Amazon Web Services ブログ
AWS Glue カスタムブループリントを使ってデータ統合パイプライン開発を簡単にする
本記事はAmazon Web Services, big data architect である Noritaka Sekiyama 、 software development engineer である Keerthi Chadalavada および Global Business Development Manager である Shiv Narayanan によって投稿されたものです。
多くの組織は、データウェアハウス、データレイクおよびレイクハウスのデータ統合パイプライン開発や維持に膨大な時間を費やしています。データエンジニアリングチームは、データ量の増加にしたがって、ビジネスチームからの新たな要求への対応に苦労するようになります。それらの要求の多くは、様々なチームから来るものですが、互いに類似しています。例えば、ソースシステムからデータレイクへの生データの取り込み、特定のキーによるデータのパーティショニング、データレイクからリレーショナルデータベースへのデータの書き込み、欠損値に対してのデフォルト値の割当などです。これらの要求に対応するため、データエンジニアは、開発環境でパイプラインを変更し、テストし、本番環境へデプロイすることになります。この冗長なプロセスは、エラーを生み出しやすく、時間がかかる原因になっています。
データエンジニアは、パイプライン開発の複雑さを抽象化することによって、ビジネスアナリスト、データアナリスト、データサイエンティストのような非データエンジニアにもセルフサービス方式によって運用できるようにする手法を必要としています。この記事では、再利用可能な AWS Glue ワークフローを構築・共有するためのフレームワークである、 AWS Glue カスタムブループリントをご紹介します。
AWS Glue カスタムブループリントの紹介
AWS Glue は、データエンジニアが複雑なデータ統合パイプラインを開発するためのサーバーレスデータ統合サービスです。AWS Glue ワークフローを活用することで、複数のクローラ、ジョブおよびトリガーを含む複雑な抽出・変換・ロード(Extract, Transform and Load – ETL)処理の作成と可視化ができます。
AWS Glue カスタムブループリントを使うことにより、データエンジニアは複雑な変換と技術的な詳細部分を抽象化するブループリントを作成することができます。非データエンジニアは、データエンジニアが個別に新しいパイプラインを作成してくれるまで待つことなく、データエンジニアが用意したカスタムブループリントを利用することで、ユーザーインターフェース上で簡単に、抽出・変換・ロードの処理を実行することができます。これらのユーザーは、自身の組織外で開発されたブループリントを利用することもできます。例えば、 AWS がデータ変換のために開発したサンプルブループリントがありますので、こちらをご利用いただけます。
以下の図は、 AWS Glue カスタムブループリントを使ったアーキテクチャを示しています。

ワークフローには、以下のステップが含まれています。
- データエンジニアは一般的なデータ統合パターンを認識して、ブループリントを作成する。
- データエンジニアはソース管理ツールや Amazon Simple Storage Service (Amazon S3) 経由でブループリントを共有する。
- 非データエンジニアは入力を提供するユーザーインターフェース上で、ブループリントを簡単に登録および利用できる。
- ブループリントはこれらのパラメータを利用して、AWS Glue ワークフローを生成する。これらワークフローを実行するだけで、データの抽出・変換処理ができる。
カスタムブループリントの開発
データレイクによって統合されたデータは、一般に、何らかの方法でパーティショニングされます。データアナリスト、ビジネスアナリスト、データサイエンティストおよびデータエンジニアによって、クエリパターンに基づいて異なるパーティショニングの方法が必要になることもあるでしょう。例えば、データサイエンティストは、タイムスタンプでデータをパーティショニングしたいのに対して、データアナリストは、ロケーションに基づいてデータをパーティショニングしたい場合などです。次に、ジョブをブループリントとしてパッケージングして、パラメータを共有し、 AWS Glue ワークフローを作成する他のユーザーに共有します。ここでは、このようなユースケースに対するブループリントを作成します。
カスタムブループリントを作成するには、データエンジニアは 3 つのコンポーネントを作成する必要があります。構成ファイル、レイアウトファイル、 AWS Glue ジョブスクリプトとレイアウトファイルにおいて指定されたリソースの作成に必要な追加のライブラリです。

