Amazon QuickSight はハイパースケールの統合ビジネスインテリジェンス ( BI ) でデータ主導型組織を強化します。QuickSight を使用すると、すべてのユーザーが同じ情報源を共有し、インタラクティブダッシュボード、ページ分割レポート、埋め込み分析、自然言語クエリを通じて、さまざまな分析ニーズに対応できます。
データセットパラメータは、ダッシュボードでインタラクティブな体験を作成するのに役立つ、QuickSight の新しい種類のパラメータです。この投稿では、データセットパラメータとは何かを深く掘り下げ、データセットパラメータと分析パラメータの主な違いを説明し、データセットパラメータのさまざまな使用例とその利点について説明します。
データセットパラメータの概要
データセットパラメータについて詳しく説明する前に、まず QuickSight 分析パラメータについて説明しましょう。 QuickSight 分析パラメータは、アクションやオブジェクト間で値を連携できる名前付きの変数です。パラメータは、インタラクティブなダッシュボードを構築するのに役立ちます。QuickSight 分析では、パラメータを他の機能と関連付けることができます。例えば、ダッシュボードユーザーは、コントロール、フィルター、アクションを使用して複数の場所でパラメータ値を参照できます。また、計算フィールド、説明文、動的タイトル内でも参照できます。関連付けを行うと、ダッシュボード内の各ビジュアルは、ユーザーによるパラメータ値の選択に応じて動作します。パラメータは、あるダッシュボードを別のダッシュボードと接続するのにも役立ち、ダッシュボードユーザーは別の分析に含まれるデータにドリルダウンすることができます。
一方、データセットパラメータ はデータセットに対して定義する変数です。データセットパラメータを使用すると、作成者は、 SQL を介して外部のデータソースとリアルタイム接続されているダッシュボードの操作性や読み込み時間を最適化できます。閲覧者がデータを操作すると、コントロール、フィルター、ビジュアルでの選択やアクションの内容が、カスタム SQLに埋め込まれたパラメータとしてリアルタイムにデータソースへ伝播されます。