Amazon Kendra と大規模言語モデル (LLM) を使って生成 AI コンシェルジュを作ってみた !
Author : 鈴木 大樹 (監修 : 関谷 侑希)
こんにちは ! ソリューションアーキテクトの鈴木です。
最近は大規模言語モデル (LLM : Large Language Model) が話題に上がることが増えてきましたが、みなさんはお使いでしょうか ? 私自身もインターネットで検索するのと同時に LLM に聞くことが多くなりました。真面目な内容に限らず、どんな内容でも返答してくれるので使っていて楽しいですよね !
でも、LLM に問いを投げた時におかしな回答をされたことはないでしょうか ? これは LLM が言葉のつながりを学習したものであり、あるトークンに続くトークンはどれであるかを確率として算出し、その可能性が高い「つながりそうな」トークンを続けるために起こります。この仕組みでは個々のトークンが持つ意味などは考慮されません。
この問題に対処するために、検索拡張生成 (RAG : Retrieval Augmented Generation) と呼ばれる技術を用いることで、正確な情報が書かれたドキュメントをもとに回答を生成することができるようになります。RAG は、ドキュメントを保存するデータベースと検索結果から自然な文章で回答を生成するための LLM で構成されます。
今回は LLM と、データベースとして Amazon Kendra を組み合わせて RAG ソリューションを作成し、正確な情報が書かれたドキュメントをもとに回答を生成する、生成 AI を活用したコンシェルジュ (QA サイト) を作る方法をご紹介します !
目次
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
このクラウドレシピ (ハンズオン記事) を無料でお試しいただけます »
毎月提供されるクラウドレシピのアップデート情報とともに、クレジットコードを受け取ることができます。
1. 検索拡張生成 (RAG : Retrieval Augmented Generation) とは
RAG とは、生成 AI の言語 AI モデルに外部メモリをつけるというコンセプトを指します。これまで大規模な事前トレーニング済み言語モデル (LLM) は、事前学習済みのデータを元に確からしい情報を生成できることが分かっています。ただし、知識を問うようなタスクの場合、事実でない事柄を出力するリスクを伴います。
