Amazon Web Services ブログ
MySQL との互換性を持つ Amazon Aurora での MariaDB JDBC ドライバーの使用
このブログ記事は、Amazon Aurora クラスターへの接続に MariaDB Connector/J として知られる MariaDB JDBC ドライバーを使用する方法について説明するものです。この記事では、フェイルオーバーの状況下でマスターとレプリカを迅速かつシームレスに切り替えるために、このコネクターの自動フェイルオーバー機能を使用します。MariaDB Connector/J は MariaDB サイトからダウンロードできます。
MariaDB Connector/J を使用した Aurora MySQL への接続
この記事を書いている時点でのコネクターの最新バージョンは MariaDB Connector/J 2.3.0 です。コネクターは 2 つの方法でインストールできます。
- Maven または Gradle などのパッケージマネージャーを利用する
- .jar ファイルを直接使用する
この記事では、.jar ファイルを使用します。完全なインストールガイドは、MariaDB サイトでご覧いただけます。
コネクターをインストールしたら、次のステップは Aurora MySQL クラスターの作成です。まず、AWS マネジメントコンソールにサインインします。RDS を選択してから [データベース] を選択し、次に [データベースの作成] を選択します。次のページで、エンジンのオプションをデフォルトの [Amazon Aurora] のままにしておき、エディションに [MySQL 5.6 との互換性] または [MySQL 5.7 との互換性] を選択します。[データベースの作成] を選択する準備が整うまで、すべての必須情報を入力します。
ルートレベルに Aurora クラスターがあり、その下にマスターエンドポイントとレプリカエンドポイントがあるのが分かるはずです。これらは、以下のスクリーンショットのように表示されます。

接続のテストについては、2 つの方法を実行します。
- オープンソース DB 管理ツールを使用して Aurora MySQL に接続する
- Java プログラムから Aurora MySQL に接続する
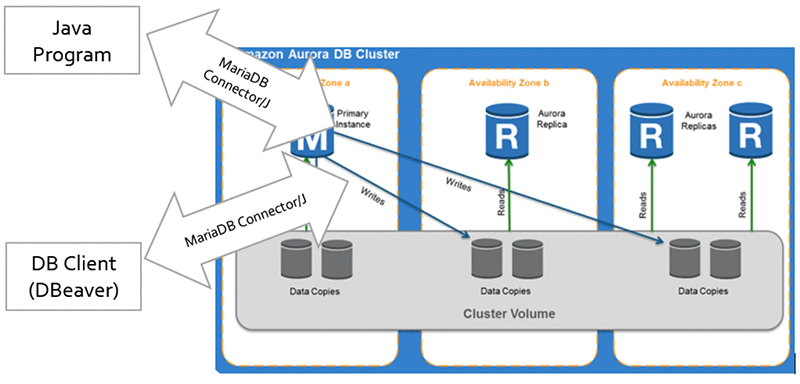
DBeaver などのオープンソース DB 管理ツールの使用
接続には、DBeaver などのオープンソースデータベース管理ツールを使用できます。DBeaver へのアクセスについては、この GitHub リポジトリを参照してください。
DBeaver を使用するには、ツールを開いて新しい接続を作成します。接続タイプには [AWS] で [MariaDB] を選択して、要求される情報を入力します。ガイドラインとして、以下のスクリーンショットを参照してください。
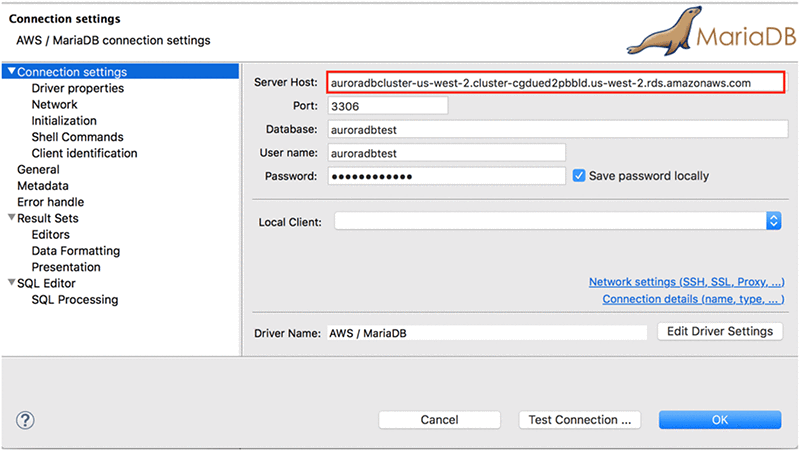
[Server Host] で、バージョン 1.5.1 以降については、次の例のようにクラスターエンドポイントを指定します。
auroradbcluster-us-west-2.cluster-cgdued2pbbld.us-west-2.rds.amazonaws.com
MariaDB Connector/J を使ったフェイルオーバーと高可用性のガイドに記載されているように、クラスターエンドポイントを使用することによって、接続時にドライバーが現在のクラスターエンドポイントからこのクラスターのマスターとレプリカを自動的に検出できるようになります。こうすることによって、クラスターインスタンスに新しいレプリカを追加することが可能になり、これらのレプリカはドライバーの設定を変更することなく検出されます。
1.5.1 より前のバージョンでは、クラスターエンドポイントの使用は推奨されていませんでした。これらのバージョンでは、フェイルオーバーが発生すると、このクラスターエンドポイントが現行のマスターではなくなったホストに期間限定でポイントできます。特定のエンドポイントをすべてリストすることが以前の推奨でした。このタイプの URL 文字列は今も機能しますが、現在推奨されている URL 文字列は、クラスターエンドポイントを指定するものです。
ローカルコンピューターから、DBeaver ライブラリに.jar ファイル mariadb-java-client-2.3.0.jar を追加します。これは、Aurora MySQL への接続に必要です。
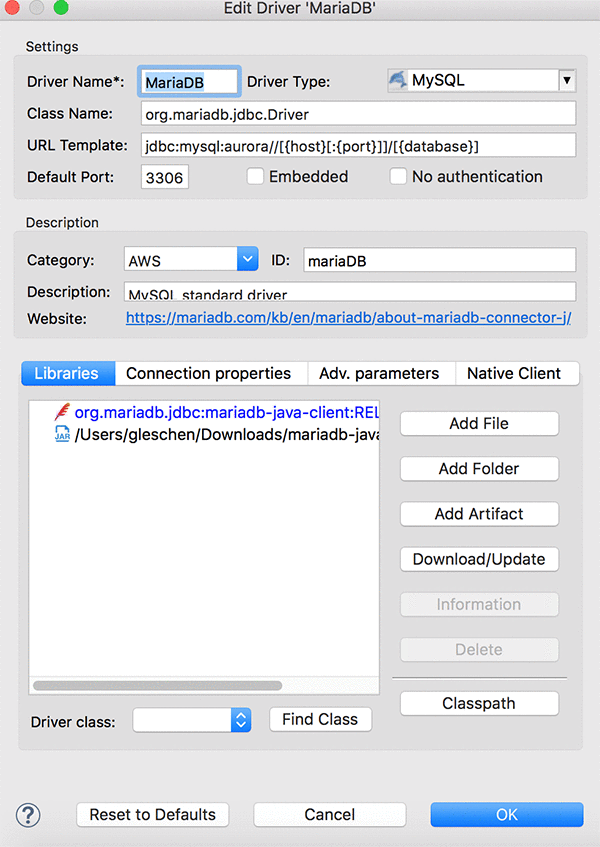
.jar ファイルをアップロードして必須フィールドに入力した後は、必ず接続をテストして、以下のスクリーンショットのような接続されているという確認を受け取ります。

