Amazon Web Services 한국 블로그
Amazon Managed Streaming for Apache Kafka(MSK) – 정식 출시
최근처럼 데이터가 폭주하는 시대에 실시간 데이터 처리는 기본적인 요구 사항이 되었습니다. AWS 고객 중에도 전 세계적으로 신뢰도가 가장 높은 기업 및 전문가를 위한 뉴스 업체인 Thomson Reuters에서는 제품 팀이 사용자 경험을 지속적으로 개선하는 데 도움이 되는 분석 데이터를 캡처, 분석 및 시각화하는 솔루션을 구축했습니다. 헤이데이, 클래시 오브 클랜 및 붐비치 같은 게임을 제공하는 소셜 게임사인 Supercell은 매일 450억 개의 이벤트를 처리하면서 실시간으로 게임 내 데이터를 제공합니다.
AWS는 re:Invent 2013에서 Amazon Kinesis를 출시한 이후로 AWS 스트리밍 데이터의 작업 방식을 지속적으로 확장했습니다. 사용 가능한 일부 도구는 다음과 같습니다.
- 자체 애플리케이션을 통해 스트림을 캡처, 저장 및 처리할 수 있는 Kinesis Data Streams.
- 데이터를 변환하고 Amazon S3, Amazon Elasticsearch Service 및 Amazon Redshift 같은 대상으로 수집할 수 있는 Kinesis Data Firehose.
- SQL 또는 Java(Apache Flink 애플리케이션 사용)를 사용하여 데이터를 지속적으로 분석할 수 있는 Kinesis Data Analytics(예: 이상 탐지 또는 시계열 집계용).
- 미디어 스트림의 처리를 간소화할 수 있는 Kinesis Video Streams.
지난 re:Invent 2018에서는 Apache Kafka를 사용하여 스트리밍 데이터를 처리하는 애플리케이션을 손쉽게 구축하고 실행할 수 있는 완전관리형 서비스인 Amazon Managed Streaming for Apache Kafka(MSK)에 대한 미리 보기가 공개되었는데, 오늘 Amazon MSK가 정식 출시되었습니다!
Amazon MSK 서비스 소개
Apache Kafka(Kafka)는 클릭스트림 이벤트, 트랜잭션, IoT 이벤트, 애플리케이션 및 머신 로그 같은 스트리밍 데이터를 캡처하는 기능과 실시간 분석을 수행하고, 지속적인 변환을 실행하고, 이 데이터를 데이터 레이크 및 데이터베이스에 실시간으로 배포하는 애플리케이션을 제공하는 오픈 소스 플랫폼입니다. Kafka를 스트리밍 데이터 스토어로 사용하면 스트리밍 데이터를 생성하는 애플리케이션(생산자)과 스트리밍 데이터를 사용하는 애플리케이션(소비자)을 분리할 수 있습니다.
Kafka는 인기 높은 엔터프라이즈 데이터 스트리밍 및 메시징 프레임워크이기는 하지만 정식 서비스 환경에서 설정, 조정 및 관리가 어려울 수 있습니다. Amazon MSK는 이러한 관리 작업을 처리하며 고가용성 및 보안에 대한 모범 사례를 따르는 환경에서 Kafka와 Apache ZooKeeper의 설정, 구성 및 실행을 간소화합니다.
MSK 클러스터는 항상 MSK 서비스로 관리되는 Amazon VPC 안에서 실행됩니다. 다음 아키텍처 다이어그램에 설명된 것과 같이 계정에 표시되는 ENI(탄력적 네트워크 인터페이스)를 통해 자체 VPC, 서브넷 및 보안 그룹에서 MSK 리소스를 사용할 수 있습니다.
