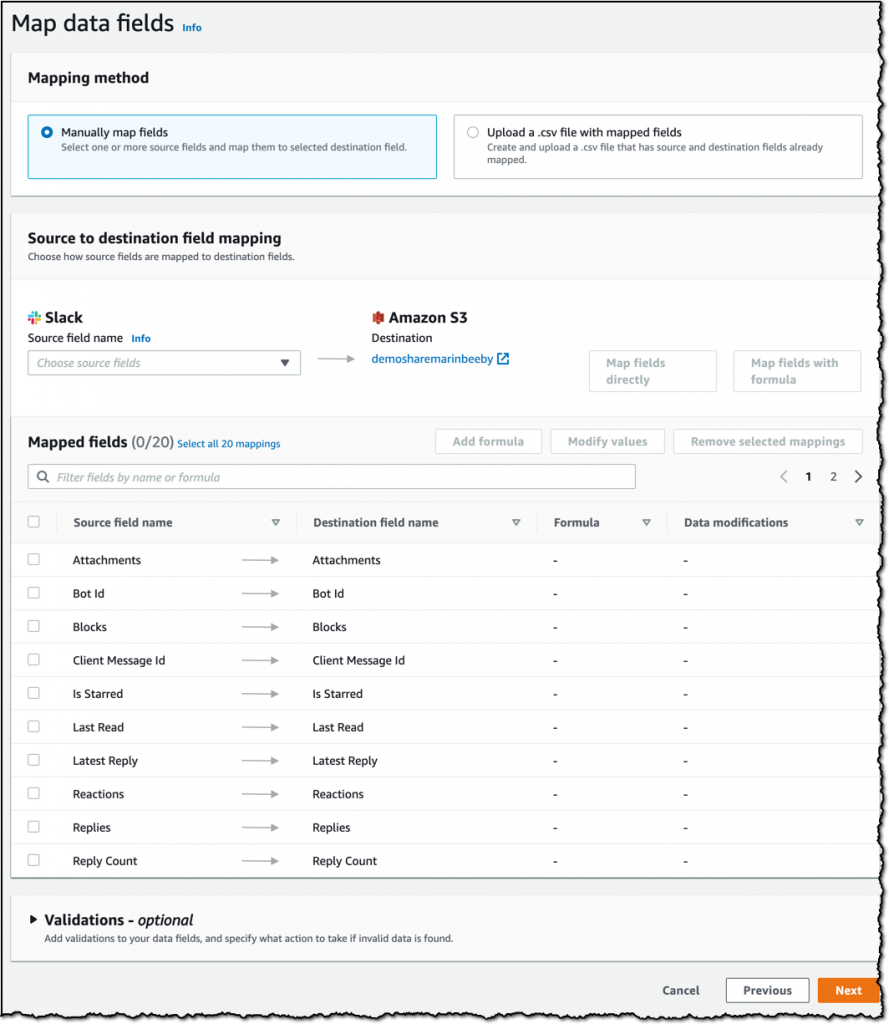
다음 단계는 데이터 필드 매핑입니다. 저는 기본값을 선택하겠지만 여러분은 원하는 대로 선택해 필드를 결합하거나 분석에 필요한 특정 필드만 설정할 수도 있습니다.
플로우가 생성되어 활성화했습니다. 플로우는 1시간마다 자동으로 실행되면서 S3 버킷에 새 데이터를 추가합니다.

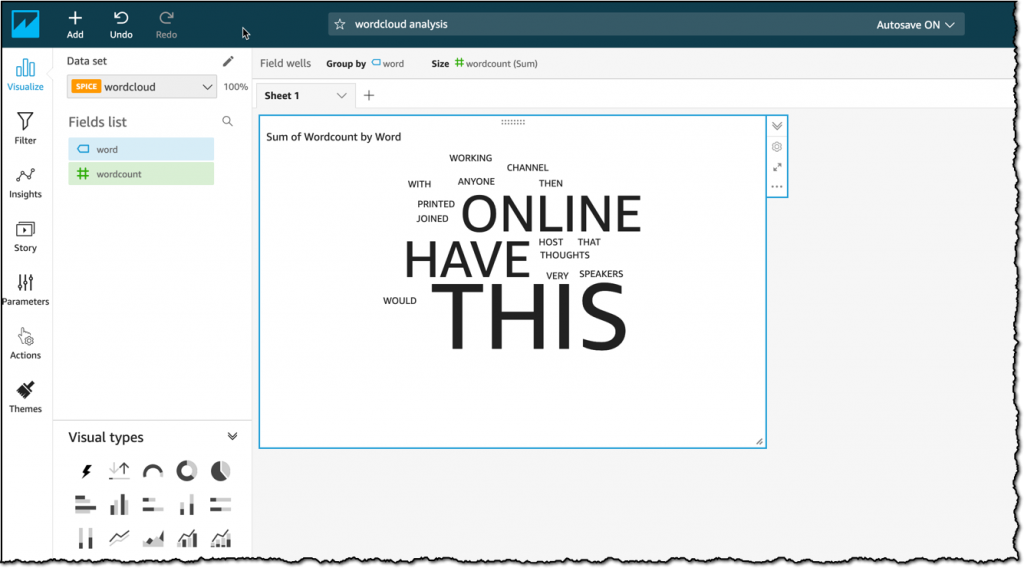
Amazon Athena나 Amazon QuickSight에 대한 자세한 설명은 생략했지만, 이 두 가지 AWS 서비스를 사용해서 S3에 저장된 데이터로 제 Slack 채널에서 가장 자주 사용된 단어 클라우드를 만들었습니다.
Athena는 추가적인 데이터 웨어하우스 없이도 S3의 암호화된 데이터에 바로 SQL 쿼리를 실행할 수 있다는 장점이 있습니다. 결과는 아래의 이미지에서 확인하실 수 있습니다. 이제 결과는 조직 내 모든 사람과 대시보드 형태로 손쉽게 공유할 수 있습니다.
Amazon AppFlow는 오늘 정식 출시되었습니다. S3 및 13개 SaaS 애플리케이션을 데이터 소스로, S3, Amazon Redshift, Salesforce, Snowflake를 대상으로 지원합니다. 서비스가 개발됨에 따라 앞으로 수백 개가 추가로 지원될 예정입니다.
이 서비스는 사용자가 정한 요구 사항에 따라 자동으로 확장되거나 축소되며, 한 번의 플로우에서 100GB까지 전송할 수 있어서 데이터를 배치 단위로 나눌 필요가 없습니다. 고가용성과 탄력성을 고려하여 설계하였기 때문에 그 어떤 중요한 데이터도 Amazon AppFlow에 믿고 맡기실 수 있습니다.
현재 Amazon AppFlow는 미국 동부(북부 버지니아), 미국 동부(오하이오), 미국 서부(북부 캘리포니아), 미국 서부(오레곤), 캐나다(중부), 아시아 태평양(싱가포르), 아시아 태평양(도쿄), 아시아 태평양(시드니), 아시아 태평양(서울), 아시아 태평양(뭄바이), 유럽(파리), 유럽(아일랜드), 유럽(프랑크푸르트), 유럽(런던), 남아메리카(상파울루)에서 제공되며, 앞으로 리전이 추가될 예정입니다.
즐겁게 데이터를 전송하세요.