Amazon Web Services ブログ
Amazon SageMaker で TensorFlow を使用して ALBERT をトレーニングし、自然言語処理を行う
re:Invent 2019 で、AWS は、BERT (自然言語処理) および Mask-RCNN (オブジェクト検出) という 2 つの一般的な機械学習 (ML) モデルに対して、クラウドで最速のトレーニング時間を叩き出したところを披露しました。BERT を 1 時間でトレーニングするために、基盤となるインフラストラクチャ、ネットワーク、ML フレームワークを改善することにより、効率的に 2,048 の NVIDIA V100 GPU にスケールアウトしました。 今日、当社は最適化されたトレーニングコードを ALBERT (A Lite BERT) にオープンソーシングしています。ALBERT は、業界のベンチマークで最先端のパフォーマンスを実現しながら、1.7 倍の速さで安価なトレーニングを実現する強力な BERT ベースの言語モデルです。 この記事では、Amazon SageMaker で ALBERT という高速で小型の高品質モデルをトレーニングする方法を示します。ALBERT は、ML モデルの構築、トレーニング、調整、デプロイを容易にするフルマネージドサービスです。
これは新しいモデルではありませんが、TensorFlow 2 の最初の効率的な分散 GPU 実装です。AWS トレーニングスクリプトを使用して、単一ノードトレーニングと分散トレーニングの両方で、Amazon SageMaker の p3dn インスタンスと g4dn インスタンスで ALBERT をトレーニングできます。スクリプトは、混合精度トレーニングと加速線形代数を使用して、24 時間以内にトレーニングを完了します (このような最適化を使用しない場合の 5 倍の速さ)。これにより、データサイエンティストはより速く反復し、モデルをより早く本番環境に導入できます。スクリプトは、オープンソースの Hugging Face transformers ライブラリのモデルアーキテクチャを使用しています。詳細については、GitHub リポジトリをご覧ください。
自然言語処理 (NLP) モデルを使用して、検索結果の改善、関連アイテムの推奨、翻訳の改善などを行うことができます。多くのユースケースでは、フルマネージド NLP サービスである Amazon Comprehend を使用できます。サービスはテキストの言語を識別し、キーフレーズ、場所、人物、ブランド、イベントを抽出し、そしてテキストがどの程度ポジティブかネガティブかを理解します。さらにトークン化と品詞を使用してテキストを分析し、テキストファイルのコレクションをトピックごとに自動的に整理します。Amazon Comprehend の AutoML 機能を使用して、組織のニーズに合わせて独自に調整されたエンティティまたはテキスト分類モデルのカスタムセットを構築することもできます。
ただし、特定のドメインまたは言語によっては、最初から NLP モデルを事前トレーニングする必要がある場合があります 。大規模な言語モデルを事前トレーニングするには、多くの場合、10〜20 GB の未加工テキスト (英語版の Wikipedia のおおよそのサイズ) と数千の GPU 時間を用意する必要があります。アルゴリズムを正確かつ効率的にすることは難しく、モデルの品質を評価するまでのトレーニング時間が長いため、NLP の開発は困難な場合があります。次の図は、トレーニングインフラストラクチャの概要を示しています。
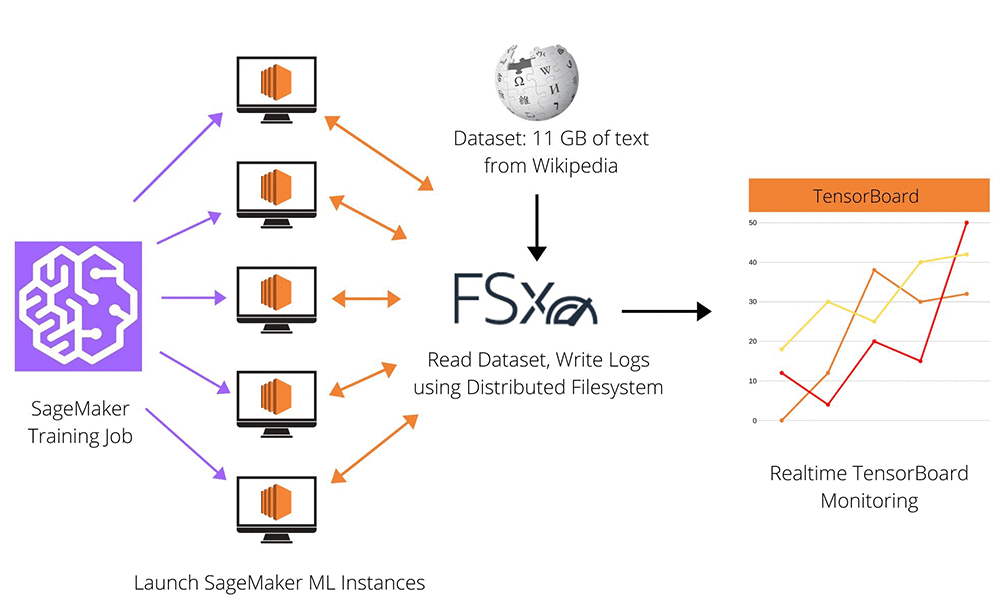
ワークフローには次の手順が含まれます。
- データセット (Wikipedia の記事のテキスト) を用意し、FSx ボリュームにダウンロードします。