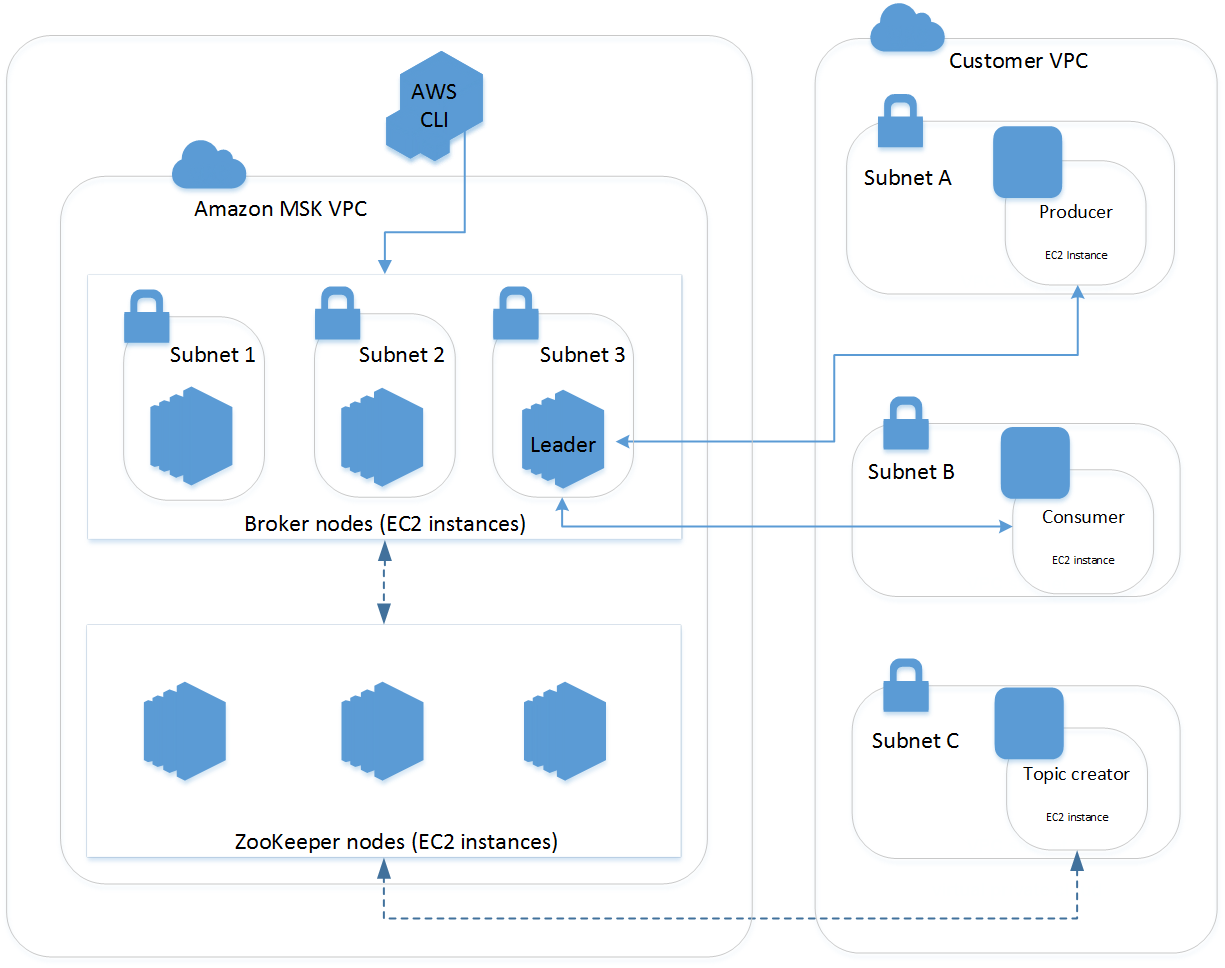
고객은 몇 분 안에 클러스터를 생성하고, AWS Identity and Access Management(IAM)를 사용하여 클러스터 작업을 제어하고, AWS Certificate Manager(ACM)로 완전히 관리되는 TLS 프라이빗 인증 기관을 사용하여 클라이언트를 인증하고, TLS를 사용하여 전송 데이터를 암호화하고, AWS Key Management Service(KMS) 암호화 키를 사용하여 저장된 데이터를 암호화할 수 있습니다.
Amazon MSK는 서버 상태를 지속적으로 모니터링하고 장애가 발생한 서버를 자동으로 대체하며, 서버 패치를 자동으로 적용하고, 고가용성 ZooKeeper 노드를 운영합니다. 이 모든 기능은 서비스의 일부로 추가 요금 없이 제공됩니다. 주요 Kafka 성능 지표는 콘솔과 Amazon CloudWatch에 게시됩니다. Amazon MSK는 Kafka 버전 1.1.1 및 2.1.0과 완벽하게 호환되므로 코드를 변경할 필요 없이 계속해서 애플리케이션을 실행하고, Kafka의 관리 도구를 사용하고, Kafka 호환 도구 및 프레임워크를 사용할 수 있습니다.
