Amazon Web Services ブログ
Amazon Redshiftを使用した高性能ETL処理のベストプラクティス Top 8
ETL(Extract、Transform、Load)プロセスを使用すると、ソース・システムからデータ・ウェアハウスにデータをロードできます。 これは、通常、バッチまたはほぼリアルタイムのインジェスト(挿入)プロセスとして実行され、データウェアハウスを最新の状態に保ち、エンドユーザーに最新の分析データを提供します。
Amazon Redshiftは、高速でペタバイト規模のデータウェアハウスであり、データ駆動型の意思決定を簡単に行うことができます。 Amazon Redshiftを使用すると、標準的なSQLを使用して、費用対効果の高い方法で大きなデータを洞察することができます。 StarおよびSnowflakeスキーマから、分析クエリを実行するための単純化された正規化されていないテーブルまで、あらゆるタイプのデータモデルを使用した分析が可能です。
堅牢なETLプラットフォームを操作し、Amazon Redshiftにデータをタイムリーに配信するには、Amazon Redshiftのアーキテクチャを考慮してETLプロセスを設計します。 従来のデータウェアハウスからAmazon Redshiftに移行する場合、リフト・アンド・シフト方式を採用することが魅力的ですが、結果としてパフォーマンスとスケールの問題が長期的に発生する可能性があります。 この記事では、ETLプロセスにおける最適かつ一貫した実行時間を確保するためのベスト・プラクティスを下記にご紹介します。
- 複数の均等なサイズのファイルからデータの COPY
- Workload Management (WLM) を用いたETL実行時間の改善
- 定期的なテーブルのメンテナンスの実施
- 単一のトランザクションで複数ステップの実行
- データの一括読み込み
- UNLOADを利用した大きな結果セットの抽出
- アドホックETL処理に Amazon Redshift Spectrumを使用
- 診断クエリを使用して日常的なETLヘルスの監視
1. 複数の均等なサイズのファイルからデータの COPY
Amazon RedshiftはMPP(大規模並列処理)データベースで、すべての計算ノードがデータの取り込み作業を分割して並列化します。 各ノードはさらにスライスに細分され、各スライスは1つ以上の専用コアを有し、処理能力を等しく分割します。 ノードあたりのスライス数は、クラスタのノードタイプによって異なります。 たとえば、各DS2.XLARGE計算ノードには2つのスライスがありますが、各DS2.8XLARGE計算ノードには16のスライスがあります。
Amazon Redshiftにデータを読み込むときは、各スライスに同じ量の作業をさせることを目指すべきです。 1つの大きなファイルまたは不均一なサイズに分割されたファイルからデータをロードすると、一部のスライスは他のスライスよりも多くの仕事をする必要があります。 その結果、プロセスは最も遅い、または最も負荷の高いスライスと同じ速度で実行されます。 以下の例では、1つの大きなファイルが2ノードのクラスタにロードされ、ノード「Compute-0」のうちの1つだけがすべてのデータ処理を実行します。

データファイルを分割する際には、圧縮後のサイズがほぼ同じ(1 MB〜1 GB)であることを確認してください。 ファイル数は、クラスタ内のスライス数の倍数にする必要があります。 また、gzip、lzop、またはbzip2を使用してロードファイルを個別に圧縮し、大規模なデータセットを効率的にロードすることを強くお勧めします。
1つのテーブルに複数のファイルをロードする場合は、複数のCOPYコマンドではなく、テーブルに対して1つのCOPYコマンドを使用します。 Amazon Redshiftはデータの取り込みを自動的に並列化します。 1つのCOPYコマンドを使用してデータをテーブルにバルクロードすると、クラスタリソースの最適な使用と可能な限り高いスループットが可能となります。
2. Workload Management (WLM) を用いたETL実行時間の改善
Amazon RedshiftのWLM(Workload Management)を使用して、さまざまなワークロード専用の複数のキュー(ETL対レポートなど)を定義したり、クエリの実行時間を管理したりすることができます。 より多くのワークロードをAmazon Redshiftに移行すると、WLMが適切に設定されていない場合は、効果的にETLが実行できない場合があります。
すべてのキュー合計でWLMの全体的な並行量を15もしくはそれ以下に制限することをお勧めします。 このWLMガイドは、Amazon Redshiftクラスターのさまざまなキューを整理してモニターするのに役立ちます。