- Amazon SageMaker は多くの ML インスタンスで分散トレーニングジョブを起動します。これらのインスタンスはすべて、FSx からシャーディングされたデータセットを読み取ります。
- インスタンスはモデルチェックポイントと TensorBoard ログを FSx に書き込みます。
- TensorBoard は FSx から読み取り、トレーニングの進行状況をリアルタイムでモニタリングします。
ALBERT モデルの概要
BERT 言語モデルは 2018 年後半にリリースされました。2019 年後半に、AWS は 256 の p3dn.24xlarge ノードにスケールアップすることにより、最速のトレーニング時間を達成しました。BERT のトレーニングに要した時間はわずか 62 分でした (以前の記録より 19% 高速)。このような最適化を拡張して、はるかに少ないリソースを使って ALBERT をトレーニングできます。たった 8 つのノードで 1 日とかからずに ALBERT をトレーニングします。
ALBERT は 2019 年後半にリリースされました。同等の BERT モデルより 18 倍少ないパラメータで 1.7 倍速くトレーニングでき、さらに優れたパフォーマンスを実現します。改善点は 3 つあります。
- クロスレイヤーの重み結合 – 各レイヤーが同じ重みを共有するため、パラメータの数が減ります。
- 埋め込み因数分解 – 言語語彙のサイズから非表示状態のサイズを分離します。
- 自己教師付き文順予測損失 – トレーニングのサンプル効率を高めます。
ALBERT の最大の利点は、パラメータが効率的であることにあります。これは、はるかに大きなバッチをメモリに格納してすばやく推論できるためです。何よりも、ALBERT は BERT と同じアーキテクチャと埋め込み形式を共有するため、以前に BERT を使用していたどのシナリオでも使用できます。 詳細情報と完全なモデルの詳細については、「ALBERT: 言語表現の自己教師付き学習のためのライト BERT」を参照してください。。
トレーニングのモデル化には 2 つのフェーズがあります。その 2 つとは、事前トレーニングフェーズと微調整フェーズです。事前トレーニングは、微調整に比べてコンピューティングコストがかかります (負荷の 98〜99%)。
事前トレーニング
事前トレーニングフェーズでは、モデルは、マスクされた言語モデリングと呼ばれる穴埋めタスクを学習します。次のような文が与えられた場合、予測された単語または語句で空白を埋めることがそのタスクです。
Michael Jeffrey Jordan (1963 年 2 月 17 日生まれ) は、イニシャル MJ でも知られ、___元プロのバスケットボール選手で、___バスケットボール協会 (NBA) のシャーロットホーネッツの___オーナーです。
答えは、アメリカの、全米、および筆頭です。文順予測と呼ばれる 2 番目のタスクもあります。これは、2 つの連続した文を取り、それらの半分の順序を切り替え、どのシーケンスがフリップされたかを予測します。このタスクのテキストのほとんどは、英語版のウィキペディアからのものです。
微調整
微調整フェーズでは、モデルはさまざまな種類のタスクを実行できます。この記事は質疑応答に焦点を当てています。Stanford Question Answering Dataset (SQuAD) は、NLP に固有の課題です。読解力テストと同じように、入力はコンテキストの段落と質問で、出力はコンテキスト文のサブセクションです。以下はコンテキスト文の例です。
アマゾンは、地球に今なお存在する熱帯雨林の半分以上を占めており、16,000 種、推定 3,900 億本の樹木が生い茂る、世界で最大かつ最も生物多様性に富んだ熱帯雨林です。
質問:
アマゾンは地球上の熱帯雨林で何パーセントを表していますか?