공개 미리 보기 중의 고객 피드백에 따라 다음과 같은 다수의 기능이 Amazon MSK에 추가되었습니다.
- TLS를 사용하여 클라이언트와 브로커 간 전송 데이터 및 브로커 간 전송 데이터 암호화
- ACM 프라이빗 인증 기관을 통한 상호 TLS 인증
- Kafka 버전 2.1.0 지원
- 99.9% 가용성 SLA
- HIPAA 적격
- 클러스터 전체 스토리지 확장
- MSK API 로깅을 위한 AWS CloudTrail 통합
- 클러스터 태그 지정 및 태그 기반 IAM 정책 에플리케이션
- 주제 및 브로커에 대한 사용자 지정 클러스터 전체 구성 정의
AWS CloudFormation 지원은 몇 주 안에 제공될 예정입니다.
Kafka 클러스터 생성하기
AWS 관리 콘솔을 사용하여 클러스터를 생성합니다. 클러스터 이름을 지정하고 클러스터를 사용하려는 VPC와 Kafka 버전을 선택합니다.

AZ(가용 영역)를 선택하고 VPC에서 사용할 서브넷을 선택합니다. 다음 단계에서 각 AZ에 배포할 Kafka 브로커 수를 선택합니다. 브로커가 많으면 여러 브로커에 파티션을 할당하여 클러스터 처리량을 확장할 수 있습니다.

태그를 추가하여 리소스를 검색 및 필터링하고, IAM 정책을 Amazon MSK API에 적용하고, 비용을 추적할 수 있습니다. 스토리지의 경우 브로커당 기본 스토리지 볼륨 크기를 유지합니다.
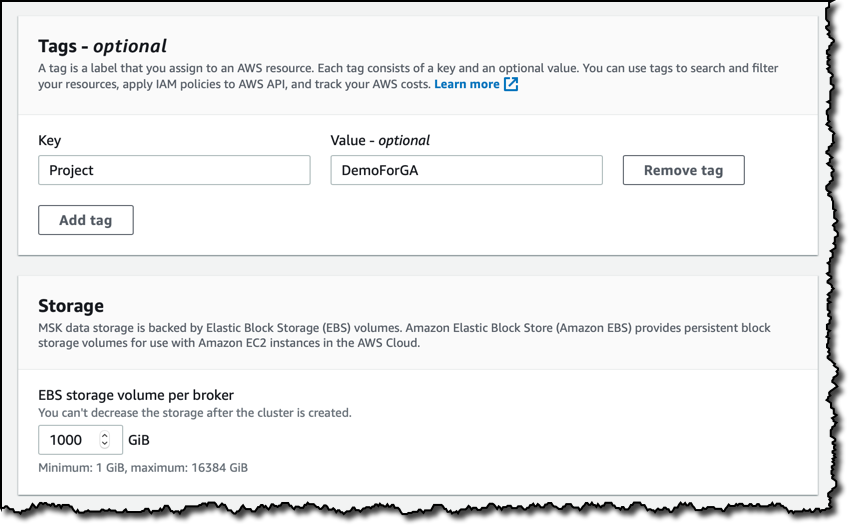
클러스터 내에서 암호화를 사용하고 클라이언트와 브로커 간의 TLS 및 일반 텍스트 트래픽을 허용하도록 선택합니다. 저장된 데이터의 경우 여기서는 AWS 관리형 CMK(고객 마스터 키)를 선택하지만 KMS를 사용해 계정의 CMK를 선택하여 제어를 확대할 수 있습니다. 프라이빗TLS 인증서를 사용하여 클러스터에 연결하는 클라이언트의 ID를 인증할 수 있습니다. 이 기능은 ACM의 프라이빗 CA(인증 기관)를 사용합니다. 지금은 이 옵션을 선택하지 않은 상태로 두겠습니다.