Amazon Redshiftクラスタ上で異なるワークロードを管理する場合は、キューの設定に関して次の点を考慮してください。
- ETLプロセス専用のキューを作成します。少数のスロット(5以下)でこのキューを構成します。 Amazon Redshiftは、トランザクション処理ではなく、分析クエリ用に設計されています。 COMMITのコストは比較的高く、COMMITを過剰に使用すると、照会がコミット・キューへのアクセスを待ってしまうことがあります。 ETLはコミットが集中するプロセスなので、スロット数の少ない別のキューを使用すると、この問題を緩和できます。
- キューに追加のメモリーを割り当てます。 ETLクエリを実行するときは、wlm_query_slot_countを利用して、特定のキューで追加のメモリーを使用可能にすることができます。たとえば、一般的なETLプロセスでは、未処理データをステージングテーブルにCOPYし、ダウンストリームETLジョブが日別、週別、および月別の集約を計算する変換を実行できるようにしています。ダウンストリーム・タスクをより早く開始できるように、COPYプロセスを高速化するには、このステップでwlm_query_slot_countを増やすことができます。
- レポートクエリ用に別のキューを作成します。長期的かつ高価なクエリをさらに管理するために、このキューでクエリモニタリングルールを構成します。
- ダイナミックメモリパラメータを活用します。ETLジョブ中はレポートキューとメモリのサイズを入れ替え、終わったら再度入れ替えます
3. 定期的なテーブルのメンテナンスの実施
Amazon Redshiftは、データを集約するための高速変換を可能にする列指向データベースです。通常の表のメンテナンスを実行することで変換ETLを予測可能で良いパフォーマンスな状態に維持できます。 Amazon Redshiftデータベースから最高のパフォーマンスを引き出すには、データベーステーブルが定期的にVACUUMおよびANALYZEされていることを確認する必要があります。 AnalyzeとVacuumスキーマユーティリティは、テーブルメンテナンスタスクを自動化し、定期的にVACUUMとANALYZEを実行するのに役立ちます。
- VACUUMを使用してテーブルをソートし、DELETEされたブロックを削除する
通常のETLリフレッシュ・プロセスでは、テーブルはCOPYを使用して新しい受信レコードを受信し、不要なデータ(コールド・データ)はDELETEを使用して削除されます。新しい行がテーブル内の未ソート領域に追加されます。削除された行は単に削除対象としてマークされます。
DELETEは、削除された行が占める領域を自動的に再利用可能にはしません。したがって、多数の行を追加および削除すると、ソートされていない領域と削除されたブロックの数が増える可能性があります。これにより、これらのテーブルに対して実行される照会のパフォーマンスが低下することがあります。
ETLプロセスが完了したら、VACUUMを実行して、ユーザー照会が一貫した方法で実行されるようにします。 VACUUM を必要とするテーブルの完全なリストは、Amazon Redshift ユーティリティのtable_infoスクリプトを使用して見つけることができます。
VACCUMがタイムリーに完了するように、次の方法を使用してください。
- wlm_query_slot_countを使用して、VACUUMプロセス中にETL WLMキューに割り当てられたすべてのメモリーを利用可能にします。
- 中間またはステージング・テーブルをDROPまたはTRUNCATEすることにより、それらをVACUUMする必要がなくなります。
- テーブルにソート列が1つのみの複合ソートキーがある場合は、データをソートキー順に読み込む事を試みてください。これは、テーブルをVACUUMする必要性を低減または排除するのに役立ちます。
- 時系列の使用を検討するこれは、VACUUMに必要なデータの量を減らすのに役立ちます。
- ANALYZEを使用してデータベース統計を更新します。
Amazon Redshiftは、コストベースのクエリプランナとオプティマイザを使用して、テーブルに関する統計情報を使用して、SQL文のクエリプランについて適切な判断を下します。 ETL完了後の定期的な統計収集により、ユーザークエリが高速に実行され、毎日のETLプロセスを効率的に実行可能になります。 Amazon Redshift ユーティリティのtable_infoスクリプトは、統計の鮮度についての洞察を提供します。統計が取れていない状態(pct_stats_off)を20%未満に維持すると、SQLクエリに対する効果的なクエリプランが確保されます。
