Amazon Web Services ブログ
新しいクエリエディタを使用して Amazon Redshift クラスターをクエリする
データウェアハウスは、データから実用的な洞察を分析および抽出するための重要なコンポーネントです。Amazon Redshift は、高速でスケーラブルなデータウェアハウスであり、データウェアハウスとデータレイク全体ですべてのデータを分析するのに費用対効果が高くなります。
Amazon Redshift コンソールは最近、クエリエディタを開始しました。クエリエディタは、AWS マネジメントコンソールから直接 Amazon Redshift クラスターで SQL クエリを実行するためのブラウザ内インターフェイスです。Amazon Redshift クラスターでホストされているデータベースでクエリを実行するには、クエリエディタを使用するのが最も効率的な方法です。
クラスターを作成したら、すぐにクエリエディタを使用して Amazon Redshift コンソールでクエリを実行できます。クエリエディタは外部の JDBC/ODBC クライアントを使用してデータベースに接続するのに代わる優れた方法です。
この記事では、クラスターにデータをロードし、コンソールからクラスターのパフォーマンスを直接モニターするための SQL クエリを実行する方法を説明します。
SQL IDE やツールの代わりにクエリエディタを使用する
クエリエディタは、Amazon Redshift クラスターで SQL クエリを実行するためのブラウザ内インターフェイスを提供します。計算ノードで実行されるクエリの場合は、クエリの横にクエリ結果とクエリ実行プランを表示できます。
クエリを可視化し、便利なユーザーインターフェイスを実現する機能により、データベース管理者としてもデータベース開発者としても、さまざまなタスクを実行できます。視覚的なクエリエディタを使用すると、次のことができます。
- 複雑なクエリを作成すること
- クエリを編集して実行すること
- データを作成して編集すること
- 結果を表示してエクスポートすること
- クエリに EXPLAIN プランを作成すること
クエリエディタを使用すると、複数の SQL タブを同時に開くこともできます。色付きの構文、クエリのオートコンプリート、およびシングルステップのクエリフォーマットはすべて、追加のボーナスです。
データベース管理者は通常、よく使用する SQL ステートメントのリポジトリを定期的に管理しています。これをメモ帳のどこかに書き記せば、保存したクエリ機能を存分に活かせるでしょう。この機能を使用すると、よく実行する SQL ステートメントを一度に保存して再利用できます。これにより、以前に実行した SQL ステートメントを確認、再実行、および変更することが効率的になります。クエリエディタにはエクスポーターもあり、クエリ結果を CSV 形式にエクスポートできます。
クエリエディタを使用すると、クラスター上にスキーマやテーブルを作成する、テーブルにデータをロードするなどの一般的なタスクを実行できます。これらの一般的なタスクは、コンソール上で直接実行するいくつかの単純な SQL ステートメントを使用して可能になりました。コンソールから日々の管理タスクを行うこともできます。これらのタスクには、クラスター上で長時間実行されているクエリを見つけること、クラスター上で長時間実行されている更新で潜在的なデッドロックをチェックすること、およびクラスターで使用可能な容量を確認することなどがあります。
クエリエディタは 16 の AWS リージョンで利用できます。追加料金なしで Amazon Redshift コンソールで利用できます。標準の Amazon Redshift 料金が、クラスターの使用量と Amazon Redshift Spectrum に適用されます。詳細については、「Amazon Redshift の料金」を参照してください。
クエリエディタを始めましょう
以下のセクションでは、コンソールから直接クエリエディタを使用して、Amazon S3 バケットのサンプルデータセットを使って Amazon Redshift クラスターをセットアップする手順を説明します。新規ユーザーにとっては、これは JDBC/ODBC クライアントをセットアップしてクラスターへの接続を確立するのに特に便利な代替手段です。すでにクラスターがある場合は、これらの手順を完了させるのに 10 分とかかりません。
次の例では、クエリエディタを使用してこれらのタスクを実行します。
- サンプルデータセットをクラスターにロードします。
- サンプルデータセットに対して SQL クエリを実行し、結果と実行の詳細を表示します。
- システムテーブルに対して管理クエリを実行し、頻繁に使用するクエリを保存します。
- SQL クエリを実行して、内部テーブルと外部テーブルを結合します。
クエリにクラスターをセットアップするには、以下の手順に従います。
- Amazon Redshift コンソールでクラスターを作成します。詳細な手順については、「 Amazon Redshift 入門ガイド」の「Amazon Redshift クラスターのサンプルを起動する」で説明されている手順を参照してください。現在サポートされているノードタイプ dc1.8xlarge、dc2.large、dc2.8xlarge、ds2.8xlarge のいずれかを使用します。この記事では、Amazon Redshift ダッシュボードの [クラスターのクイック起動] ボタンを使用して、us-east-1 リージョンに demo-cluster という単一ノードの dc2.large クラスターを作成しました。チュートリアルを進めながら、このクラスター名を、起動したクラスター名、および起動したリージョンに置き換えます。