複数のデータセットパラメータを分析パラメータに紐づけることで、ユーザーはコントロール、ユーザーアクション、パラメータ化された URL、計算フィールドのほか、動的なビジュアルのタイトルやインサイトを使用して、さまざまな体験を構築できます。
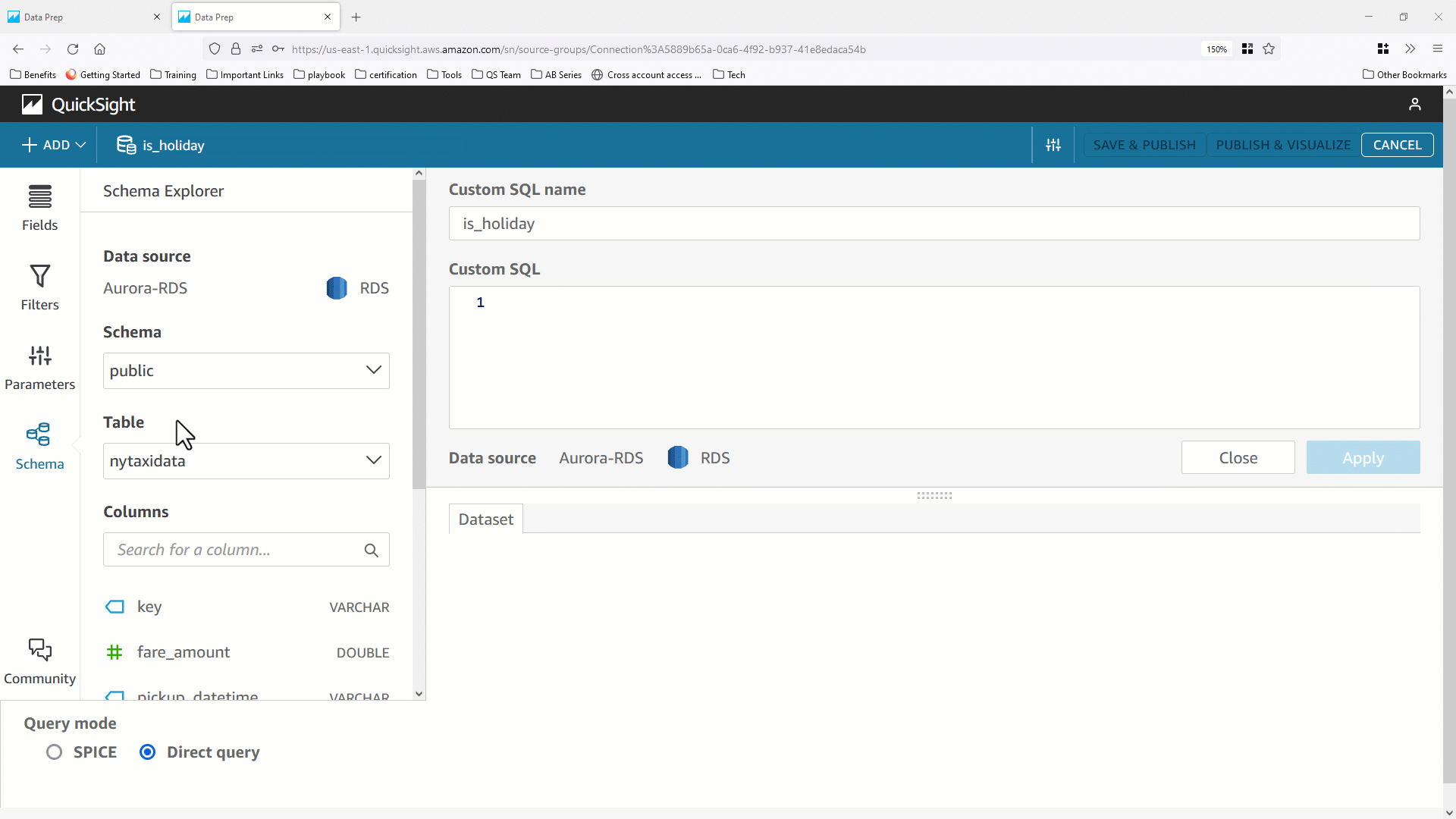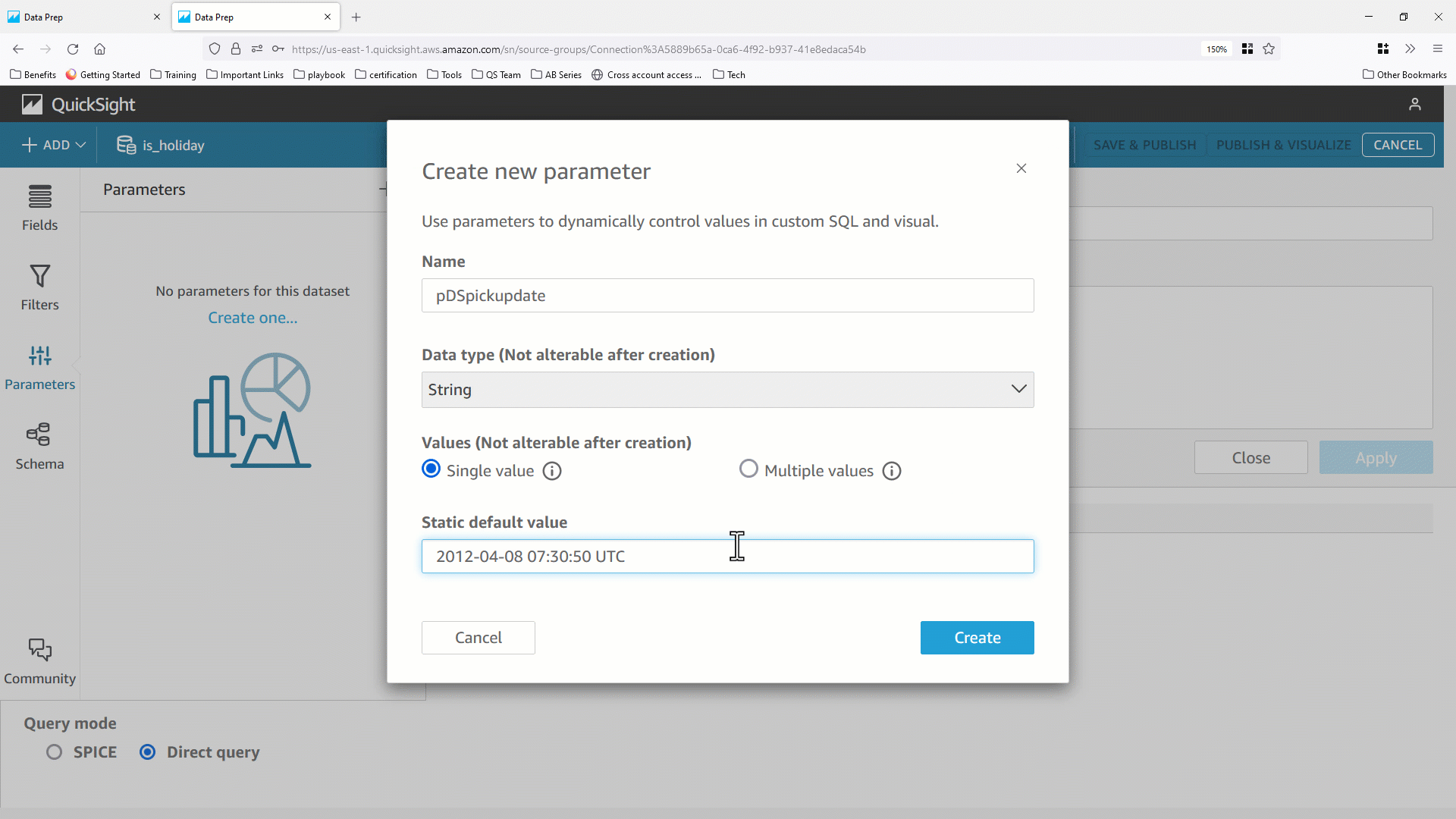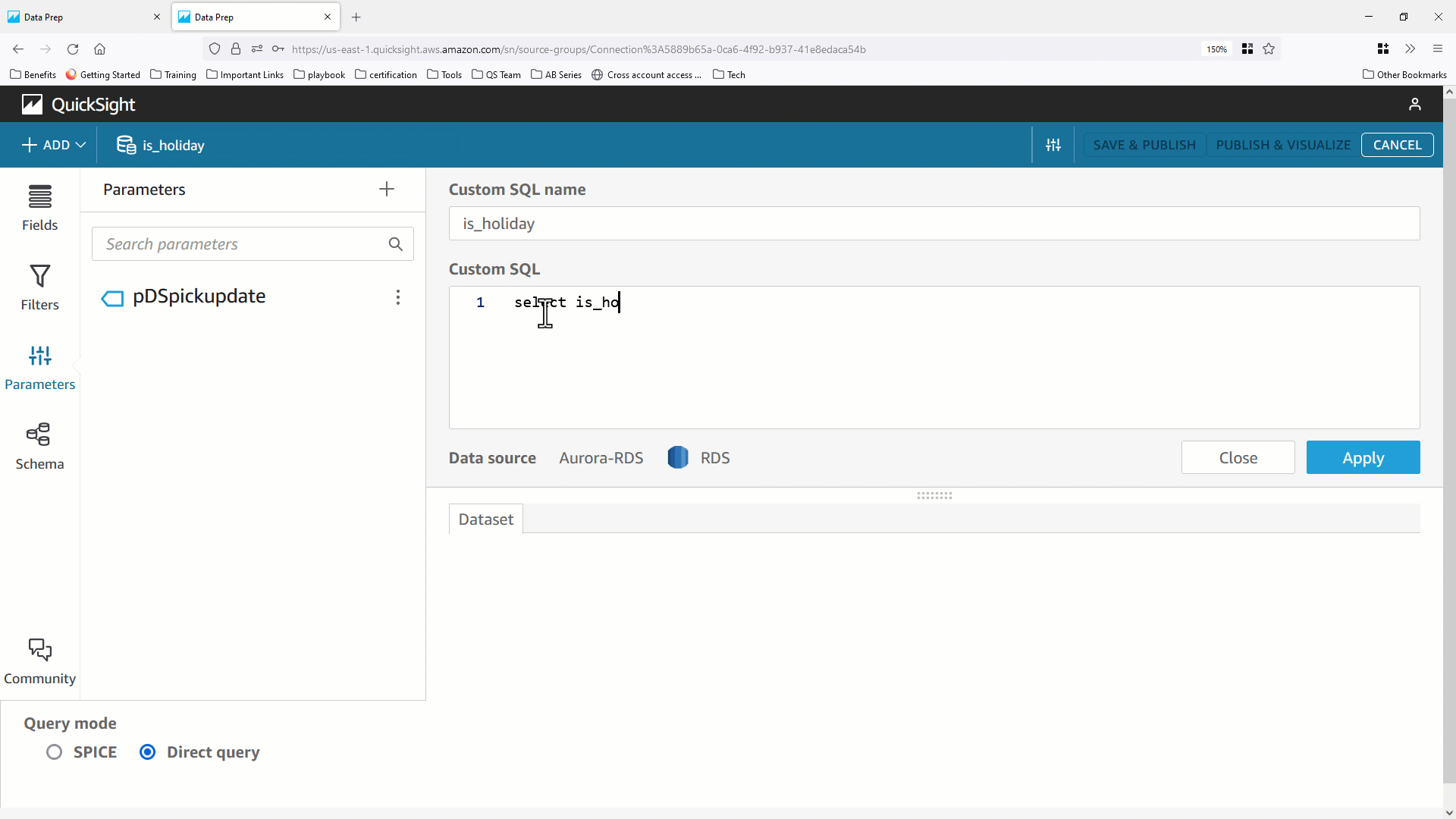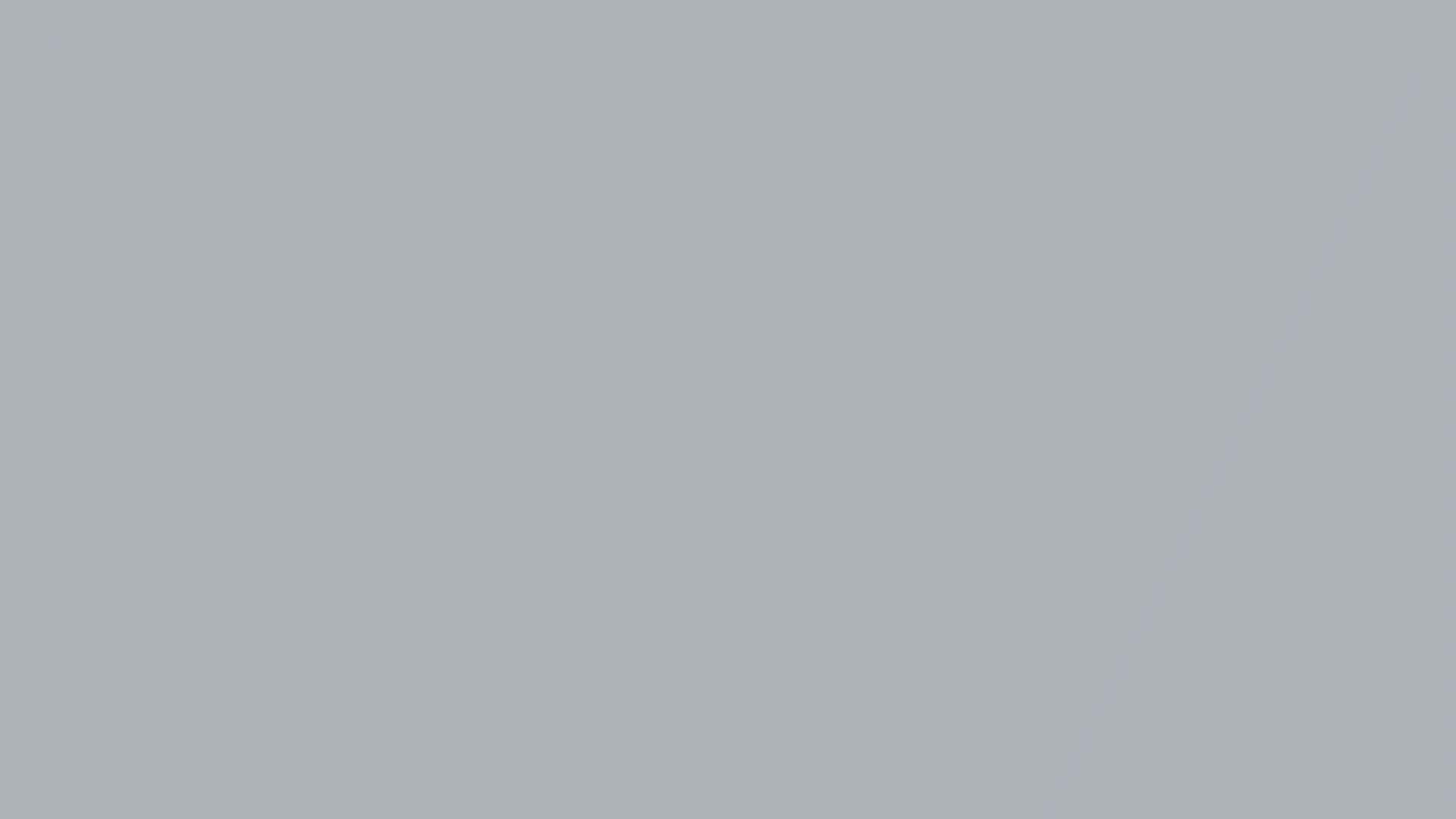
以下の例では、ニューヨークでのタクシー乗車に関するデータを含むテーブルに対し、直接クエリ接続形式でデータセットを作成しています。カスタム SQL に WHERE 句を追加することで、乗車日に基づきデータセットをフィルタリングできるようにします。乗車日は後ほどダッシュボード閲覧者によって指定されます。SQL では <<$pPickupDate>> パラメータで指定された値とpickupdate 列の値が一致する行のみが抽出されます。これにより、特定のタクシー乗車日のデータのみに関心があるユーザーにとって、データセットのサイズを大幅に小さくすることができます。
以下コードを参照してください。
SELECT *
FROM nytaxidata
WHERE pickupdate = <<$pPickupDate>>
ユーザーがパラメータに複数の値を入力できるようにするには、複数値のパラメータ (例えば pPickupDates )を作成し、そのパラメータを次のように SQL の IN 述語に挿入します。
SELECT *
FROM nytaxidata
WHERE pickupdate in (<<$pPickupDates>>)
データセットパラメータのユースケース
このセクションでは、データセットパラメータを使用する一般的なユースケースとその利点について説明します。