4. 単一のトランザクションで複数ステップの実行
ETL変換ロジックは、多くの場合、複数のステップに分かれています。 Amazon Redshiftのコミットはコストが高いため、各ETLステップがコミットを実行すると、複数の同時ETLプロセスの実行に時間がかかることがあります。
プロセス内のコミット数を最小限に抑えるには、すべての変換ロジックが実行された後で1回のコミットが実行されるように、ETLスクリプト内のステップをBEGIN … ENDステートメントで囲む必要があります。 たとえば、最後に1つのコミットを実行するマルチステップETLスクリプトの例を次に示します。
Begin
CREATE temporary staging_table;
INSERT INTO staging_table SELECT .. FROM source (transformation logic);
DELETE FROM daily_table WHERE dataset_date =?;
INSERT INTO daily_table SELECT .. FROM staging_table (daily aggregate);
DELETE FROM weekly_table WHERE weekending_date=?;
INSERT INTO weekly_table SELECT .. FROM staging_table(weekly aggregate);
Commit5. データの一括読み込み
Amazon Redshiftは、ペタバイト規模のデータセットを格納して照会するように設計されています。 Amazon S3を使用すると、大量のCOPY操作を実行する前に、複数のソースシステムからデータをステージングして蓄積することができます。 下記の方法を使うことで、これらのバルクデータセットをAmazon Redshiftに効率的かつ迅速に転送できます。
- マニフェストファイルを使用して、複数のファイルにまたがる大規模なデータセットを取り込みます。マニフェストファイルは、Amazon Redshiftにロードするすべてのファイルを一覧表示するJSONファイルです。マニフェストファイルを使用することにより、Amazon RedshiftはS3からロードされるデータの一貫性のあるビューを保ちながら、重複したファイルによって同じデータが複数回読み込まれることがなくなります。
- 一時的なステージングテーブルを使用して、変換のためのデータを保持します。これらのテーブルは、ETLセッションの完了後に自動的に削除されます。テンポラリ・テーブルは、CREATE TEMPORARY TABLE構文を使用するか、SELECT … INTO #TEMP_TABLEクエリを発行して作成できます。明示的にCREATE TEMPORARY TABLEステートメントを指定すると、DISTRIBUTION KEY、SORT KEY、および圧縮を設定して、パフォーマンスをさらに向上させることができます。
- ALTER TABLE APPENDを使用して、ステージングテーブルからターゲットテーブルにデータをスワップします。ソーステーブルのデータは、ターゲットテーブルの一致する列に移動されます。列の順序は関係ありません。データが正常にターゲットテーブルに追加された後、ソーステーブルは空になります。 ALTER TABLE APPENDは、データのコピーまたは移動を伴わないため、同様のCREATE TABLE ASによる操作またはINSERT INTOによる操作よりもはるかに高速です。
6. UNLOADを利用して大きな結果セットの抽出
SELECTを使用して多数の行をフェッチするのは高価で時間がかかります。 大量のデータがAmazon Redshiftクラスタからフェッチされると、リーダーノードはフェッチが完了するまでデータを一時的に保持する必要があります。 加えて、データは順次転送されるため、それが終わるまでより長い時間が必要になります。 その結果、リーダーノードの負荷が増大する可能性があり、実行されているSELECTに影響を与えるだけでなく、実行計画を作成し、全体的なクラスターリソースを管理するためのリソースに影響を与えます。 大規模なSELECT文の例を次に示します。 リーダ・ノードが行をストリーム・アウトするためのほとんどの作業を行っていることに注意してください。
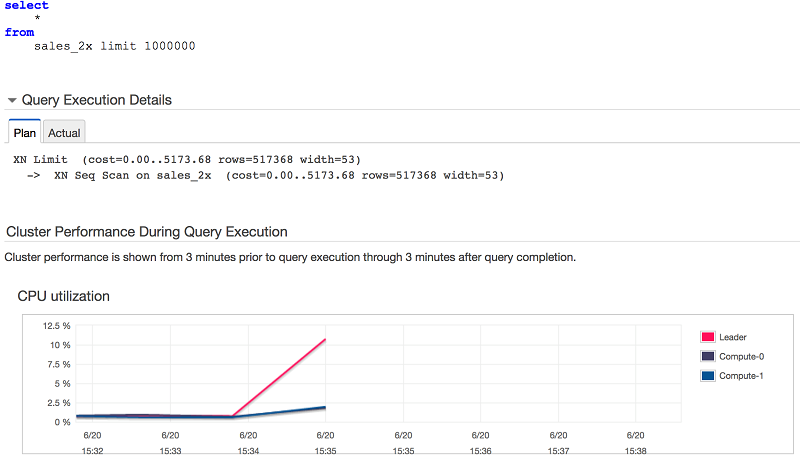
