Amazon Web Services ブログ
Amazon DynamoDB におけるシングルテーブル vs マルチテーブル設計
この文書は、AWS ヒーローであるAlex DeBrie によるゲスト投稿です。
Amazon DynamoDB について学ぶ人にとって、シングルテーブル設計という考え方は、最も心を揺さぶるコンセプトの1つです。DynamoDBのテーブルは、エンティティごとにテーブルを持つというリレーショナルデータベースのような概念ではありません。多くの場合、1つのテーブルに複数の異なるエンティティを含みます。
DynamoDBのシングルテーブルに関するデザインパターンについては、DynamoDBのデベロッパーガイドを読む、re:Inventのトークやその他のビデオを見る、私が執筆した本をチェックするなどで理解することができます。シングルテーブル設計の賛否両論に特に焦点を当てながら、このトピックを高い視点で説明していきたいと思います。
この記事では、DynamoDBにおけるシングルテーブル設計について説明します。まず、データモデリングの議論に役立つDynamoDBの関連する背景を説明します。次に、シングルテーブル設計があなたのアプリケーションでどのような場合に役立つかを説明します。最後に、DynamoDBで複数のテーブルを使用した方が良い例をいくつか紹介します。
DynamoDB にまつわる関連背景
シングルテーブル設計とマルチテーブル設計のメリットの比較に本格的に入る前に、DynamoDB にまつわる背景から始めましょう。ここで余す所なく全てをカバーするには紙面が足りませんので、シングルテーブル対マルチテーブルの議論に関連するいくつかの要点を押さえます。
これらを押さえるにあたって、それらを束ねるひとつの包括的なテーマがあります。それは、DynamoDB は現実を晒したい、そのことでアプリケーション要求に対して正しい判断をすることができる、ということです。多くのデータベースは、低いレベルのビットの抽象化を提供します。抽象化によって柔軟な方法でデータをクエリすることが容易になりますが、同時に重要な詳細が隠蔽されます。詳細が隠蔽されることで、データベースが予期しない方法でスケールしたり、使用量が増えたときにかかる多額のコストを理解することが難しくなったりすることがあります。
このことを念頭に置いて、DynamoDB の際立った特徴を見ていきましょう。
着実なスケーリングのための基礎的なふたつの核となる仕組み
何よりも、DynamoDBはアプリケーションのスケールに応じて着実なパフォーマンスを実現することを望んでいます。データベースのサイズや同時実行クエリ数に関係なく、全ての操作に対して同じ一桁ミリ秒のレスポンスタイムを提供することをDynamoDBは目指しています。
このために、DynamoDB はふたつの核となる仕組みに依存しています。それがパーティショニングとB-Tree です。これらを強固な基礎とすることで、DynamoDB はペタバイト級のデータや数百万の同時実行クエリに対してテーブルをスケールさせることができます。
まずパーティショニングです。伝統的なリレーショナルデータベースにおいては、全てのアイテムは単一のノード上に格納されます。データや使用量が増加した際は、インスタンスサイズを増強して追随するかもしれません。しかし、垂直スケーリングには限界があり、データサイズの増加によってリレーショナルデータベースのパフォーマンスが劣化することがよくあります。
これを避けるため、DynamoDBではパーティショニングを採用して水平スケーリングを実現します。DynamoDB テーブル内の各アイテムは、ひとつのパーティションキーを持ちます。内部的には、DynamoDB はデータベースをパーティションと呼ばれる区分に分割しています(以下図1 に示します)。各パーティションは最大10GBのデータを保持します。
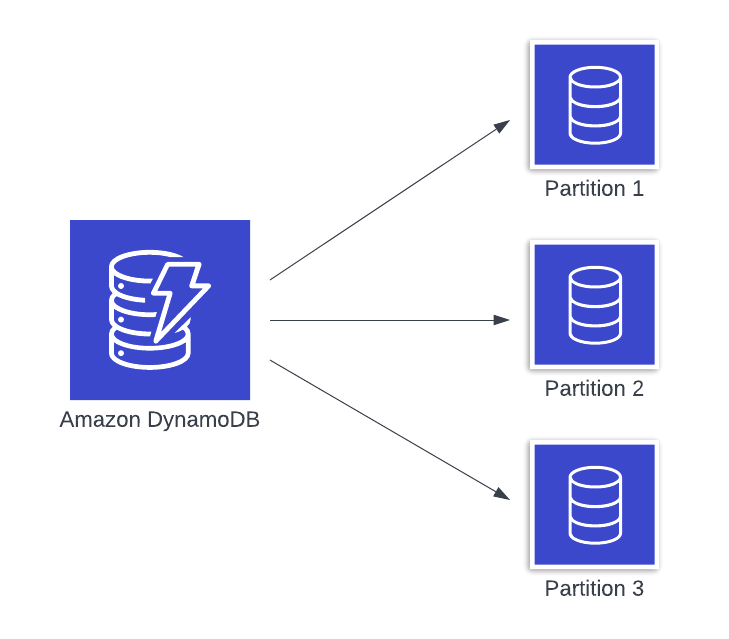