一方で、LLM が学習していないことに対して正確な回答を出力することが難しいことが分かっています。 そこで、テキスト生成モデルで文章を生成する前に、関連する外部データを取得 (retrieve) し、それを元に文章生成を行うアプローチが考案され、検索拡張生成 (RAG : Retrieval Augmented Generation) と名付けられました。
本ソリューションに沿って、RAG の流れをご紹介します。
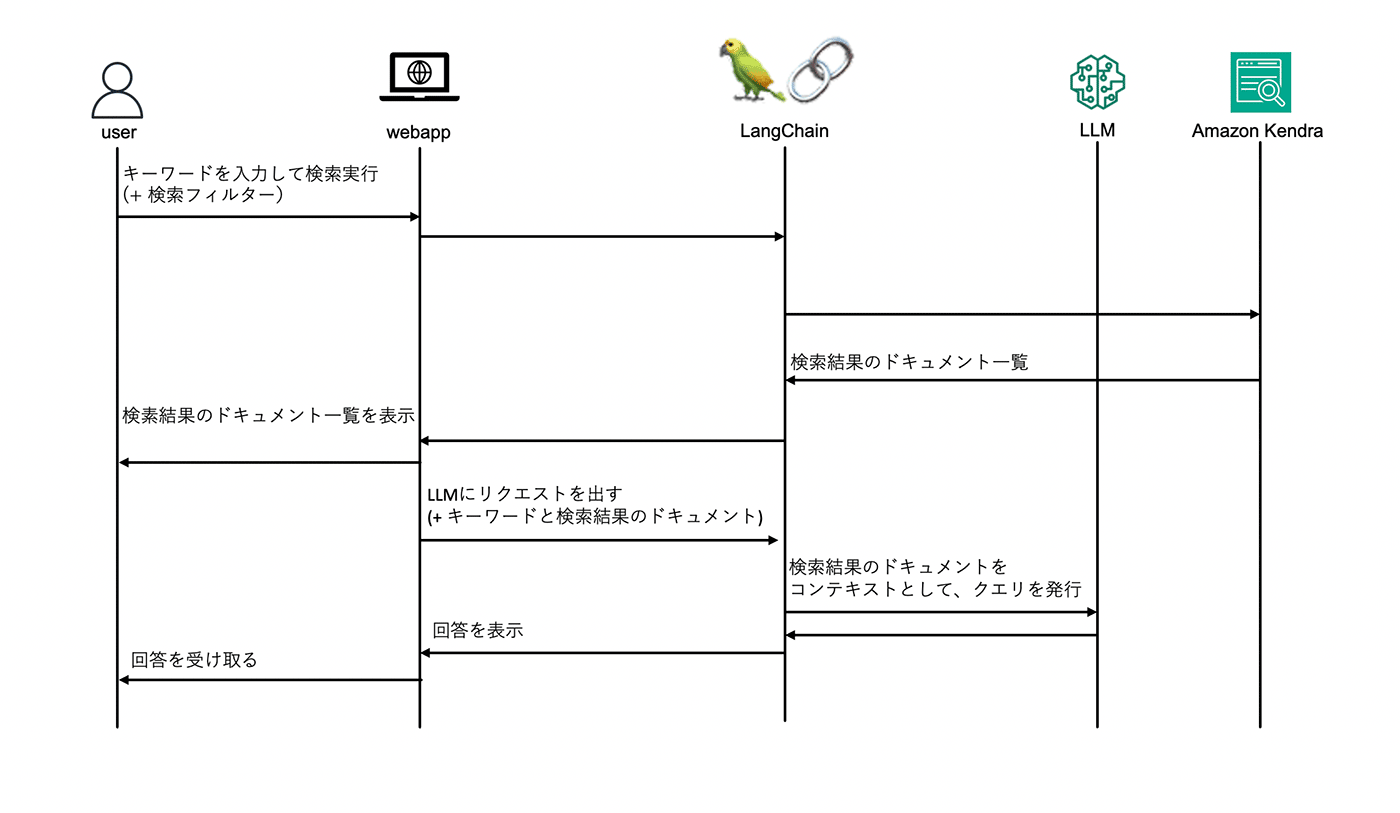
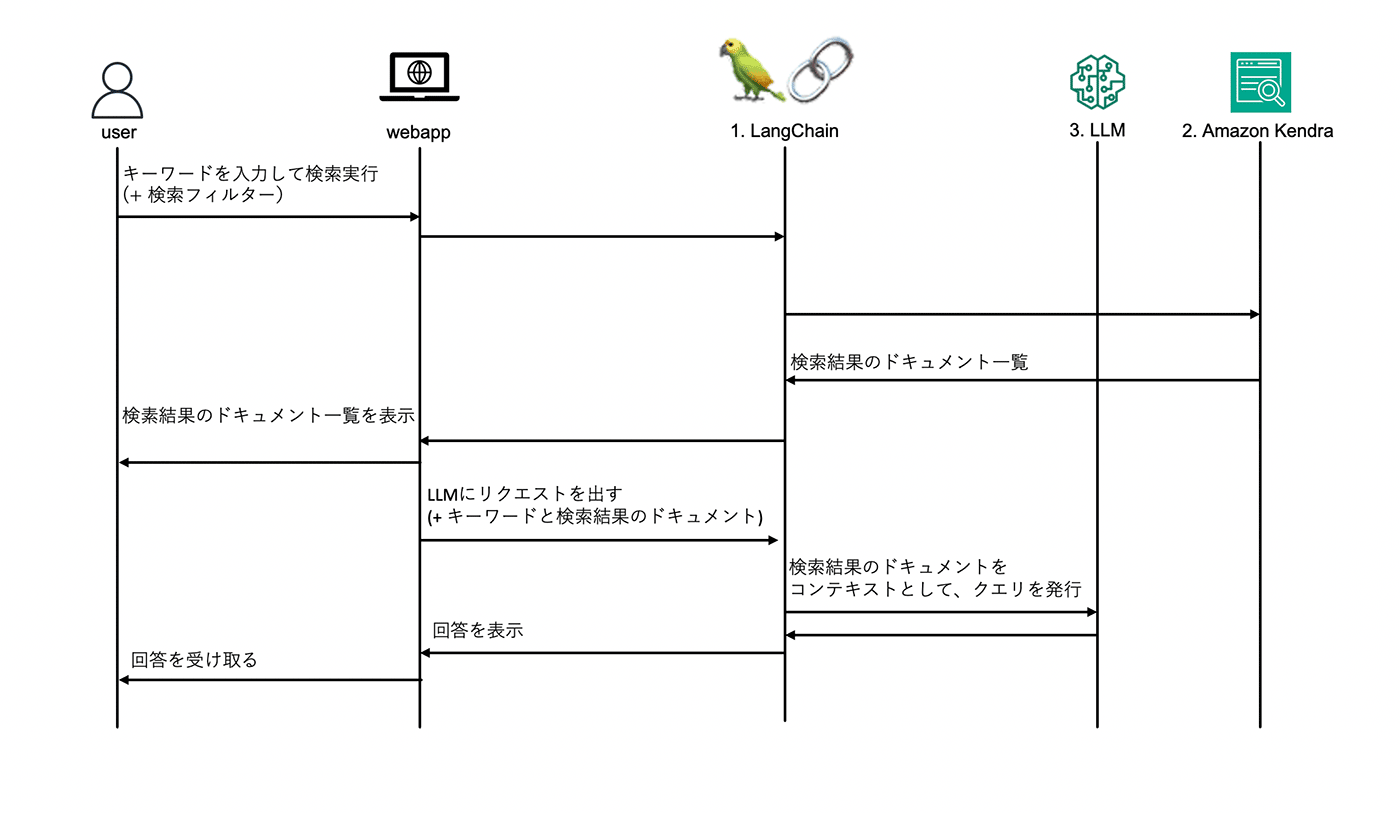
ユーザーからの入力を受けて、LangChain (言語系モデルの機能拡張を効率的に実装するためのライブラリ) が Amazon Kendra にキーワードを入力し検索を実行します。検索結果のドキュメントをコンテキストとして、キーワードとともに LLM にクエリを発行し、回答を得ます。
ユーザーが入力したクエリと 検索結果のドキュメントを一つのクエリとして LLM に入力することで、誤った回答を減らすことができます。
2. ソリューションの特徴
Amazon Kendra の採用
本ソリューションの一つ目の特徴としては、関連ドキュメントを抜き出す部分に Amazon Kendra を利用している点が挙げられます。Amazon Kendra はフルマネージド型の AI サービスです。事前学習済みの AI モデルが組み込まれているので、関連度の高いドキュメントを取り出せます。
これまでは検索したい情報があった場合、インターネット上にある情報を検索していました。一方で、インターネット上には社内の情報がありません。その課題を解決するための社内の情報を検索するためのシステム構築やアクセス権限、セキュリティも考慮すると簡単なものではありません。また、検索システムの導入を決定し、検索アプリケーションを構築・運用する段階でも、データを取り込むコネクタの開発、全文データベースの運用、ベクトル生成用のアルゴリズム開発などが必要でした。
