Category: Auto Scaling
대상 추적 통계를 활용한 유연한 EC2 자동 스케일링 정책 구성 기능 출시
최근 DynamoDB의 자동 스케일링(Auto Scaling)을 통해 DynamoDB 테이블 용량 관리를 자동화하기 위해 어떻게 다중 CloudWatch 알람을 이용하고 있는지를 소개하였습니다. 앞으로 여러 가지 AWS 서비스에 일반 Application Auto Scaling 모델을 사용하여 지속적으로 기능을 추가하고자 하고 있습니다.
새로운 자동 스케일링 모델은 대상 추적(target tracking)이라는 중요한 새로운 기능을 가지고 있습니다. 대상 추적을 사용하는 자동 확장 정책을 만들 때 특정 CloudWatch 메트릭에 대한 대상 값을 선택합니다. 그런 다음 자동 스케일링을 사용하여 적절한 노브 (말하자면)를 돌려 추적 대상을 값에 따라서 관련 CloudWatch 알람을 조정합니다. 통계치 기반 단위가 애플리케이션에 적합한 지 여부와 관계없이 원하는 목표를 지정하는 것은 일반적으로 원래 단계별 확장 정책 유형을 사용하여 범위 및 임계 값을 수동으로 설정하는 것보다 간단합니다. 그러나, 단계별 확장과 함께 대상 추적을 사용하여 고급 확장 전략을 구현할 수 있습니다. 예를 들어, 스케일-아웃 작업의 경우 대상 추적을 사용하고 스케일-인의 경우 단계별로 사용할 수 있습니다.
EC2에 신규 자동 스케일링 대상 추적 기능 출시
오늘 EC2 자동 스케일링 기능에 대상에 따른 추적 지원을 추가했습니다. Application Load Balancer 요청 수, CPU 부하, 네트워크 트래픽 또는 고객 측정에 의한 스케일링 정책을 만들 수 있습니다. (Request Count per Target이 새롭게 추가된 통계치입니다.)
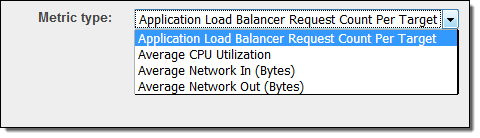
이 통계치는 중요한 특징을 가지고 있습니다. EC2 인스턴스를 추가하여 (전체 부하가 변화하지 않을 때) 통계치를 낮추는 것입니다. 혹은 그 반대의 경우도 있습니다.
대상 추적을 사용한 Auto Scaling Group을 만드는 것은 아래 그림처럼 정책 이름, 입력 통계치 선택, 원하는 대상 값 설정만 하면 됩니다.
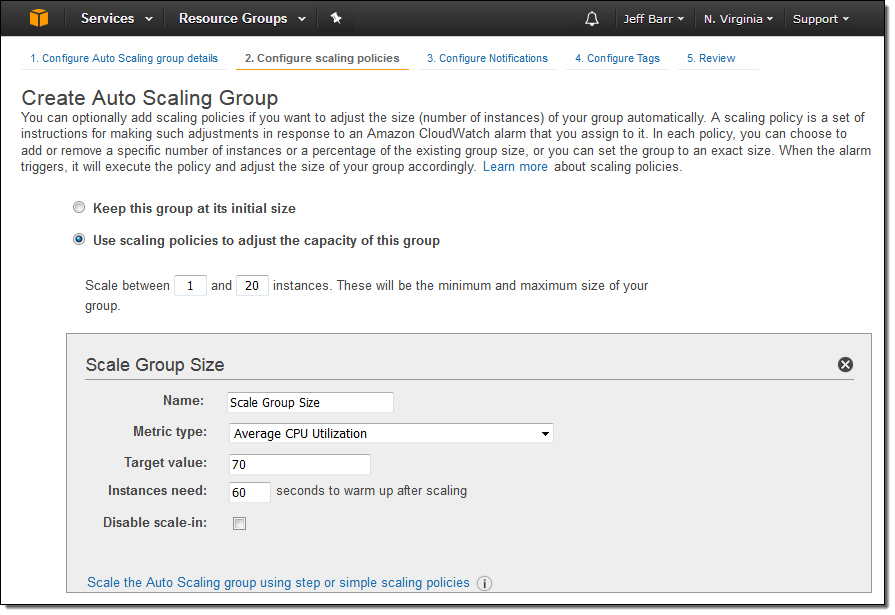
스케일-인 측의 정책을 선택적으로 해제 할 수도 있습니다. 이 경우 수동으로 스케일-인하거나 다른 정책을 사용할 수 있습니다.