図1: 3つのパーティションに分割されたDynamoDB データベース
DynamoDB にリクエストが到達すると、リクエストルーター層が所与のアイテムに対するパーティションの場所を探索し、図2 に示されるように、処理のために適切なパーティションに向けてリクエストを転送します

図2: 処理するのに適切なパーティションに転送されるリクエスト
テーブルが大きくなっても、DynamoDB はシームレスに新しいパーティションを追加し、ワークロードにあわせてスケールするようデータを再分配することができます。メタデータサブシステムはパーティションキーの範囲(レンジ)とストレージノードのマッピングを維持し、対応するパーティションに素早くリクエストを転送することができます。
パーティショニングが水平スケーリングを可能にする一方で、単一のリクエスト内で、ある一定範囲の関連したアイテムを取得しななければならないこともよくあります。ここでDynamoDBのふたつめの核となる仕組みが登場します。B-tree は、ソート済みデータの保持に効率の良い方法です。これは多くのデータアプリケーションにおいて有効で、例えばユーザネームをアルファベット順に並べ替えたり、注文時刻によって電子取引の注文を並べ替えたりします。
DynamoDB は各パーティション上のアイテムを、パーティションキーと(もしそのテーブルで使われていてれば)ソートキーに従って整列されたB-Tree に格納します。このB-tree は、キーの探索において対数的な時間計算量を実現します。データのサブセットに対してB-Tree を使用することで、同一パーティションキーを持つアイテムの高効率な範囲クエリーを可能にしています。
特化したAPI によるデータ構造への直接アクセス
パーティショニングもB-Tree も興味深いものですが、しかしDynamoDB に特有のものではほとんどありません。全てのNoSQL データベースは水平スケールのために何かの形態でパーティショニングを採用していますし、世にある全てのデータベースはB-Tree(もしくはその近縁種)を索引操作に使用しています。
DynamoDB とその他のデータベースとでの大きな違いは、DynamoDB ではいかにネイティブにデータ構造が剥き出しにされているかという点です。ディスクの異なる場所からデータを読込み、結合し、集計を行うための複数ステップの処理にクエリを構文解析するクエリプランナーはありません。核となるパーティショニングとB-Tree の設定の外には柔軟なインデックス戦略もありません。
DynamoDB はアイテム(項目)と項目の基礎的なデータ構造に直接アクセスすることに焦点を当てたAPI を持っています。このAPI はふたつの主要な分類にわかれます。個々の項目の基本的なCRUD 操作―PutItem、GetItem、UpdateItem そしてDeleteItem―があります。これらの操作は完全なプライマリキーを要求し、ハッシュテーブルにおける単純な探索に等しいと考えることができます。
DynamoDB API のふたつめのカテゴリは、単体のリクエストで複数の項目を取得することができるfetch many 操作 ー クエリ(Query) オペレーションを包含します。これは、特定の顧客情報の注文情報をすべて取得したり、あるIoTセンサーの直近の測定値を取得したりするのに利用できます。
しかし、Query オペレーションであっても制限され、パーティションキーは完全一致しなければならず、それによりリクエストを処理して応答を返すために単一のパーティションに転送されます。これにより、パーティションキーをベースにした高速なターゲティングとB-Treeの素早い検索と容易なシーケンシャル読込を組み合わせ、規模に応じた効率の良い範囲検索を実現します。