UNLOADを使用して大きな結果セットを直接S3に抽出しましょう。 それがS3に入ったのちは、下流にある複数のシステムとデータを共有することができます。 デフォルトでは、UNLOADはクラスタ内のスライス数に応じて複数のファイルに並列にデータを書き込みます。 すべての計算ノードが参加して、データをS3に迅速にオフロードします。
Amazon Redshift Spectrumで使用するデータを抽出する場合は、MAXFILESIZEパラメータを使用してファイルを150 MBに保つべきです。 前述のベストプラクティス1と同様に、均等なサイズのファイルが多数あると、Redshift Spectrumは最大限の処理を並行して実行できます。
7. アドホックETL処理に Amazon Redshift Spectrumを使用
データのバックフィル、プロモーションアクティビティ、特別な暦日などのイベントは、Amazon Redshiftクラスタのデータ更新時間に影響を与える追加のデータボリュームをトリガする可能性があります。 これらのデータ量とスループットの急上昇に対処するため、S3でデータをステージングすることをお勧めします。 S3でデータを整理した後、Redshift Spectrumでは標準的なSQLを使用して直接クエリすることができます。 このようにして、クラスタのサイズを変更することなく、追加した容量によるメリットを得ることができます。
Redshift Spectrumの使用を開始して最適化するためのヒントについては、前の記事、Amazon Redshift Spectrumの10のベストプラクティスを参照してください。
8. 診断クエリを使用した日常的なETLヘルスの監視
ETLプロセスの正常性を定期的に監視することで、パフォーマンス上の問題がクラスタに大きな影響を及ぼす前に、早期に発生する問題を特定することができます。 次の監視スクリプトを使用して、ETLプロセスの健全性を把握することができます。
| スクリプト | いつ利用するか | ソリューション |
|---|---|---|
| commit_stats.sql – Commit queue statistics from past days, showing largest queue length and queue time first | INSERT / UPDATE / COPY / DELETE操作などのDML文においてこれらの操作の複数が実行された際に、実行に数倍の時間を要している場合 | ETLプロセス用に個別のWLMキューをセットアップし、並列数を5未満に制限します。 |
| copy_performance.sql – Copy command statistics for the past days | 日々のCOPY操作で長時間要している場合 | •COPYコマンドのベストプラクティスに従ってください
•受信データセットを使用してデータの増加を分析し、期待されるSLAを満たすようにクラスタのサイズ変更を検討してください |
| table_info.sql – Table skew and unsorted statistics along with storage and key information | 変換ステップで長時間要している場合 | •通常のVACCUMジョブを設定して、ソートされていない行を対処し、削除されたブロックを要求して、変換SQLが最適に実行されるようにします。
•データスキューを避けるために、テーブルの再設計を検討してください。 |
| v_check_transaction_locks.sql – Monitor transaction locks | 特定のテーブルに対する INSERT/UPDATE/COPY/DELETE 操作が、ETL後の実行と比較して、タイムリーに応答しない場合 | 複数のDML文が、異なるトランザクションから同時に同じターゲットテーブルを操作している状態です。 同じターゲットテーブルに対して順次実行するようにETLジョブの依存関係を設定します。 |
| v_get_schema_priv_by_user.sql – Get the schema that the user has access to | レポーティングユーザーが中間テーブルを参照する可能性がある場合 | レポートおよびETLユーザー用に個別のデータベース・グループを設定し、GRANTを使用してオブジェクトへのアクセスを許可します。 |
| v_generate_tbl_ddl.sql – Get the table DDL | データバックフィルのために、ターゲットテーブルと同じ構造のからテーブルを作成する必要がある場合 | このスクリプトを使用してデータバックフィル用のDDLを生成します。 |