一方 Amazon Kendra はフルマネージドサービスであるため、それらの開発は不要です。Amazon Kendra には、Amazon Simple Storage Service (Amazon S3)、Slack、Atlassian Confluence、ウェブサイトなどの一般的なデータソースへのコネクタがあらかじめ組み込まれており、HTML、Microsoft Word、PowerPoint、Excel、PDF、テキストファイルなどの一般的なドキュメント形式もサポートしています。エンドユーザーの権限で許可されているドキュメントのみに基づいて応答をフィルタリングするために、アクセス制御リスト (ACL) にも対応しており、エンタープライズ企業での導入実績 (例 : SBI 生命様の事例、BrainPad 様の事例) もあります。
本ソリューション 2 つ目の特徴として、 RAG を提供するのは勿論ですが、 Kendra 単体での検索や、 LLM 単体での Q&A 用途でもご利用いただけるように工夫をしています。
各モードを紹介します。クエリとして、「Amazon Kendraとは何ですか ?」を入力した際の結果もイメージとして共有します。
3 つのモードの切り替え
本ソリューション 2 つ目の特徴として、 RAG を提供するのは勿論ですが、 Kendra 単体での検索や、 LLM 単体での Q&A 用途でもご利用いただけるように工夫をしています。
各モードを紹介します。クエリとして、「Amazon Kendraとは何ですか ?」を入力した際の結果もイメージとして共有します。
RAG モード (#rag)
キーワードをもとに、Amazon Kendra でドキュメントの検索を行い、その検索結果のドキュメントをコンテキストとした上で、LLM にクエリを入力してレスポンスを表示するモードです。 こちらでは、結果として「LLM の回答」「Amazon Kendra の検索結果」の 2 つが出力されます。
なお、検索実行から終了までの体感速度を上げる工夫として、Amazon Kendra の検索結果をそのまま LLM に入力するのではなく、検索結果を画面に一度表示をしてから、LLM に入力するという二段構えを採用しています。 RAG モードでは、AI の回答と、Amazon Kendra による関連する文章を表示しています。