これはDynamoDB API によって提供されるものではないことに留意してください。リレーショナルデータベースのように複数のテーブルを統合するJOIN 操作は行えません。また、膨大なレコードを集約するためにcount、sum、min もしくはmax のような集計もできません。これらの操作は、不透明で、クエリに関わるレコード数に強く依存し、それは予め知ることができません。あらゆる規模で堅実なパフォーマンスを実現するため、DynamoDB は結合や集計といった著しい変動性を加える高レベルの構成概念を排除しています。
読み取りバイトと書き込みバイトに基づいた明朗会計
前節において、DynamoDB がキーとなるデータ構造に基づいて構築され、それを直接さらけ出すことでパフォーマンスをわかりやすくしていることを確認しました。こうすることで、不透明なクエリプランナーを使うデータベースの不思議な点や予測不可能性を取り除いています。
DynamoDB はコストについても同様にしています。データをディスクに書き込むと費用が発生します。データをディスクから読み戻すと費用が発生します。そしてこれらのコストの双方は読み書きするデータのサイズで増加します。DynamoDB は、テーブルへの読み書きバイト数に直接よって課金することで、これらの根本的なコストを判読しやすくしています。
DynamoDB の課金は書き込みキャパシティユニット (WCU)と読み取りキャパシティユニット(RCU) に基づいています。ざっと説明すると、1 WCU で1KB データを書き込むことができるのに対し、1 RCU で4KB のデータを読み取ることができます。読み取りおよび書き込みキャパシティは予めプロビジョニングすることができ、あるいは、発生する各読み取りまたは書き込みリクエストに対し支払うオンデマンド課金を使うこともできます。
私はこの透明性が大好きです。DynamoDB を使って働く人々にいつも話すのは“計算すればわかる(Do the math)“ということです。どのくらいのトラフィックがありそうか大まかな見積りがあれば、発生する費用を自身で計算することができます。あるいは、データをモデル化するふたつのアプローチについてどちらかに決めようとしているのであれば、より安価なほうを計算で知ることができます。この後の節では、この透過的な課金モデルがデータモデリングにおいてシングルテーブル設計の原則を使用するひとつの理由であることを見ていきましょう。
シングルテーブル設計を使用する理由とタイミング
DynamoDBの基本が分かったところで、アプリケーションにシングルテーブル設計を使用する理由を見てみましょう。
まず始めに、シングルテーブル設計の推奨事項は単一のサービスに対して適用される事に注意してください。アプリケーションに複数のサービスがある場合、サービス毎に独自のDynamoDB テーブルを用意する必要があります。DynamoDB テーブルは、RDBMSのインスタンスと同様に考えてください。つまり、独立したRDBMSインスタンスがある場合、DynamoDB テーブルも分けるべきです。
更にエンティティを1つのテーブルにまとめる場合の経験則を挙げるとすれば「まとめてアクセスされる項目はまとめて保存する」と言う事です。RDBMSで頻繁に結合する2つのテーブルにデータを保存している場合、DynamoDBでは1つの非正規化されたテーブルとしてデータを格納するよう検討して下さい。そうでない場合、通常は必要に応じて分離しても問題ありません。
DynamoDBでシングルテーブル設計を使用する機能上の理由は3つあり、非機能的な利点も1つあります。それでは詳細を見ていきましょう。
DynamoDB内でアイテムの統合を行う為にシングルテーブル設計を利用する
背景のセクションでは、DynamoDB には専用のAPI があり、JOIN などの一般的な SQL 操作が削除されていることがわかりました。
しかしJOINは便利です!1対多、または多対多の関係にある場合、1つのアイテムを取得する為に関連する親アイテムに関する情報も必要になる、というアクセスパターンがあるかもしれません。