正解は、「アマゾンには地球に今なお存在する熱帯雨林の半分以上がある」、または「半分以上」です。
比較
事前学習済みモデルはコンテキスト表現を学習してから学習を転移させることで、事前学習済みモデルを微調整してさまざまなダウンストリームタスクに再利用できます。言語モデリングには 2 つの方法があります。
- 微調整のみ (シンプル) – これには 1 時間もかかりません。既存の事前トレーニング済みモデルをダウンロードして、事前トレーニングフェーズをスキップします。欠点は、ダウンロードしたモデルが事前トレーニングされたものとデータスタイルが異なる場合、この方法は不正確になる可能性があることです。
- 一から事前トレーニング (アドバンスト) – これにはより多くの専門知識が必要で、より正確なモデルが作成されます。独自のテキストデータセットを収集し、カスタムデータを一からトレーニングします。
この記事のスクリプトにより、両方のオプションが使えるようになります。
トランスフォーマーのオープンソースライブラリ
モデルアーキテクチャは、NLP の人気のあるオープンソースプロジェクトである Hugging Face のトランスフォーマーライブラリからのものです。トランスフォーマーを使用すると、モデルを簡単に入れ替えてすばやく比較できます。当社は新しいモデルを引き続きサポートしていき、機械学習の再現性に関する作業をオープンソース化していきます。すでに、次のようないくつかの重要なプルリクエスト (PR) のアップストリームをライブラリに提供しています。
- TensorFlow と PyTorch 向けの AlbertForPreTraining アーキテクチャを追加しました (#4057)。
- TFAlbert モデルの精度の問題を診断し、再トレーニングを支援しました (#2837)。
- 壊れたドロップアウトレイヤーを修正し、バイアスが重複するレイヤーを修正しました (#3928)。
- トランスフォーマレイヤー (プレレイヤーノルム) の最初にレイヤーの正規化をもってきて、トレーニングを安定させるためのサポートが追加されました (#3929)。
トレーニングの最適化
トレーニングクラスターをプロビジョニング、設定、または管理せずに、Amazon SageMaker で分散トレーニングジョブを実行できます。すべてのフレームワークと依存関係は事前にインストールされ、パフォーマンスが向上するように調整されています。全体として、このようなトレーニング最適化は、基本的なスクリプトよりもトレーニングを 10〜15 倍高速化します。具体的には、スクリプトは以下を使用します。
- 混合精度トレーニング – 3 倍高速。32 ビットではなく 16 ビットの浮動小数点を用いているため、モデルに必要なメモリを最大 50% 削減できます。これにより、モデルのトレーニングが速くなり、バッチサイズが大きくなります。また、数値の精度を向上させるために、損失スケーリング技術を組み込んでいます。