直接クエリで最適化されたカスタム SQL
データセットパラメータを使用することで、カスタム SQL で得られる柔軟性と、最適化された SQL で得られるパフォーマンスの両方のメリットを享受することができます。パラメータ化されたデータセットはロードされる際、比較的小さな結果セットにフィルタリングされます。作成者や閲覧者は、分析やダッシュボードの初期表示時、パラメータのデフォルト値を使用することで高速に読み込むことができます。さらに、後ほどダッシュボードのフィルターコントロールを使用しデータを細かく分析する際にもパラメータが適用されます。データ所有者としても、データセットによりバックエンドのデータベースに対する処理負荷を軽減し、スケーラビリティやパフォーマンスの向上を図りユーザーの同時実行性を上げることができます。
特に副問合せ内でデータをフィルタリングするようなネスト化されたクエリなど、複雑なカスタム SQL を含む直接クエリの場合、パフォーマンス向上効果はより明確になります。
分析全体で再利用可能な汎用データセット
データセットのパラメータにより、データセットをさまざまな分析で広く再利用できるようになり、データ所有者がデータセットを準備して管理する労力を軽減できます。 SPICE データセットでも直接クエリデータセットでも、データセットパラメータを使用することにより、計算フィールドの参照パラメータを分析からデータセット側に移植できます。データセット所有者が作成したパラメータについて、分析作成者は複数の分析ごとに都度参照する計算フィールド作成するのではなく、データセット内にある計算フィールドとして再利用できるようになりました。
パラメータに依存する計算フィールドを分析からデータセット側に移植するオプションを選択すると、データセットに計算フィールドを作成して複数の分析で再利用することができます。これはガバナンスを重視するユースケースで有効です。データセット所有者は、パラメータに依存する計算フィールドを分析から分離し、分析の作成者が計算フィールドを変更できないようにすることでビジネスロジックを保護できます。
静的変数によるデータセットの保守性向上
カスタム SQL や計算フィールドの複数箇所で静的な値(プレースホルダー)を参照するデータセットがある場合、データセットパラメータを作成し複数箇所で再利用できるようになりました。これによりコードの保守性が向上可能です。
(ただし、カスタム SQL へのパラメータ挿入は直接クエリでのみ可能である点に注意してください。)
ソリューション概要
このシナリオでは、まずデータセットパラメータなしでカスタム SQL 直接クエリデータセットを作成し、最適化されていない SQL が生成されることを確認します。そしてデータセットパラメータを使用しない場合、カスタム SQL がどのように実行されていくかをデモを通して観察します。次に、カスタム SQL を変更してデータセットパラメータを追加し、データセットパラメータを使用した場合に同じデータセットに対し、最適化されたクエリが生成されることを示します。
なお、この例では、データベースとして Amazon RDS for PostgreSQL を使用しますが、この機能は QuickSightで利用可能なその他のSQLベースのデータソースでも動作します。
分析パラメータを使用してデータをクエリする
データソース、データセット、分析をセットアップするには以下手順を実行します。ご自身のデータを使用する場合は、次のセクションに進んでください。
- QuickSight のデータソースを作成します。
次のスクリーンショットはデータソース接続の詳細を例示しています。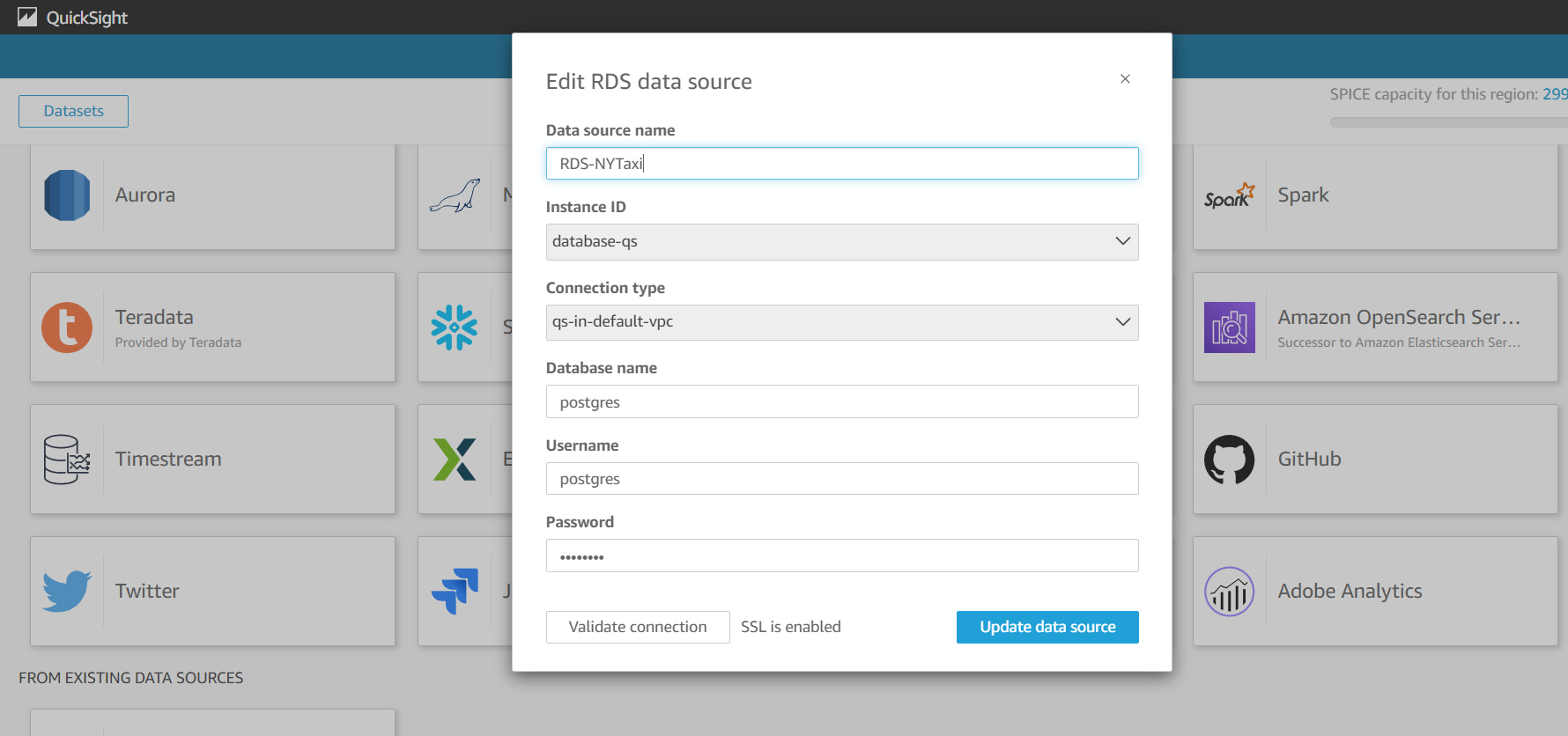
- 直接クエリのカスタム SQL データセットを作成します。
今回、NYC OpenData で公開されているニューヨークのタクシー乗車データの部分集合である約100万件のレコードをサンプルとして使用します。データは nytaxidata と命名された RDS for PostgreSQL データベース上のテーブルにロードされています。