DynamoDB を使い始めたとき、リレーショナルデータベースに似たマルチテーブル設計を使用していました。DynamoDB では結合を提供していない為、アプリケーションコードに結合を実装しただけです。例えば、特定のアクセスパターンで顧客情報 (Customer) と注文情報 (Order) の両方を取得したいとします。そのためには、まず顧客レコードを取得し、その主キーを取得してから、関連する注文情報を外部キー関係で取得します。

図3:マルチテーブル設計からの情報取得
しかしこれは、このユースケースを処理するには非効率です。アプリケーションから DynamoDB への I/O は、アプリケーションの処理の中で最も遅い部分です。前の図 3 に示すように、別々のシーケンシャルクエリを発行して実行しています。
これがアプリケーションの一般的なアクセスパターンになる事がわかっている場合、DynamoDB のコアデータ構造と API を利用して最適化できます。個別に順次リクエストするのではなく、関連項目を事前に結合しておく事であらかじめアイテムを統合することができます。Customer 項目に関連する Order 項目と同じパーティションキーを付与すると、それらは同じパーティションに配置され、ソートキーに従って順序付けられます。そして、次の図 4 に示すように、Query オペレーションを使用して 1 回のリクエストですべての項目を効率的に取得できます。

図4:シングルテーブル設計からの情報取得
これは、シングルテーブル設計を使用する場合の標準的な例です。DynamoDB に期待する一貫したパフォーマンスを維持しながら、異なる性質のアイテムを含むアクセスパターンを処理できます。
大きいアイテムにアクセスするコストを削減する為にシングルテーブル設計を利用する
2 つ目の理由は、DynamoDB のコストを削減するためです。
多くの NoSQL システムでは、関連するネストされたデータを含む、より大きい非正規化ドキュメントを作成することが推奨されています。これは、関連データをまとめて取得することが多く、データを別々のレコードにまとめるよりも 1 つのレコードとしてまとめる方が効率的であるためです。
この戦略は良いアドバイスですが、やりすぎないように注意してください。DynamoDB では、読み取りと書き込みのコストがアイテムのサイズに応じて増加することを覚えておいてください。
通常、大きなアイテムには 2 つの異なる属性セットがあります。1 つは変更頻度の低い属性、もう1つは変更頻度の高い属性が組み合わされたものです。例えば、YouTube の動画を表すアイテムを考えてみてください。利用可能なさまざまな解像度や場所、動画の説明、字幕、情報カードなど、動画自体に関する多くのデータがあります。これは大量の情報であり、ほとんど変更されません。
ただし、YouTube の動画には視聴回数を表示するカウンターもあります。これはほんの数ビットの小さな属性ですが、1 日に何千回も増加する可能性があります。このカウンターをビデオメタデータと同じ項目に保存した場合、視聴回数が増えるたびに複数の WCU にお金を払うことになります。このパターンは、以下の図5に示されています。
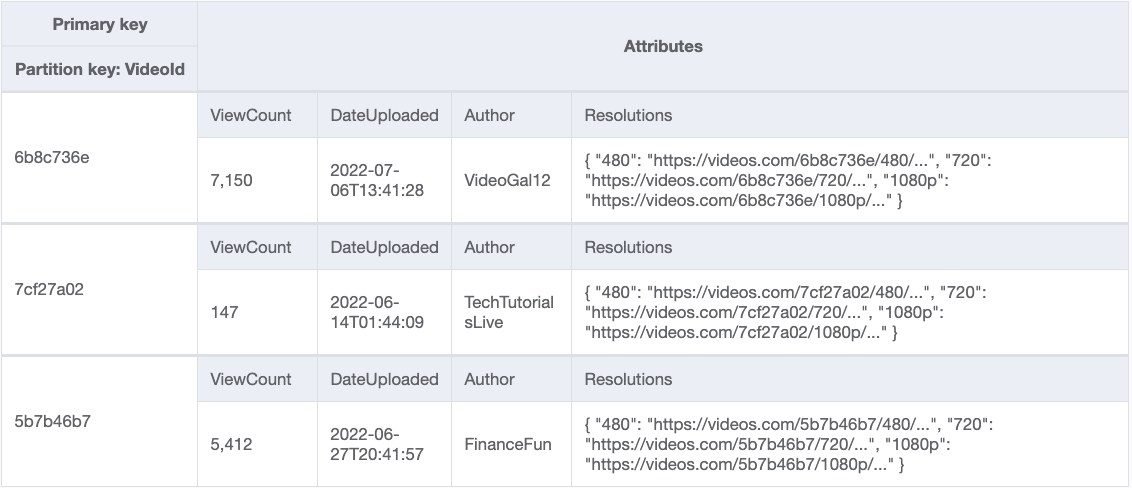
図5:ビデオメタデータの一部としてViewCount 属性をインクリメントする
代わりに、このアイテムを Video と VideoStats の 2 つに分割します。視聴回数を記録する時は、小さな VideoStatsアイテムをインクリメントするだけで済みます。ビデオを表示するときは、以下の図 6 に示すようにQuery オペレーションを使用し、両方のアイテムを取得できます。
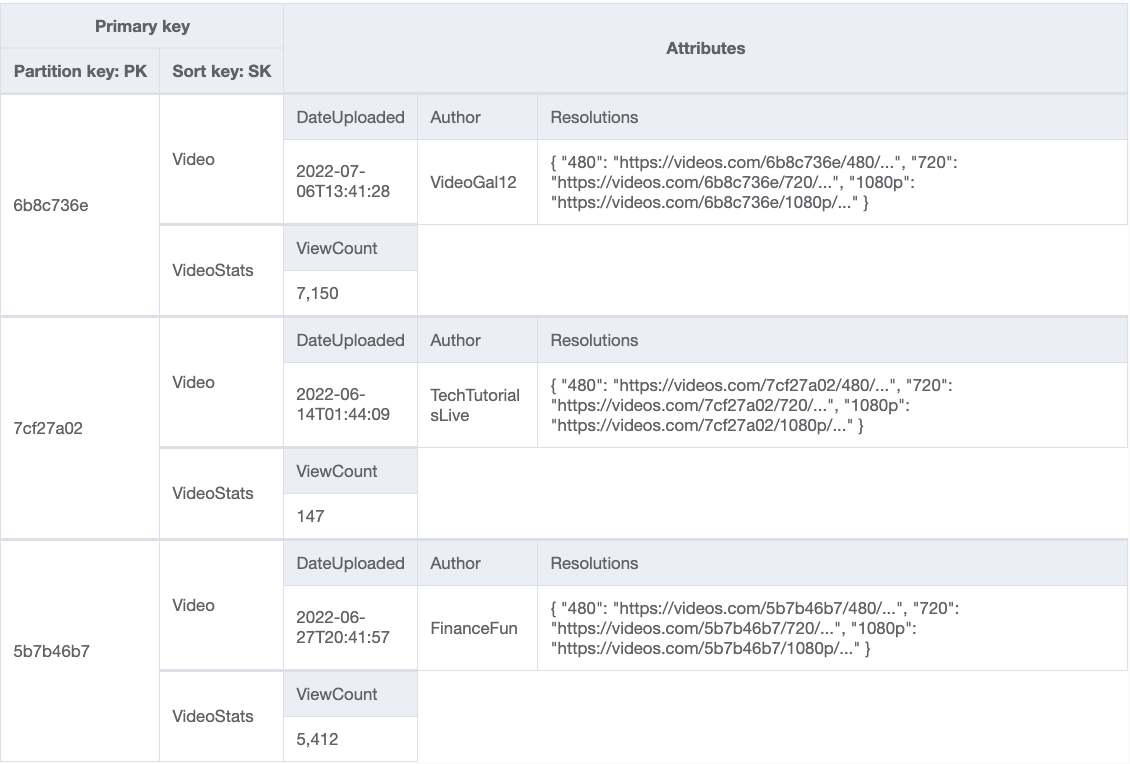
図 6: ビデオメタデータとは別に ViewCount 属性をインクリメントする
このパターンでは、DynamoDB のコスト透過性とスキーマレス性を利用し、アプリケーションのニーズに合わせて最適化できます。
オペレーション負担を軽減する為にシングルテーブル設計を利用する