- 加速線形代数 (XLA) – 2 倍高速。特定の操作とカーネルを融合することで、メモリ使用量を減らし、トレーニング速度を上げることができます。
- サインの最適化 – 3 倍高速。特定の関数を TensorFlow グラフにインテリジェントにコンパイルすることで、メモリ使用量を減らしてトレーニング速度を上げることができます。
- 効率的なデータ読み込み – 言語モデルには大規模なデータセットが必要です。ALBERT は 16GB を使用します。16 GB というのは、11,000 冊の本とすべての英語版ウィキペディア分のサイズです。Amazon FSx for Lustre を使用しています。これは、ML ワークロード用に特別に構築された高性能ファイルシステムです。他のストレージソリューションとは異なり、FSx は数百のマシンに並列に接続できるため、データセットを 1 つの場所に一元的に保存し、リアルタイムで効率的にシャード化できます。
結果
基本モデルと大規模モデルの両方で目標の精度に到達し、通常必要なトレーニング時間よりもはるかに短いトレーニング時間で済みました。
- 125,000 ステップの事前トレーニングを実行し、8 つの p3dn.24xlarge ノードでの合計バッチサイズは 4,096 で 20 時間かかりました。
- 1 つの p3.16xlarge ノードで 20 分間、合計バッチサイズ 48 で 8,144 ステップの微調整を実行しました。
さらに長い期間の事前トレーニングにより、精度がさらに向上します。時間とコストの両方を最小化することに重点が置かれているため、そのコンピューティング予算のほんの一部を使って比較的強力な精度を実現しています。
SQuAD スコアリングは、完全一致と F1 という 2 つのメトリクスを介して行われます。完全一致は、選択した回答が正確に一致したかどうかを測定します。F1 は、予測された回答の各単語の精度と再現率の両方を組み合わせた測定です。これらのメトリクスはどちらも 0〜100 の範囲で、F1 は完全一致と同じかそれ以上です。
| モデルサイズ | トレーニング時間 | F1/完全一致 |
| ALBERT-base | 20 時間 | 78.4/75.2 |
| ALBERT-large | 59 時間 | 79.1/75.6 |
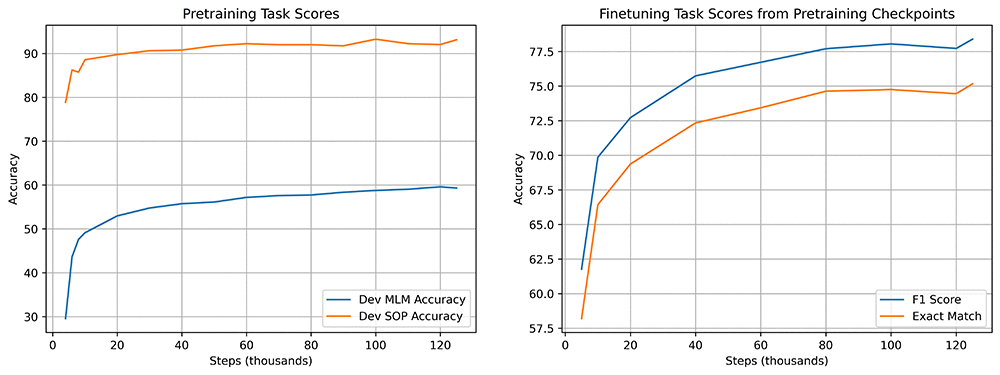
次のグラフは、トレーニング中のモデルの品質を示しています。1 つ目は、事前トレーニング中に使用されるマスク言語モデリング (MLM) と文順予測 (SOP) タスクのスコアを示しています。2 番目は、事前トレーニング中にさまざまなチェックポイントから微調整したときの質疑応答 (SQuAD) の精度を示しています。MLM および SOP タスクの改善は、より高い SQuAD 精度と相関しています。
事前トレーニングにとって最も時間効率とコスト効率が高いインスタンスタイプはどれですか?
