- AWS Builder Center›
- builders.flash
Amazon Bedrock を活用した Web ページ作成をアシストする仕組みの構築 ~ 株式会社ペライチによるページ作成 AI 機能の実装解説
2024-09-03 | Author : 藤代 康太 (株式会社ペライチ)
はじめに
弊社では「Technology for Everyone テクノロジーをすべての人が使える世界に」というビジョンのもと、直感的に分かりやすい操作でホームページを作ることができ、予約・決済などの機能も簡単に利用できる Web サービス「ペライチ (peraichi)」を提供しています。
AI の力でより簡単にホームページを作成することができる「ペライチクリエイトアシスタント」の開発事例を紹介します。実装の背景や、開発プロセス、実装にあたって採用した AWS の各種サービスについて紹介できればと思います。

builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
ページ作成におけるユーザー課題と新機能
弊社は主に SMB (Small to Medium Business) のユーザー様をターゲットにサービスを展開しています。ホームページ制作・運用にあたり現場のユーザーの方々が抱えている課題として「ページの内容を決めるのが難しい」や「社内にノウハウが蓄積されていない」、「制作費用が高い」といった課題が存在します。ペライチではこれらの課題に対して「誰でも簡単に初期費用無料で、600 種類以上のテンプレートから選んで編集するだけでページを作成・公開できる」サービスを提供することで課題解決に取り組んできました。
しかし、それでもユーザー様の中には
- そもそもどのテンプレートを選べばよいか分からない
- どのデザインパーツを追加したら良いか分からない
- いまあるページをイチから作り直すのはハードルが高い
といった課題を抱えているユーザー様が多く、ノーコードツールのホームページ作成エディターだけでは解決しきれない課題が残っているのも事実でした。
従来は弊社のカスタマーサポートのメンバーなどがテンプレートの選択やデザインパーツの選択、素材の移行などでサポートすることで解決に取り組んできました。
今回の機能は入力情報として外部の URL 情報を与え、そこからユーザー様のビジネスや商材、ページのユースケースなどの情報を抽出・要約し、それらの情報を元にしてページを生成することを試みています。「古いページを作り直すケース」や「既存の EC 販売サイトとは別に独自の EC サイトを立ち上げたい」などといったユースケースを想定しています。インプット情報を簡便化し、そこからユーザーに必要な情報を抽出・推論することで、今までヒューマンタッチでサポートしていた部分を一部生成 AI によって置き換えて、ユーザーの制作コストやリードタイムを削減できないかという試みをしています。
機能の全体像と採用した AWS サービス
アーキテクチャ図
STEP 1 : URL からの Web ページの情報の抽出・説明・要約
最初のステップでは入力された URL 情報から WEB ページの情報の抽出・説明・要約する処理を「AWS Step Functions」と「AWS Lambda」そして「Amazon Bedrock」を活用して実装しています。
URL 情報から HTML と WEB ページのスナップショットを取得し、構造化データから取得できるものは構造化データから、配色など構造化データだけでは取得できないものは WEB ページのスナップショットから取得・推論しています。そのため、基盤モデルとしては画像をインプットとして取り扱えるマルチモーダルモデルの Claude 3 Sonnet を利用しています。
Step Functions と Lambda を利用し、ユースケースの特定や情報の抽出、配色の推論を並列で処理することで生成の精度と速度の向上に取り組んでいます。
ワークフローは大きく 3 つのステップに分かれています。
- 1 : Web ページの HTML ファイルの取得と画面キャプチャの取得
- 2 : 取得した HTML と画面キャプチャを元にした情報の判定・抽出・要約
- 3 : 抽出・要約した情報の整形
Amazon Bedrock を利用しているのは主に 2 と 3 のステップです。