3 つ目の理由は、オペレーション負担を軽減するためです。ここでの計算は簡単です。持っているものが少ないほど、監視しなければならない項目は少なくなります。ここでのロジックは、特に AWS が DynamoDB に加えた改善を考えると、少し複雑です。
よく議論になるポイントから始めましょう。DynamoDB テーブルにはリレーショナルデータベースのテーブルと共通点がいくつかありますが、相違点もいくつかあります。最も重要なのは、DynamoDB はテーブル単位で個別のインフラストラクチャであるということです。そのインフラストラクチャには、設定、監視、アラーム、およびバックアップが必要です。アプリケーションに 15 の異なるエンティティ、つまり 15 種類の DynamoDB テーブルがある場合、それらが負担になる可能性があります。
論理的には、データを1つのテーブルにまとめることで、オペレーション負担が軽減されます。監視する必要があるのは、15 テーブルではなく 1 つのテーブルだけです。さらに、AWS リージョン内のテーブル数と同時に実行されるコントロールプレーンのオペレーション数にはAWS 上の制限があります。アカウントが大きい場合や、顧客ごとにテーブルを分割している場合は、これらの上限に達する可能性があります。
複数のエンティティに対して単一のテーブルを使用すると、テーブル全体のパフォーマンスを向上させることもできます。DynamoDB はパーティションレベルでバーストキャパシティを提供しているため、ベストエフォートベースでプロビジョニングされたスループットを短期間超えることが可能です。テーブルが大きいと、アイテムがより多くのパーティションに分散されるため、スロットリング範囲が狭くなります。
最後に、少数のアクセスパターンがアプリケーションの読み取り/書き込みキャパシティを支配しているのはよくあることです。エンティティを単一のテーブルにまとめることで、あまり使用されないアクセスパターンがコアパターンの余剰容量に溶け込む可能性があります。
とはいえ私の考察では、この議論は小さな要因だと思います。DynamoDB テーブルのメンテナンスはかなり軽く、ほとんどの場合、AWS CloudFormation やその他のコードとしてのインフラストラクチャツールを使用して自動化できます。自動スケーリングを設定したり、アラームを設定したり、自動化された方法でポイントインタイムリカバリによるバックアップを有効にしたりできます。
さらに、DynamoDB では多くの改善が行われています。2018 年に DynamoDB はアダプティブキャパシティを発表しました。これにより、プロビジョンドキャパシティはテーブル全体で最も必要なパーティションに分散されます。その後、2019 年に DynamoDB はオンデマンドモードを発表しました。キャパシティの管理が面倒な場合は、オンデマンドモードに切り替えて、必要なリソース分のみを支払うことができます。
おまけ:DynamoDB について正しく考える必要がある
人々が DynamoDB を学び、使いこなせるよう手助けするのが好きな私にとって、最後の理由は (勝手に) 特定のアプリケーションやオペレーション利点ではなく、学習プロセスについてです。この議論は次のようになります。DynamoDB でシングルテーブル設計に重点を置くことは、リレーショナルデータベースで行ったモデリングとは異なるというメッセージを明確にするのに役立ちます。
非常に多くの新しい DynamoDB ユーザーは、リレーショナルデータモデルをDynamoDB テーブルにリフトアンドシフトしています。次に、メモリ内で結合と集約を行うことで、アプリケーションに不適切なバージョンのクエリプロセッサを書き込みます。このアプローチでは、DynamoDB で実現できるスケーラビリティや予測可能性が得られないアプリケーションの動作が遅くなります。