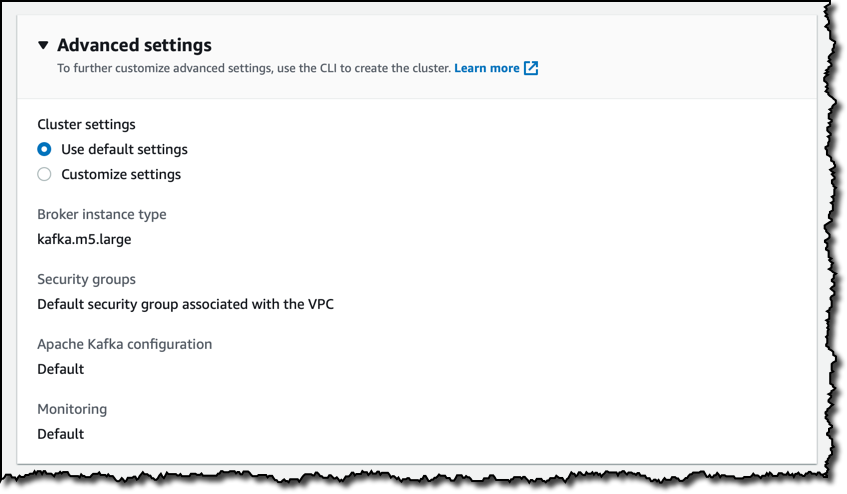
고급 설정에서 기본값을 유지합니다. 예를 들어 여기서 브로커에 대해 다른 인스턴스 유형을 선택할 수도 있습니다. 이러한 설정 중 일부는 AWS CLI를 사용하여 업데이트할 수 있습니다.
클러스터를 생성하고 클러스터 요약에서 CLI 또는 SDK를 통해 상호 작용할 때 사용할 수 있는 상태(예: ARN(Amazon 리소스 이름))를 모니터링할 수 있습니다..
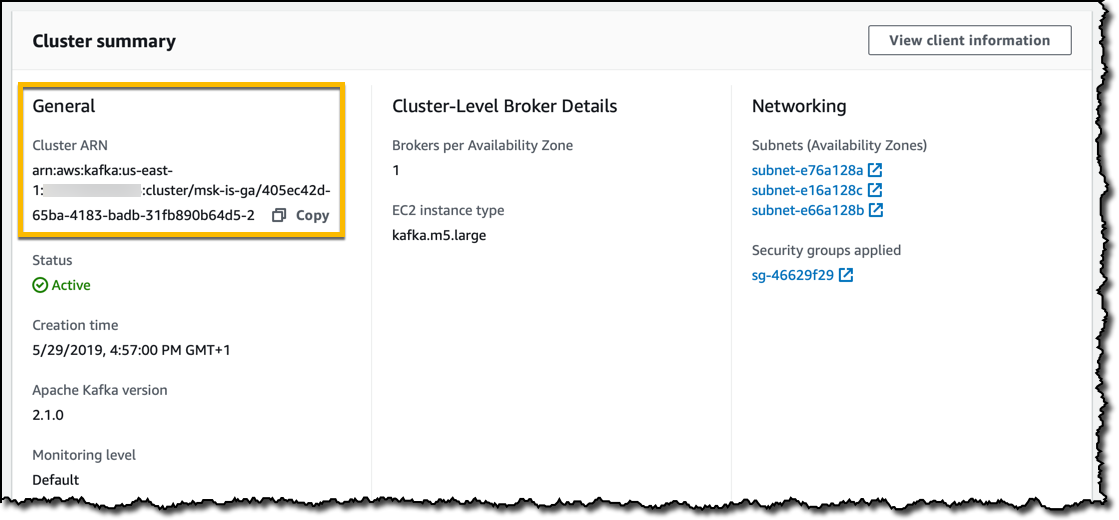
상태가 활성인 경우 클라이언트 정보 섹션에 클러스터 연결을 위한 다음과 같은 특정 세부 정보가 표시됩니다.
- Kafka 도구에서 클러스터에 연결할 때 사용할 수 있는 부트스트랩 서버.
- 호스트 및 포트의 Zookeper 연결 목록.