AWS Glue ジョブスクリプト は、データ変換用のスクリプトです。この例では、データエンジニアが partitioning.py というジョブスクリプトを作成します。このスクリプトは、ソース S3 の場所、パーティションキー、パーティションテーブル名およびターゲット S3 の場所などのパラメータを受け付けます。このジョブは、ソース S3 の場所にあるデータを読み込み、ターゲット S3 へパーティショニングされたデータを書き込み、AWS Glue Data Catalog においてパーティションテーブルをカタログ化します。
構成ファイル は、JSONベースのファイルです。データエンジニアが、ワークフローの作成に必要な入力リストを定義します。この例では、データエンジニアが blueprint.cfg を作成します。入力データの場所、パーティションテーブル名、出力データの場所など、必要な全ての入力に関するファイルです。 AWS Glue ユーザーは、このファイルを使って、ワークフロー作成に必要な値のためのユーザーインターフェースを構成します。次の図は、構成ファイルのパラメータが、ユーザーインターフェースにどのように反映されたかを示しています。

レイアウトファイル は、 Python のファイルです。ユーザーによる入力を使って以下を作成します。
- ETL スクリプトを保存したり、中間データの保存場所として使われる Data Catalog データベースや S3 の場所などの前提条件オブジェクト
- AWS Glue ワークフロー
この例では、開発者が layout.py ファイルを作成します。ユーザーから提供されたパラメータに基づくワークフローを作成するためのファイルです。レイアウトファイルには、以下の機能を実行するコードが含まれています。
- ユーザーから提供された入力に基づく AWS Glue データベースの作成
- AWS Glue スクリプト用 S3 バケットの作成と、
partitioning.pyのアップロード - 処理用の一時的な S3 の場所の作成
- 最初にクローラを実行し、次にジョブを実行するワークフローの作成
- 入力パラメータに基づいたワークフロースケジュールの設定
カスタムブループリントのパッケージング
ブループリント作成後、zip ファイルとしてパッケージ化する必要があります。このファイルを利用して、ブループリントを登録することができます。次のファイルを含めなければなりません。
- 構成ファイル
- レイアウトファイル
- AWS Glue ジョブスクリプトと必要な追加ライブラリ
選択したソール管理リポジトリもしくはファイルストレージを使って、他のユーザーとブループリントを共有することが可能です。
ブループリントの登録
AWS Glue コンソール上で、ブループリントを登録するには、以下のステップを実施します。
- zip ファイルを Amazon S3 へアップロード
- AWS Glue コンソールにて、 Blueprints を選択
- 設計図を追加 を選択
- 下記の情報を入力
- 設計図名
- ZIP アーカイブの場所 (S3)
- 説明 (任意)
- 設計図を追加 を選択
ブループリントの登録が成功すると、ステータスが ACTIVE になります。