대상 추적 정책은 AWS 관리 콘솔, AWS 명령줄 (CLI), AWS SDK도 만들 수 있습니다.
다음은 대상 추적을 사용하려고 할 때 미리 설정할 항목입니다.
- 하나의 Auto Scaling Group 대해 다른 통계치를 참조하여 여러 대상을 설정할 수 있습니다. 스케일링은 항상 가장 높은 용량을 요구하는 정책을 따릅니다.
- 통계치 데이터가 불충분 한 경우에는 스케일링을 하지 않습니다.
- 자동 스케일링은 통계치가 급속하게 일시적인 변동을 보완하여, 컴퓨팅 용량의 급격한 변동을 최소화하려고 노력합니다.
- 맞춤 측정 대상에 대한 추적 Auto Scaling API 또는 AWS 명령줄 (CLI)를 통해 설정할 수 있습니다.
- 많은 경우에 1 분 간격으로 들어오는 통계(상세 모니터링 방식)에 따라 확장하도록 선택해야 합니다. 5분 간격으로 하는 경우, 반응 시간이 늦어질 수 있습니다.
정식 출시
본 기능은 오늘부터 이용 가능하며, 리소스 요금 이외 추가 요금없이 사용할 수 있습니다. 더 자세한 내용은 Auto Scaling 사용자 가이드 및 대상 추적 스케일링을 참조하십시오.
— Jeff;
이 글은 New – Target Tracking Policies for EC2 Auto Scaling의 한국어 번역입니다.
오토스케일링 신규 기능 – 인스턴스 보호하기
EC2 인스턴스에서는 고객이 만든 조건에 따라 서버의 숫자를 증가 혹은 감소할 수 있는 오토 스케일링을 이용할 수 있습니다. 스케일 아웃(Scale-out)을 통해서 고객의 요구에 맞는 트래픽 처리를 위한 컴퓨팅 성능을 확보할 수 있고, 스케일 인(Scale-in)을 통해 줄어든 트래픽에 대응해 비용을 줄일 수 있습니다.
오토스케일링에서 서버가 감소되는 스케일인 상황에서 인스턴스를 제어할 수 있는 추가 기능을 소개합니다. 과거에는 어떤 특별한 방법 없이 모든 오토스케일링 그룹 내 모든 인스턴스가 제거될 수 있습니다. 신규 제어 기능을 사용하시면, 특정 인스턴스를 제거하지 않도록 보호 할 수 있습니다.
이러한 기능을 추가한 것은 몇 가지 이유가 있습니다. 먼저 특정 인스턴스가 SQS 큐를 받아주는 것 같은 긴 시간 동작하는 작업을 진행하는 경우, 인스턴스 보호를 통해 작업이 소실 되는 것을 막아줄 수 있습니다. 두번째는 특정 인스턴스가 오토스케일링 그룹내에서 특별한 역할을 하는 경우, 즉 Hadoop 클러스터의 마스터 노드라던가 다른 인스턴스가 띄워져 실행되는 것을 모니티렁 하는 경우 등입니다.
스케일인 상황에서 인스턴스 보호하기
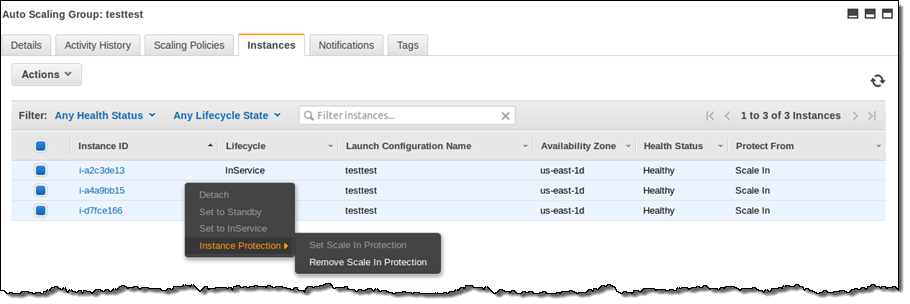
오토스케일링 콘솔에서 Actions 메뉴의 Instance Protection를 선택하여 특정 인스턴스를 스케일인 상황에서도 제거되지 않도록 할 수 있습니다.
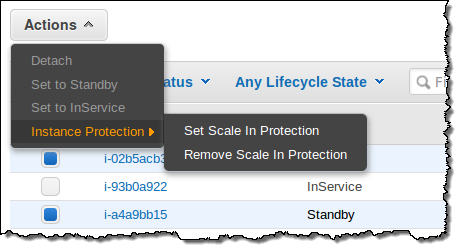
아래에서 확인해 볼 수 있습니다.