ほとんどのサービスで単一のテーブルを使用できることを伝えると、DynamoDB テーブルはリレーショナルデータベーステーブルと直接比較できないことがわかります。もう少し深く掘り下げてみると、データを抽象化して正規化するのではなく、まずアクセスパターンに焦点を当てる必要があることに気づき、NoSQLデータストアをモデル化してパフォーマンスを最適化するための主要な戦略を学びます。
同様にDynamoDB を学ぶことでより良い開発者になれると思います。DynamoDBは基礎を公開しているので、以前使用していた抽象化の中には無料ではないものもあることがわかります。リレーショナルデータベースに戻っても、パフォーマンスプロファイルはインデックスフィールドで 1 つのレコードを選択することと同じではないことがわかっているので、結合や集計などの機能に注目する必要があります。
複数テーブルをDynamoDB で使う理由
前節では、DynamoDBでのシングルテーブル設計を支持するにあたって、核となる主張を見てきました。しかしながら、1テーブルと複数テーブルとからの選択には微妙なものがあり、複数テーブルが賢い選択肢となるかもしれない状況があります。そのいくつかを探っていきましょう。
DynamoDB Streams に対して複数の要求がある
Amazon DynamoDB Streams はDynamoDBで私が好きな機能の一つです。DynamoDB テーブルに対する全ての書き込み操作の記録を含んだ完全にマネージドな変更データキャプチャ を取得することができます。そして、サーバーレスコンピューティングで変更ストリームを集計を更新したり、システム間でイベントを共有したり、分析システムに入力したりできます。
DynamoDB Streams の欠点の一つは、同時コンシューマ数に制限があることです。DynamoDB はDynamoDB Streams 上での同時コンシューマ数を2つまでに制限しています。追加のコンシューマがいると、ストリームを処理する要求はスロットルされます。
10もしくはそれ以上のエンティティによるシングルテーブル設計ではこの制限を超過することは珍しくありません。おそらく、新しいOrder項目は、そのOrderを処理するためのAWS Step Functions ワークフローをトリガーすることを必要とし、新規 Customer の登録には、他のサービスに Amazon EventBridge を通じてブロードキャストする必要があります。単一のストリームコンシューマにもっとロジックを追加するか、注文のセマンティクスを維持しながらイベントのファンアウトを実現するように Amazon Simple Notification Service (Amazon SNS) をつかったFIFO 型のSNSトピックもしくは Amazon Simple Queue Service (Amazon SQS) キューにつなげるか、などのいくつかの難しいトレードオフを行う必要があります。
この場合には、シングルテーブルを複数の特化したテーブルに分割するほうが容易です。各テーブルはより少数のエンティティを持ち、DynamoDB のストリームパイプラインがワークロード毎にさらに特化することができます。
分析向けにより簡単にエクスポートしたい
DynamoDB は、各々のレコードで膨大な数の同時更新を行うために設計されたオンライントランザクション処理 (OLTP) システムです。よくあるユーザー向けのインタラクションを考えてみてください – 注文を行ったり、ディスカッションスレッドにコメントしたりする。DynamoDB はこれらのワークロードに秀でており、ひとつのリクエストにおいて不可分操作、低遅延、そして少数のレコードについてのACID トランザクションを許可します。