p3dn.24xlarge が最も高速で、g4dn.12xlarge が最もコスト効率が高いインスタンスタイプです。 言語モデルには大量の GPU メモリが必要です。3 つの異なる GPU タイプを相互にベンチマークしました。GPU VRAM が増えると、バッチサイズが大きくなり、トレーニングステップが速くなりますが、コストが増加します。
| インスタンスタイプ | トレーニング時間 | ノード | バッチ x 勾配の累積 | 合計バッチ | 反復/秒 |
| ml.p3dn.24xlarge (8x32GB Tesla V100) | 20 時間 | 8 | 32×2 | 4096 | 1.72 |
| ml.p3.16xlarge (8x16GB Tesla V100) | 39 時間 | 8 | 16×4 | 4096 | 1.01 |
| ml.g4dn.12xlarge (4x16GB Tesla T4) | 78 時間 | 16 | 16×4 | 4096 | 0.51 |
モデルは、シングルノードからマルチノードまでどの程度効率的にスケーリングできるでしょうか?
勾配の累積を適用すると、ALBERT は 95% という驚異的なスケーリング効率を発揮します。スケーリング効率とは、単一ノードのモデルと比較した場合の、複数のノードに分散されたモデルの相対的なスループットを指します。限られた数のノードで大規模な言語モデルをトレーニングする場合、勾配の累積により、大きなグローバルバッチサイズを使用して最高の精度を得ることができます。また、単一バッチ時間で測定された従来のスケーリング効率は、ベースモデルでは 91% で実行されることも示しています。BERT の 1 億 1000 万のパラメータと比較して、ベースモデルには 1200 万のパラメータがあるため、ALBERT は非常に適切にスケーリングします。通信オーバーヘッドが低いため、分散トレーニングの理想的な候補になります。次の表は、勾配の累積がある場合とない場合のスケーリング効率をまとめたものです。
次の表は、512 トークンのシーケンスによるスケーリング効率と勾配の累積を示しています。
| モデルサイズ | 1 ノードシーケンス/秒 | 8 ノードシーケンス/秒 | 効率 |
| ALBERT ベース (バッチ 32、2 acc) | 931 | 7045 | 95% |
| ALBERT-large (バッチ 16、4 acc) | 322 | 2457 | 95% |
次の表は、勾配の累積なしのスケーリング効率を示しています。
| モデルサイズ | 1 ノードシーケンス/秒 | 8 ノードシーケンス/秒 | 効率 |
| ALBERT ベース (バッチ 32) | 888 | 6438 | 91% |
| ALBERT-large (バッチ 16) | 311 | 2109 | 85% |
モデルの実行
モデルの実行には、次の手順が含まれます。
- FSx ボリュームを作成します。
- FSx でデータを準備します。
- カスタム Docker コンテナを構築します。
- SageMaker で Horovod 事前トレーニングジョブを実行します。
- SageMaker で Horovod の微調整ジョブを実行します。
- TensorBoard でトレーニング結果をモニタリングします。
詳細な手順については、aws-samples/deep-learning-models GitHub リポジトリを参照してください。以下の手順は、v0.2 タグに対応しています。
FSx ボリュームの作成
- cloudformation/fsx.yaml で、LustreBucketName を一意の S3 バケット名に置き換え、SubnetId をデフォルト VPC のメインサブネットに置き換えます。
- 次のコマンドを入力します。完了するまでに 5〜10 分かかります。
- CloudFormation コンソールに移動し、[スタック] をクリックして、新しい FSx ファイルシステムの ID をメモします。
- cloudformation/ec2.yaml で、VPC と一致するように VPCId を置き換え、既存の EC2 SSH キー認証情報の名前として KeyName を指定し、新しく作成された FSx FileSystem の ID と一致するように FileSystem を設定し、ステップ 1 で指定されたバケットと一致するように LustreBucketName を設定します。