| v_space_used_per_tbl.sql – monitor space used by individual tables | Amazon Redshiftのデータウェアハウスの領域の増加率が、通常以上に増加傾向にある場合 | 通常より高いレートで成長している個々のテーブルを分析します。 後で分析するためにUNLOAD を使用して S3とRedshift Spectrumへのデータアーカイブを検討してください。 unscanned_table_summary.sqlを使用して未使用のテーブルを検索し、それらをアーカイブまたはドロップします。 |
| top_queries.sql – Return the top 50 time consuming statements aggregated by its text | ETL変換処理に長時間要している場合 | 最も時間が掛かる変換SQLを分析し、EXPLAINを使用してクエリプランを調整する機会を見つけます。 |
amazon-redshift-utils(https://github.com/awslabs/amazon-redshift-utils/tree/master/src)リポジトリには、他にも有用なスクリプトがいくつかあります。 AWS Lambda Utility Runner(https://github.com/awslabs/amazon-redshift-utils/tree/master/src/LambdaRunner)は、これらのスクリプトのサブセットをスケジュール通りに実行し、大量のETLプロセス監視を自動化することができます。
ETLプロセスの例
以下のETLプロセスは、この記事で説明したベストプラクティスの一部を強化しています。 RDBMSソースシステムからのデータがS3にステージングされ、次にAmazonのRedshiftにロードされるという、以下のの4ステップの日次のETLワークフローを考えてみましょう。 Amazon Redshiftは、日次、週次、月次の集計を計算するために使用されます。S3は、Redshift SpectrumやAmazon Athenaなどのさまざまなツールを使用して処理され、エンドユーザーのレポート作成に使用されます。

ステップ 1: RDBMSソースからS3バケットへの抽出
このETLプロセスでは、データ抽出ジョブは1時間ごとに変更データをフェッチし、複数の時間別ファイルにステージングします。 たとえば、ステージングされたS3のフォルダは次のようになります。
[ec2-user@ip-172-81-1-52 ~]$ aws s3 ls s3://<<S3 Bucket>>/batch/2017/07/02/ 2017-07-02 01:59:58 81900220 20170702T01.export.gz 2017-07-02 02:59:56 84926844 20170702T02.export.gz 2017-07-02 03:59:54 78990356 20170702T03.export.gz … 2017-07-02 22:00:03 75966745 20170702T21.export.gz 2017-07-02 23:00:02 89199874 20170702T22.export.gz 2017-07-02 00:59:59 71161715 20170702T23.export.gz
データを複数の均等なサイズのファイルで構成することで、COPYコマンドはAmazon Redshiftクラスタ内のすべての利用可能なリソースを使用してこのデータを取り込むことができます。 さらに、ファイルはCOPYに要する時間をさらに短縮するために圧縮(gzip)されます。
ステップ2: クレンジングのためにデータを Amazon Redshift へステージングする
データの取り込みは、JSONベースのマニフェストファイルを使用して行うことができます。 マニフェストファイルを使用することで、最終的なS3の整合性の問題を排除し、必要に応じて任意のファイルを削除することができます。 サンプルのmanifest20170702.jsonファイルは、次のようになります。
{
"entries": [
{"url":" s3://<<S3 Bucket>>/batch/2017/07/02/20170702T01.export.gz", "mandatory":true},
{"url":" s3://<<S3 Bucket>>/batch/2017/07/02/20170702T02.export.gz", "mandatory":true},
…
{"url":" s3://<<S3 Bucket>>/batch/2017/07/02/20170702T23.export.gz", "mandatory":true}