逆に、DynamoDB はオンライン分析処理(OLAP) 作業には向いていません。これらの内部的な分析作業 – カテゴリや地域ごとの前週比売上を知りたいビジネスアナリストやこの1年で最も人気の出たソーシャルメディア投稿を見つけたいマーケティングチームのことを考えてください。これらの作業は高いスループットや低遅延を要求しませんが、膨大な量のデータを効率よくスキャンし計算を行うことを必要とします。これらのOLAP要求に対しては、多くのDynamoDB ユーザが、大規模集計を目的として構築された Amazon Athena や Amazon Redshift のような外部の分析システムにデータをエクスポートします。しかしながら、データをDynamoDB から分析システムへ取得する仕組みはデータの詳細によって異なります。
上述したDynamoDB Streams の機能を使ってレコードを分析システムに流すこともあります。大概は、Amazon Redshift にデータをロードする前に Amazon Kinesis Data Firehose を使って Amazon Simple Storage Service (Amazon S3) にデータをバッファするか、もしくはAthea でクエリされるようにシンプルに Firehose を使ってS3 にデータを送ります。このパターンは、テーブルの完全なエクスポートが非現実的でなほど大きく、変化しないデータセットに対してよく機能し、データが変化しない性質はOLAP型システムとうまく働きます。
しかしながら、より小さく変更されるデータセットもあり、異なったニーズがあります。アプリケーションのユーザーやカスタマーエンティティを考えてみてください。これらのエンティティはデータウェアハウスにおいて重要で、他のさらに大きいイベント然としたテーブルと結合して、イベントに色を付けます。これらのエンティティは変化するので、データウェアハウスのデータは現行バージョンに定期的にアップデートされることが望まれています。データウェアハウスはランダムアップデートは得意ではなく、そのため通常は、更新されたテーブルを完全にエクスポートしシステムにロードするほうがよいです。これには通常 Redshift COPY コマンド か S3へのDynamoDBエクスポート操作 が使われます。
シングルのDynamoDB テーブル内に両方のタイプのデータが存在している場合、分析系のニーズに応えることはとても難しくなります。完全なテーブルのエクスポート処理は、より小さな変更可能なデータセットと一緒により大きな変更されないデータセットの全てをエクスポートするため遅くなります。異なるデータを異なるテーブルに分割することで、分析パイプラインを特定の形やニーズに対してカスタマイズすることができます。
恩恵が必要ないのであれば話は簡単
複数テーブルを使う最後の理由は、多くの場合シングルテーブル設計のそれとは単純に逆の場合です。
上述のシングルテーブル設計の利点が重要でないのであれば ― ひとつのリクエストで異なる性質を含む項目を取得できるようにアイテムを統合しようとしておらず、アイテムを複数の断片に分解しようともしていなくて、運用負荷に脅かされたりすることもないのであれば―マルチテーブル設計のほうが容易であればシングルテーブル設計は省略してよいでしょう。
DynamoDB における結合のためのモデリングについて前述した最初の利点をもう少しだけ詳しく見ていきましょう。アプリケーション内での結合やDynamoDB に対し複数の連続するリクエストが必要になる正規化されたモデルを避けようとすることは絶対に正しいことです。しかしそれは、アイテムを統合したシングルテーブル設計をしなければならないということを必ずしも意味しません。順番にではなく並列にデータの両方のセットを取得するようにテーブルを構成することで、ほぼ同様の利点を享受することが来ます。
DynamoDB に順番にリクエストを行う必要があった前述の例に戻って考えましょう―ひとつはeメールアドレスによって顧客情報(Customer) レコードを取得し、もうひとつは割り当てられた顧客ID (CustomerID)によって注文情報(Order)を取得します。シングルテーブル設計モデルに切り替える場合は、どちらのエンティティにもCustomerEmailAddress をパーティションキーとすることで、ひとつのクエリ操作でそれらのデータを取得できます。