クリックすると拡大します
AI モード (#ai)
キーワードをもとに LLM に対してクエリを入力し、そのレスポンスを表示するモードです。
なお、本 RAG ソリューションでは、過去の検索結果を「ピン止めして記録しておく」機能があるのですが、AI モードで検索を行う際には、「ピン留め」したテキストを、クエリのコンテキストに含めて検索することが可能となります。

クリックすると拡大します
Amazon Kendra モード (#kendra)
キーワードをもとに、Amazon Kendra でドキュメントの検索を行い、その検索結果のドキュメントを一覧で表示するモードです。 こちらでは、結果として「Amazon Kendra の検索結果」が出力されます。

クリックすると拡大します
3. アーキテクチャ
今回ご紹介するシステムのアーキテクチャです。システムの概要を説明します。
AWS Amplify を用いてフロントエンド・バックエンドのデプロイをします。AWS Amplify とは、AWS でフルスタックアプリケーションを簡単に構築やホストできるようにする AWS サービスです。本ソリューションの AWS Amplify で、Amazon API Gateway、AWS Fargate、Amazon Cognito をデプロイできます。
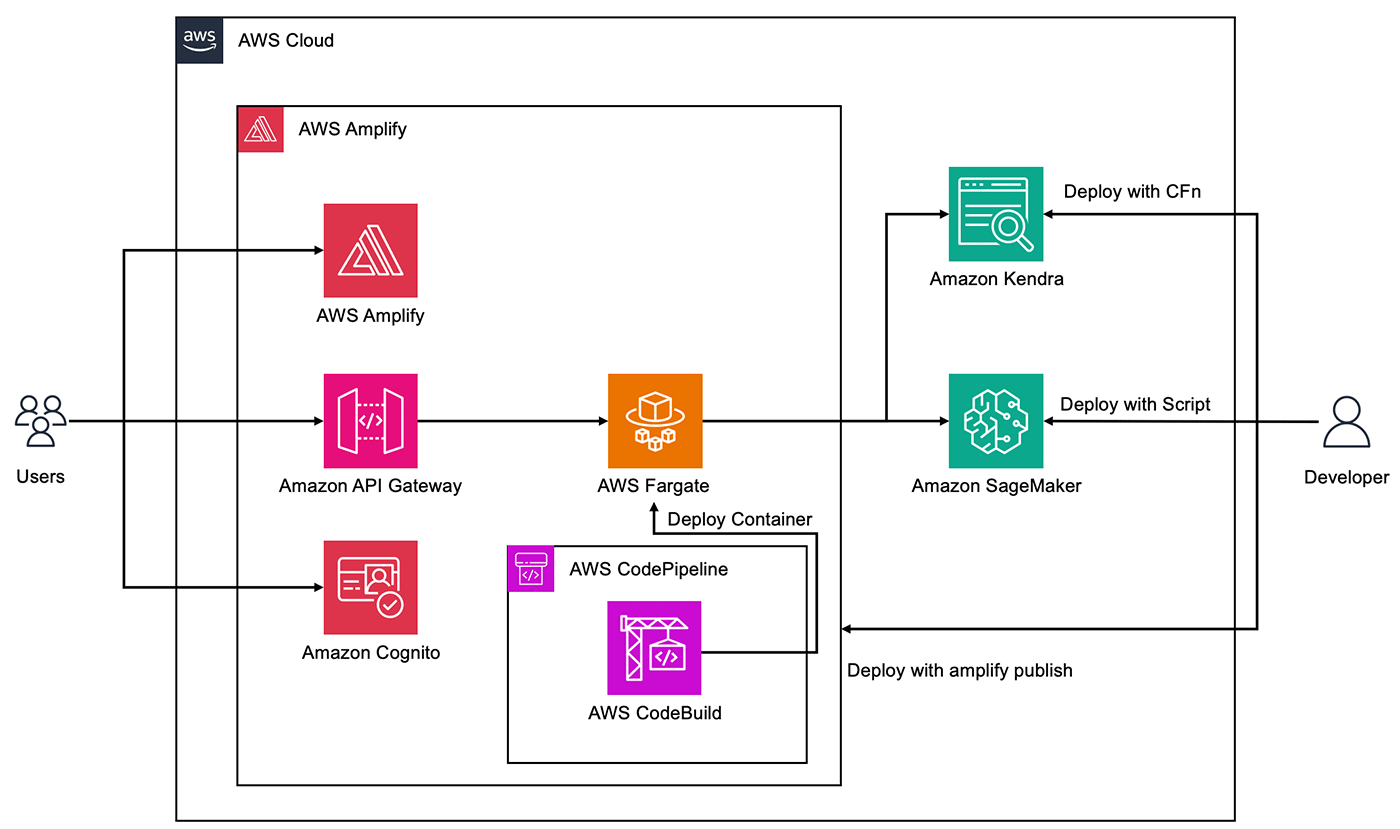
まず、フロントエンドについて説明します。Amplify Hosting でフロントエンドをデプロイし、アクセス可能な Web サイトの URL が発行されます。ユーザーは、アクセス管理など、セキュリティ機能を提供する Amazon Cognito のユーザー認証を用いて Web サイトにログインします。以下のシーケンス図で言うところの「User」 にあたります。
続いて、バックエンドについて説明します。コンテナ向けのサーバレスコンピューティングリソースを提供する AWS Fargate で Amazon Kendra でドキュメントを検索する HTTP API や、Amazon SageMaker 上にデプロイされた LLM にクエリを入力する HTTP API を作成します。それらの API を、API の作成やモニタリングを行える Amazon API Gateway で管理して利用します。