接続後、[データベース] メニューを展開すると、テーブルがない状態の auroradbtest インスタンスが表示されます。

次のステップでは、データベースにテーブルを作成する Java プログラムを実行します。その後、DBeaver に戻ってテーブルが作成されていることを確認します。
Aurora MySQL インスタンスに接続するための Eclipse からの Java プログラムの使用
Eclipse から Java プログラムを使って接続するには、DB ツール (DBeaver) と同様に、まず MariaDB 用の JDBC ドライバをインストールする必要があります。インストールするには、以下のステップに従ってください。
- Eclipse でプロジェクト (auroradb) を右クリックし、[ビルド・パス]、[ビルド・パスの構成] と選択してプロジェクトのプロパティーウィンドウを開きます。
- [ライブラリ] を選択します。
- [外部 JAR の追加] を選択し、前のステップでローカルコンピューターにダウンロードして保存した MariaDB Connector/J (.jar ファイル) をアップロードします。


今回は、以下の Java コードを使用して Aurora MySQL に接続し、auroradbtest データベースに VENDORS テーブルを作成するクエリを実行します。
JDBC クラスが含まれるパッケージを含めるようにする必要があります。これは、 import java.sql.*; のコード行を使って実行します。
Eclipse でプログラムを実行して、コンソールで問題なく実行されることをチェックします。

次に、テーブルが作成されていることを確認するために、DBeaver ツールをチェックします。以下のスクリーンショットから、auroradbtest DB の下に 3 つの列 (name、CEO、および VAT_Number) がある新しいテーブル、VENDORS が表示されているのがわかります。