このモデリングの切替えにはふたつの異なるテーブルを必要としません。注文情報テーブルがCustomerEmailAddress をパーティションキーとして使用しているのであれば、Customer レコードを取得しているのと同時にOrder レコードを取得することができます。
これは、ふたつのリクエストのうち遅い方の戻りを待つことになるので、シングルリクエストを行うよりも僅かながら遅くなります。そして、RCUの計算時にクエリ操作をまとめる利点が得られないので、ごくわずかながら支払いが多くなります。しかしながら、シングルテーブル設計の場合でも、クライアントが最初のページを超えてデータを取得してくるためにページネーションを行ったり、どのみち似たような何かを実装する必要があるというのは、よくありそうなことです。これらのトレードオフがあなたやアプリケーションにとって受け入れられるのであれば、マルチテーブル設計を選ぶことができます。
これはDynamoDB がどのように動いているかを学習することを回避するための口実にはならないことに注意してください! DynamoDB をリレーショナルデータベースのようにモデリングするべきではありませんし、DynamoDB データモデリングの原則は学習されるべきです。この数年で携わってきたほぼすべてのモデルにおいて、アクセスパターンに優先して取り組みそれらのアクセスパターンを扱えるようにプライマリキーを設計することで、必要とあらばふたつの分かたれたテーブルをひとつのテーブルにまとめることができるでしょう。
おわりに
今回は、DynamoDBを使ったシングルテーブルの設計について学びました。まず、シングルテーブルの議論に重要なDynamoDBの関連する背景を説明しました。次に、DynamoDBでシングルテーブル設計を使用するいくつかの理由を説明しました。また、複数のテーブルを使用する際のいくつかの理由についても説明しました。
最後に、お勧めの学習方法についてお伝えします。まず最初に、DynamoDBを使ったモデリングの原則を最初に理解することをお勧めします。DynamoDBはリレーショナルデータベースのような使い方をするべきではありません。学習曲線がやや険しく感じるかもしれませんが、学ぶべき重要な概念は3つか4つだけで、他のすべての考え方はそこから派生します。これらの基本を理解すれば、アプリケーションで使用するテーブルの数について、より多くの情報に基づいた決定を下すことができるようになります。
DynamoDBのデータモデリングについて理解したいのであれば、たくさんの素晴らしいリソースがあります。私はDynamoDBのデータモデリングに関する基礎的な概念と実際に適用できる例などを通して体系的に学ぶことができるガイド「The DynamoDB Book」を書きました。また、DynamoDBについて正しく開発できる方法を説明するために、DynamoDBチームが書き上げた、「Amazon DynamoDB デベロッパーガイド」も確認することを強くお勧めします。ぜひ、怖がらずに飛び込んで試してみてください。DynamoDBコミュニティはフレンドリーで成長中のコミュニティであり、その過程で多くのサポートを得られるはずです。
このブログ記事を書くにあたり、Joseph Idziorek、Jeff Duffy、Amrith Kumarから意見やコメントをいただいたことに感謝します。
著者について

Alex DeBrie はAWS ヒーローであり、DynamoDB を使ったデータモデリングの包括的なガイドであるThe DynamoDB Book の著者です。独立コンサルタントとして、DynamoDB データモデリングとサーバレスなAWS アーキテクチャ実装によりあらゆる規模の企業を支援しています。プライベートではスポーツを愛し、妻と4人の子どもと過ごす時間を大切にしています。Twitter のフォローはコチラ。
この記事の翻訳は Tatsuya Kimura, Koki Ishikawa, Kenta Nagasueが担当しました