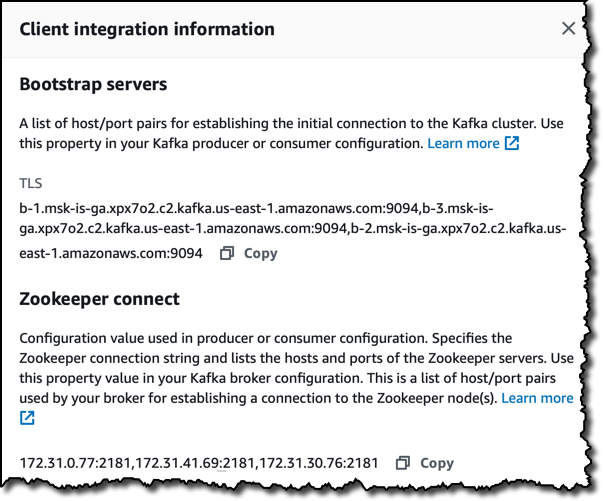
다음과 같이 AWS CLI를 사용하여 유사한 정보를 확인할 수도 있습니다.
aws kafka list-clusters: 특정 리전에 있는 클러스터의 ARN 보기aws kafka get-bootstrap-brokers --cluster-arn <ClusterArn>: Kafka 부트스트랩 서버 가져오기aws kafka describe-cluster --cluster-arn <ClusterArn>: Zookeeper 연결 문자열 등 클러스터의 세부 정보 보기
Kafka 사용에 대한 빠른 데모
Kafka 사용을 시작하기 위해 동일한 VPC에 생산자와 소비자로 사용할 EC2 인스턴스 2개를 생성합니다. 이 인스턴스를 클라이언트 머신으로 설정하기 위해 Apache 웹 사이트 또는 다른 미러에서 Kafka 도구를 다운로드하고 추출합니다. Kafka를 실행하려면 Java 8이 필요하므로 Amazon Corretto 8을 설치합니다.
생산자 인스턴스의 Kafka 디렉터리에 생산자 데이터를 소비자로 전송할 주제를 생성합니다.
bin/kafka-topics.sh --create --zookeeper <ZookeeperConnectString> \
--replication-factor 3 --partitions 1 --topic MyTopic
콘솔 기반 생산자를 시작합니다.
bin/kafka-console-producer.sh --broker-list <BootstrapBrokerString> \
--topic MyTopic
소비자 인스턴스의 Kafka 디렉터리에서 콘솔 기반 소비자를 시작합니다.
bin/kafka-console-consumer.sh --bootstrap-server <BootstrapBrokerString> \
--topic MyTopic --from-beginning
다음은 주제를 생성하고 생산자(상단 터미널)의 메시지를 해당 주제의 소비자(하단 터미널)로 전송하는 빠른 데모를 녹화한 것입니다.

요금 및 가용성
요금은 Kafka 브로커 시간 단위와 프로비저닝된 스토리지 시간 단위로 부과됩니다. 클러스터에 사용되는 Zookeeper 노드에는 요금이 없습니다. MSK 내부 및 외부로 전송되는 데이터에는 AWS 데이터 전송 요금이 적용됩니다. 브로커 간 데이터 전송 및 브로커와 ZooKeeper 노드 간 데이터 전송을 포함하여 리전의 클러스터 내에서 발생하는 데이터 전송에는 요금이 부과되지 않습니다.
MirrorMaker(오픈 소스 Kafka에 포함됨) 같은 도구를 사용하여 기존 클러스터의 데이터를 MSK 클러스터로 복제하는 방법으로 기존 Kafka 클러스터를 MSK로 마이그레이션할 수 있습니다.
업스트림 호환성은 Amazon MSK의 주요 원칙 중 하나입니다. Kafka 플랫폼에 대한 코드가 변경되는 경우 오픈 소스로 다시 릴리스됩니다.
Amazon MSK는 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), 아시아 태평양(도쿄), 아시아 태평양(싱가포르), 아시아 태평양(시드니), EU(프랑크푸르트), EU(아일랜드), EU(파리) 및 EU(런던)에서 제공됩니다. Amazon MSK를 다양한 방법으로 사용하여 스트리밍 애플리케이션을 간편하게 구축하고 해 보시기 바랍니다!
– Danilo Poccia, AWS 서버리스 전문 테크에반젤리스트