]
}データは下記のコマンドを利用して取り込むことができます
SET wlm_query_slot_count TO <<ETLキューの最大並列実行値>>; COPY stage_tbl FROM 's3:// <<S3 Bucket>>/batch/manifest20170702.json' iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole' manifest;
ダウンストリームETLプロセスの完了はこのCOPYコマンドに依存するため、wlm_query_slot_countにより、キューで利用可能なすべてのメモリーを使用させます。 これにより、COPYコマンドはできる限り迅速に完了します。
ステップ3: 日次、週次、月次データセットへのデータの変換と、ターゲットテーブルへのロード
データは、「stage_tbl」にステージングされ、日次、週次、月次集計として変換され、ターゲットテーブルにロードされます。 以下のジョブは、一般的な週次プロセスを示しています。
Begin
INSERT into ETL_LOG (..) values (..);
DELETE from weekly_tbl where dataset_week = <<current week>>;
INSERT into weekly_tbl (..)
SELECT date_trunc('week', dataset_day) AS week_begin_dataset_date, SUM(C1) AS C1, SUM(C2) AS C2
FROM stage_tbl
GROUP BY date_trunc('week', dataset_day);
INSERT into AUDIT_LOG values (..);
COMMIT;
End;
上記の通り、複数のステップが1つのトランザクションに結合されて1つのコミットを実行し、コミット・キューの競合を削減します。
ステップ4: 日次データセットをアンロードして、S3データレイクのバケットに投入する
変換結果は、Redshift SpectrumやAmazon Athenaなどの様々なツールを用いてエンドユーザーが処理してレポーティングすることができるように、別のS3バケットにアンロードされます。
unload ('SELECT * FROM weekly_tbl WHERE dataset_week = <<current week>>’) TO 's3:// <<S3 Bucket>>/datalake/weekly/20170526/' iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
サマリ
Amazon Redshiftを使用すると、クラウド上でペタバイト規模のデータウェアハウスを簡単に操作できます。 この記事では、Amazon Redshift内でスケーラブルETLをネイティブに操作するためのベストプラクティスをまとめたものです。 私は、データを取り込み、変換する効率的な方法と、詳細なモニタリングをご覧いただきました。 また、データをAmazon Redshiftに変換するための典型的なサンプルETLワークロードで使用されているベスト・プラクティスをお伝えしました。
参考情報
この記事がお役に立った場合は、Amazon Redshiftの “Top 10 Performance Tuning Techniques for Amazon Redshift” (https://thinkwithwp.com/blogs/big-data/top-10-performance-tuning-techniques-for-amazon-redshift/) と “10 Best Practices for Amazon Redshift Spectrum” (https://thinkwithwp.com/blogs/big-data/10-best-practices-for-amazon-redshift-spectrum/) も併せてご覧ください。
筆者について
 |
Thiyagarajan Arumugamは、Amazon Web ServicesのBigData Solutions Architectであり、スケールする環境でのデータを処理するためのお客様のアーキテクチャを設計しています。AWSの前は、Amazon.comでデータウェアハウスソリューションを構築しました。時間があるときは、彼は様々なアウトドアスポーツを楽しみ、またインドの古典的なドラム “mridangam” の練習に励んでいます。 |
原文はこちら。翻訳はSA大井が担当致しました。