AWS Fargate の API は、AWS CodeBuild を用いてビルドします。AWS CodeBuild は、ビルドサーバーのプロビジョニングやスケーリングが不要になるサービスです。また、API を構築する AWS サービスとして、サーバレスでイベント駆動型の AWS Lambda ではなく、AWS Fargate を選択した理由は、初回ロード時の LLM からの回答の返答が遅い場合にタイムアウトになる可能性があり、それを避けるために AWS Fargate を採用しています。以下のシーケンス図では「1. LangChain」にあたります。
三つ目に、関連ドキュメントを取得する部分について説明します。
本ソリューションでデータベースとして用いる Amazon Kendra は、さまざまなコンテンツリポジトリを検索できるようにするサービスです。今回は、https://docs.thinkwithwp.com/ja_jp/kendra/.* などの URL からAmazon Kendra のコネクタを利用してデータを収集します。以下のシーケンス図では「2. Amazon Kendra」にあたります。
最後に、 LLM について説明します。
機械学習モデルの構築やデプロイを行える Amazon SageMaker に LLM をデプロイします。その LLM に対して#rag モードではユーザーのクエリと Amazon Kendra によって取得した関連ドキュメントを入力して回答を行ないます。また、#ai モードでは ユーザーからのクエリを入力として回答を行ないます。以下のシーケンス図では「3. LLM」にあたります。
4. Amazon Kendra の設定
まず、本ソリューションの構築にはAWS サービスの有効なアカウントが必要となります。
今回のサンプルでは Amazon Kendra を利用して、 AWS のドキュメントをクローリングします。今回はあらかじめリソースをプロビジョニングできる AWS CloudFormation で使える yml ファイルを作成しているため、これを用いて Amazon Kendra を構築します。
まず、 GitHub から、 kendra-docs-index.yml をダウンロードしておきます。