例えば 2 において、Web ページの情報を取得する際には「その Web ページがどのような目的で作成されているのか ?」といったページのユースケースによって抽出する情報や情報を抽出するためのプロンプトを分離させることで出力する情報の精度を上げています。具体的には対象とするページが 無形商材ないしは有形商材を販売する EC サイトなのか、またはイベントの予約を行うページなのかによって取得したい情報や取得するためのプロンプトが異なってくるためです。
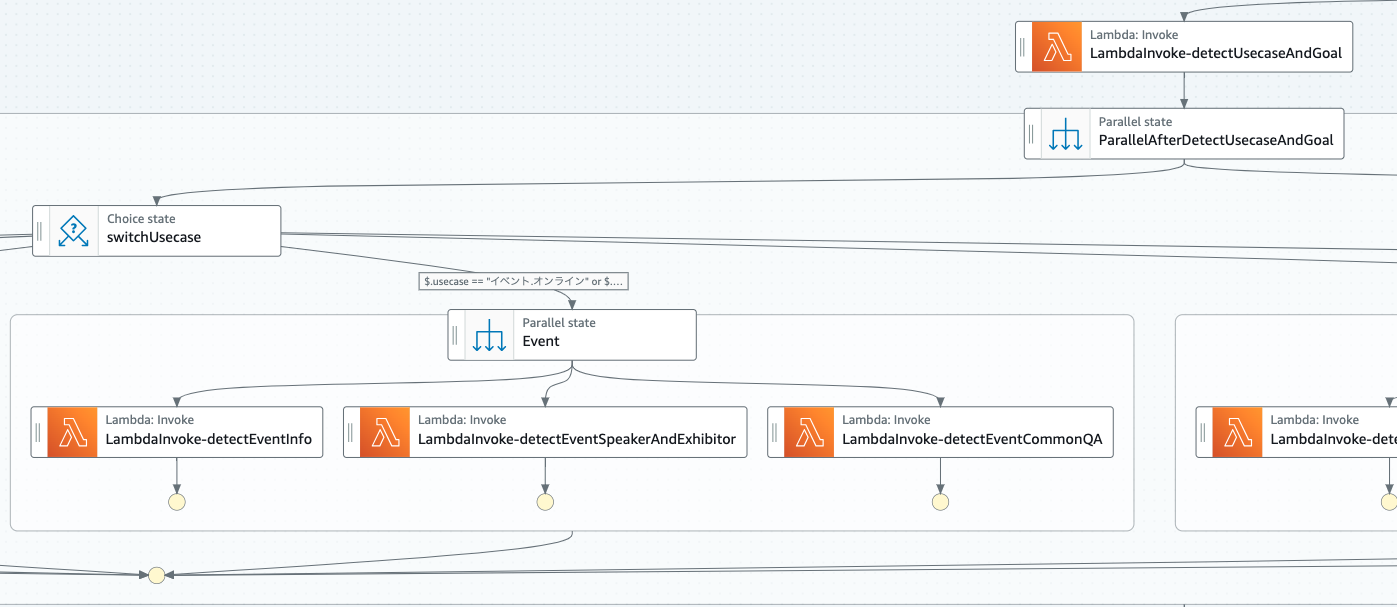
ワークフロー
図はそのフローの一部分です。この場合は、対象のページが「オンライン・オフラインなどのイベントの集客ページ」だった場合の分岐となります。
プロンプト
具体的にユースケースを判定するプロンプトは以下のようにしています。一部記述を省略しており、実際のプロンプトと異なる場合があります。
Human: あなたはユーザーが保有しているホームページの移行を支援するコンサルティングです。あなたの役割は、ホームページから情報を抽出して新しいホームページの仕様書を作成する支援をします。
画像データと <ホームページの情報> を参照して、 <抽出項目> に記載されている項目について抽出して回答します。記載のない情報は絶対に回答しないでください。
<回答手順>
* <回答のルール></回答のルール>を理解してください。このルールは絶対に守ってください。ルール以外のことは一切してはいけません。例外は一切ありません。
* あなたは<回答のルール></回答のルール>に従って回答を行なってください。
</回答手順>
<回答のルール>
* 日本語で回答してください。
* 回答のフォーマットはJavaScript Object Notation(JSON)です。JSONの前後には何も出力する必要ありません。
後続のシステムがあなたの出力するJSONを受け取ります。JSON以外の出力をすることは禁止です。例外は一切ありません。
* <output> のフォーマットを厳守して出力してください。例外はありません。
* <禁止事項>に記載のルールは絶対に守ってください。例外はありません。
</回答のルール>
<禁止事項>
* 要約は禁止
* 推測で記入するのは禁止. 確実な情報のみを抽出すること
* 画像データと <ホームページの情報> と <html> に記載のない情報は絶対に回答しないでください
* XMLタグの出力は禁止
* 定義されていないJSONの要素を追加する行為は禁止
</禁止事項>
<抽出項目>
* 各用語については以下に定義します。
"イベント"とは、展示会・見本市、スポーツイベント、講演会・シンポジウム、祭り、自治体主催イベント、音楽イベント・コンサート、興行、展示会・即売会、セレモニー・式典、学園祭などが該当します。イベントの告知やイベントのチケット販売も"イベント"に該当します。
・・・その他抽出項目候補に関する定義・・・
* このホームページのユースケースを以下のテーブル形式のリストから選択して、"usecase" に入力してください。"大項目.中項目.小項目.詳細"のように、"."で結合してください。
項目にない選択肢を選ぶことは禁止です。
| 大項目 | 中項目 | 小項目 | 詳細 |
|-----------------|------|-------|-----|
| イベント |オンライン|||
| イベント |オフライン|||
・・・その他候補・・・
| その他 ||||
* このホームページにはどのようなコンバージョンレートが設定されているか推定してください。JSONの"goalOfPage"に記入してください。
* 推定したコンバージョンレートの種別を以下から選択してJSONの"CVR"に記入してください。優先度が高い順に並んでいます。
- 予約
・・・その他候補・・・
- その他
* 推定した理由を"reason"に入力してください。
</抽出項目>
<html>
{}
</html>
<ホームページの情報>
{}
</ホームページの情報>
<output>
<example>
{{
"goalOfPage": "イベントへの参加登録",
"CVR": "登録",
"usecase": "イベント・オフライン",