- 次のコマンドを入力します。完了するまでに 1〜2 分かかります。
- これで FSx ファイルシステムと EC2 インスタンスができました。 インスタンスに SSH 接続し、
ls/fsxを実行して、新しくマウントされたファイルシステムを表示します。
FSx でのデータの準備
EC2 インスタンスにアタッチして SSH で接続することにより、FSx ファイルシステムに直接データセットを準備します。Amazon S3 のアップロードは必要ありません。
Wikipedia のデータセットを自分でダウンロードすると、簡単に開始できます。これには、英語の Wikipedia の記事からの 12GB テキストのダンプが含まれています。ダウンロードする前にデータセットライセンスを読んで内容を理解しましょう。または、独自のカスタムデータセットをご使用ください。データは、1 行に 1 つの記事を含む単一のテキストファイルとして構造化する必要があります。次に、GitHub リポジトリの指示に従って、データを前処理します。
カスタム Docker コンテナの構築
Docker コンテナを構築して Amazon Elastic Container Registry (ECR) にプッシュするには、次のコードを実行します。
FSx 環境変数の定義
起動スクリプトは、環境変数を使用して FSx ボリュームを指します。コマンドラインで次の変数を定義します。
Amazon SageMaker で Horovod 事前トレーニングジョブを実行する
次のコードを使用して、SageMaker で horovod 事前トレーニングジョブを実行します。
Amazon SageMaker で Horovod の微調整ジョブを実行する
モデル名は、事前トレーニングスクリプトの Tensorboard ログまたは stdout ログにあります。次のコードを使って微調整ジョブを実行します。
TensorBoard のモニタリング
- FSx にマウントされた EC2 インスタンスで、次のコードを実行します。
- ローカルコンピューターで、次のコードを実行します。
- 次に、ウェブブラウザで localhost:6006 を開き、トレーニングをモニタリングします。 実行例を以下に示します。
まとめ
この記事では、Amazon SageMaker で一から ALBERT 言語モデルをトレーニングする方法を示しました。加速線形代数や混合精度トレーニングなどの最適化により、ベースラインの 5 倍の速度でトレーニングを高速化できます。詳細とトレーニングスクリプトについては、aws-samples/deep-learning-models GitHub リポジトリをご覧ください。
著者について
 Jared Nielsen は、AWS Deep Learning の機械学習エンジニアです。彼は最先端の機械学習研究をお客様にお届けするのを手伝っています。仕事以外では、ロッククライミングを楽しんだり、すばらしい本を読んだりしています。
Jared Nielsen は、AWS Deep Learning の機械学習エンジニアです。彼は最先端の機械学習研究をお客様にお届けするのを手伝っています。仕事以外では、ロッククライミングを楽しんだり、すばらしい本を読んだりしています。
 Derya Cavdar は、AWS Deep Learning のソフトウェアエンジニアとして働いています。彼女は 2016 年にボガジチ大学でコンピューターエンジニアリングの博士号を取得しました。彼女は、ディープラーニング、分散システム、最適化などに興味を抱いています。
Derya Cavdar は、AWS Deep Learning のソフトウェアエンジニアとして働いています。彼女は 2016 年にボガジチ大学でコンピューターエンジニアリングの博士号を取得しました。彼女は、ディープラーニング、分散システム、最適化などに興味を抱いています。
 Aditya Bindal は、AWS Deep Learning のシニアプロダクトマネージャーです。彼は、顧客のために深層学習エンジンを使いやすくする製品に取り組んでいます。余暇には、テニスをしたり、歴史小説を読んだり、旅行を楽しんだりしています。
Aditya Bindal は、AWS Deep Learning のシニアプロダクトマネージャーです。彼は、顧客のために深層学習エンジンを使いやすくする製品に取り組んでいます。余暇には、テニスをしたり、歴史小説を読んだり、旅行を楽しんだりしています。