クリックすると拡大します
今回の AWS サービスのリソースはオレゴンリージョン (us-west-2) に配置します。
オレゴンリージョンとした理由として、一つはコスト面があります。もう一つは、今回利用する LLM である rinna/japanese-gpt-neox-3.6b-instruction-ppo はインスタンスサイズが g4dn.xlarge ですが、より大きいモデルを動かす際、g5.2xlarge が必要になり、その際に切り替えが対応しているリージョンであれば他の大きなモデルに切り替えが容易であるためです。
本アプリケーションは東京リージョン (ap-northeast-1) でも設定箇所を変更すれば動作いたします。東京リージョンで使用する際は、リージョンを設定する箇所でその都度案内します。
AWS マネジメントコンソールから、オレゴンリージョンを選択します。東京リージョンで作成する場合は、東京リージョンを選択してください。

クリックすると拡大します
AWS CloudFormation を利用して Amazon Kendra のクローラーとインデックスを作成します。
このリンク をクリックして AWS CloudFormation のスタックを作成します。
テンプレートでの指定では、「テンプレートファイルのアップロード」を選択し、先ほどダウンロードした kendra-docs-index.yml をアップロードします。
アップロードが完了したら「次へ」をクリックします。

クリックすると拡大します
スタック名を jp-rag-sample-kendra とし、「次へ」をクリックします。

クリックすると拡大します
スタックオプションの設定や詳細オプションの設定はデフォルトのままで構いません。「次へ」をクリックして次のページに行きます。

クリックすると拡大します
「レビュー jp-rag-sample-kendra」のページ下部に移動し、「AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。」にチェックマークをつけて「送信」をクリックします。
これで AWS CloudFormation によって、 kendra-docs-index.yml の内容のリソースが作成されます。作成には 10 分から 30 分程度かかります。

クリックすると拡大します
AWS CloudFormation のスタック画面でスタックの作成が完了したことを確認し、AWS マネジメントコンソールで「Amazon Kendra」を検索します。
jp-rag-sample-kendra-Index が作成されていれば、Amazon Kendra の設定は完了です。

クリックすると拡大します
5. 環境構築
本アプリケーションの構築には、AWS Cloud9 を使用します。AWS Cloud9 は、ブラウザのみでコードを記述、実行、デバッグできるクラウドベースの統合開発環境 (IDE) です。
また、今回のアプリケーション構築にあたって、AWS サービスのリソースは 「4. Amazon Kendra の設定」 と同様に、オレゴンリージョン (us-west-2) に配置します。
リージョンが 「4. Amazon Kendra の設定」 と同様にオレゴンリージョン (us-west-2) を選択しているか確認し、開発環境を作成していきます。
このリンク をクリックして、AWS Cloud9 の環境を作成します。
AWS Cloud9 が利用できない場合、こちらのブログ をご参考に AWS IDE Toolkits または AWS CloudShell をご利用ください。
「環境を作成」のページで、名前を「jp-rag-sample-cloud9」 、説明を「jp-rag-sample の開発環境] とします。

クリックすると拡大します
Amazon EC2 インスタンスのインスタンスタイプは「t3.small」とします。

クリックすると拡大します
ネットワーク設定はデフォルトのままで構いません。
設定後、ページ下部の「作成」ボタンをクリックすると Cloud9 IDE の環境が作成されます。

クリックすると拡大します
続いて、GitHub の開発者ガイド に沿ってコマンドを実行していきます。
今回は、本記事を参照することで本ソリューションのデプロイを行うことができます。
作成した環境「jp-rag-sample-cloud9」の「開く」をクリックします。

クリックすると拡大します
Cloud9 IDE が開いたら、「Window」をクリックして、「New Terminal」を選択し、ターミナルを開きます。

クリックすると拡大します
Cloud9 IDE のターミナルで以下のコマンドを実行して、リポジトリをクローンします。
git clone https://github.com/aws-samples/jp-rag-sample.gitその後、クローンしたリポジトリのルートに移動します。
cd jp-rag-sample
クリックすると拡大します
以降の手順は、jp-rag-sample ディレクトリで作業していきます。Cloud9 IDE を以降も使って本ソリューションを構築するので、別のタブで開いておいてください。
6. LLM のデプロイの手順
Amazon SageMaker 上に、 Rinna 社が開発したモデル rinna/japanese-gpt-neox-3.6b-instruction-ppo をデプロイします。
デプロイするためにまず、AWS Cloud9 に AWS IAM で assumeRole を設定します。本項以降で利用する「許可ポリシー」や、「信頼されたエンティティ」の設定もこのタイミングで行います。
このリンク をクリックして、IAM ロールを作成します。
信頼されたエンティティタイプに、「AWS のサービス」と、「一般的なユースケース」の「EC2」にチェックを入れ、「次へ」をクリックします。

クリックすると拡大します
「次へ」をクリックします。「許可を追加」の画面で、「AdministratorAccess」を追加します。

クリックすると拡大します
AdministratorAccess を選択した後、ページ下部の「次へ」をクリックします。

クリックすると拡大します
ロール名を「jp-rag-sample-assume-role」として、ページ下部の「ロールを作成」をクリックします。

クリックすると拡大します
IAM のリソースのページに切り替わるので、そのページで先ほど作成した「jp-rag-sample-assume-role」をクリックします。

クリックすると拡大します
「信頼関係」をクリックして、「信頼ポリシーを編集」をクリックします。

クリックすると拡大します
“Principal” を次のように変更し、「ポリシーを更新」をクリックします。
"Principal": {
"Service": [
"ec2.amazonaws.com",
"cloud9.amazonaws.com",
"sagemaker.amazonaws.com"
]
},
クリックすると拡大します
次に このリンク をクリックして、実行中のインスタンスを表示します。
「[aws-cloud9-jp-rag-sample-...」のインスタンスにチェックを入れ、「アクション」の「セキュリティ」から「IAM ロールを変更」をクリックします。