"reason: "推定理由",
}}
</example>
・・・その他候補・・・
<example>
{{
"CVR": "その他",
"usecase": "その他",
"reason": "推定理由",
}}
</example>
</output>
take a deep breath.プロンプトの解説
上記のようにして最初に Web ページのユースケースを判定させて個別の情報を抽出・要約しつつ、ユースケースに関わらず共通で取得可能な情報、例えば、ページの制作者情報や Web ページの画面キャプチャから判定されるデザインや配色に関する情報の抽出・要約作業を並列で個別のプロンプトにより実行しています。
なお、権利を持っていないページの URL を指定することはお断りしております。
STEP 2 : 抽出した情報を元にしたページの自動生成
後処理では、前処理から渡された情報を元にして主に下記の処理を行っています。
- デザインテンプレートの選択
- デザインテンプレート内の文言の生成・置き換え
- デザインテンプレート内の画像の置き換え
- 配色などの決定
STEP 2 の部分は既存システムとのつなぎ込み等も考慮し、元々弊社内で運用していた、文言生成などの処理をまとめた API サーバー上に構築しています。
後処理においても、基本的には前処理と同様に最終的なアウトプットである Web ページの生成プロセスを細かく分解してそれぞれプロンプトを作成しています。
なお、基盤モデルとしてはマルチモーダルモデルの Claude 3 Sonnet を利用していますが、後処理については文章生成や文字の置き換えなどが中心のため、コストや生成速度などを鑑みて、今後 Claude 3 Haiku などへの置き換えも検討しています。
開発体制と実装プロセス
開発は著者 (PdM)、フロントエンドエンジニア 1 名、バックエンドエンジニア 1 名、デザイナー 1 名の計 4 名という少人数体制で進めてきました。プロセス自体はユースケース検討・確定⇒要件定義⇒設計・開発⇒評価というプロセスとなり一般的なプロダクト開発と大きな違いはありませんが、私を含めて AI のプロダクト開発が初めてのメンバーが大半であったため、「そもそもユースケースの確定が難しい」や「Amazon Bedrock を利用したベストプラクティスが分からない」といった課題感がありました。
この点については、 AWS 様主催の生成 AI 活用のためのユースケース確定ワークショップに参加させていただいたり、プロトタイピング支援をいただいたりしました。
ワークショップでは、LLM を利用したアプリケーションのユースケースについてご紹介いただき、自社の課題を解決するための適切なアプローチについて多くのアドバイスをいただくことができました。また、その後にご提案いただいたプロトタイピング支援では、主に STEP 1 の「URL からの Web ページの情報の抽出・説明・要約」を行うプロセスにおいて、AWS の各種サービスを用いたアーキテクチャや実装の提案をいただきました。たとえば、シンプルな LLM の処理 (タスク) を組み合わせて精度を高めるアプローチに、 Step Functions と Lambda を活用するなど、弊社内には元々なかった知見を得ることができ、プロトタイピング開発を前進させることができました。この場を借りて、改めて感謝申し上げます。
また、今回の実装においては「ページを作成するときにデザイナーがどのような思考プロセスで情報を抽出し、ページに埋め込み直しているのか」という WEB デザイナーや WEB ディレクターといった職種の方々が実施している一部ケースの AI への置き換えのため、AI の実装そのものよりも、プロセスの整理や既存のデザインモジュールの整理といった要件定義・設計部分でのディスカッションが実装プロセスにおいては大半を占めました。
まとめ
筆者プロフィール
藤代 康太
株式会社ペライチ カスタマーリレーション部 PdM
フロントエンドエンジニアとして入社し、WEBページの編集エディタの機能開発などを担当。その後、スクラムマスターとエンジニアリングマネジャーを経て現在は新機能開発のPdMを担当。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages