Amazon Web Services ブログ
Amazon Redshift 用の AWS Step Functions を使用した ETL プロセスのオーケストレーション
現在のデータレイクは、大量の情報を使用可能なデータに変換する抽出、変換、ロード (ETL) 操作をベースとしています。この記事では、AWS Step Functions、AWS Lambda、AWS Batch を緩やかに結合して Amazon Redshift クラスターをターゲットにする ETLオーケストレーションプロセスの実装について詳しく説明します。
Amazon Redshift はカラムナストレージを使用するため、便利な ANSI SQL クエリを使用した迅速な分析的インサイトに最適です。Amazon Redshift クラスターを数分ですばやく増減して、エンドユーザーレポートとデータウェアハウスへのタイムリーなデータ更新の両方の厳しいワークロードに対応することができます。
AWS Step Functions を使用すると、拡張性に優れた繰り返し可能なワークフローを簡単に開発および使用できます。Step Functions によって、個々の Lambda 関数から自動化ワークフローを構築できます。各関数は個別のタスクを実行し、ワークフローのコンポーネントを迅速かつシームレスに開発、テスト、変更することを可能にします。
ETL プロセスは、データウェアハウスをソースシステムから更新し、未加工データをより簡単に使用できる形式に編成します。大半の組織は、ETL をバッチとして、またはリアルタイムの取り込みプロセスの一部として実行し、データウェアハウスを最新の状態に保ち、タイムリーな分析を提供します。完全に自動化されたスケーラビリティの高い ETL プロセスにより、通常の ETL パイプラインの管理に投入する必要がある運用上の労力を最小限に抑えることができます。また、データウェアハウスのタイムリーで正確な更新も保証されます。このプロセスをカスタマイズして、データを任意のデータウェアハウスまたはデータレイクに更新することができます。
また、この記事では、TPC-DS データセットを更新するためにワンクリックでサンプル ETL プロセス全体を開始する AWS CloudFormation テンプレートも提供しています。テンプレートへのリンクは、AWS CloudFormation を使用してワークフロー全体を設定するセクションにあります。
アーキテクチャの概要
次の図は、ETL ワークフローのオーケストレーションに関連するさまざまなコンポーネントのアーキテクチャの概要を示しています。このワークフローは Step Functions を使用して Amazon S3 からソースデータを取得し、Amazon Redshift データウェアハウスを更新します。

ワークフローのコアコンポーネントは以下のとおりです。
- Amazon CloudWatch は、スケジュールに基づいて、AWS CLI を通じて、または Lambda 関数でさまざまな AWS SDK を使用して ETL プロセスをトリガーします。
- ETL ワークフローは、マルチステップ ETL プロセスに Step Functions を使用し、AWS のサービスをサーバーレスワークフローで管理します。JSON ベースのテンプレートを使用してこれらを構築し、簡単に繰り返すことができます。たとえば、一般的な ETL プロセスでは、最初にディメンションを更新し、後でファクトテーブルを更新します。Step Functions 状態マシンを使用して、操作の順序を宣言できます。
- Lambda 関数を使用すると、ワークフローロジック、並列処理、エラー処理、タイムアウト、または再試行のコードを記述する必要なく、ジョブの送信と監視を調整するためのマイクロサービスを構築できます。
- AWS Batch は、Amazon Redshift への変換やロードなど、いくつかの ETL ジョブを実行します。AWS Batch は、ユーザーのためにインフラストラクチャのすべてを管理し、バッチコンピューティングジョブのプロビジョニング、管理、監視、拡張の複雑さを回避します。また、ジョブが完了するのを待つこともできます。
- Amazon S3 のソースデータは、PL/SQL コンテナを介して Amazon Redshift データウェアハウスを更新します。ETL ロジックを指定するには、特定のステップの SQL コードを含む .sql ファイルを使用します。たとえば、一般的なディメンションテーブル更新用の .sql ファイルには、Amazon S3 から一時ステージングテーブルにデータをロードし、ターゲットテーブルを INSERT/UPDATE する手順が含まれています。始める前に、サンプルのディメンションテーブルの .sql ファイルを確認してください。