- AWS アカウントにクエリエディタ関連の権限を追加します。コンソールでクエリエディタ機能にアクセスするには、権限が必要です。詳細な手順については、「Amazon Redshift クラスターマネジメントガイド」の「クエリエディタへのアクセスの有効化」を参照してください。
- サンプルデータセットに対してクエリをロードして実行するには (S3 からデータをロードする権限、または AWS Glue もしくは Amazon Athena データカタログを使用する権限を含む)、次の手順に従います。COPY コマンドを使用して Amazon S3 からサンプルデータをロードするには、代わりに Amazon S3 にアクセスするためのクラスターの認証を提供する必要があります。この手順のサンプルデータは、Amazon Redshift が所有する Amazon S3 バケットで提供されています。バケットのアクセス許可は、すべての認証済み AWS ユーザーがサンプルデータファイルへの読み取りアクセスを許可するように設定されています。この手順を実行するには、次の手順を実行します。
• AmazonS3ReadOnlyAccess ポリシーを IAM ロールにアタッチします。AmazonS3ReadOnlyAccess ポリシーは、すべての Amazon S3 バケットへの読み取り専用アクセスをクラスターに付与します。
• AWS Glue Data Catalog を使用している場合は、AWSGlueConsoleFullAccess ポリシーを IAM ロールにアタッチします。Athena Data Catalog を使用している場合は、AmazonAthenaFullAccess ポリシーを IAM ロールにアタッチします。
b.例のステップ 2 では、COPY コマンドを実行してサンプルデータをロードします。COPY コマンドには、IAM ロールの Amazon リソースネーム (ARN) のプレースホルダーが含まれています。サンプルデータをロードするには、COPY にロール ARN を追加します。以下は COPY コマンドのサンプルです。
これらの手順を完了すると、Amazon Redshift クラスターの準備が整います。次のセクションでは、クエリエディタでできることを説明する 3 つの手順について説明します。
- データをロードするためにクエリエディタを使用します。
- いくつかの日常的な管理タスクを実行します。
- Amazon Redshift クラスターと Amazon S3 データレイクに格納されているデータに対してクエリを実行します。ロードやその他のデータの準備は必要ありません。
ステップ 1: クエリエディタでクラスターに接続する
クラスターに接続するには、
- Amazon Redshift コンソールの左側のナビゲーションペインを使用して、クエリエディタに移動します。
- [認証情報] ダイアログボックスの [クラスター] ドロップダウンリストで、クラスター名 (demo-cluster) を選択します。このクラスターのデータベースとデータベースユーザーを選択します。
- サービスで提供されるデフォルト値を使用してクラスターを作成した場合は、データベースとして [dev] を選択し、データベースユーザーボックスで awsuser と入力します。
- クラスターのパスワードを入力します。通常、Amazon Redshift データベースユーザーは、データベースユーザー名とパスワードを入力してログオンします。別の方法として、パスワードを覚えていない場合は、次の例に示すように [一時パスワードの作成] を選択して暗号化形式で取得できます。詳細については、「IAM 認証を使用したデータベースユーザー認証情報の生成」を参照してください。

AWS アカウントにクエリエディタ関連の権限がある場合、これによりクラスターに接続します。詳細については、前のセクションの AWS アカウントにクエリエディタ関連の権限を追加する手順を参照してください。
ステップ 2: サンプルデータセットを使用してクラスターを準備する
サンプルデータセットを使用してクラスターを準備するには、
- クエリエディタで次の SQL を実行します。これにより、Amazon Redshift クラスターの demo-cluster にスキーマ myinternalsalschema が作成されます。

- クエリエディタで次の SQL ステートメントを実行して、スキーマ myinternalschema のテーブルを作成します。
- 次の SQL ステートメントを COPY コマンドを使用して実行し、サンプルデータセットを Amazon S3 から us-east-1 の Amazon Redshift クラスターである demo-cluster にコピーします。サンプルデータセットの Amazon S3 パスは s3://aws-redshift-spectrum-sample-data-us-east-1/spectrum/event/allevents_pipe.txt です。