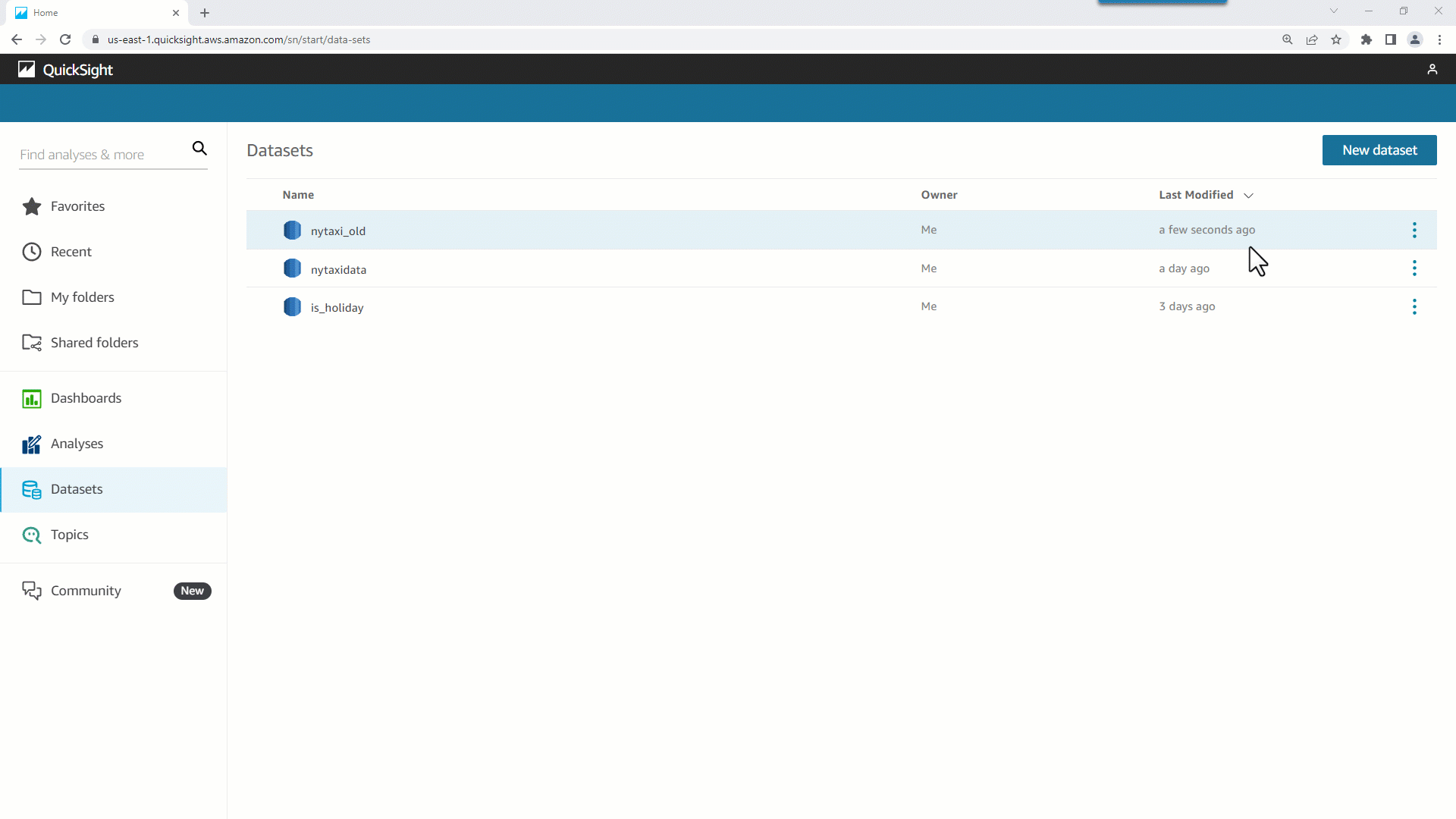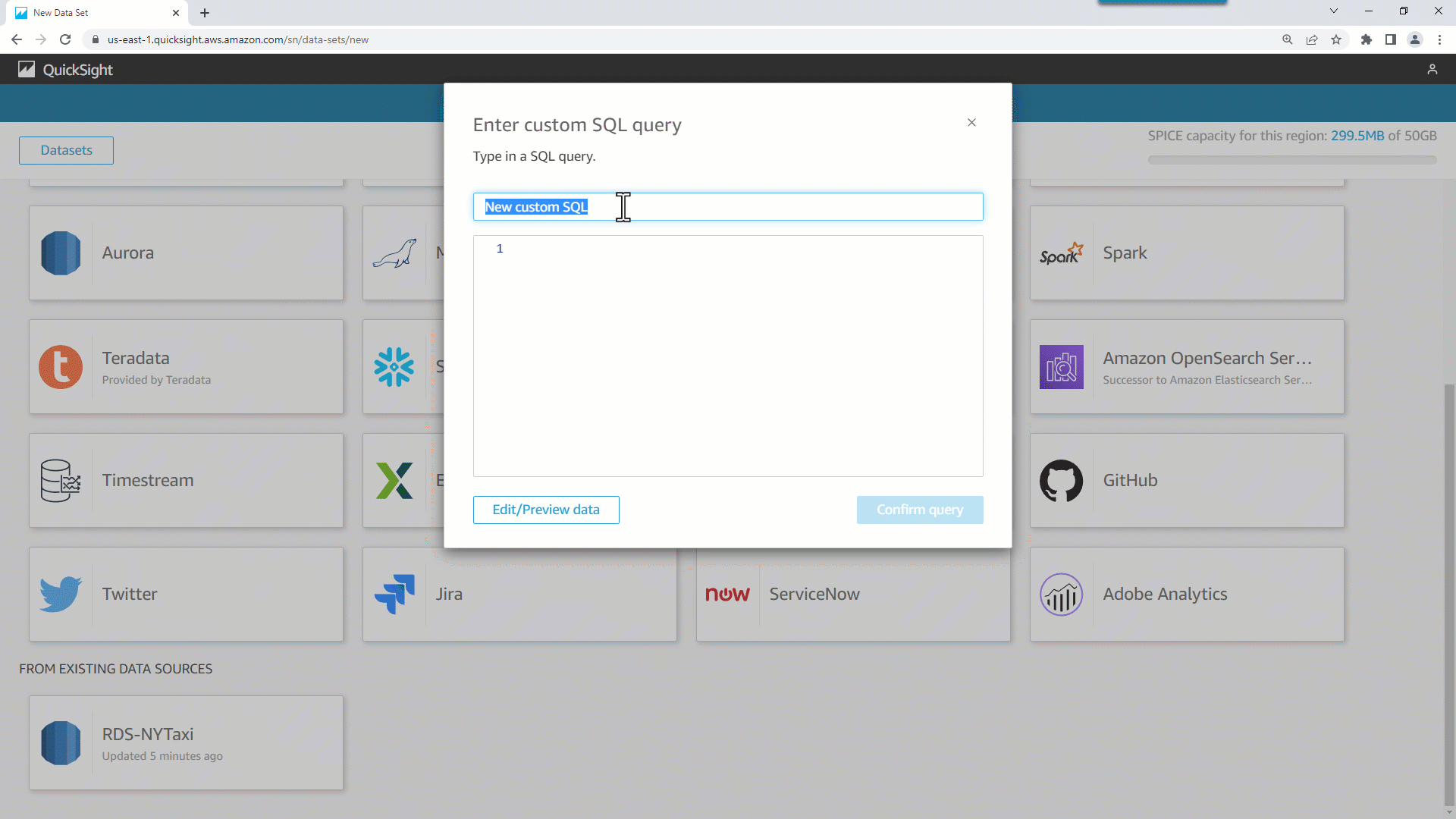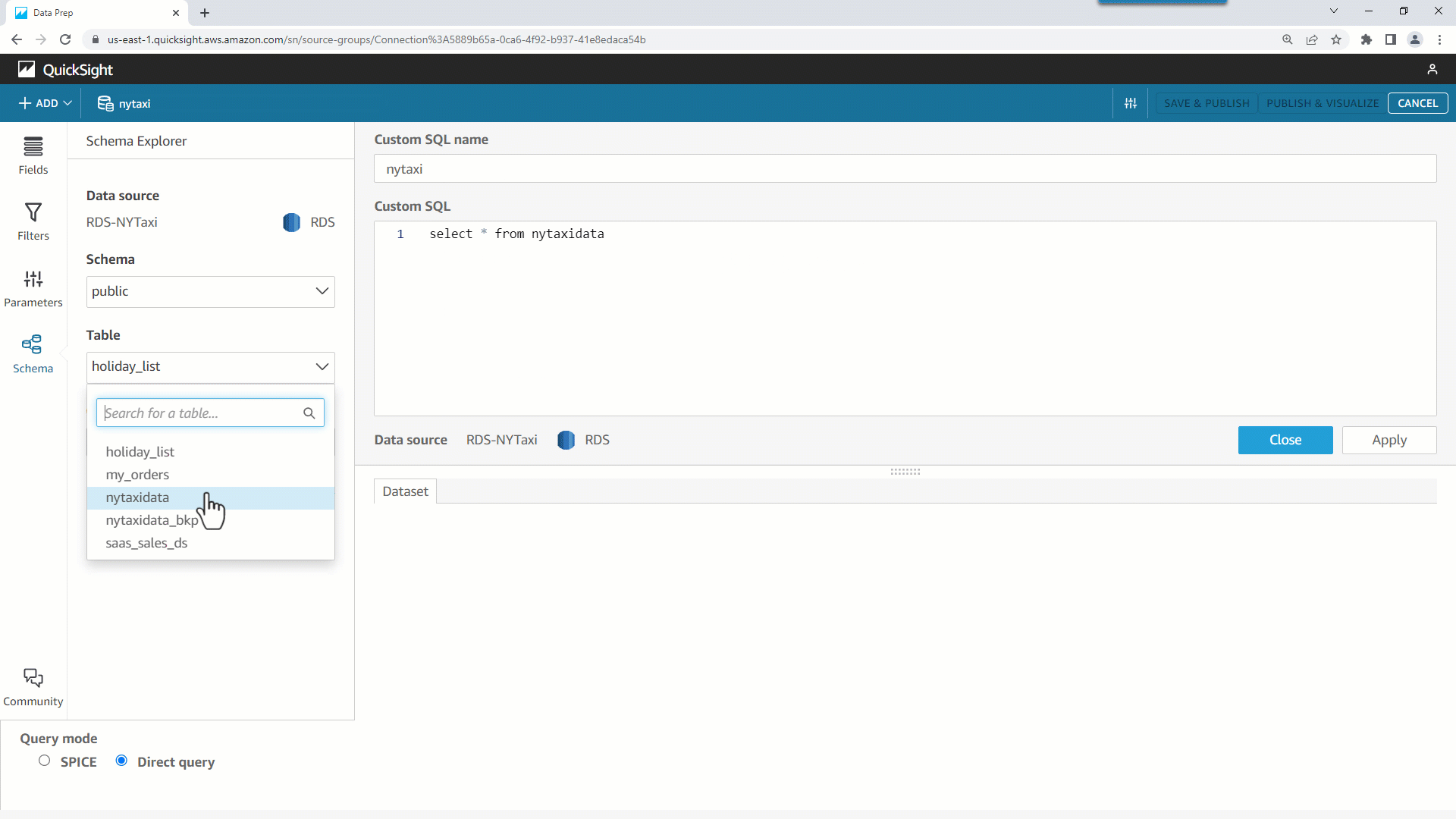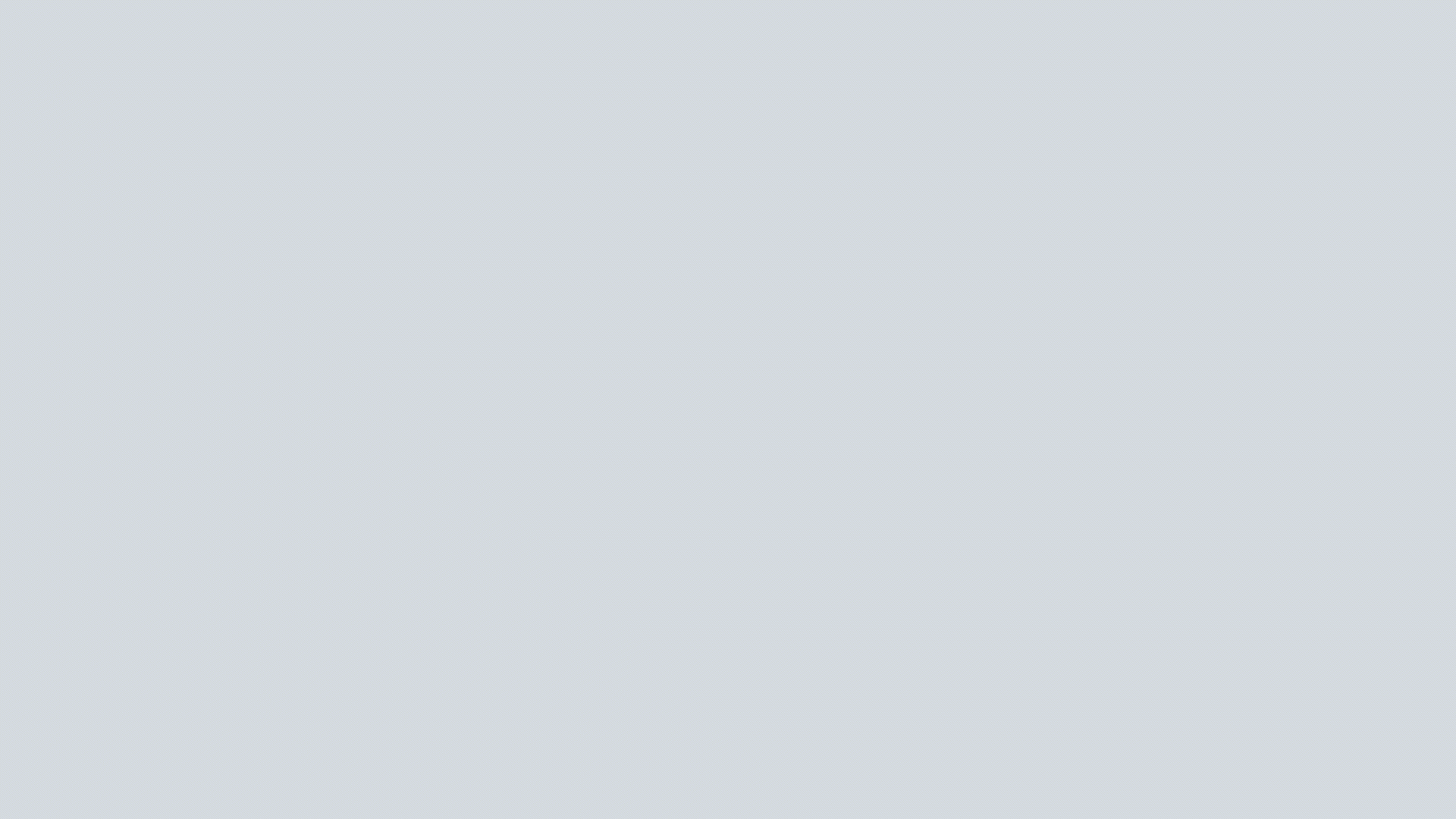
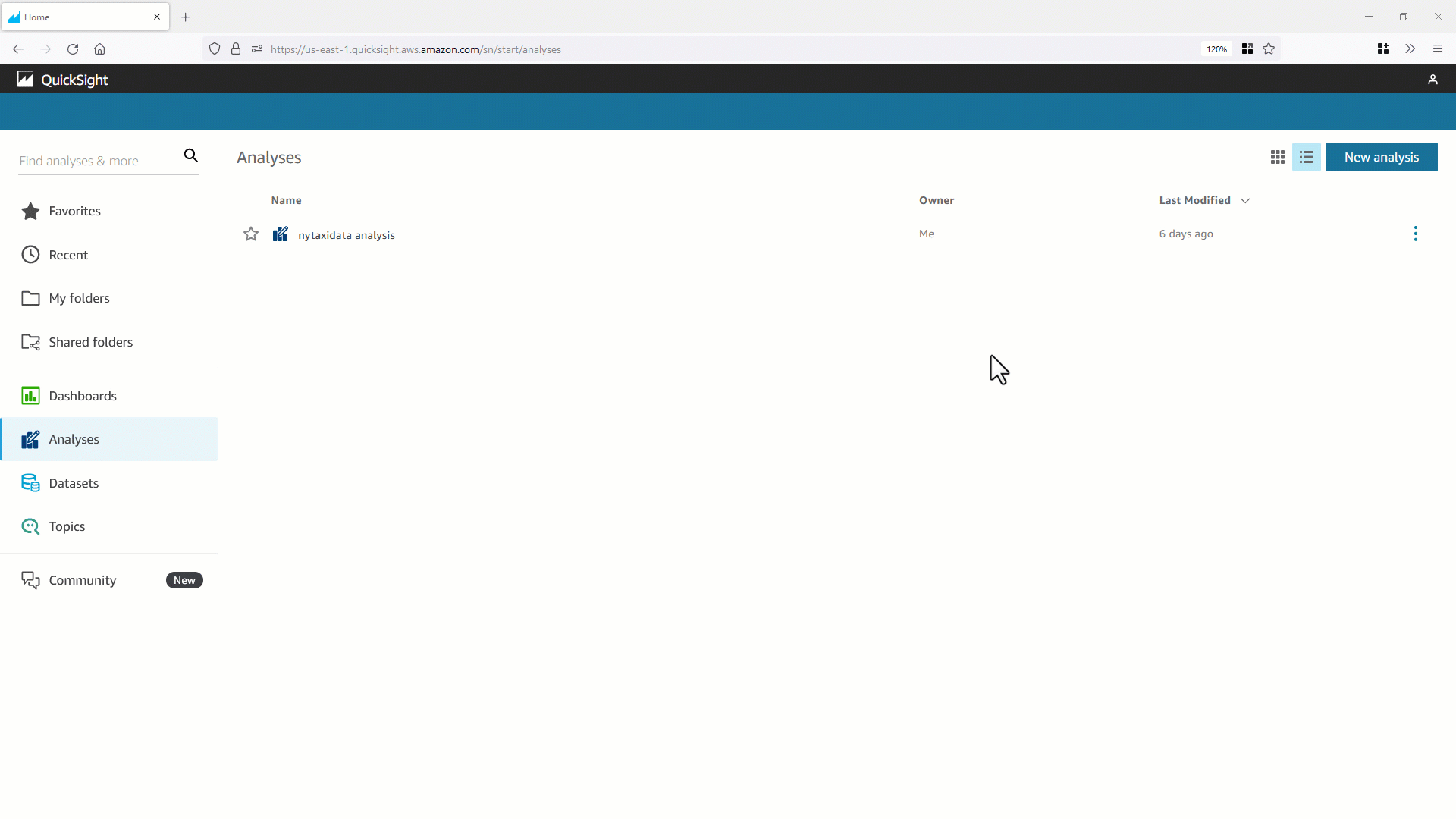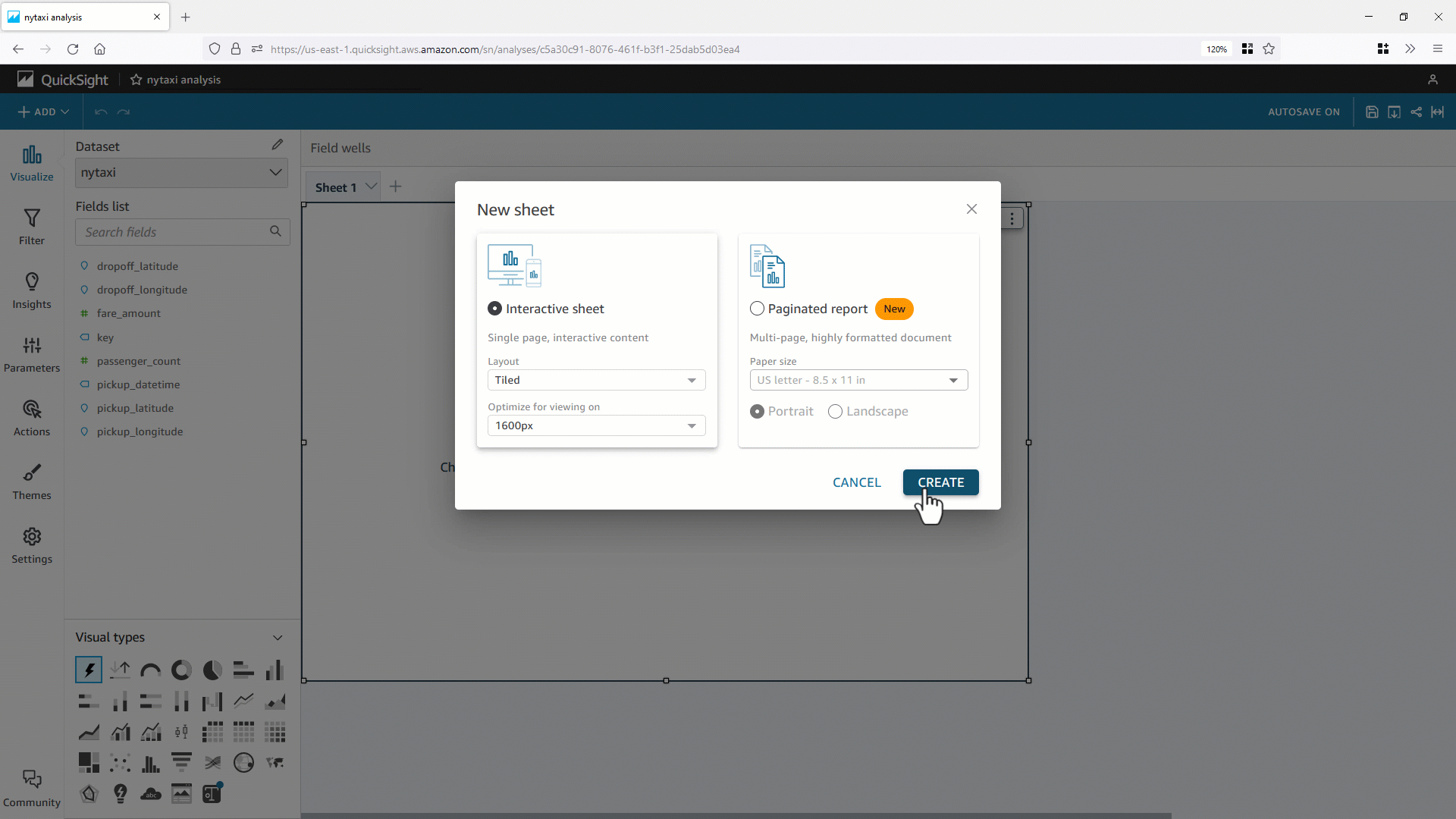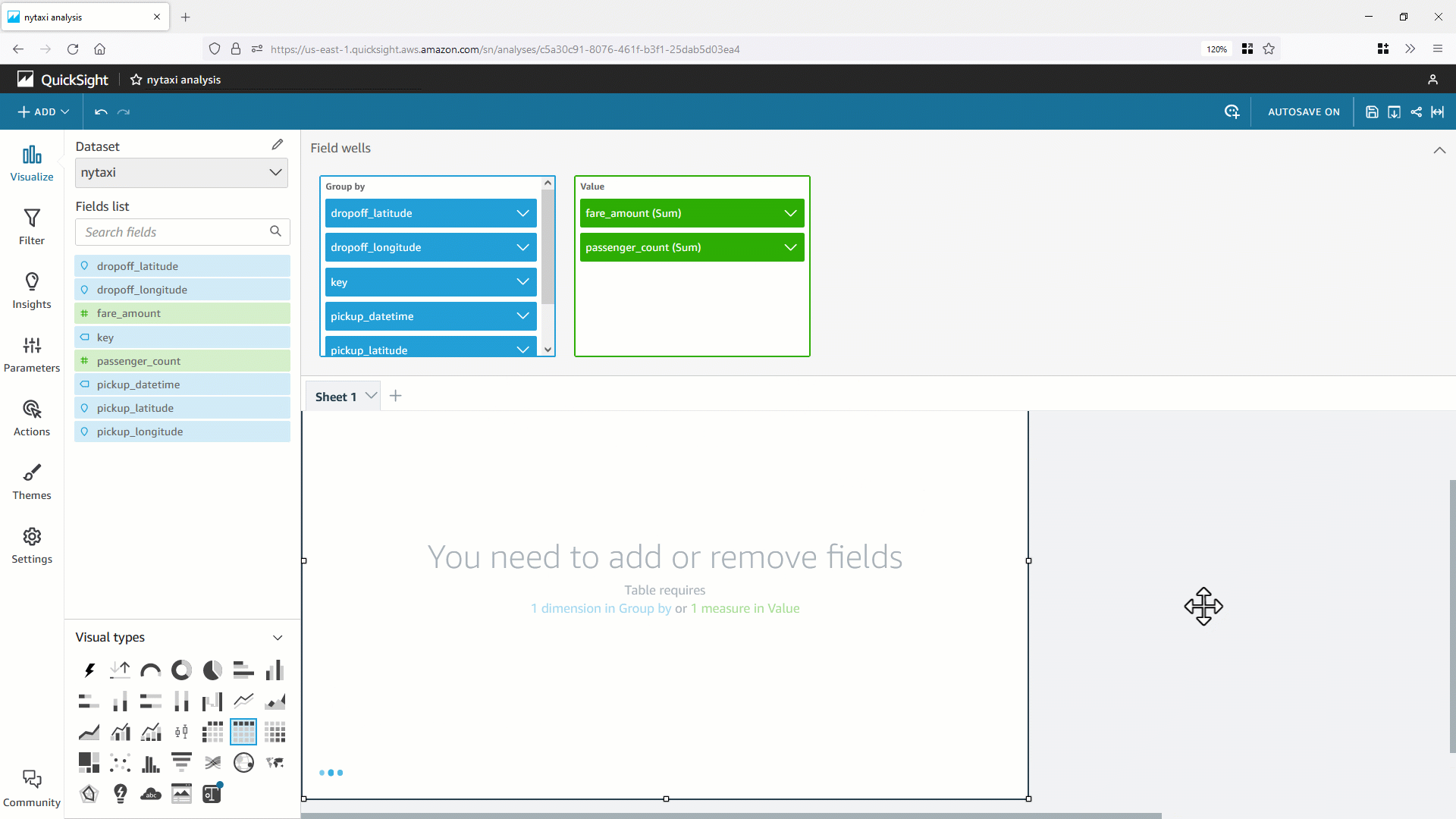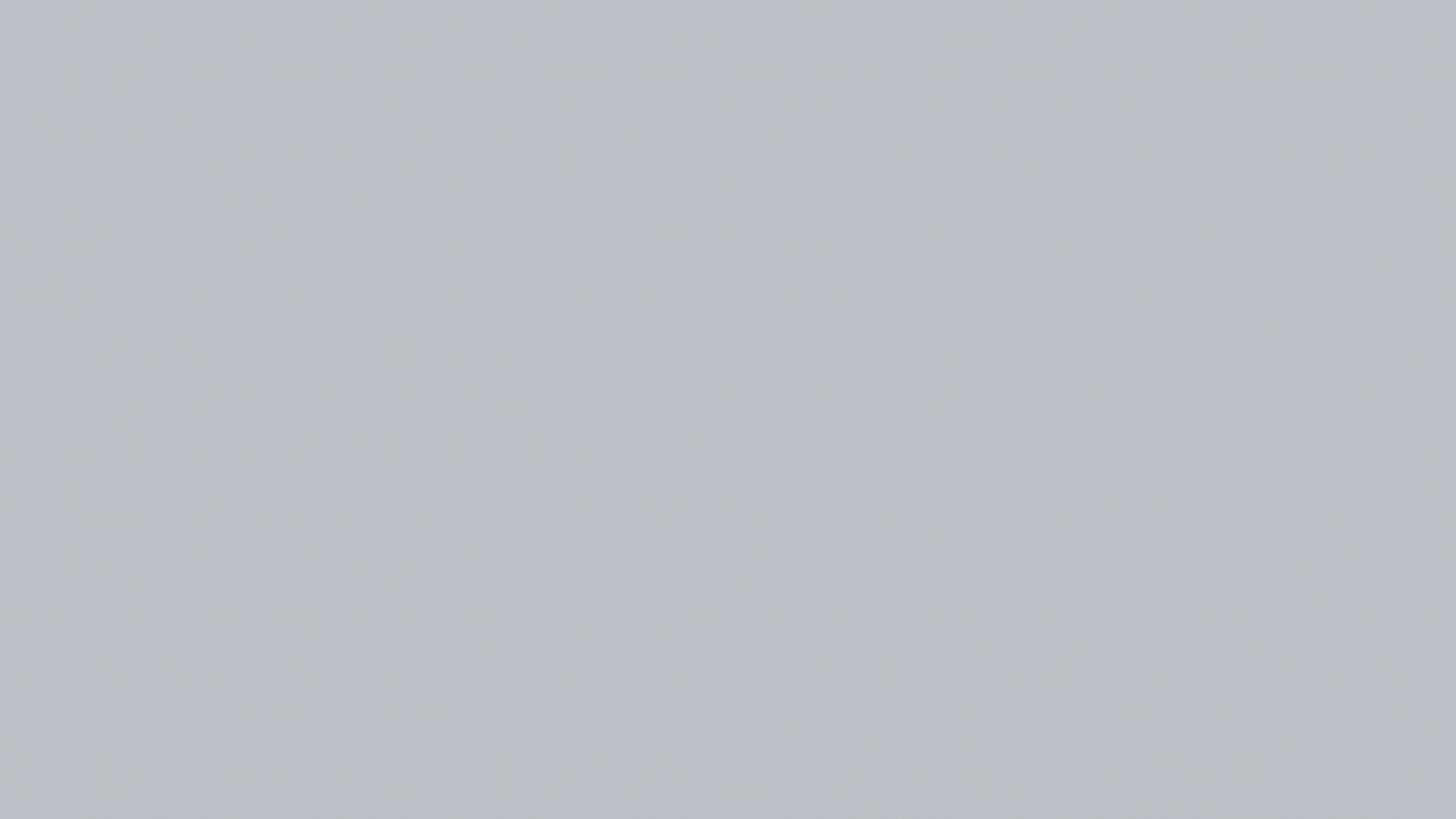
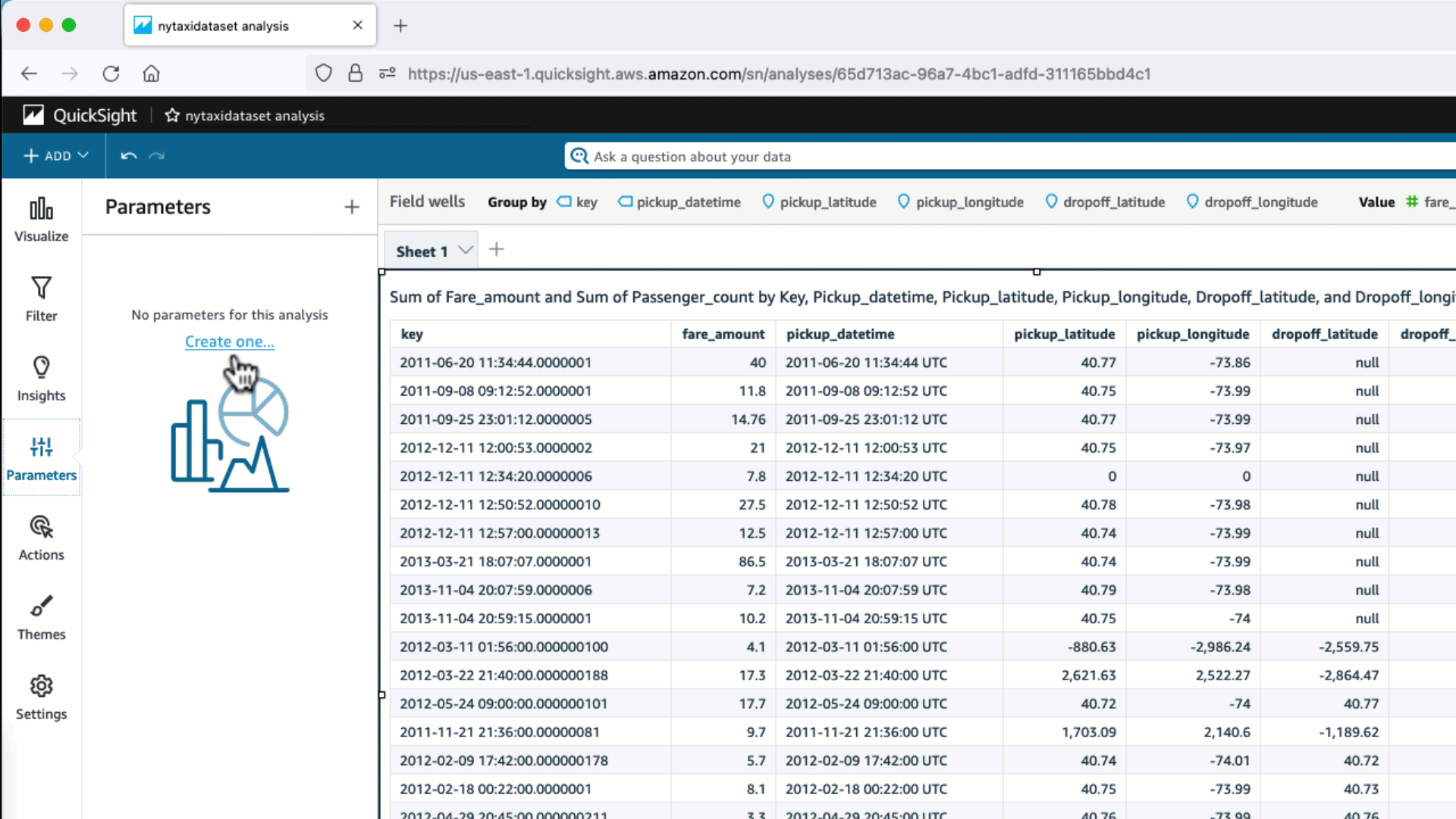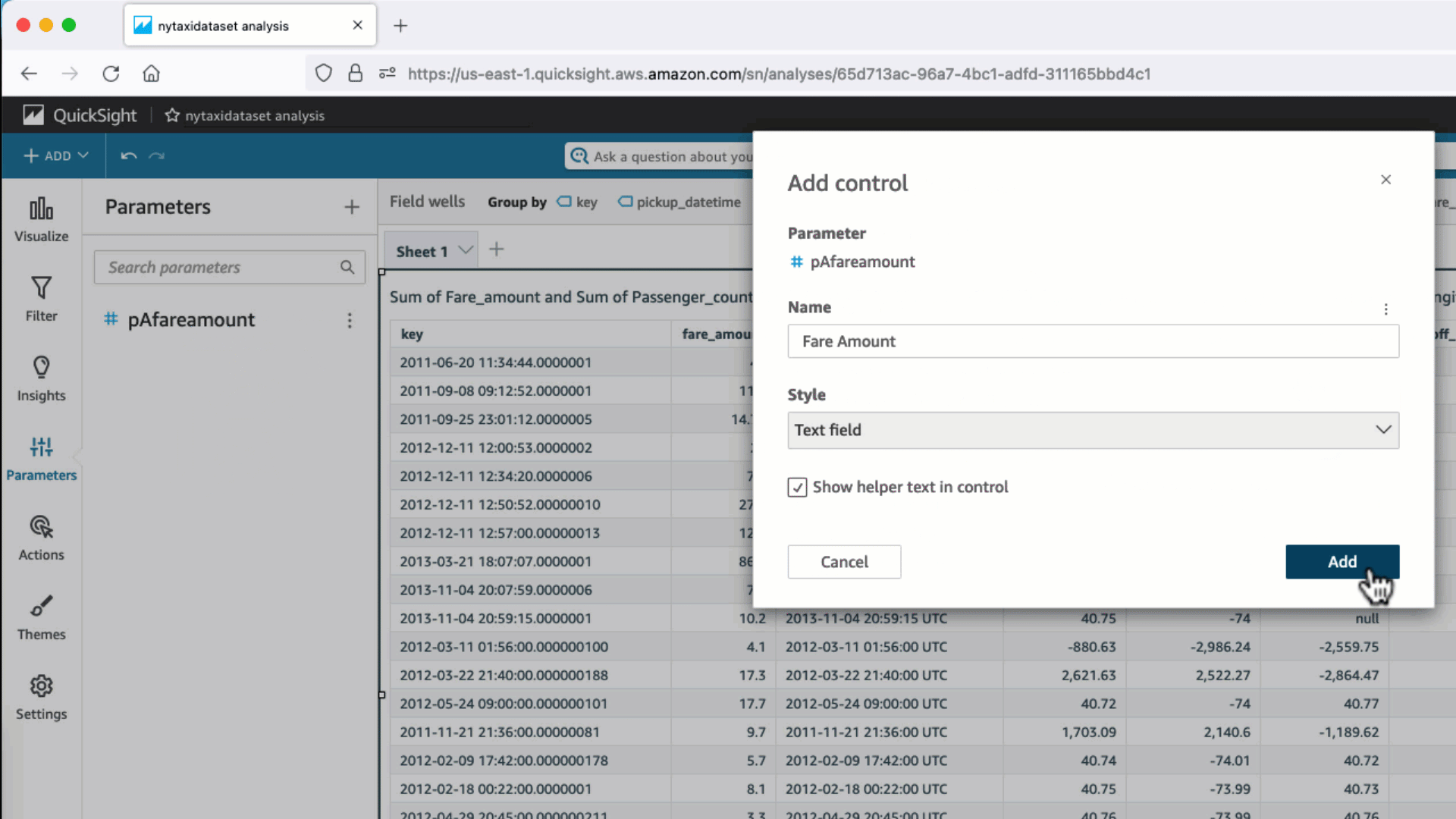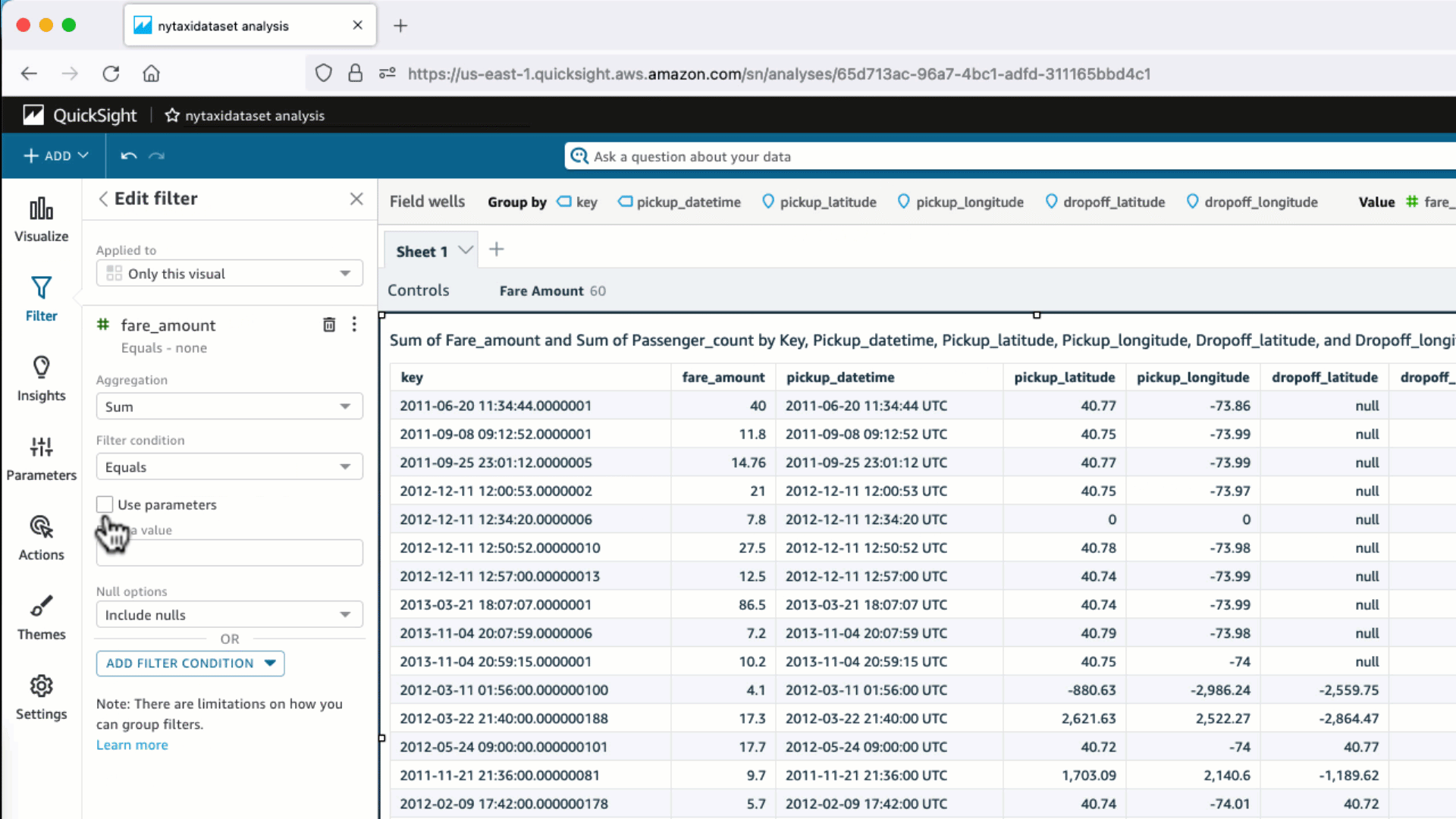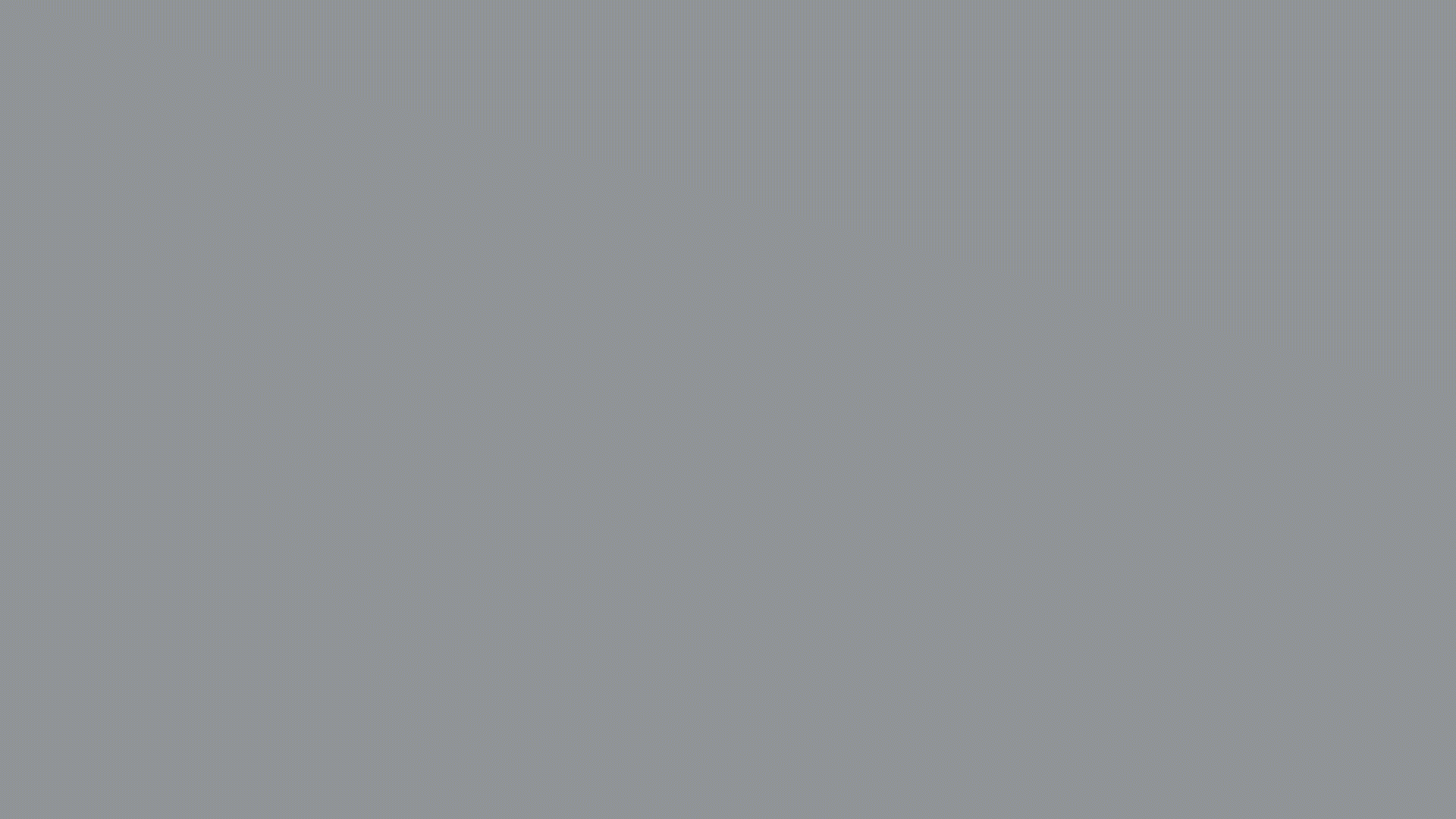
- 作成したデータセットを使いサンプルの分析を作成します。 ビジュアルからテーブルを選択し、いくつかの項目をフィールドリストから追加します。
- 分析をリロードして、 PostgreSQL データベース上で生成されたクエリを確認します。
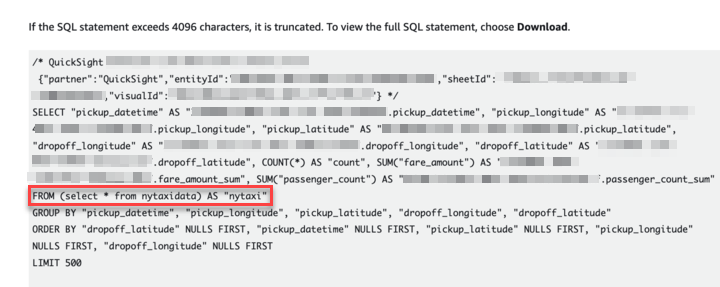
以下の RDS Performance Insights のスクリーンショットに示されている通り、データセット全体が読み込まれていることが分かります( select * from nytaxidata )。
- QuickSight の分析にパラメータにリンクされたフィルターコントロールを追加します。その上で、このフィルターコントロールの値を任意のものに変更します。
データセットで定義したカスタムSQLは副問い合わせで使用され、Where句がありません。フィルター用のパラメータは引き続き主問合せ側の WHERE 句として使用されているため、カスタム SQL は副問合せとして結果セット全体をフェッチしてしまいます。カスタム SQL クエリではなく、データベーステーブルそのものをデータセットとして使用した場合は、そうならない可能性があります。テーブルを直接基にしたデータセットでは、パラメータ値は WHERE 句でデータベース側に引き渡されます。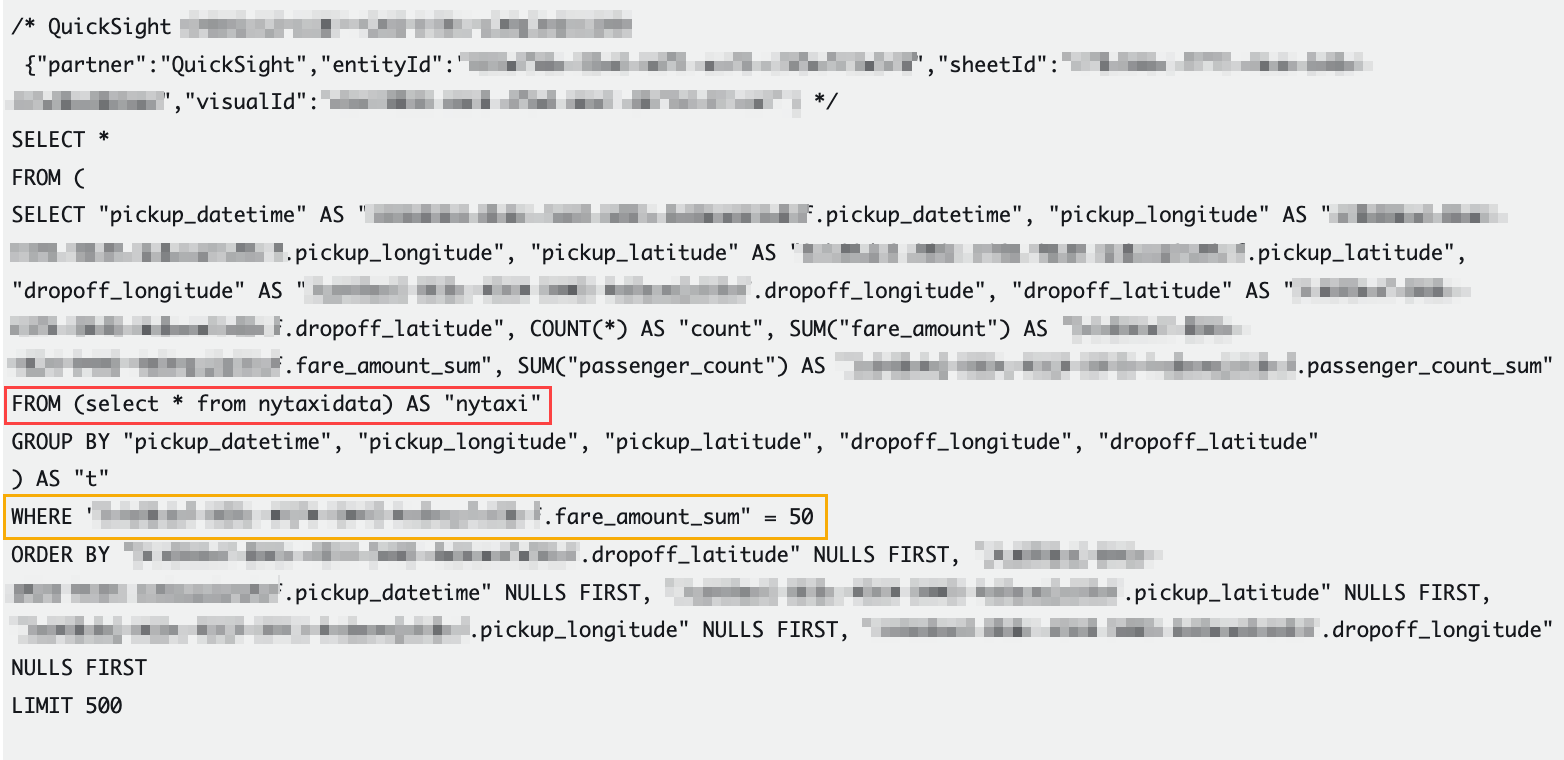
では、カスタム SQL データセットの WHERE 句にパラメータを含められない課題を克服するにはどうすればよいでしょうか。データセットパラメータを使えばいいのです!
データセットパラメータを使用してクエリを最適化
データセットパラメータを使用して、より最適化されたクエリをデータベースに送信できるシナリオをいくつか見てみましょう。
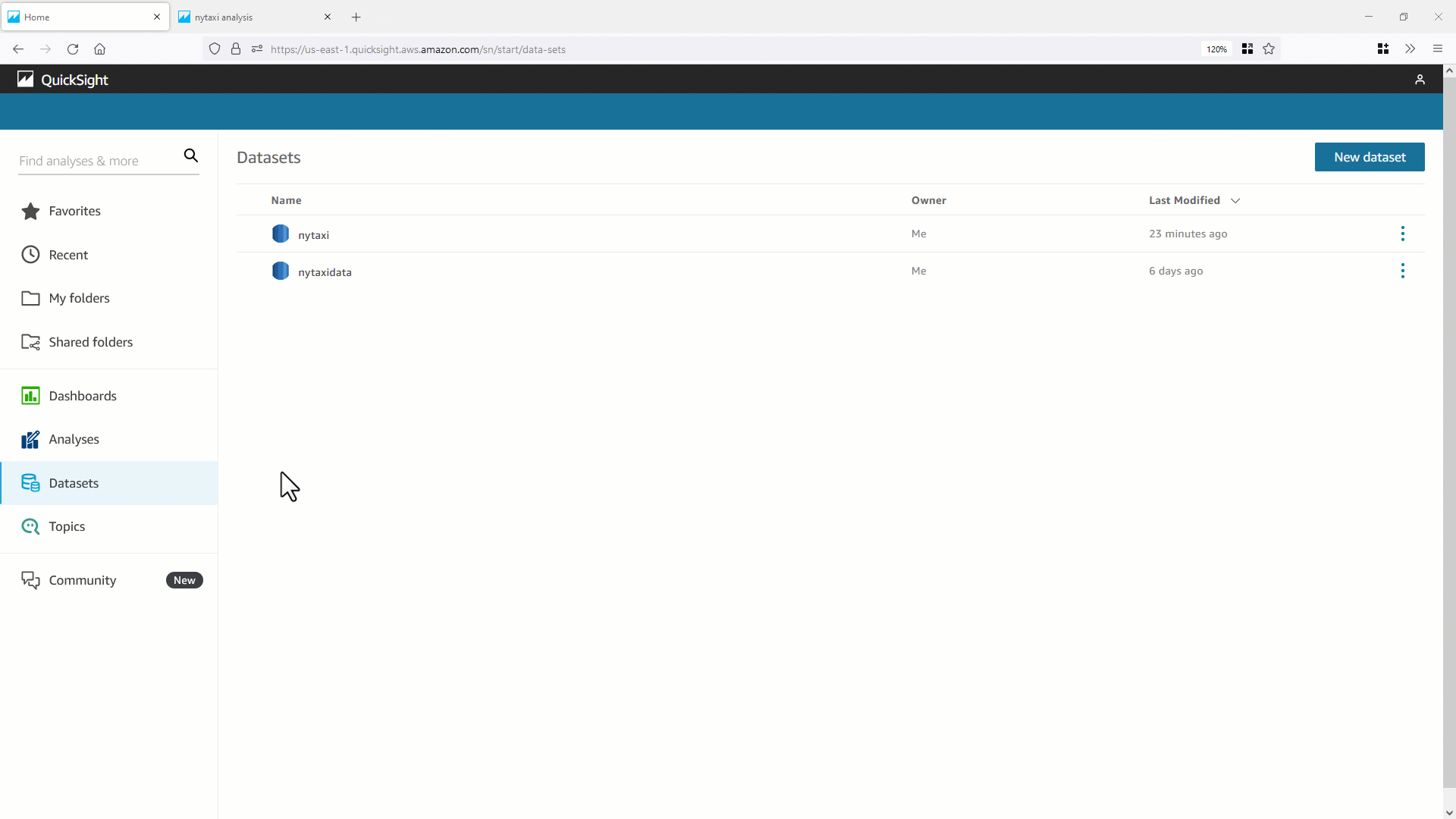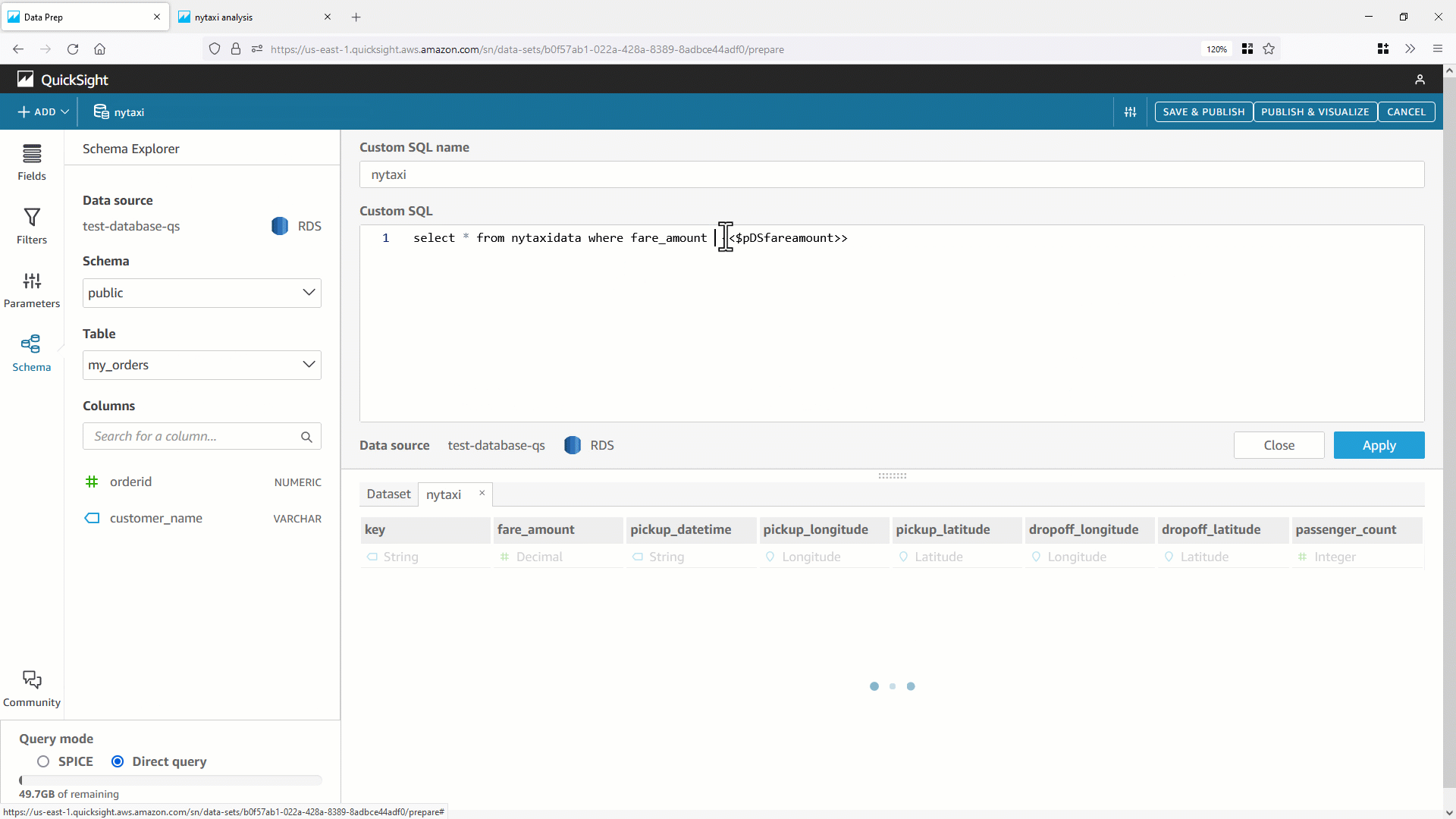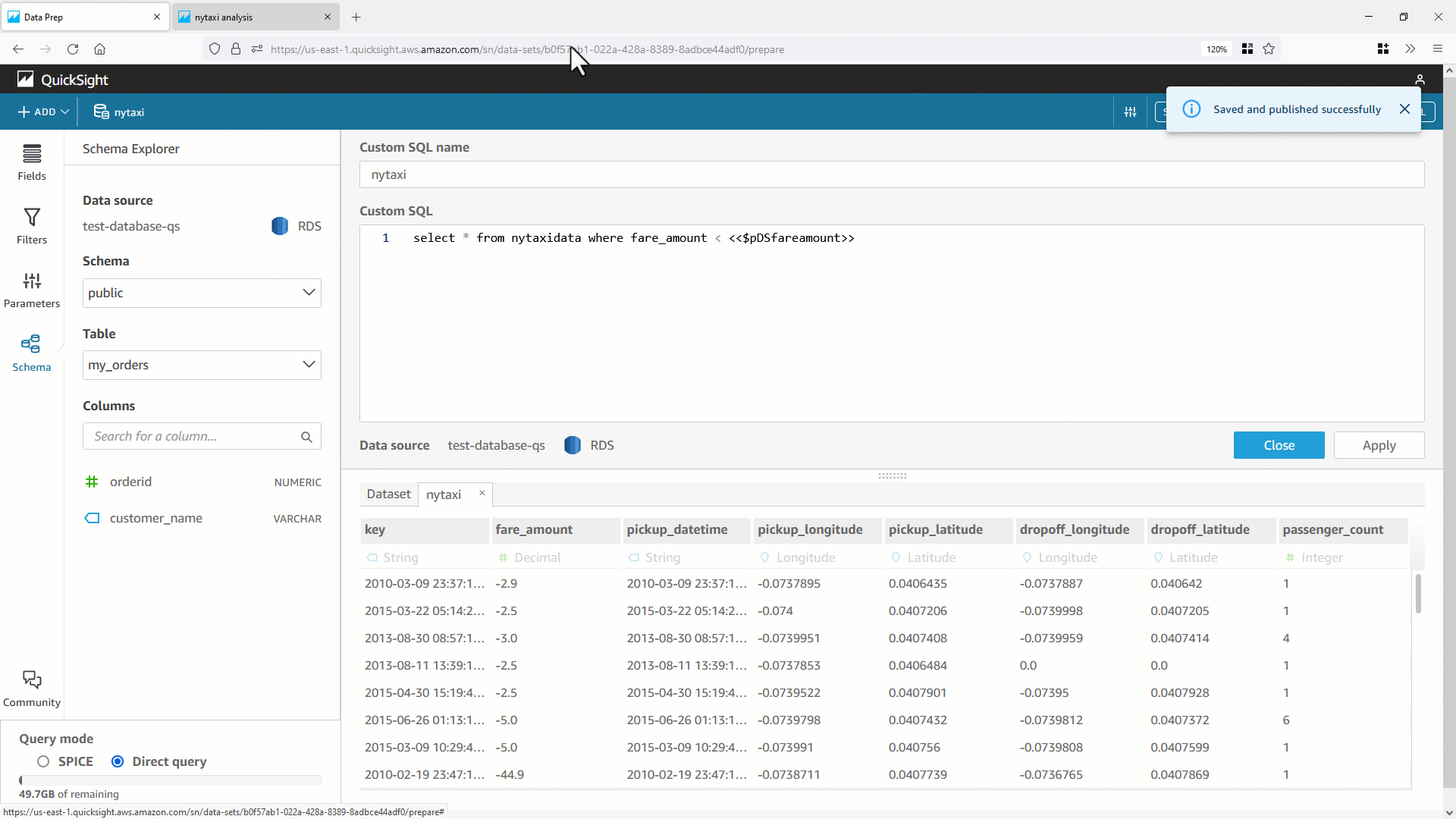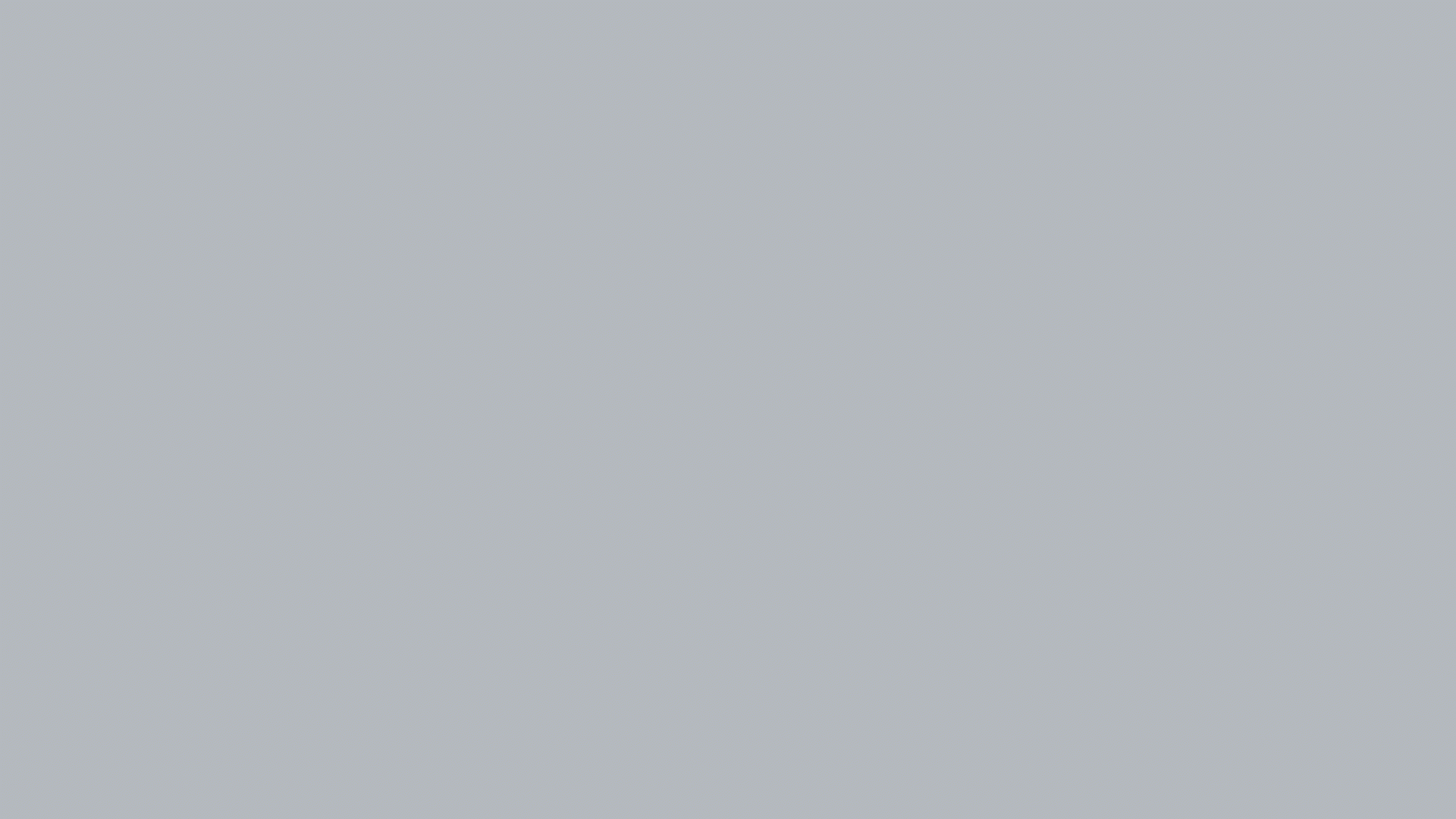
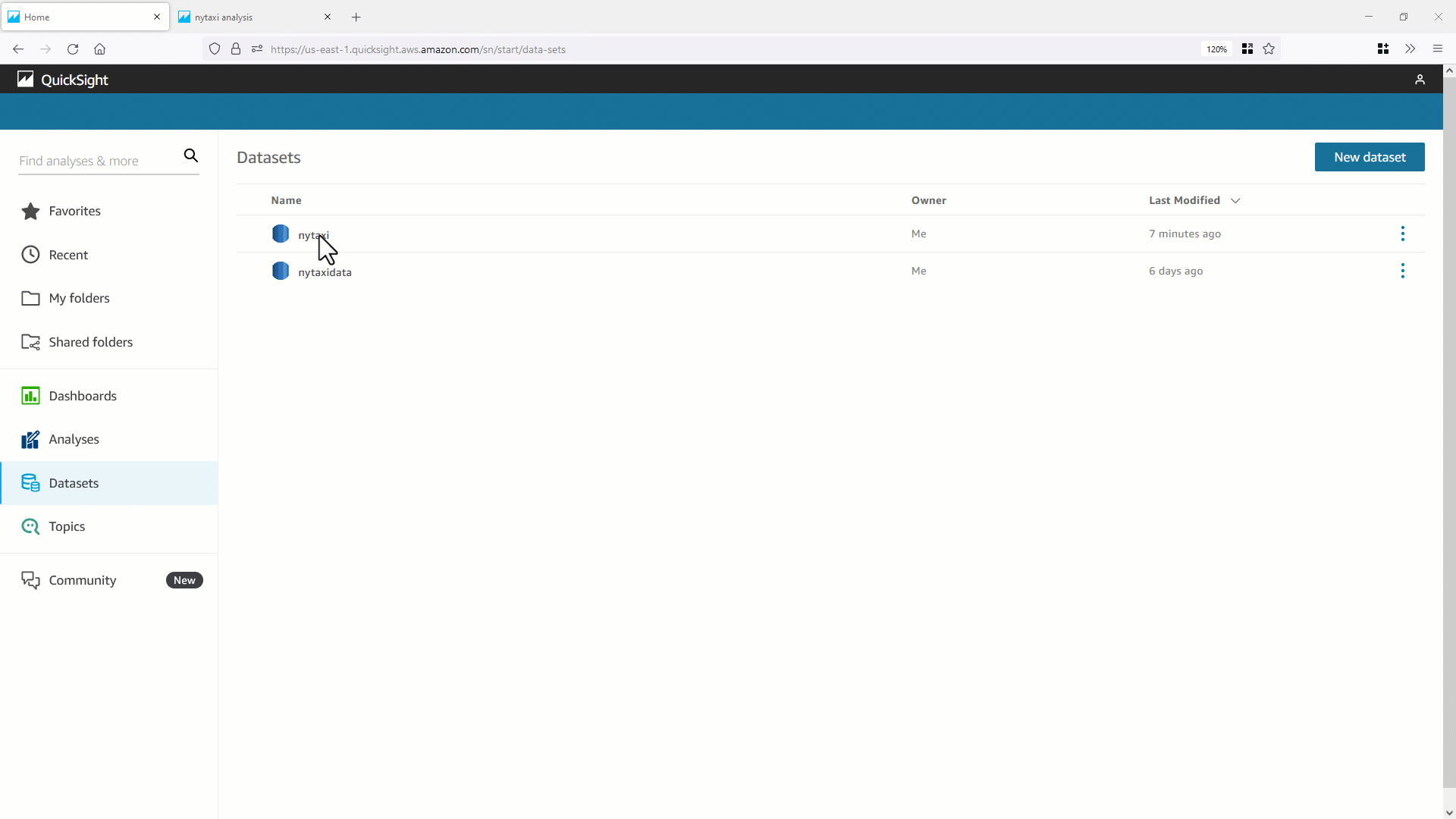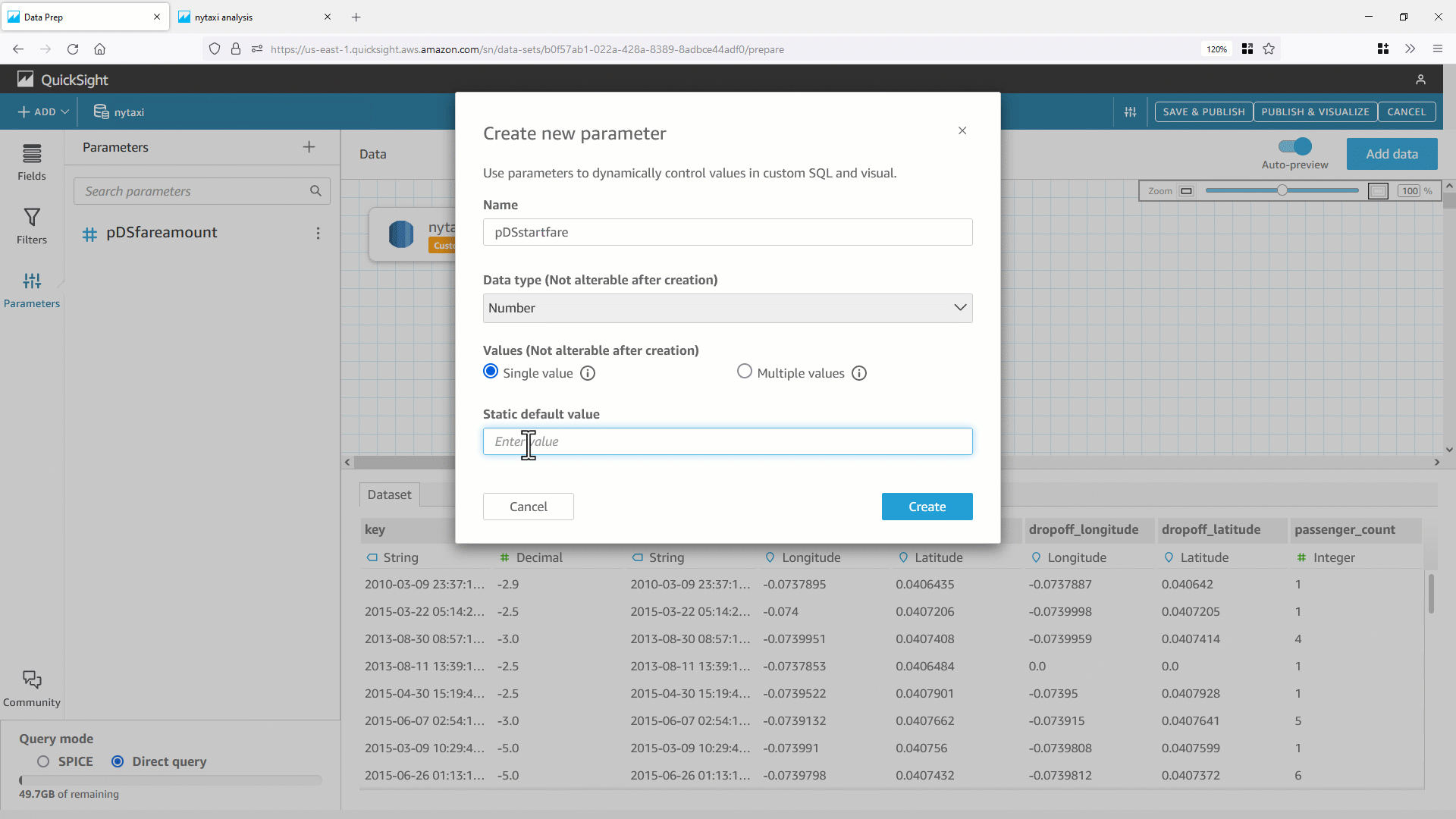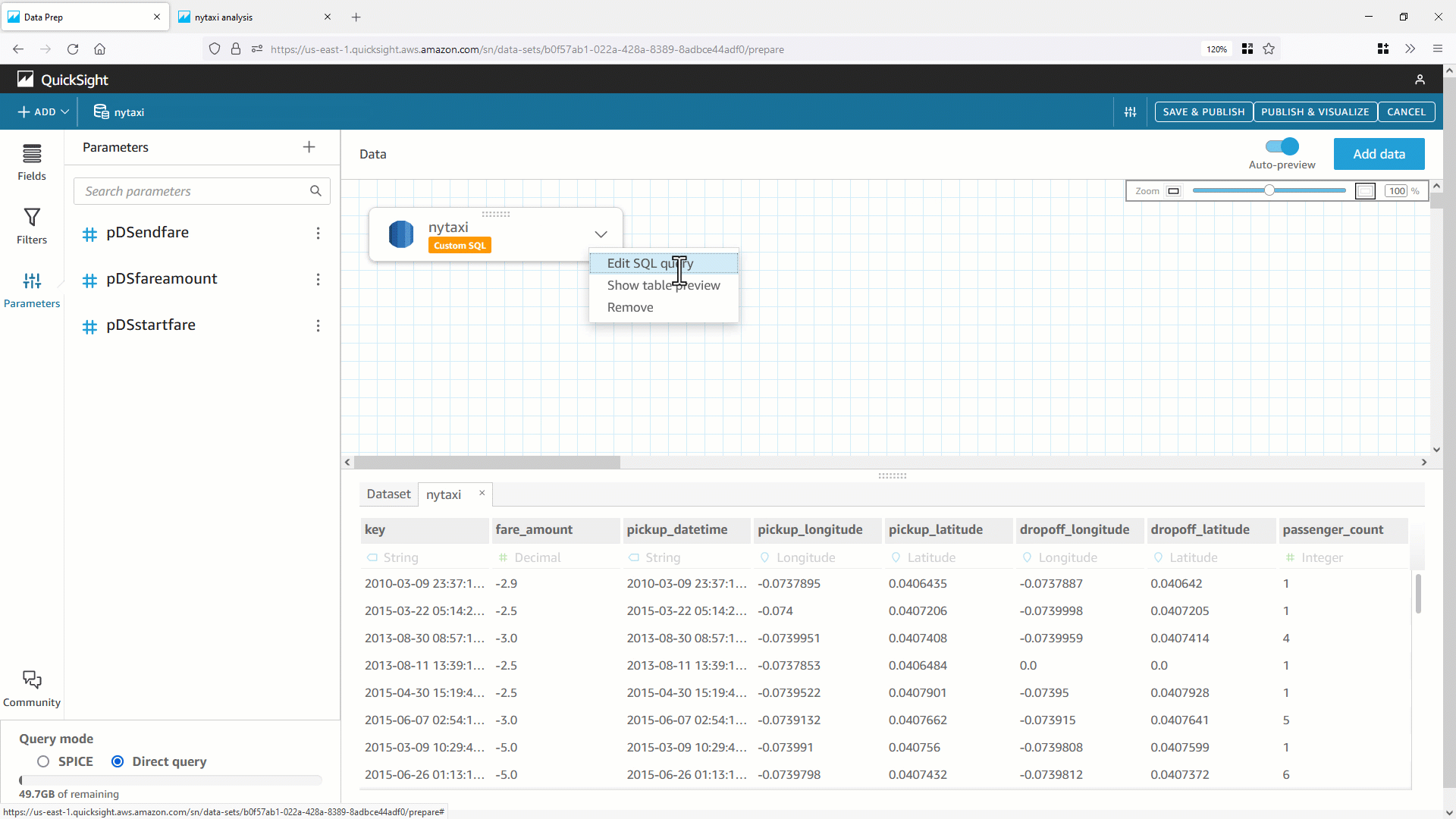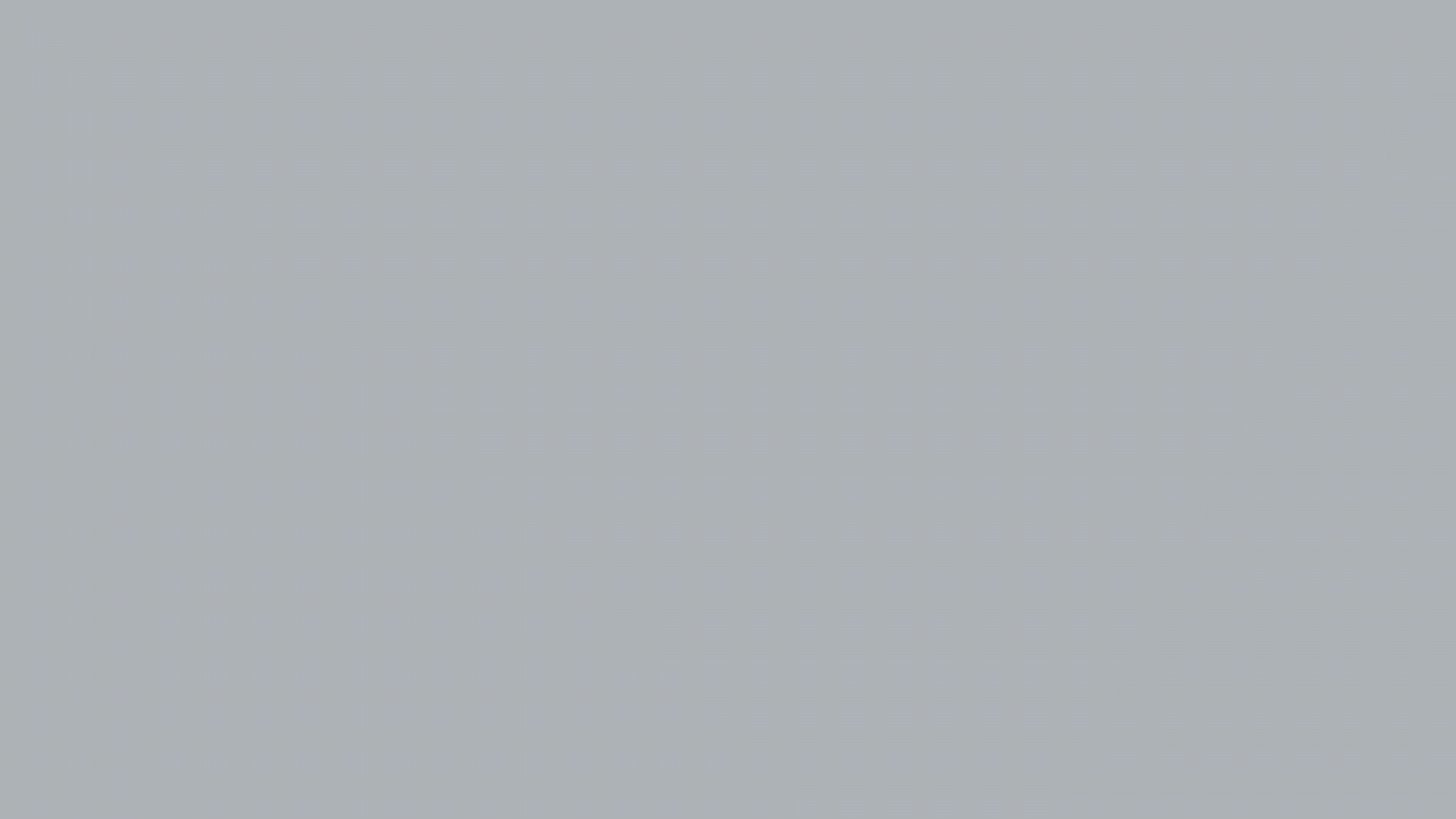
- まずデータセットパラメータ(例:
pDSfareamount )を作成し、カスタム SQL の等号演算子を使用した WHERE 句に追加します。データベースに渡された SQL に変化がないか確認します。
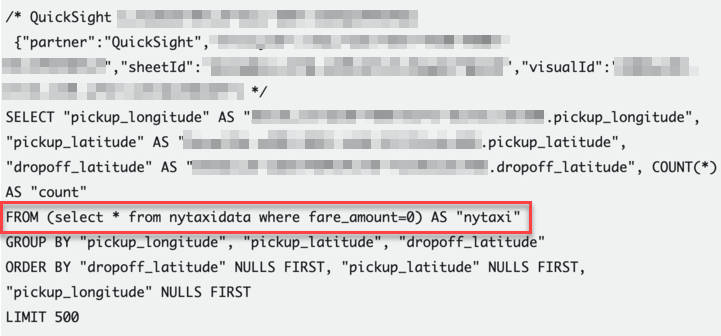
 今回は、副問合せ(
今回は、副問合せ( select * from nytaxidata where fare_amount=0 )の WHERE 句にデフォルト値を使用して最適化されたSQLが生成されていることが分かります。これにより、直接クエリデータセットのクエリパフォーマンスが向上します。
データセットパラメータと分析パラメータの紐づけ
データセットパラメータは分析パラメータに紐づけることもでき、ダッシュボードのインタラクションからユーザーが選択した値をデータセットパラメータに引き渡すことができます。
また単一の分析パラメータを複数のデータセットパラメータに紐づけることもできます。親となる分析パラメータをフィルターコントロールまたはアクションと連携し、カスタム SQL に基づき複数のデータセットをフィルタリングできるようになりました。
このセクションでは、データセットパラメータを分析パラメータに紐づけ、フィルターコントロールと関連付けします。
- まず、分析パラメータを作成し、それをデータセットパラメータに紐づけます(これまでに作成したデータセットパラメータを使用します)。
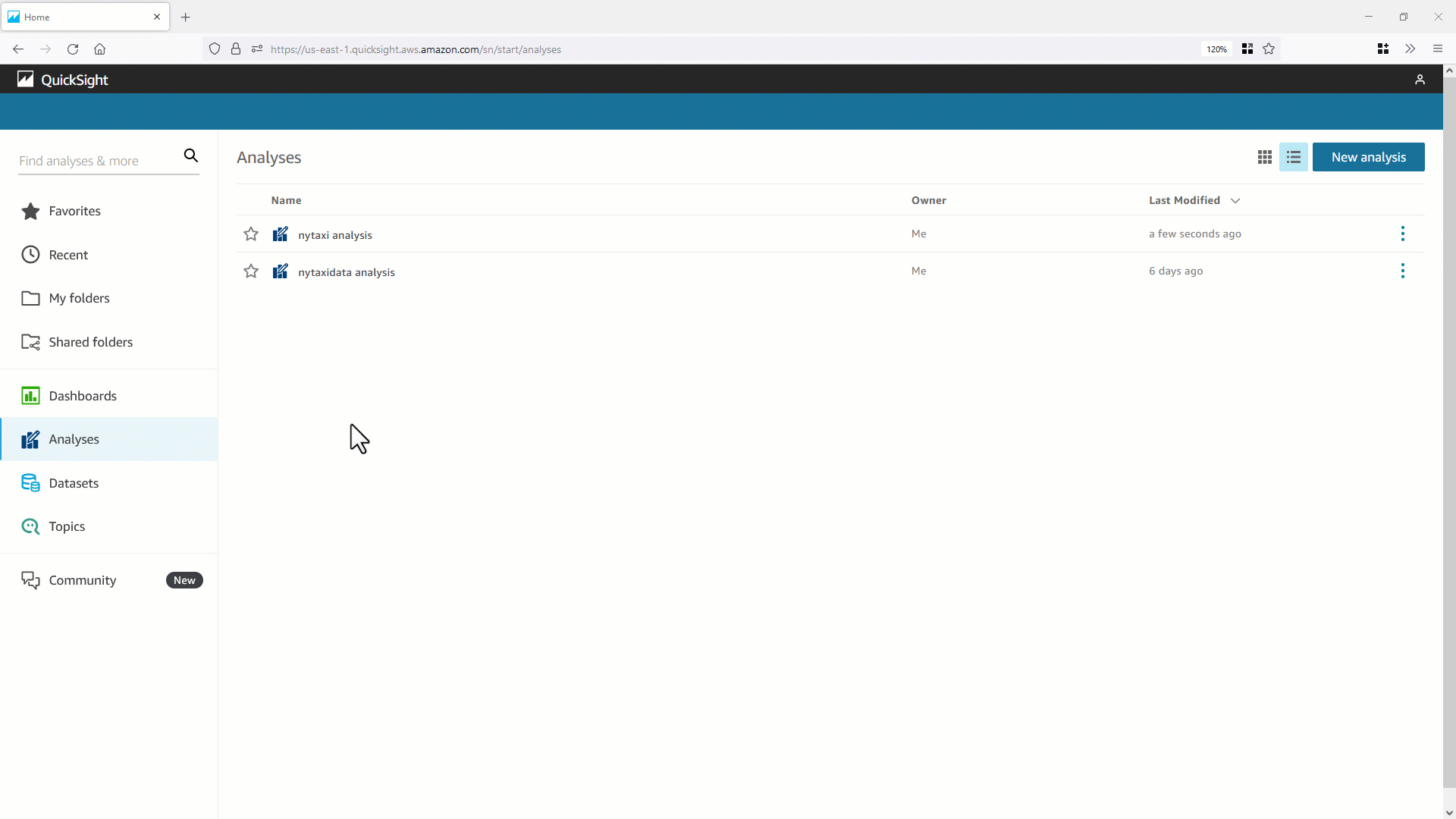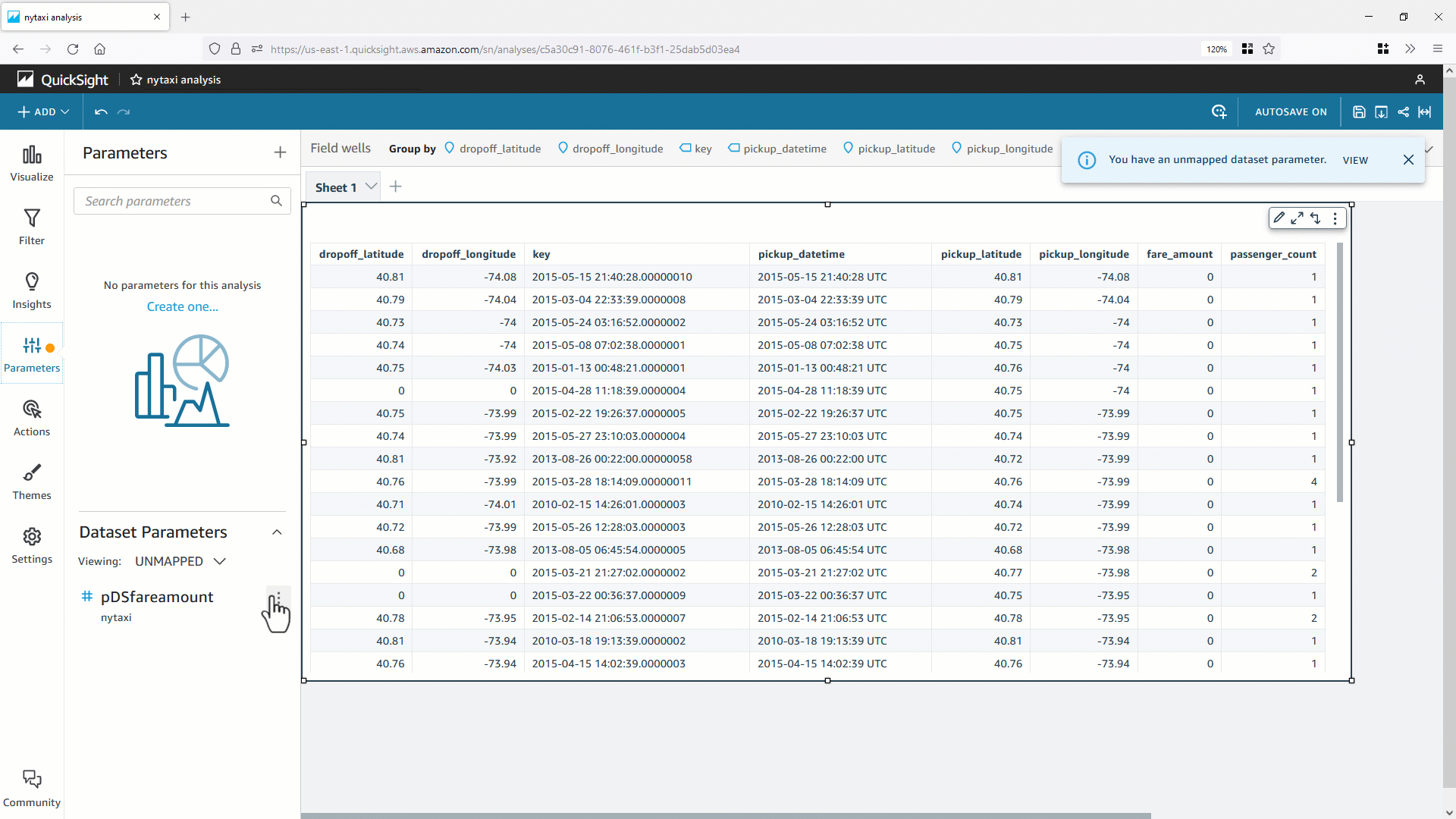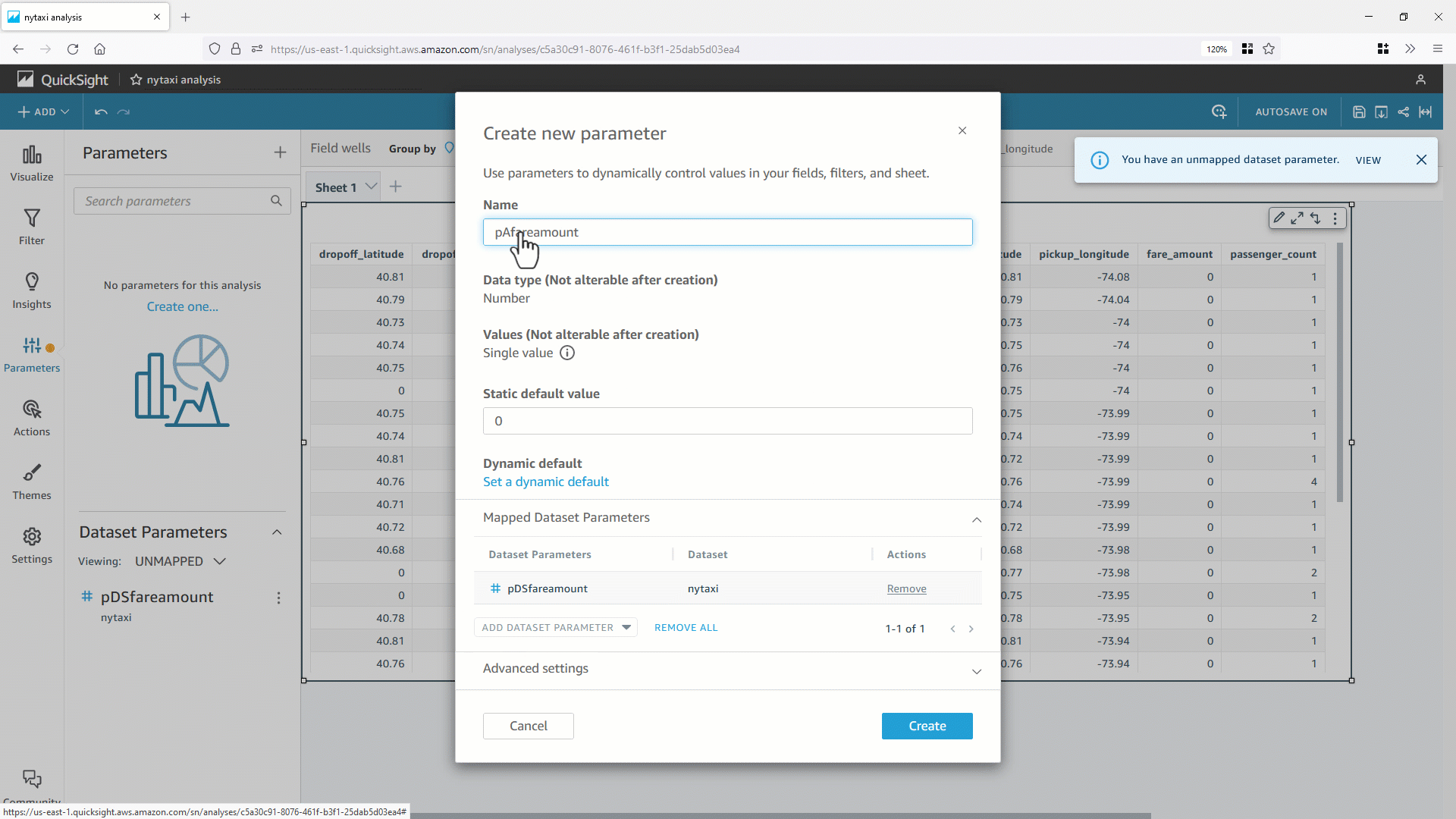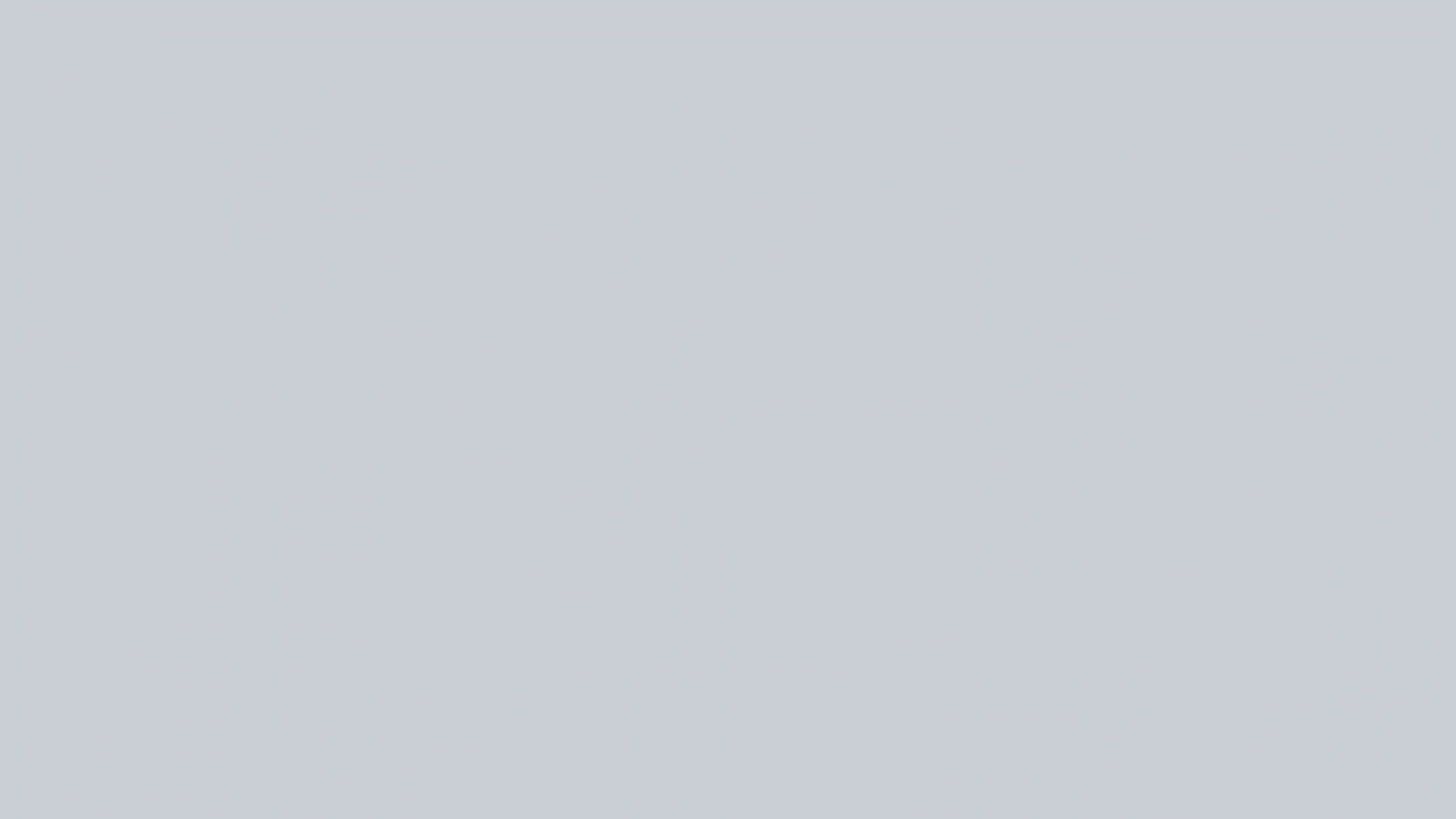
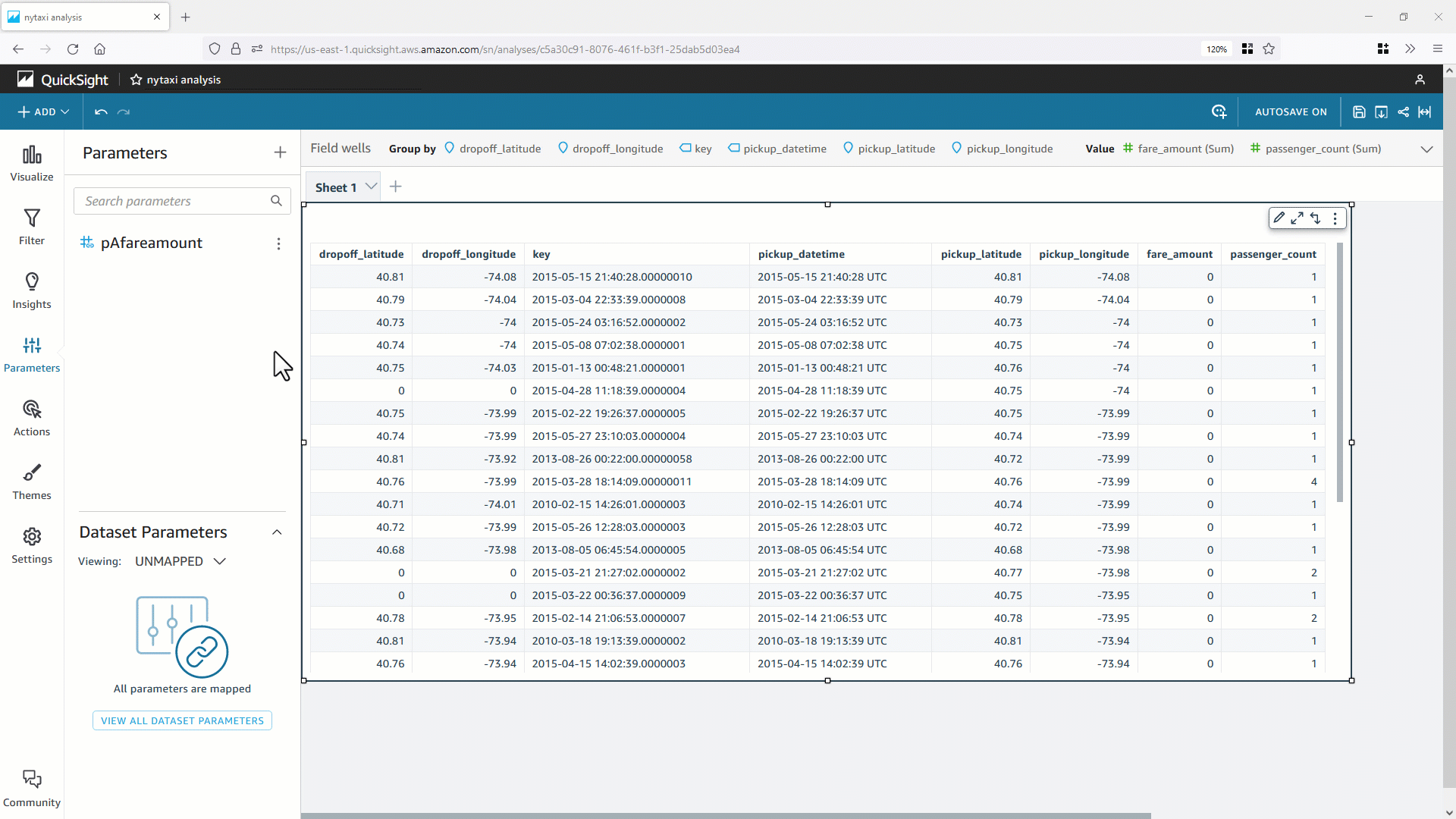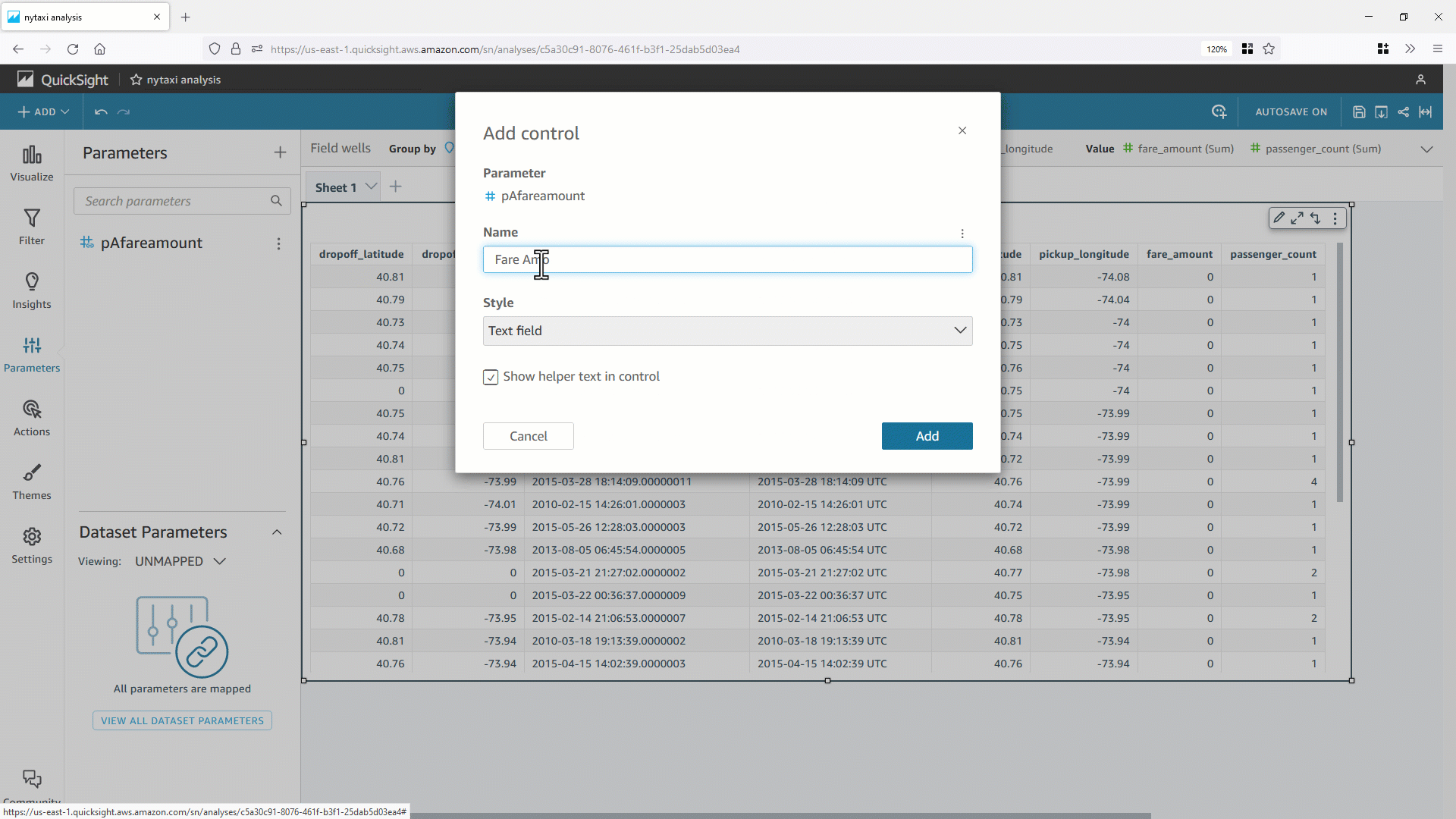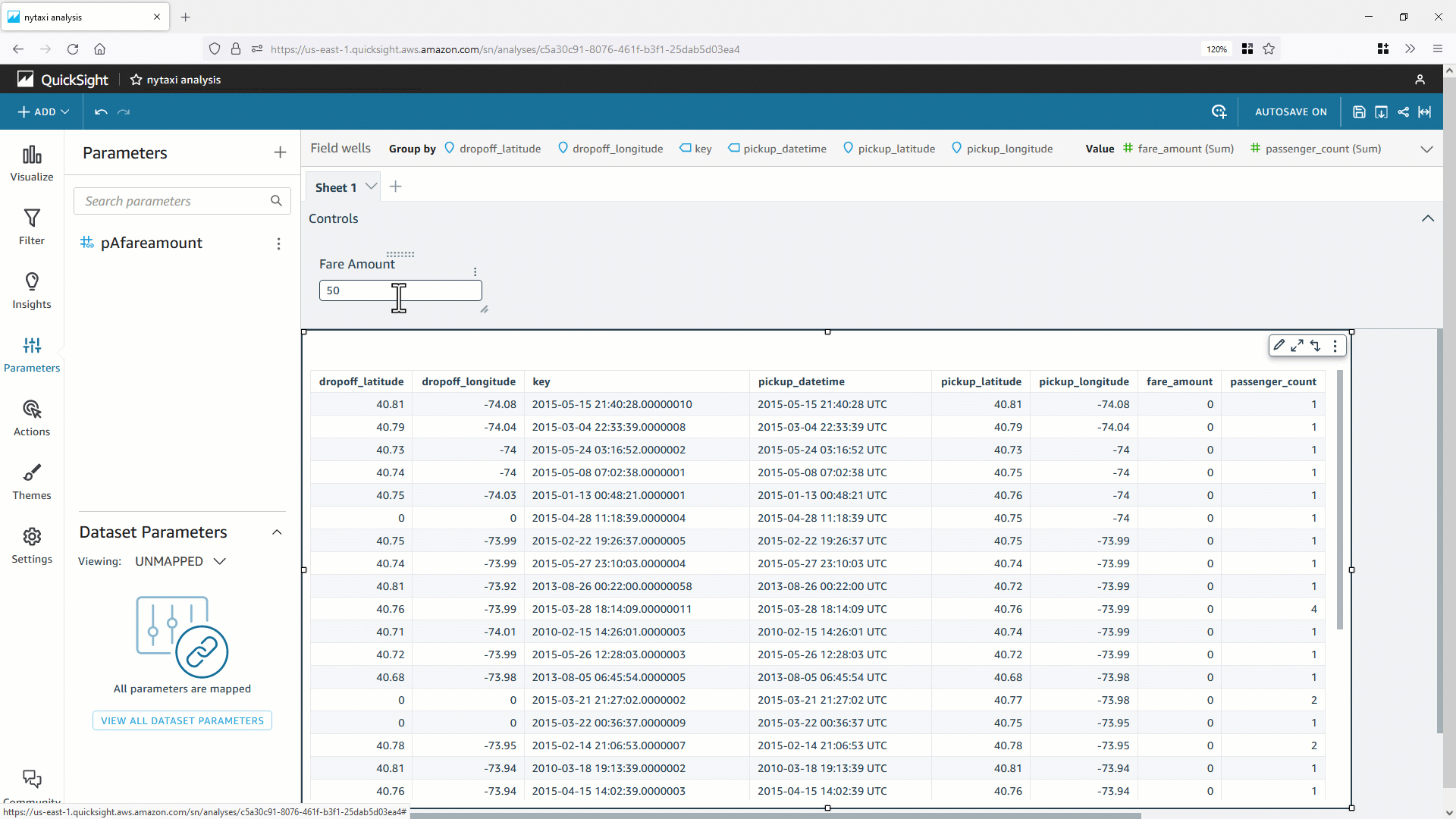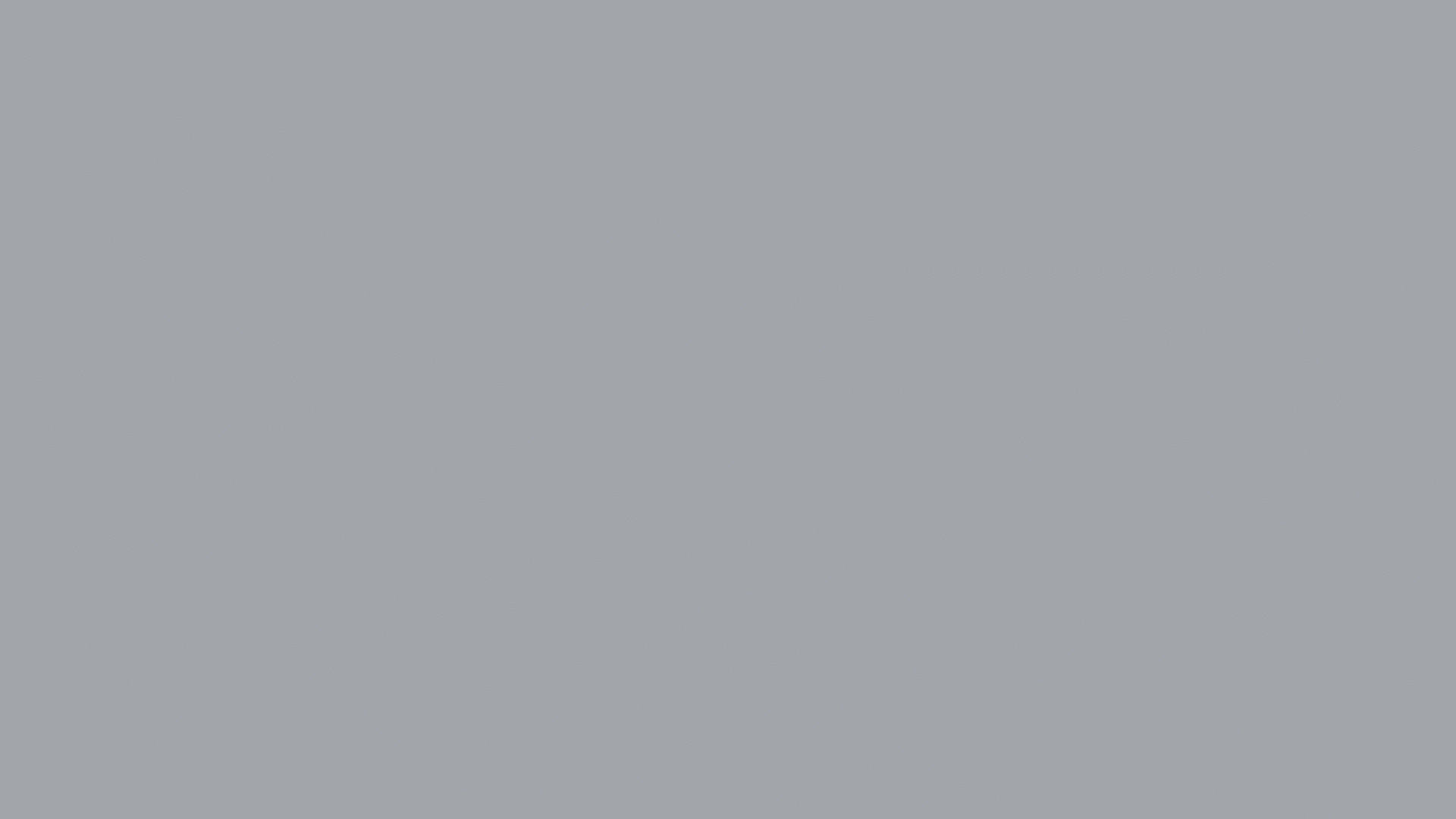
- これで分析パラメータ(この例では
pAfareamount ) が作成されます。パラメータコントロールを使用し、分析またはダッシュボードからデータセットのパラメータ値を動的に変更するために、コントロールオブジェクト Fare Amount を作成します。 pAfareamount を QuickSight のフィルターと関連付けることで、データセットパラメータに値を動的に渡すことができます。パラメータコントロールの値を変更すると、バックエンドのデータベースに対し副問合せ内に WHERE 句が含まれる最適化された SQL が生成されます。