クリックすると拡大します
「jp-rag-sample-assume-role」を選択し、「IAM ロールの更新」をクリックします。

クリックすると拡大します
次に、Amazon SageMaker 上に LLM をデプロイします。あらかじめ作成しておいたデプロイするためのシェルスクリプトを使用します。
Cloud9 IDE を開き、右上の歯車マークから設定を開きます。

クリックすると拡大します
右のサイドバーを下にスクロールし、「AWS Settings」をクリックします。

クリックすると拡大します
「Credentials」の「AWS managed temporary credentials」のチェックを外します。

クリックすると拡大します
続いて、Cloud9 IDE のターミナルから、以下のコマンドを実行します。
東京リージョンで作成する場合は、以下のコマンドの「us-west-2」の箇所を「ap-northeast-1」に変更して下さい。デプロイには 10 分から 30 分程度かかります。
export AWS_DEFAULT_REGION=us-west-2
cat << EOF > ~/.aws/config
[default]
region = us-west-2
EOF
bash llm/deploy_llm.sh実行後、このリンク をクリックして、Amazon SageMaker のダッシュボードを開きます。
SageMaker ダッシュボード画面の、左側のナビゲーションパネルの「SageMaker ダッシュボード」をクリックします。

クリックすると拡大します
「エンドポイント」の「使用中」をクリックします。

クリックすると拡大します
エンドポイントに「Rinna-Interface」があればデプロイ完了です。

クリックすると拡大します
7. フロントエンドおよびバックエンドの設定
Amazon Amplify を用いてフロントエンド・バックエンドをデプロイするための手順を説明します。まずはデプロイするための環境を作ります。
以下のコマンドで Amplify CLI のインストールをします。
npm install -g @aws-amplify/cli@12.1.1xdg-utils, jq をインストールします。
sudo yum install -y xdg-utils jq「jp-rag-sample」直下に「get-credential.sh」を作成し、 AWS Amplify で利用する IAM ロールの情報を取得します。

クリックすると拡大します
get-credential.sh のコードは次のとおりです。
#!/bin/bash
#アタッチされている IAM role 名を変数に保存
role_name=$(curl -s "http://169.254.169.254/latest/meta-data/iam/security-credentials/")
#assume role して aws cli の credential_process に適合するよう整形
curl -s "http://169.254.169.254/latest/meta-data/iam/security-credentials/$role_name" | jq ". + {Version: 1}" | sed 's/Token/SessionToken/'
クリックすると拡大します
以下のコマンドで実行権限を与えます。
chmod +x /home/ec2-user/environment/jp-rag-sample/get-credential.sh以下のコマンドで AWS Amplify で用いるリージョンや credential の情報を設定します。東京リージョンで作成する場合は、以下のコマンドの「us-west-2」の箇所を「ap-northeast-1」に変更して下さい。
cat << EOF >> ~/.aws/config
[profile amplify-user]
output=json
region=us-west-2
credential_process=/home/ec2-user/environment/jp-rag-sample/get-credential.sh
EOFライブラリをインストールします。
npm iAmplify プロジェクトを初期化します。
amplify init「? Do you want to use an existing environment?:」では、「n」を入力します。
「? Enter a name for the environment:」が表示されましたら、「dev」を入力します。
「? Choose your default editor:」では、「None」を入力します。
「? Select the authentication method you want to use:」では、「AWS profile」を入力します。
「? Please choose the profile you want to use:」では、「amplify-user」を入力します。
続いて、フロントエンドおよびバックエンドの環境変数を設定します。
以下のコマンドを実行して、docker-compose.yml ファイルの作成や、Amazon Kendra のインデックス ID を各種ファイルに設定します。
bash setenv.sh jp-rag-sample-kendra-Index最後に、フロントエンドおよびバックエンドをデプロイします。
「amplify publish」でデプロイします。デプロイには 10 分から30 分程度かかります。
「? Are you sure you want to continue? (Y/n)」は「Y」と入力します。(* Secure Token Timed out というエラーが表示された場合、amplify publish の再実行をお願いします。)
「? Secret configuration detected. Do you wish to store new values in the cloud?」では、「y」と入力します。この設定で、AWS Secret Manager にシークレット情報を保存します。
作成完了後、コンソール画面に、~~~.amplifyapp.com/ の URL が発行されます。URL が発行されない場合、「amplify publish -y」を実行します。
発行された URL にアクセスすると、アカウント作成画面が表示されます。
デプロイ作業お疲れ様です!
ここからは RAG ソリューションで作成した QA サイトを実際に触ってみましょう。まずはアカウントを作成します。
「Create Account」をクリックして、Username、Password、Email を入力し、ページ下部の「Create Account」をクリックします。