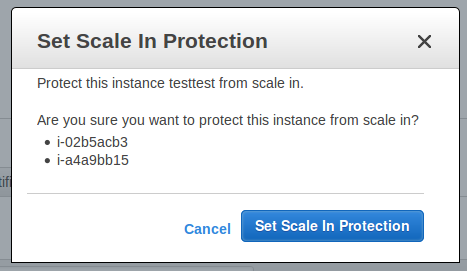
콘솔 내에서 각 인스턴스의 보호 상태를 확인할 수 있습니다.
SetInstanceProtection API 함수를 통해서도 이러한 기능을 수행할 수 있습니다. 만약 장시간 큐 기반 워커 프로세스를 스케일인 상황에서 보호하려면, 다음과 같은 슈도 코드를 사용할 수 있습니다.
while (true)
{
SetInstanceProtection(False);
Work = GetNextWorkUnit();
SetInstanceProtection(True);
ProcessWorkUnit(Work);
SetInstanceProtection(False);
}대부분의 경우, 오토스케일링 그룹에서 적어도 하나의 인스턴스를 남겨둘 수 있습니다. 그러나, 모든 인스턴스를 보호하게 되면, 스케일인 동작은 일어나지 않습니다. 더 자세한 사항은 오토스케일링 라이프 사이클 문서를 참고하시기 바랍니다.
이 기능은 오늘부터 사용 가능합니다.
— Jeff;
PS – AWS SDKs는 2015년 12월 8일 부터 SetInstanceProtection API 함수를 통해 사용 가능합니다.
이 글은 New – Instance Protection for Auto Scaling의 한국어 번역본입니다.
신규 오토 스케일링 반응형 정책 업데이트
이 글에서 지금까지 AWS에서 오토스케일링을 사용하는 방법을 한번 집중 해부해보고, 이에 대해 그 이면에서 어떤 일들이 일어나는지 사항을 먼저 이야기 해보면 좋을 것 같습니다.
리소스 실행 및 종료 – 오토 스케일링을 위해서는 EC2 인스턴스를 필요한 만큼 실행하거나 없애야 하는데, AWS API를 활용하여 RunInstances 및 TerminateInstances 그리고 부가적으로 DescribeInstances를 사용 합니다.:
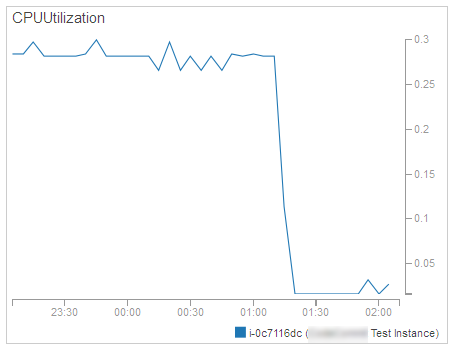
리소스 모니터링 – CPU 사용량, 네트웍 트래픽 등 다른 요소에 의해서 인스턴스가 개별적 혹은 그룹으로 얼마나 많은 리소스를 사용하느냐는 스케일링을 선택하는 주요 기준이고 Amazon CloudWatch를 활용해 왔습니다:
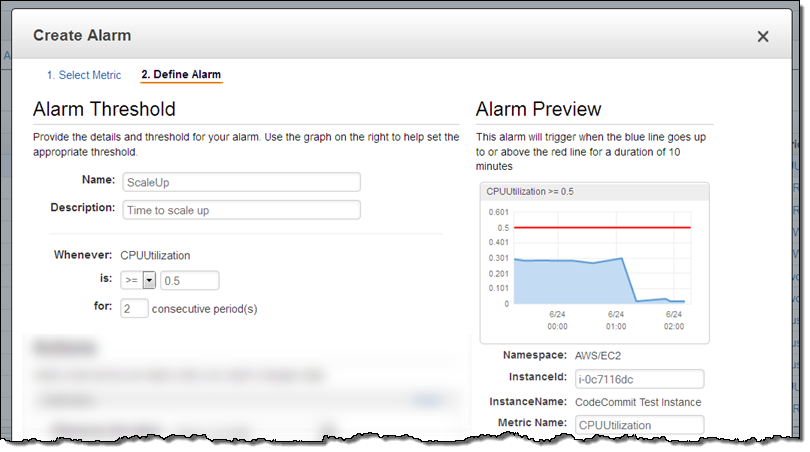
알림 보내기 – 자원의 사용량을 추적하여 스케일-인/아웃 시에 CloudWatch를 통해 알림을 보낼 수 있습니다.:
스케일링 실행 – 마지막으로 알람이 오면 실행을 하는데 이는 오토스케일링이 시작이 되는 것입니다.
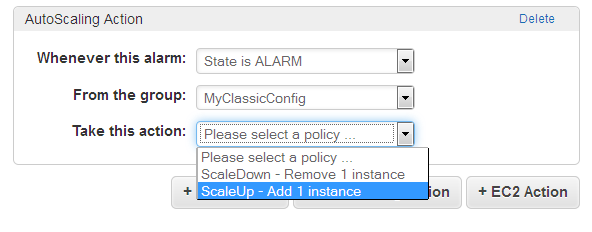 이 동작은 특정 오토스케일링 그룹 내에서 실행 되며, 이에 따라 특정 인스턴스를 시작 및 종료를 하게 되며 특정 퍼센테이지 혹은 숫자를 통해 인스턴스 숫자를 조정합니다.
이 동작은 특정 오토스케일링 그룹 내에서 실행 되며, 이에 따라 특정 인스턴스를 시작 및 종료를 하게 되며 특정 퍼센테이지 혹은 숫자를 통해 인스턴스 숫자를 조정합니다.
신규 스케일링 단계별 정책
오늘 부터 이전 보다 더 유연한 새로운 오토 스케일링 정책을 수행하는 단계를 소개해 드립니다.
그 목적은 트래픽이나 로드가 갑자기 증가할 때 대응하는 오토 스케일링 시스템을 만드는데 있습니다. 이제 magnitude라는 알람을 기반으로 원하는 스케일링 정책을 정할 수 있습니다. 예를 들어 평균 CPU 사용량을 50%로 잡고 있는데, 조금씩 CPU가 늘어나는 구간 즉, 50-60% 혹은 60-70%, 80% 이상 등 다양한 구간에서 인스턴스를 추가할 수 있습니다.
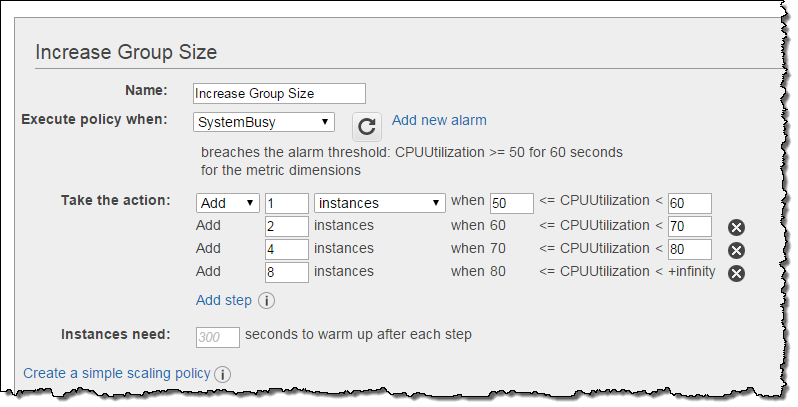
위에서 보시다시피 고정된 숫자의 인스턴스가(1, 2, 4 또는 8) 그룹에 있습니다. 사용 퍼센티지 기반으로 인스턴스 숫자를 정하고 단계별로 50%, 100%, 150% 및 200%로 증가시킬 수 있습니다. 이러한 비율은 스케일을 줄일때도 정책을 활용할 수 있습니다.
이러한 단계별 정책을 통해 알람을 통해 평가하여, 스케일링이 일어나는 도중에 인스턴스 헬스체크를 해서 문제가 있는 것은 새 것으로 교체합니다. 이를 통해 더 빠른 요구에 응답할 수 있습니다. CPU 로드가 계속 올라갔다면, 정책 중 첫 번째 단계가 시작되어 첫 워밍업(약 120초 정도) 기간 동안 더 빠르게 반응할 수 있습니다. 시스템 로드가 계속 증가하더라도 유연하게 대처할 수 있습니다. 여러분이 같은 리소스에 대해 다중 단계의 (CPU 사용량 및 네트워크 트래픽을 기반으로) 스케일링 정책을 만들 수 있다면, 갑작스런 트래픽에도 유연하게 대처할 수 있을 것입니다.
새로운 오토스케일링 정책은 AWS Command Line Interface (CLI)이나 Auto Scaling API를 사용하시면 됩니다.
새로운 기능은 오늘 부터 바로 사용 가능합니다.
— Jeff;
이 글은 Auto Scaling Update – New Scaling Policies for More Responsive Scaling의 요약 편집입니다.