AWS Glue ワークフローを作成するためのブループリントを使う準備ができました。
ブループリントを使う
始めての方向けのブループリントが提供されています。それらのブループリントを使うためには、前のセクションで説明したように、ブループリントをダウンロードした後、 zip ファイルを作成して、 AWS Glue に登録する必要があります。
| カスタムブループリント名 | 説明 |
| Crawl S3 locations | S3 の場所をクローリングし、 AWS Glue Data Catalog にテーブルを作成します |
| Convert data format to Parquet | S3 に置かれている様々な形式のファイルを Snappy 圧縮方式の Parquet 形式に変換します |
| Partition Data | ユーザー入力に基づいてファイルをパーティショニングし、 Amazon S3 におけるデータレイアウトを最適化します |
| Copy data to DynamoDB | Amazon S3 から Amazon DynamoDB へデータをコピーします |
| Compaction | (大量な小さなサイズの)ファイルを、(少量な)より大きなサイズのファイルへ圧縮し、クエリのパフォーマンスを向上させます |
| Encoding | S3 に置かれているファイルのエンコーディングを変換します |
本記事では、データアナリストが Partition Data ブループリントを簡単に使う方法を示します。データをパーティショニングすると、クエリのパフォーマンスが向上します。日付、国、地域などの列の値に応じてそれぞれのディレクトリにデータが保存されるためです。この手法は、パーティションでフィルターが設定されているときに、クエリによってスキャンされるデータ量を制限するのに役立ちます。タイムスタンプや他の属性によって、異なる方法でデータをパーティショニングしたくなる場合もあるでしょう。パーティショニングのブループリントによって、データアナリストはデータエンジニアリングに関する深い知識がなくても、簡単にデータをパーティショニングできます。
本記事では、 AWS COVID-19 データレイク で利用可能な Daily Global & U.S. COVID-19 Cases & Testing Data (Enigma Aggregation) データセットをソースデータとして使います。このデータには、国によって整理された COVID-19 に関連する米国および全世界の症例、死亡例、検査データが含まれています。

データセットは、 2 つの JSON ファイルを含み、この記事の執筆時点では、合計データサイズが 215.7 MB になっています。このデータは、クエリにおいて最高のパフォーマンスを得るためのパーティショニングや最適化は実施されていません。この種の履歴データには、 WHERE 句で日付範囲条件を指定してクエリするのが一般的です。データのスキャンサイズやパフォーマンスの最適化を実現するために、日付フィールドにてデータをパーティショニングします。
ネストされたパーティショニングもしくはフラットなパーティショニングにより、データセットをパーティショニングできます。
- フラットなパーティショニング –
path_to_data/dt=20200918/ - ネストされたパーティショニング –
path_to_data/year=2020/month=9/day=18/
この例において、入力データには 日付 (date) のフィールドが含まれており、2020-09-18 (YYYY-MM-DD) 形式になっています。フラットなパーティショニングでは、日付のフィールドをパーティションキーとして指定するだけです。しかし、ネストパーティショニングをするためには少し手の込んだ実装をする必要があります。エンジニアであれば日付フィールドから年、月、日を抜き出せますが、非エンジニアが、この実装をするのは難しいでしょう。このブループリントでは、このような複雑さを抽象化し、日時のフィールドから任意の粒度で(年、月、日などの)ネストされたフィールドを作成することができます。
このブループリントを使うためには、以下のステップを実施します。
- 次のコードを使って、 GitHub からファイルをダウンロードします。
- ブループリントのファイルを zip 圧縮します。
- zip ファイルを S3 バケットへアップロードします。
- AWS Glue のコンソールにて、 Blueprints を選択します。
- 設計図を追加 を選択します。
- 設計図名 に、
partitioning-tutorialと入力します。 - ZIPアーカイブの場所 (S3) に、
s3://path/to/blueprint/partitioning.zipと入力します。 - ブループリントのステータスが
ACTIVEになるまで待ちます。 partitional-tutorialブループリントを選択し、アクション メニューから、ワークフローを作成 を選択します。- 下記のパラメータを入力します。
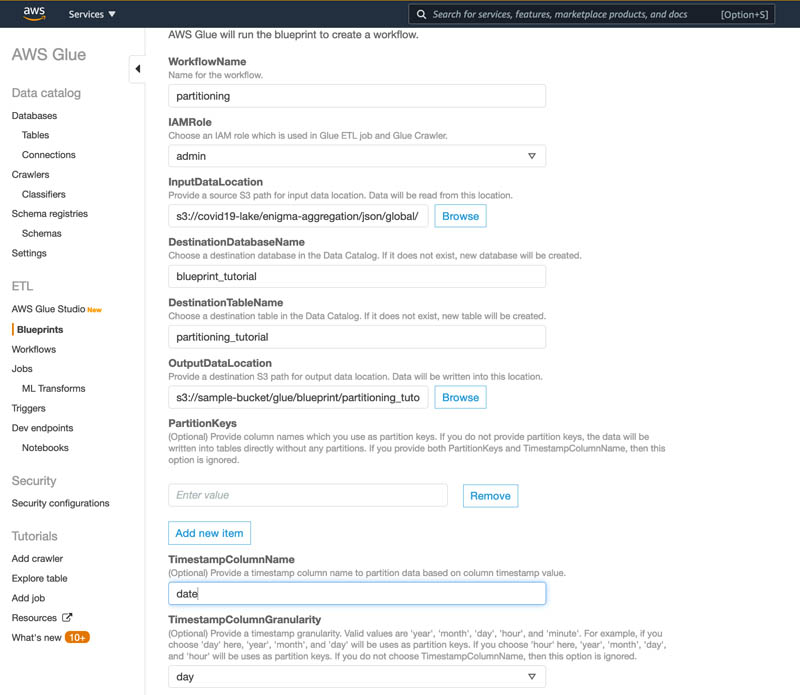
- WorkflowName –
partitioning - IAMRole – AWS Glue ジョブとクローラを実行するための AWS Identity and Access Management (IAM) ロール
- InputDataLocation –
s3://covid19-lake/enigma-aggregation/json/global/ - DestinationDatabaseName –
blueprint_tutorial - DestinationTableName –
partitioning_tutorial - OutputDataLocation –
s3://path/to/output/data/location/ - PartitionKeys: (blank)
- TimestampColumnName –
date - TimestampColumnGranularity –
day - NumberOfWorkers –
5(the default value) - IAM role – AWS Glue にて、ワークフロー、クローラ、ジョブ、トリガとレイアウトスクリプトで定義された他のリソースを作成を引き受けるロール。ロールの推奨ポリシーは、ブループリントロールのアクセス許可を参照してください。
- WorkflowName –
- 送信 を選択します。
- ブループリントの実行状態が
SUCCEEDEDになるまで待ちます。