最初にオープンソースクライアント (DBeaver)、次に小さな Java プログラムを使用した 2 つの方法で、Aurora MySQL DB への接続に MariaDB Connector/J として知られる MariaDB JDBC ドライバーを使用する方法のデモは以上です。
フェイルオーバーでの作業
このブログ記事の後半では、MariaDB Connector/J のフェイルオーバー機能が Aurora の自動フェイルオーバーとどのように連動するのかをお見せします。
これを実行するには、まず クエリを実行できるように Java プログラムを変更します。このクエリは、現在の接続がポイントしているエンドポイント (マスターまたはレプリカ) の INFORMATION_SCHEMA テーブルから読み取りを行います。
各 Amazon Aurora DB クラスターは、ひとつのマスターインスタンスと最大 15 個のレプリカインスタンスで構成されるマスター/レプリカ DB クラスターです。Amazon Aurora には、マスターインスタンスに不具合が発生している場合におけるレプリカインスタンスの自動昇格機能があります。Aurora 用の MariaDB connector/J 実装は、この自動フェイルオーバーを処理するために特別に設計されています。
JDBC 接続文字列の形式は以下のとおりです。
jdbc:mariadb:aurora://[clusterInstanceEndPoint[:port]]/[database][?<key1>=<value1>[&<key2>=<value2>]…]
ここにある <hostDescription> は、ノード (コンマで区切られたマスターとスレーブ) の DNS を表します。
このプログラムでは、接続 URL に aurora というキーワードが使用されていることに注目してください。
これは、ドライバーに対して Aurora フェイルオーバーサポートを使用するように指示します。
前述した Java プログラム、および DBeaver から SELECT SERVER_ID, SESSION_ID FROM INFORMATION_SCHEMA.REPLICA_HOST_STATUS"; クエリを実行した後は、それぞれ Eclipse コンソールと DBeaver から以下の結果を受け取ります。

上記のスクリーンショットから、現行のセッションがマスターエンドポイントに接続されていることがわかります。
それでは、前のステップで作成した VENDORS テーブルにデータを挿入するためのクエリを実行してみましょう。フェイルオーバーシナリオを分かりやすくするため、それぞれのノードエンドポイントに個別に接続してクエリを実行し、VENDORS テーブルにデータを追加してみます。そうすることで、レプリカエンドポイントには読み取り専用許可があることから、レプリカエンドポイントに接続している間はデータベースにデータを挿入できないことを実証できます。
以下のスクリーンショットにあるように、マスターエンドポイントに接続しましょう。

次に、SELECT * FROM VENDORS; クエリを実行して、データを挿入する前にテーブルが空であることを確認します。

上記のスクリーンショットにあるように、VENDORS テーブルは空です。ここで、以下のクエリを実行してテーブルにデータを挿入します。









Eclipse からの Java プログラムの実行も、以下のスクリーンショットにあるものと同じ出力を提供します。Java プログラムの出力は、以前のスクリーンショットに表示されている DBeaver でのクエリの実行による出力に似ています。

上記のスクリーンショットから、クエリの結果が分かります。これらは、マスターエンドポイントへの接続を使用していたドライバーが、自動で接続をレプリカに切り替えたことを示しています。AWS コンソールでフェイルオーバーのシミュレーションを行った今、レプリカにはそのロールがライターに変更された MASTER_SESSION_ID があります。
それでは、マスターに昇格されたレプリカエンドポイントに接続されている間に、INSERT クエリに戻って VENDORS テーブルにデータを追加しましょう。

今回はクエリが正常に実行され、SELECT * FROM VENDORS; クエリから、以下のスクリーンショットにあるようにデータがテーブルに挿入されていることが分かります。

同様に、DBeaver で接続をマスターエンドポイントに切り替えて INSERT クエリを実行してみると、以下のスクリーンショットにあるエラーが表示されます。


今回、このブログ記事では、Aurora MySQL への接続に MariaDB JDBC ドライバーを使用する方法について説明しました。このデモでは、ドライバーを最大限に活用して、その迅速でシームレスなフェイルオーバー機能を活かす方法をご紹介しました。
 Georges Leschener は、アマゾン ウェブ サービス、グローバルシステムインテグレーター (GSI) チームのパートナーソリューションアーキテクトです。Georges は AWS の GSI パートナーと連携して、お客様のワークロードの AWS クラウドへの移行を助け、AWS のベストプラクティスを適用することによって AWS 上で革新的なソリューションをデザインし、設計しています。
Georges Leschener は、アマゾン ウェブ サービス、グローバルシステムインテグレーター (GSI) チームのパートナーソリューションアーキテクトです。Georges は AWS の GSI パートナーと連携して、お客様のワークロードの AWS クラウドへの移行を助け、AWS のベストプラクティスを適用することによって AWS 上で革新的なソリューションをデザインし、設計しています。