[クエリの実行] を選択する前に、この AWS アカウントに関連付けられている IAM ロールの ARNで、例の中のプレースホルダーを必ず置き換えてください。クラスターが別の AWS リージョンにある場合は、次の SQL コマンドに示すように、region パラメータの Region と Amazon S3 パスを置き換えます。
- Amazon S3 でパブリックデータセットに確実にアクセスするには、この AWS アカウントに、Amazon S3、AWS Glue、およびAthena にアクセスするための正しい権限があることを確認してください。詳細については、この記事の前半にあるサンプルデータセット (Amazon S3 および AWS Glue/Amazon Athena Data Catalog の権限) でクエリをロードして実行するための手順を参照してください。
- クエリエディタで以前に作成したテーブルのデータを確認するには、左側のスキーマビューアでテーブルを参照します。イベントテーブルの最初の 10 レコードを表示するには、テーブル名の横にあるプレビューアイコンを選択します。このオプションを選択すると、テーブルのプレビューに対して次のクエリが実行され、テーブルの 10 行が表示されます。
独自の SQL ステートメントを入力することもできます。クエリエディタでクエリをオートコンプリートして、作成したテーブル内のデータを確認するには、Ctrl + Space を使用します。
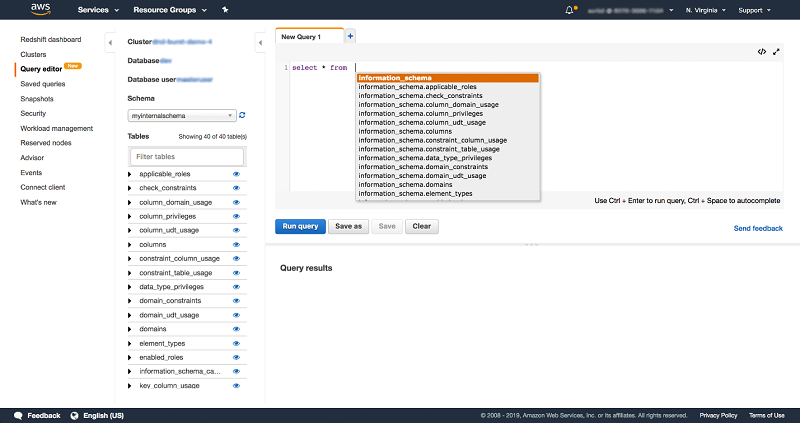
ステップ 3: 便利なクラスター管理クエリ
Amazon Redshift を試す準備ができました。 日々のクラスターの管理と監視では、クエリエディタで次の SQL クエリを実行できます。これらの頻繁に使うクエリを使用すると、長時間実行されているクエリを見つけてシャットダウンし、デッドロック状況を発見し、Amazon Redshift クラスターで使用可能なディスク容量を確認できます。次の例に示すように、コンソールの左側のナビゲーションで [保存されたクエリ] を選択することで、これらのクエリを保存して簡単にアクセスできるようにします。

クラスター上で誤動作しているクエリや長時間実行されているクエリを強制終了する
誤動作しているクエリがあってシャットダウンしなければならない場合、そのクエリを見つけるには複数の手順を踏まなければならないことがよくあります。SQL ステートメントを使用して Amazon Redshift クラスターで実行されているすべてのクエリを見つけるには、クエリエディタで次の SQL を実行します。
クエリ結果セットから誤動作しているクエリを見つけた後、cancel <pid> <msg> コマンドを使用してクエリを強制終了します。クエリ ID ではなく、必ずプロセス ID (前の SQL の pid) を使用してください。クエリの発行者に返されてログに記録されるオプションのメッセージを提供できます。
クラスターで使用されているディスク容量を監視する
最も頻繁に使用されるコンソール機能の 1 つは、クラスターが使用しているディスク容量の割合を監視することです。クエリの実行中に使用する一時テーブルを作成するためのクラスター内のスペースが限られていると、クエリは失敗します。クラスターの復元プロセスで中間データを格納するための空き容量がクラスターにない場合も、バキュームは失敗する可能性があります。このメトリクスを監視することは、クラスターが満杯になる前にプランを立てる上で重要です。また、クラスターのサイズを変更したりクラスターを追加したりする必要があります。
Amazon Redshift でディスクの使用率が高いまたはフルになっていると思われる場合は、クエリエディタで次の SQL を実行して使用可能なディスク領域を見つけ、クラスターの個々のテーブルサイズを確認します。
ここから、不要なテーブルを削除するか、クラスターのサイズを変更して容量を増やすことができます。詳細については、「Amazon Redshift でのクラスターのサイズ変更」を参照してください。
クラスター上で疑わしいほど長時間実行されている更新があるデッドロック状況を監視する
クラスターに疑わしいほど長時間実行されている更新がある場合、デッドロックトランザクションになっている可能性があります。stv_locks テーブルは、関連するセッションのプロセス ID とともに、ロックがあるトランザクションをすべて示します。この pid を pg_terminate_backend (pid) に渡して問題のセッションを強制終了させることができます。
クエリエディタで SQL ステートメントを実行して、ロックを調べます。
セッションをシャットダウンするには、stl_locks の値を使って select pg_terminate_backend (lock_owner_pid) を実行します。
クラスターの最新のバキュームの影響を受ける行を確認する
クラスター内のテーブルに対して vacuum コマンドを実行することで、削除および更新操作による空き領域が回収されます。同時に、テーブルのデータがソートされます。その結果、コンパクトでソートされたテーブルが作成され、クラスターのパフォーマンスが向上します。