- ナビゲーションペインにある ワークフロー を選択します。
partitioningを選択肢、アクション メニューから、実行 を選択します。- ワークフローの実行状態が
Completedになるまで待ちます。

Amazon S3 コンソール上で出力ファイルに移動します。 Parquet 形式のファイルが year=yyyy/month=MM/day=dd/ のパーティションフォルダの中に正しく書き込まれたことを確認できます。

ブループリントは2つのテーブルを登録します。
- source_partitioning_tutorial – AWS Glue クローラによって生成されたパーティショニングされていないデータソースのテーブル
- partitioning_tutorial – AWS Glue Data Catalog の新しいパーティショニングされたテーブル
両テーブルともに Amazon Athena によってアクセスすることが可能です。両テーブルのデータスキャンサイズを比較してみましょう。パーティショニングの利点が確認できます。
最初に、パーティショニングされていないソーステーブルに対して、次のクエリを実行します。
次のスクリーンショットは、クエリ結果を示しています。

次に、パーティショニングされたテーブルに対して同じクエリを実行します。
次のスクリーンショットは、クエリの結果を示しています。

パーティショニングされていないテーブルは、 215.67 MB のデータをスキャンしています。一方で、パーティショニングされたテーブルでは、 126.42 KB です。 1700 分の 1 になっています。この結果から、パーティショニングは Athena のコスト削減にもつながることが理解できます。
結論
本記事では、データエンジニアが AWS Glue カスタムブループリントを使って、データ統合パイプラインを簡素化する方法と再利用性を高める方法を示しました。データサイエンティスト、ビジネスアナリストおよびデータアナリストのような非データエンジニアでも、詳細な技術の前提知識なしで、リッチな UI により抽出・変換処理が可能になります。サンプルのテンプレートにより、 AWS Glue カスタムブループリントを使ってみることが可能です。ぜひ AWS Glue コミュニティにて公開し、誰でも利用できるようにすることもご検討ください。
原文はこちらです。