クリックすると拡大します
数分後に 6 桁のコードが届くので、コードを入力して「Confirm」をクリックしてください。

クリックすると拡大します
言語設定が「Japanese」になっている場合は、「English」に変更してください。
この言語設定では、Amazon Kendra のデータソースの言語を指定しています。本ソリューションの対象ドキュメントは日本語ですが、AWS CloudFormation でデプロイできる Amazon Kendra のデータソースが現状では英語しか指定できないため、「English」に指定することとなります。

クリックすると拡大します
試しに「Amazon Kendraとはなんですか ?」と入力してみます。それぞれのモードでの回答例を見てみます。
まずは AI モード (#ai) を見てみます。以下の回答が返ってきました。
「Amazon Kendraとは、Amazonの注文を処理するコンピュータプログラムです。Amazonは、さまざまな商品を注文し、注文を処理し、注文を処理するためにAmazon Kendraを使用します。Amazon Kendraは、Amazonの注文処理の中心的な役割を果たしています。」
rinna/japanese-gpt-neox-3.6b-instruction-ppo モデルは Amazon Kendra に関する情報を持たないため、おかしな回答をしてしまいます。

クリックすると拡大します
続いて Amazon Kendra モード (#kendra) を見てみます。Amazon Kendra から関連するドキュメントを 10 個取得することができました。

クリックすると拡大します
最後に、RAG モード(#rag) を見てみます。
同じ LLM を使っていますが、今回は正しい回答が返ってきました !
Amazon Kendra から取得した関連ドキュメントも表示されています。

クリックすると拡大します
8. リソースの削除
使ったリソースをそのままにしておくと、利用していなくとも S3 バケットなど、コストが継続的に掛かるサービスもあるため、不要になった場合は削除してください。
作成した AWS CloudFormation の 「amplify-jpragsampleamplify-」から始まるスタックを削除することで、フロントエンド・バックエンド環境を削除できます。
Amazon Kendra は「jp-rag-sample-kendra」を削除することで Amazon Kendra のリソースを削除することができます。
「jp-rag-sample-kendra」を選択し、ページ上部の「削除」をクリックします。

クリックすると拡大します
「削除」をクリックすることで削除できます。

クリックすると拡大します
Amazon SageMaker は、LLM を Amazon SageMaker 上にデプロイした時と同じように、AWS Cloud9 のターミナルから以下のコマンドを実行することで削除できます。
sh llm/delete_llm.shその他 AWS Cloud9 の環境、S3 バケットの削除も忘れず行いましょう。
9. まとめ
本記事では LLM と Amazon Kendra を組み合わせて RAG ソリューションを作成し、正確な情報が書かれたドキュメントをもとに回答を生成する、生成 AI を活用した QA サイトを作る方法を紹介しました。
ユーザーの入力となるクエリから、自然な文章を作成できる LLM の強みを活かしつつ、LLM の誤った回答を生成する可能性を減らすことができる RAG ソリューションと組み合わせることで、ドキュメントをもとに回答を生成させることができるようになりました。
今回は AWS サービスのドキュメントを回答に用いるドキュメントとしましたが、社内ドキュメントを Amazon Kendra に入れ込むことで社内専用の RAG サービスを構築することができます。
builders.flash をご覧の皆様も、生成 AI を活用した社内コンシェルジュの作成にぜひチャレンジしてみてください !
筆者プロフィール

鈴木 大樹
アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト
2023 年 4 月に AWS Japan に入社したソリューションアーキテクト。趣味はフットサルで、猫が好きです。
監修者プロフィール

関谷 侑希 (せきや ゆうき)
アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト
交通・建設などの業界のソリューションアーキテクトです。個社向けの技術支援をする傍ら、Amazon Kendra を日本で普及させる活動も行っています。
趣味はバドミントンで YouTube や Netflix も時間があればよく見ています。
AWS を無料でお試しいただけます