ワークフローを実行し、状態マシンを使用して監視することができます。スケジュールまたはイベントに従って (たとえば、すべてのデータファイルが S3 に到着したらすぐに) ETL をトリガーすることができます。
前提条件
始める前に、.sql ファイルを実行できる Docker イメージを作成してください。AWS Batch は、この Docker イメージを使用して ETL ステップを実行するためのリソースを作成します。Docker イメージを作成するには、以下が必要です。
初めて AWS Batch を使用する場合は、AWS Batch の概要を参照してください。Docker イメージを構築して登録するための環境を作成します。この記事では、このイメージを Amazon ECR リポジトリに登録します。これはデフォルトでプライベートリポジトリであり、AWS Batch ジョブに役立ちます。
フェッチおよび実行の psql Docker イメージの構築
Docker イメージを構築するには、単純な「フェッチおよび実行」の AWS Batch ジョブの作成の記事で説明されている手順に従います。
以下の Docker 設定を使用し、psqlスクリプトをフェッチして実行しイメージを構築します。
記事の手順に従って Docker イメージを ECR コンテナレジストリにインポートします。前の手順を完了すると、Docker イメージは Amazon Redshift クラスターの .sql 実行をトリガーする準備が整っています。
例: TPC-DS データセットを使用した ETL プロセス
この例は、TPC-DS データセットのサブセットを使用して、一般的なディメンションモデルの更新を説明します。以下は、この ETL アプリケーションに使用する TPC-DS データモデルのエンティティ関係図です。

ETL プロセスは、Store_Sales ファクトテーブルのテーブルデータを、特定のデータセット日付の Customer_Address および Item ディメンションと共に更新します。
Step Functions を使用して ETL ワークフローを設定する
Step Functions は、複雑なワークフローをより簡単にします。JSON ベースのテンプレートを使用して、依存関係管理と障害処理を設定できます。ワークフローは一連の手順にすぎず、ある手順の出力が次の手順への入力として機能します。
この例では、Fact テーブルのロードをトリガーする前に、さまざまなディメンションテーブルの変換およびロードを完了しています。また、ワークフローは必要に応じて複数の並列ステップに分岐できます。実行の各段階を監視することができます。つまり、問題を迅速に識別して修正できることになります。
次の図は、Step Functions によって設定された ETL プロセスの例を概説しています。

詳しくは、詳細なワークフロー図を参照してください。
上記のワークフローでは、ETL プロセスはステップ 1 で DB 接続をチェックし、Customer_Address (ステップ 2.1) と Item_dimension (ステップ 2.2) のステップをトリガーします。これらは並行して実行されます。Store_Sales (ステップ 3) FACT テーブルは、プロセスがディメンションテーブルを完了するのを待ちます。それぞれの ETL ステップは自律的であるため、どの段階でも障害を監視して対応できます。
ここで、Store_Sales ステップ (ステップ 3) を詳しく調べます。他のステップも同様の実装パターンになります。
Store_Sales ステップ (ステップ 3) の状態実装は次のとおりです。
すべてのディメンションテーブルをロードする Parallel プロセスは、Next 属性を使用して、後の Store Sales Fact 変換/ロード SalesFACTInit に依存関係を設定します。SalesFACTInit ステップは、AWS Lambda ジョブ JobStatusPol-SubmitJobFunction を介してトリガーされた、SubmitStoreSalesFACTJob を使用した AWS Batch への変換をトリガーします。GetStoreSalesFACTJobStatus は、完了を確認するために AWS Lambda JobStatusPoll-CheckJobFunction を通じて 30 秒ごとにポーリングします。CheckStoreSalesFACTJobStatus はステータスを検証し、返されたステータスに応じてプロセスを成功させるか失敗させるかを決定します。
以下は、ステップ 3 の状態マシンジョブを実行するための入力のスニペットです。
入力は、各ステップがどのファイルを呼び出すかを、更新日とともに定義します。複雑なworkflow ワークフローを JSON ワークフローとして表現できるため、管理が簡単になります。これはまた、各ステップで呼び出す入力を切り離します。
ETL ワークフローの実行
AWS Batchは、特定の日の売上データの増分データ更新を使用して、状態マシンが呼び出す各 .sql スクリプト (store_sales.sql) を実行します。
以下は、store_sales.sql のロードと変換の実装です。
この ETL 実装は、以下の手順で実行されます。
- COPY コマンドは、S3 から一括してステージングテーブル
stg_store_salesにデータを高速ロードします。 - 「Begin…end」トランザクションは、変換およびロードプロセスの複数のステップをカプセル化します。これにより、最終的にコミット操作が少なくなり、プロセスが安価になります。
- ETL の実装は冪等です。失敗した場合は、クリーンアップせずにジョブを再試行できます。たとえば、毎回
stg_store_salesを再作成してから、毎回特定の更新日付のデータを含むターゲットテーブルstore_salesを削除します。
前の実装で使用したベストプラクティスについては、Amazon Redshift を使用した高性能 ETL 処理のためのトップ 8 ベストプラクティスの記事を参照してください。
さらに、Customer_Address は Type 1 の実装を示し、Item は一般的なディメンションモデルでは Type 2 の実装に従います。
AWS CloudFormation を使用してワークフロー全体を設定する
AWS CloudFormation テンプレートには、このソリューションのすべての手順が含まれています。このテンプレートは必要なすべての AWS リソースを作成し、特定の日の初期データ設定とこのデータの更新を呼び出します。以下は、CloudFormation スタック内に作成するすべてのリソースのリストです。
- VPC と関連するサブネット、セキュリティグループ、およびルート
- IAM ロール
- Amazon Redshift クラスター
- AWS Batch のジョブ定義とコンピューティング環境
- AWS Batch ジョブを送信およびポーリングする Lambda 関数
- ETL ワークフローを統合し、Amazon Redshift クラスターのデータを更新する Step Functions 状態マシン
以下は、VPC での Amazon Redshift 設定と Step Functions を使用して統合された ETL プロセスを示す、この設定のアーキテクチャです。
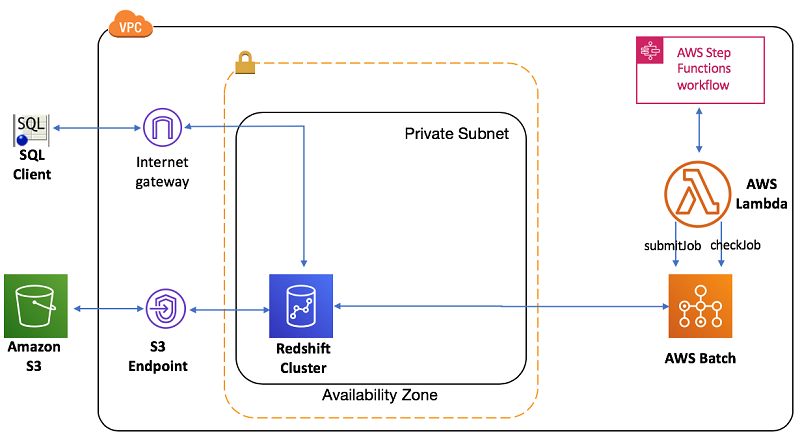
ステップ 1: AWS CloudFormation を使用してスタックを作成する
このアプリケーションを AWS アカウントにデプロイするには、まずこの CloudFormation スタックを起動します。
![]()
- このスタックは、パスワード「Password#123」を使用します。できるだけ早く変更してください。最低 8 文字、少なくとも 1 つの大文字、1 つの小文字、1 つの数字、および 1 つの特殊文字を使用してください。
- 他のパラメータはデフォルト値を使用します。
このスタックが起動するのに約 10 分かかります。完了して、ステータスが「CREATE_COMPLETE」に変わるのを待ちます。
スタックの [Output] セクションにある [ExecutionInput] の値を書き留めます。JSON は、次のコード例のようになります。
スタックの [Resources] セクションにある [JobDefinition] および [JobQueue] の物理 ID を書き留めます。
ステップ 2: Amazon Redshift で TPC-DS 1-GB の初期データを設定する
以下の手順で、TPCDS データの最初の 1 GB を Amazon Redshift クラスターにロードします。
- AWS Batch コンソールで、[Job] を選択し、前述のジョブキューを選択して、[Submit Job] を選択します。
- 新しいジョブ名 (例えば、TPCDSdataload) を設定し、前に書き留めた JobDefinition の値を選択します。[Submit Job] を選択します。ジョブが、TPCDS データの最初の 1 GB を完全に Amazon Redshift クラスターにロードするのを待ちます。
- AWS Batch ダッシュボードで TPCDS データロードの完了を監視します。これは、完了までに約 10 分かかります。
ステップ 3: Step Functions で ETL ワークフローを実行する
ETL プロセスは、TPCDS ディメンションモデルを 2010-10-10 のデータで更新するマルチステップワークフローです。
- Step Functions コンソールで、「JobStatusPollerStateMachine-*」を選択します。
- [Start execution] を選択して、オプションの実行名 (ETLWorkflowDataRefreshfor2003-01-02 など) を指定します。実行の入力に、前に書き留めた ExecutionInput の値を入力します。これにより、ETL プロセスが開始されます。状態マシンは、Lambda ポーラーを使用して ETL ジョブの各ステップを送信および監視します。各入力は、ETL ワークフローを呼び出します。ブラウザを更新することで ETL のプロセスを監視できます。
ステップ 4: Amazon Redshift クラスターで ETL データの更新を確認する
Amazon Redshift コンソールで、[Query Editor] を選択します。以下の認証情報を入力してください。
- データベース: dev。
- データベースユーザー: awsuser。
- パスワード: これには、ステップ 1 で作成したパスワード (デフォルトの「Password#123」) が必要です。
パブリックスキーマにログインしたら、以下のクエリを実行して 2010-10-10 のデータロードを確認します。
クエリは、ETL プロセスがロードした 2010-10-10 の TPC-DS データセットを表示するはずです。
ステップ 5: クリーンアップ
このソリューションのテストが終了したら、AWS CloudFormation を使用して作成したすべての AWS リソースをクリーンアップするのを忘れないでください。AWS CloudFormation コンソールまたは AWS CLI を使用して、前に指定したスタックを削除します。
結論
この記事では、AWS で分離サービスを使用して ETL ワークフローを実装する方法と、Amazon Redshift クラスターにデータを更新できるようにする非常にスケーラブルなオーケストレーションを設定する方法について説明しました。
ここで学んだことは簡単に拡張できます。このソリューションを拡張して他の分析サービスに対応させたり、本場稼働の準備が整うのに十分な堅牢性を持たせたりするためのオプションをいくつか示します。
- この例では、Step Functions を使用して状態マシンを手動で呼び出します。代わりに、新しいファイルがソースバケットに到着したときなど、CloudWatch イベントまたは S3 イベントを使用して自動的に状態マシンをトリガーすることができます。また、スケジュールを使用して ETL の呼び出しを進めることもできます。ETL ワークフローを自動化するための有用な情報については、サーバーレスワークフローをスケジュールするを参照してください。
- 失敗した場合にアラートメカニズムを追加することもできます。これを行うには、Step Functions ワークフローの各ステップのステータスに基づいて E メールを送信する Lambda 関数を作成します。
- 状態マシンの各ステップは自律しており、Lambda 関数を使って任意のサービスを呼び出すことができます。任意の分析サービスをワークフローに統合できます。たとえば、Amazon Redshift を使用してデータを変換する前に、AWS Glue を呼び出してデータの一部を消去する独立した Lambda 関数を作成できます。この場合、ディメンションをロードする前の手順で AWS Glue ジョブを依存関係として追加します。
この Step Functions ベースのワークフローでは、あらゆる分析サービスを使用して ETL オーケストレーションのさまざまなステップを切り離すことができます。このため、このソリューションはさまざまなアプリケーションに適応し、交換可能です。
ご不明な点がございましたら、下記へコメントをお寄せください。
著者について
 Thiyagarajan Arumugam はアマゾン ウェブ サービスのビッグデータソリューションアーキテクトで、大規模なデータを処理するためのカスタマーアーキテクチャを設計しています。AWS の前は、Amazon.com でデータウェアハウスソリューションを構築していました。余暇には、野外スポーツを楽しみ、インドの伝統的な太鼓であるムリダンガムを練習しています。
Thiyagarajan Arumugam はアマゾン ウェブ サービスのビッグデータソリューションアーキテクトで、大規模なデータを処理するためのカスタマーアーキテクチャを設計しています。AWS の前は、Amazon.com でデータウェアハウスソリューションを構築していました。余暇には、野外スポーツを楽しみ、インドの伝統的な太鼓であるムリダンガムを練習しています。