次の SQL ステートメントを実行して、svv_vacuum_summary テーブルの最新のバキュームから削除または復元された行数を確認します。
Amazon Redshift クラスターの接続の問題をデバッグする
stv_sessions テーブルと stl_connection_log テーブルを結合すると、すべてのセッション (クラスター上のすべての接続、認証、および切断セッション) とそれぞれのリモートホストおよびポート情報のリストが返されます。
すべての接続を一覧表示するには、クエリエディタで次の SQL ステートメントを実行します。
保存されたクエリ機能を使用して、これらのよく使用される SQL ステートメントをアカウントに保存し、ワンクリックでクエリエディタで実行します。
ボーナスステップ 4: Amazon Redshift Spectrum を使ってクエリする
Amazon Redshift Spectrum を使用すると、最初に Amazon Redshift にロードする必要なしに、Amazon S3 内のデータをクエリできます。Amazon Redshift Spectrum クエリは、大規模な並列処理を採用して、そのデータを Amazon Redshift に取り込むことなく、S3 で大規模なデータセットを迅速に処理します。処理の大部分は Amazon Redshift Spectrum レイヤーで行われます。複数のクラスターは、各クラスターのデータのコピーを作成しなくても、Amazon S3 の同じデータセットを同時にクエリできます。
Amazon Redshift Spectrum でセットアップするには、demo-clusterに対してクエリエディタで次の SQL ステートメントを実行します。クラスターが別の AWS リージョンにある場合は、次の SQL ステートメントで region パラメータの Region と Amazon S3 パスを必ず置き換えてください。
Amazon Redshift Spectrum で使用するためにデータカタログから新しいスキーマを作成するには、以下の手順を実行します。
Amazon Redshift Spectrum S3 サンプルデータセット用のテーブルを作成するには、以下の手順を実行します。
クエリを始めましょう!
このセクションでは、外部 (Amazon S3) の sales テーブルと内部 (Amazon Redshift) の event テーブルからデータのクエリを開始するシナリオの例を示します。このシナリオの join クエリは、支払った販売価格が 50 を超える (デモクラスターにロードされた販売データセットの) すべてのイベントを (Amazon S3 の Amazon Redshift Spectrum データセット s3://aws-redshift-spectrum-sample-data-us-east-1/spectrum/sales/ から) 探します。
[クエリ結果] セクションで [実行の表示] を選択して、詳細な実行プランを確認します。クエリプランは、計算ノードで実行されたすべてのクエリに使用できます。
注 : カタログテーブルのみを使用する管理クエリなど、ユーザーテーブルを参照しないクエリには、利用できるクエリプランがありません。
オプションで、オフラインで使用するためにクエリ結果をローカルディスクにダウンロードします。クエリはクエリエディタで最大 3 分間実行されます。クエリが完了した後、クエリエディタは結果を取得するために 2 分を指定します。クエリを再実行し、2 分のしきい値に達した場合はもう一度やり直します。

次の SQL ステートメントを使用して Amazon Redshift サンプルデータセットから追加のテーブルをロードし、クリエイティブなクエリを実行します。クエリエディタで [クエリの実行] を選択する前に、次の SQL ステートメントのプレースホルダーにこの AWS アカウントに関連付けられている IAM ロールの ARN を追加します。クラスターが別の AWS リージョンにある場合は、次の SQL ステートメントで region パラメータの Region と Amazon S3 パスを置き換えてください。
まとめ
この記事では、Amazon Redshift クラスターで SQL クエリを実行するためのブラウザ内インターフェイスであるクエリエディタを紹介しました。これを使用して、クラスターにデータをロードし、クラスターのパフォーマンスを直接コンソールで監視するための SQL クエリを実行する方法を示しました。Amazon Redshift について詳しく知り、クエリエディタの使用を開始するには、Amazon Redshift のウェブページにアクセスしてください。
この機能が気に入った場合は、次のように、コンソールの [フィードバックの送信] リンクを使用してフィードバックを共有してください。

ご不明な点がございましたら、下記へコメントをお寄せください。
クエリをお楽しみください!
著者について
 Surbhi Dangi は、アマゾン ウェブ サービスのプロダクトマネージャーです。
Surbhi Dangi は、アマゾン ウェブ サービスのプロダクトマネージャーです。
 Raja Bhogi は、アマゾン ウェブ サービスのソフトウェア開発エンジニアです。
Raja Bhogi は、アマゾン ウェブ サービスのソフトウェア開発エンジニアです。