データセットパラメータのさらなる使用例
これまで等号演算子を使用したデータセットパラメータの使い方を見てきましたが、データセットパラメータを使用する別のシナリオをいくつか見てみましょう。
- 次のスクリーンショットは、カスタム SQL 内で比較演算子を用いたデータセットパラメータの使用方法を示しています。
- 次の例は、2 つのデータセットパラメータを BETWEEN 述語とともに使用する方法を示しています。
- 次の例は、計算フィールド内でデータセットパラメータを使用する方法を示しています。
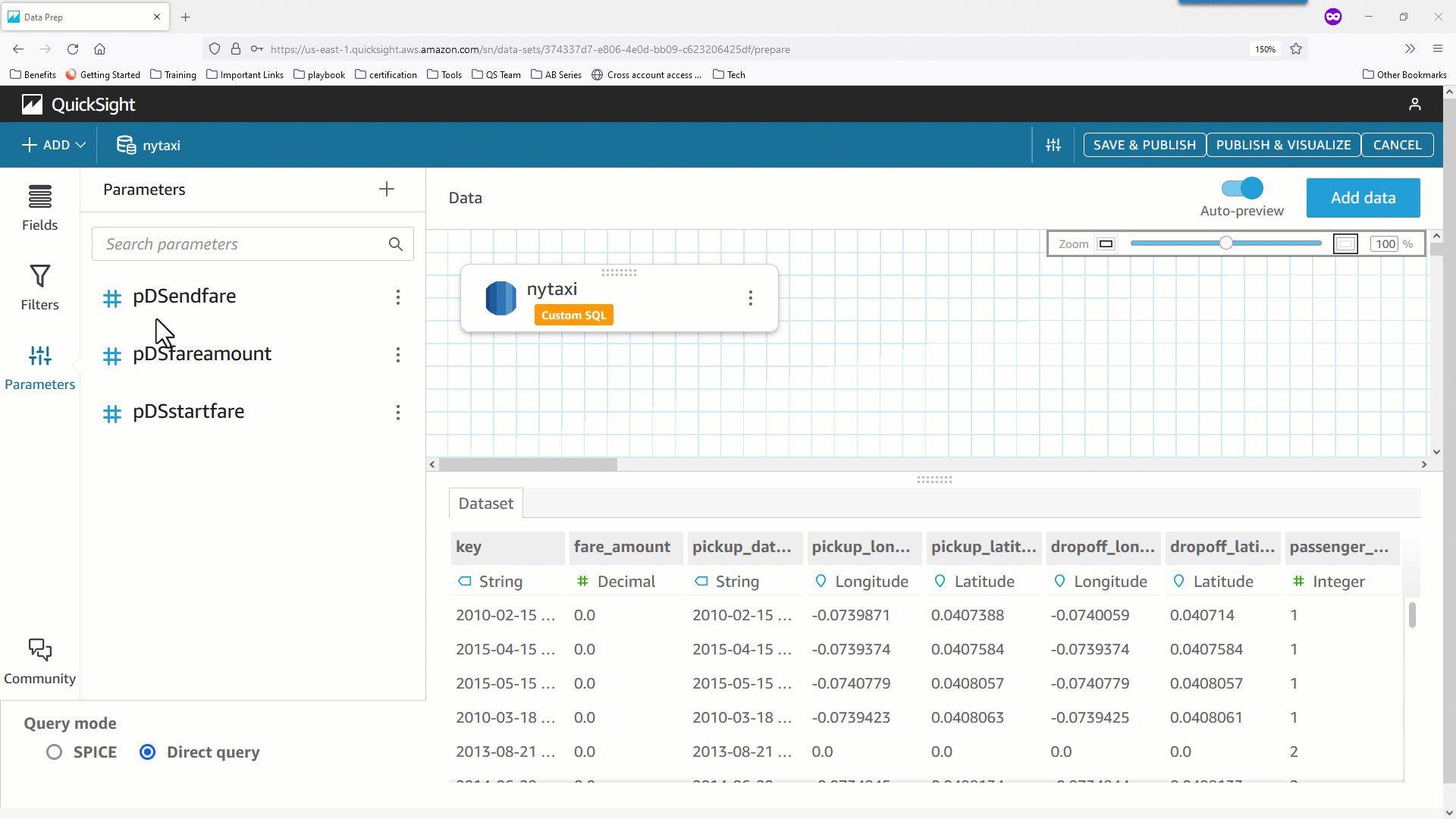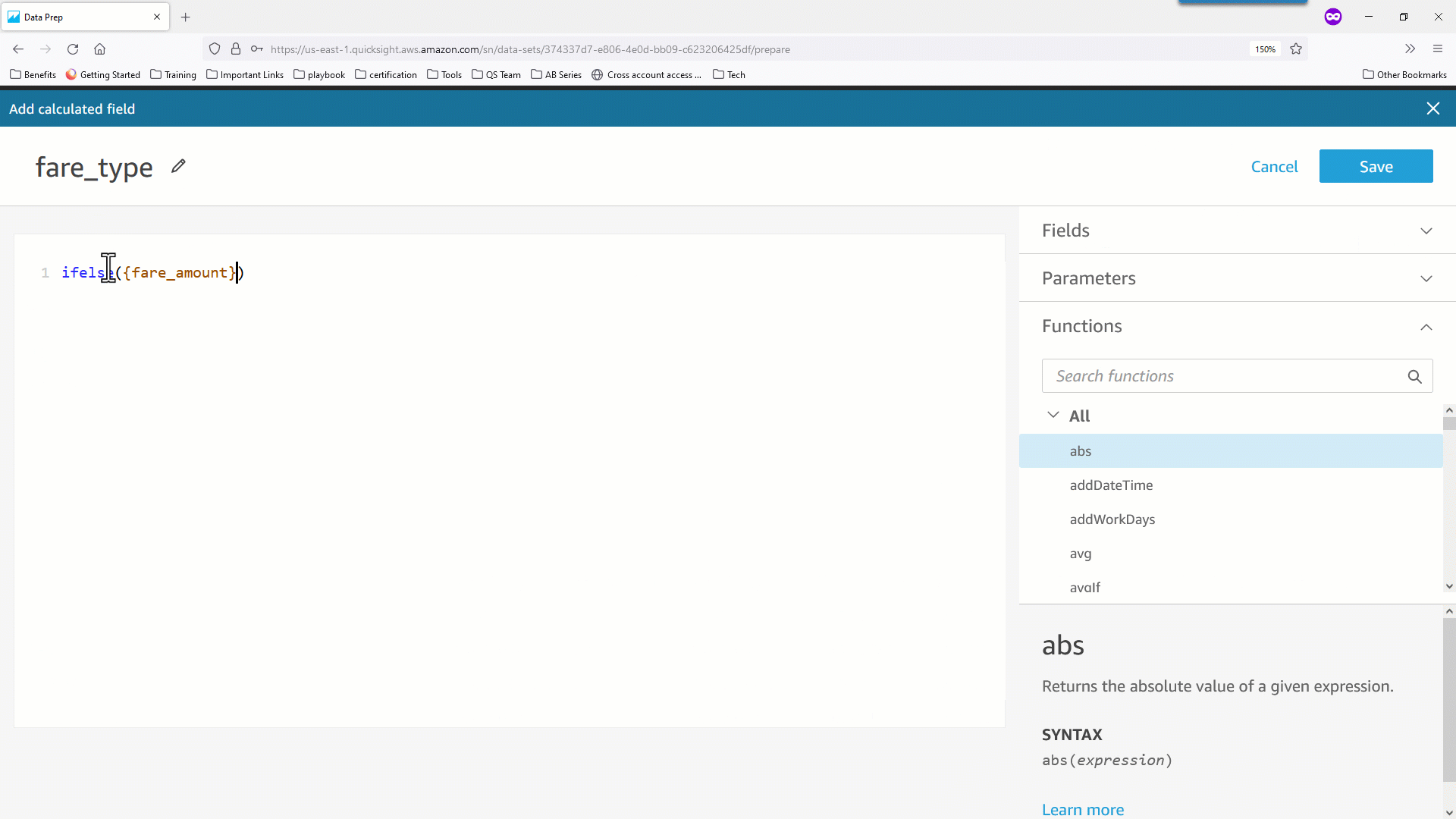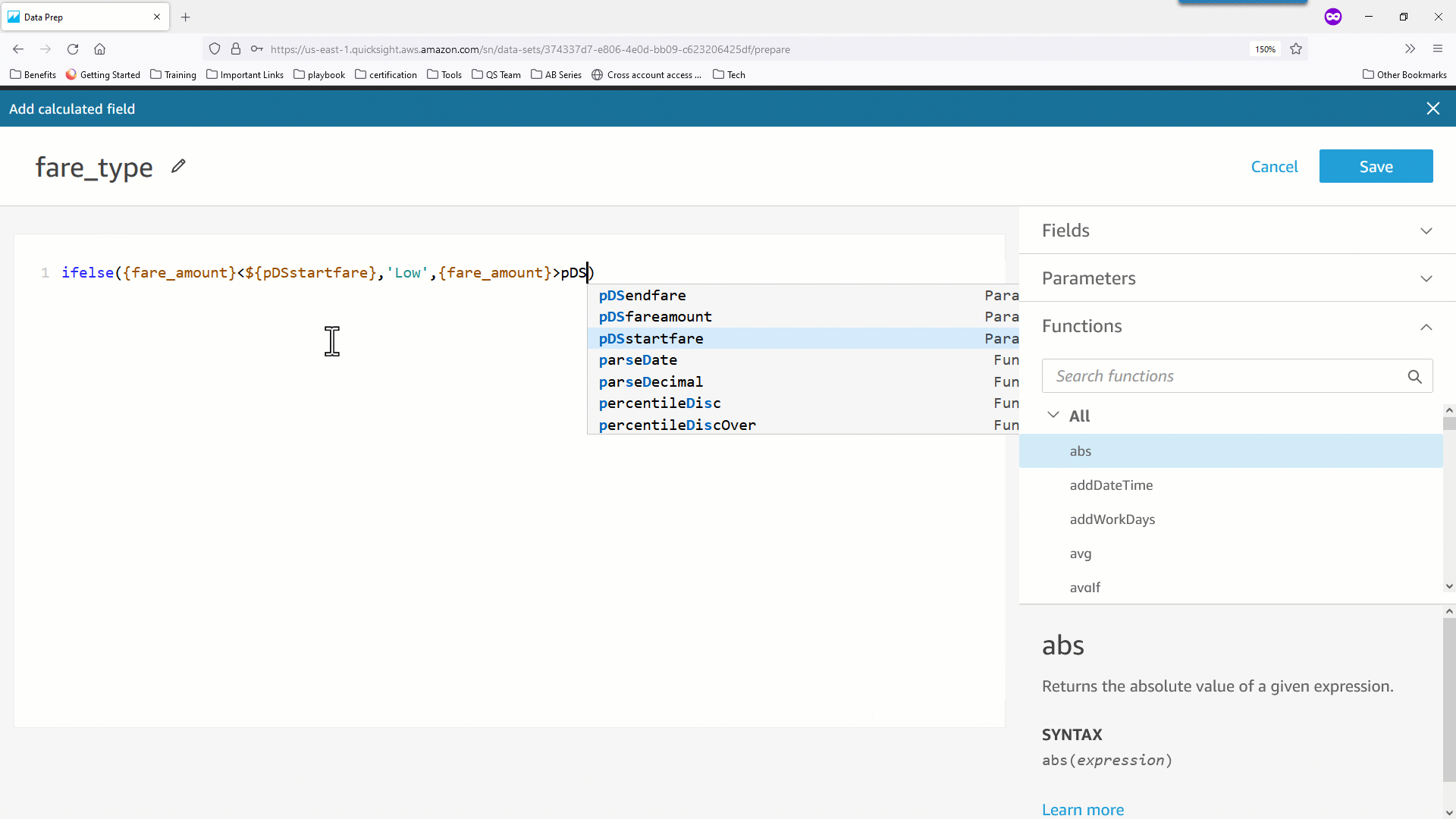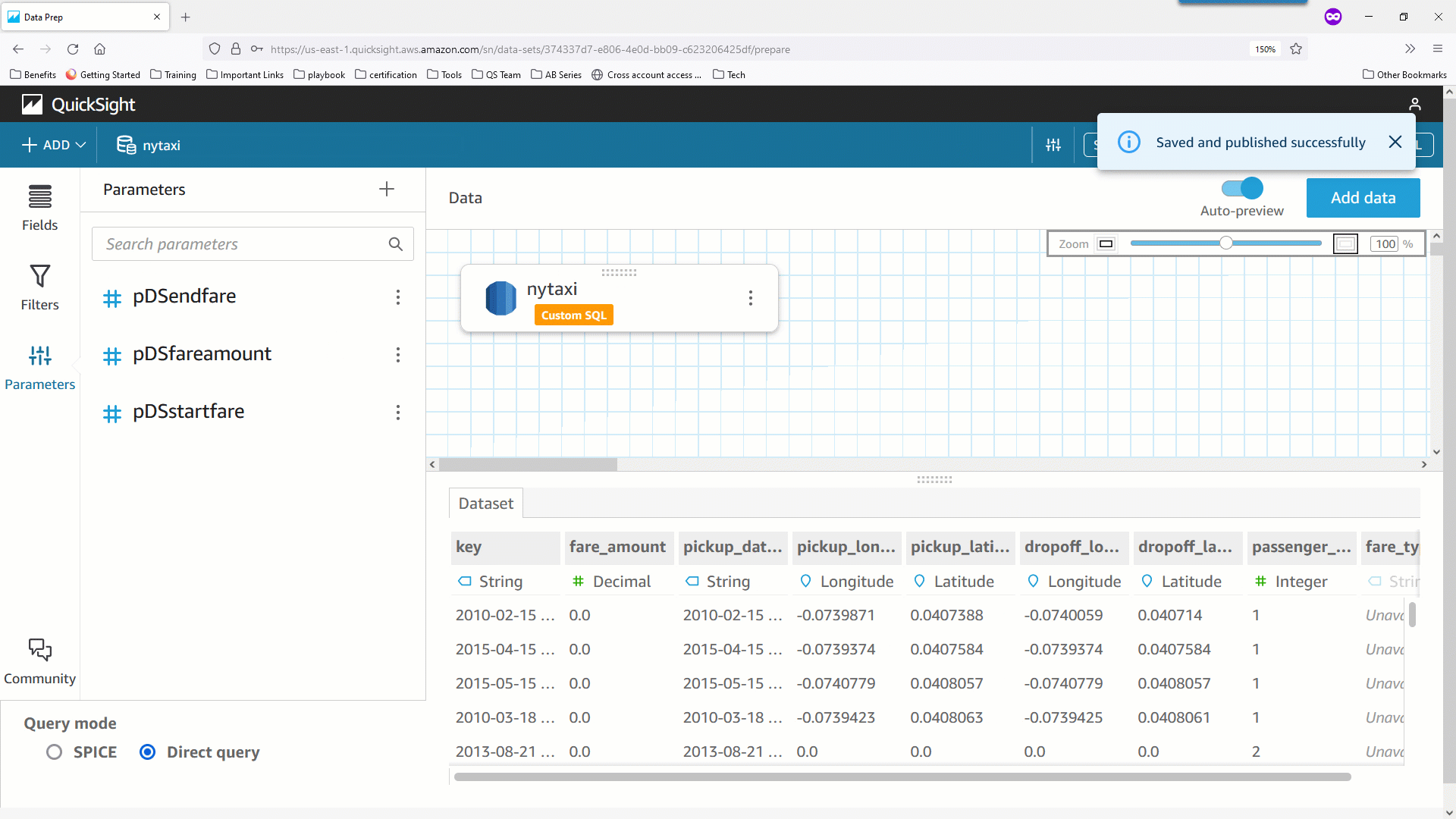
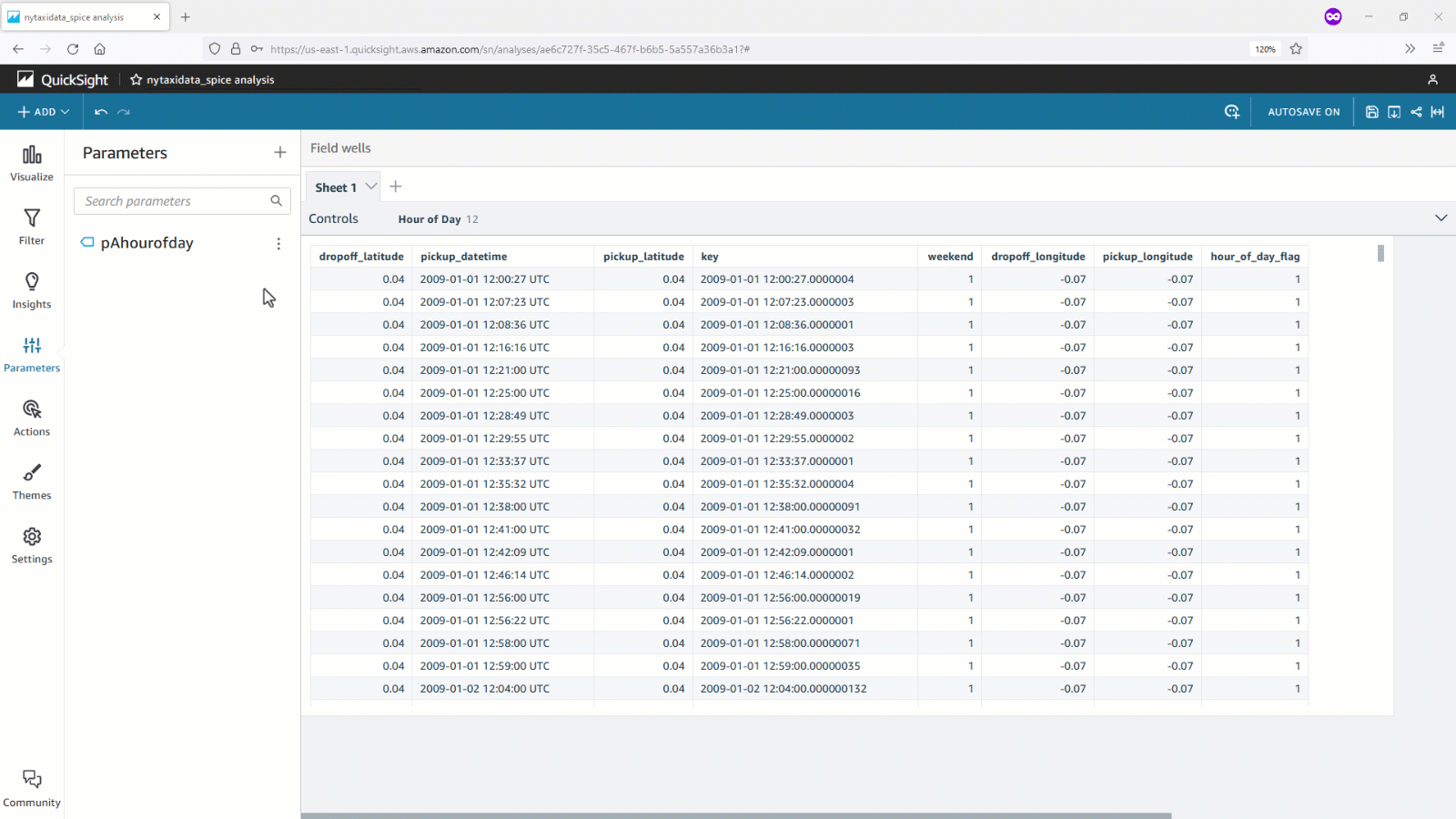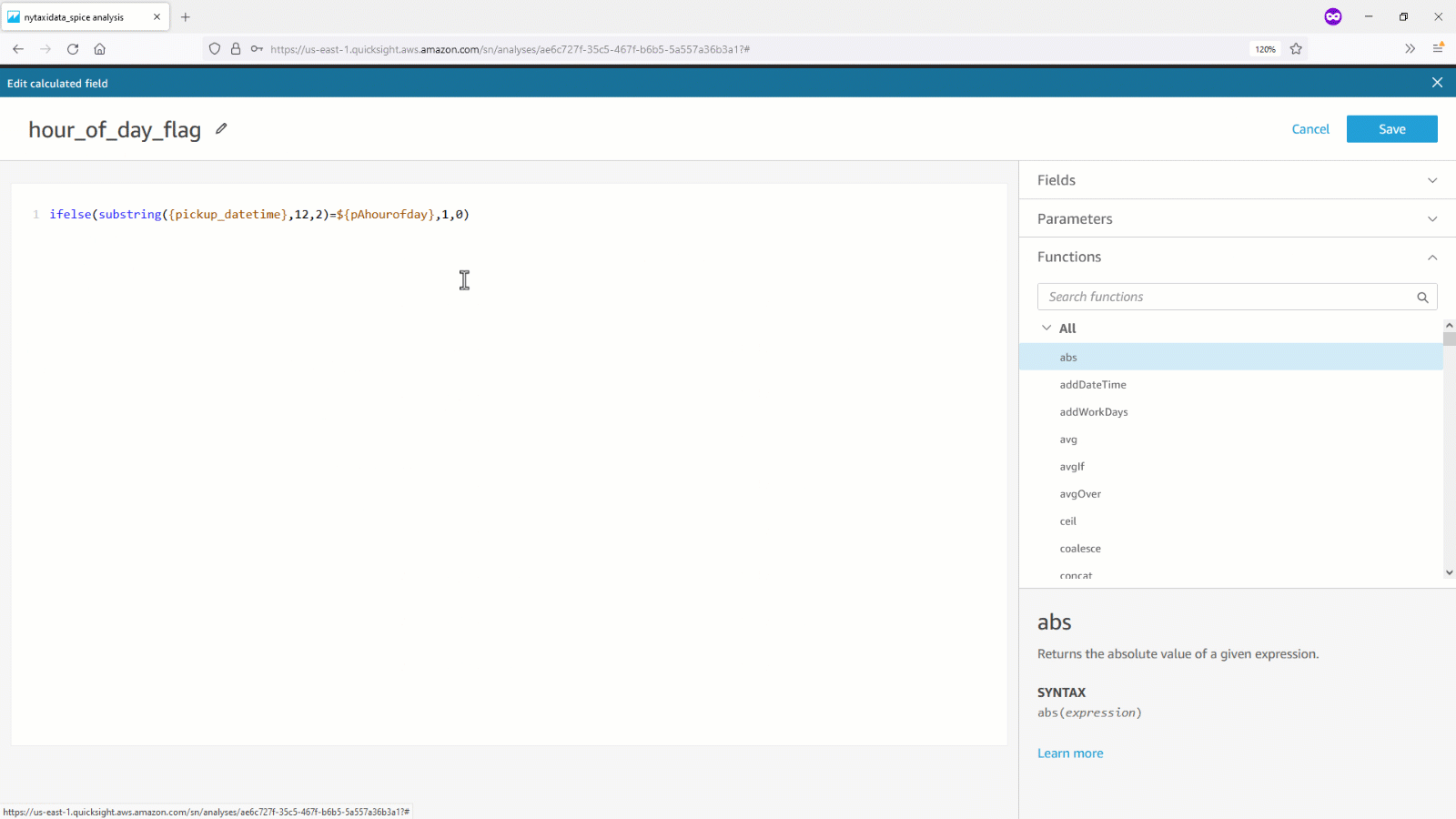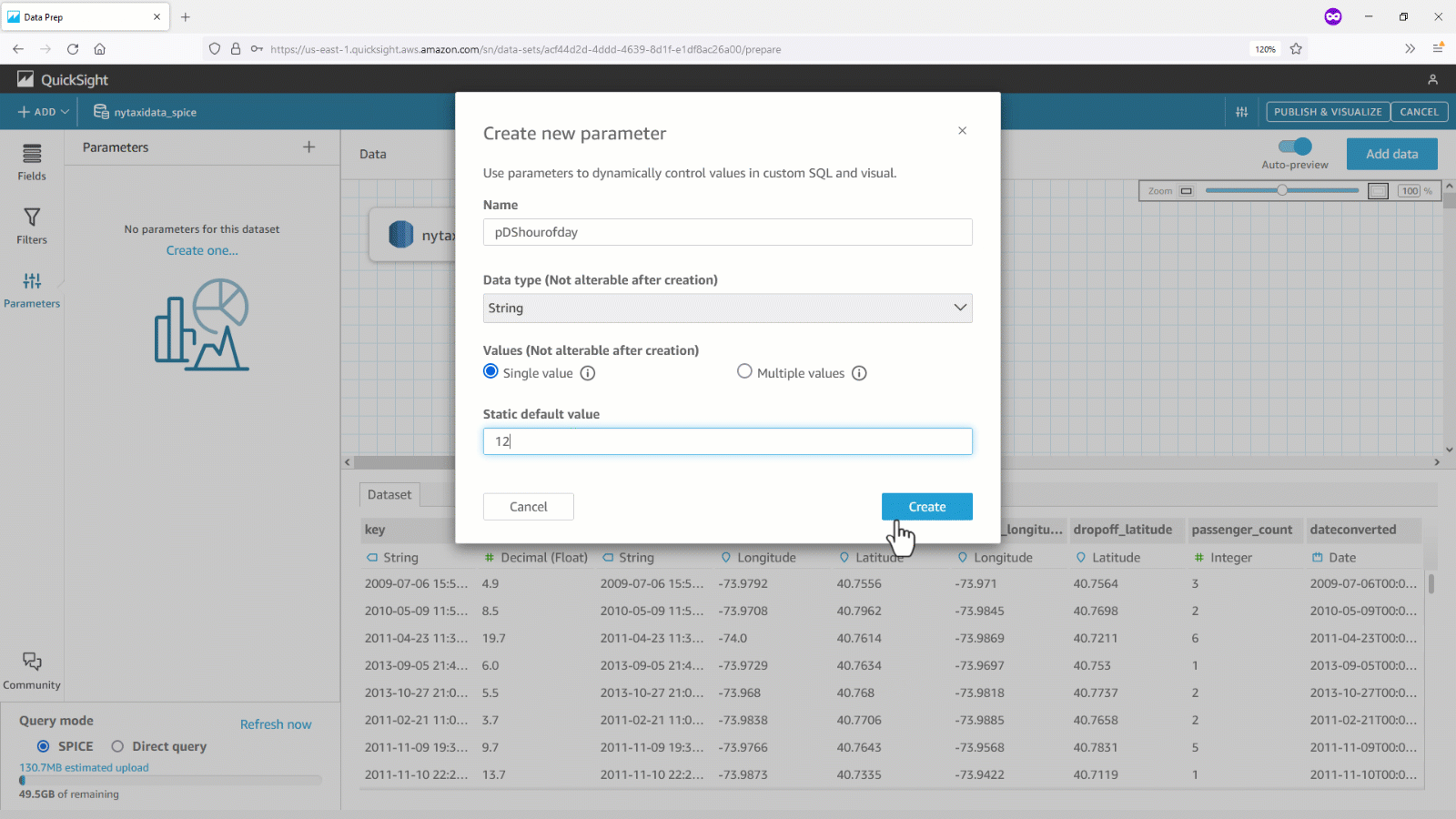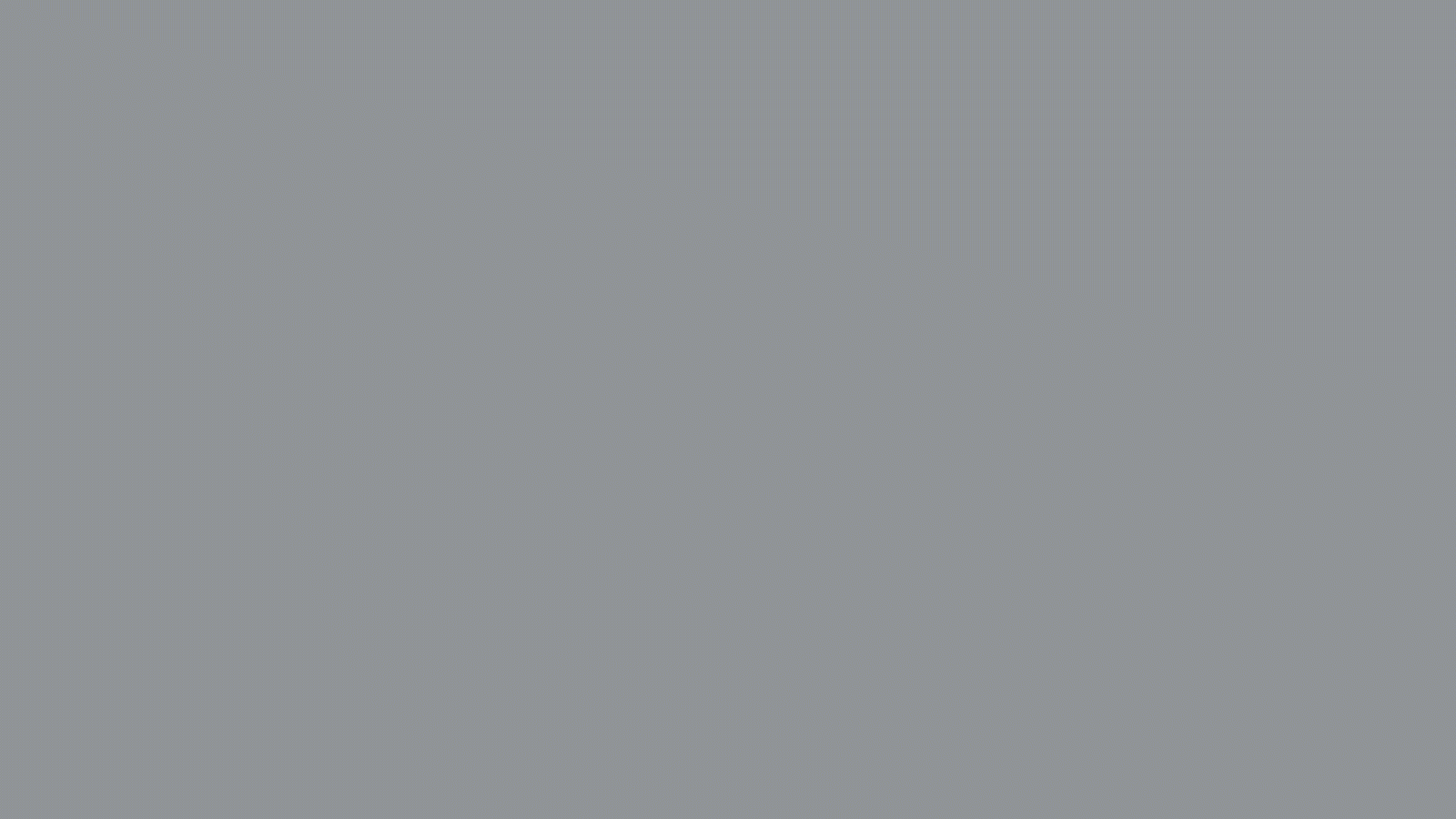
- データセットパラメータはユーザー定義したスカラー関数( UDF )で使用することもできます。次の例では、
pickupdate をパラメータとして受け取り、 pickupdate が祝日かどうかに基づき 0 または 1 のフラグを返す is_holiday(pickupdate) というスカラー関数を定義しています。
- さらに、データセットパラメータを使用して計算項目を導出することもできます。次の例では、実行時に指定された値と乗客数に基づき動的に
surcharge_amount を計算しています。データセットパラメータを CASE 文とともに使用することで求めるべき surcharge_amount を導出していることが分かります。
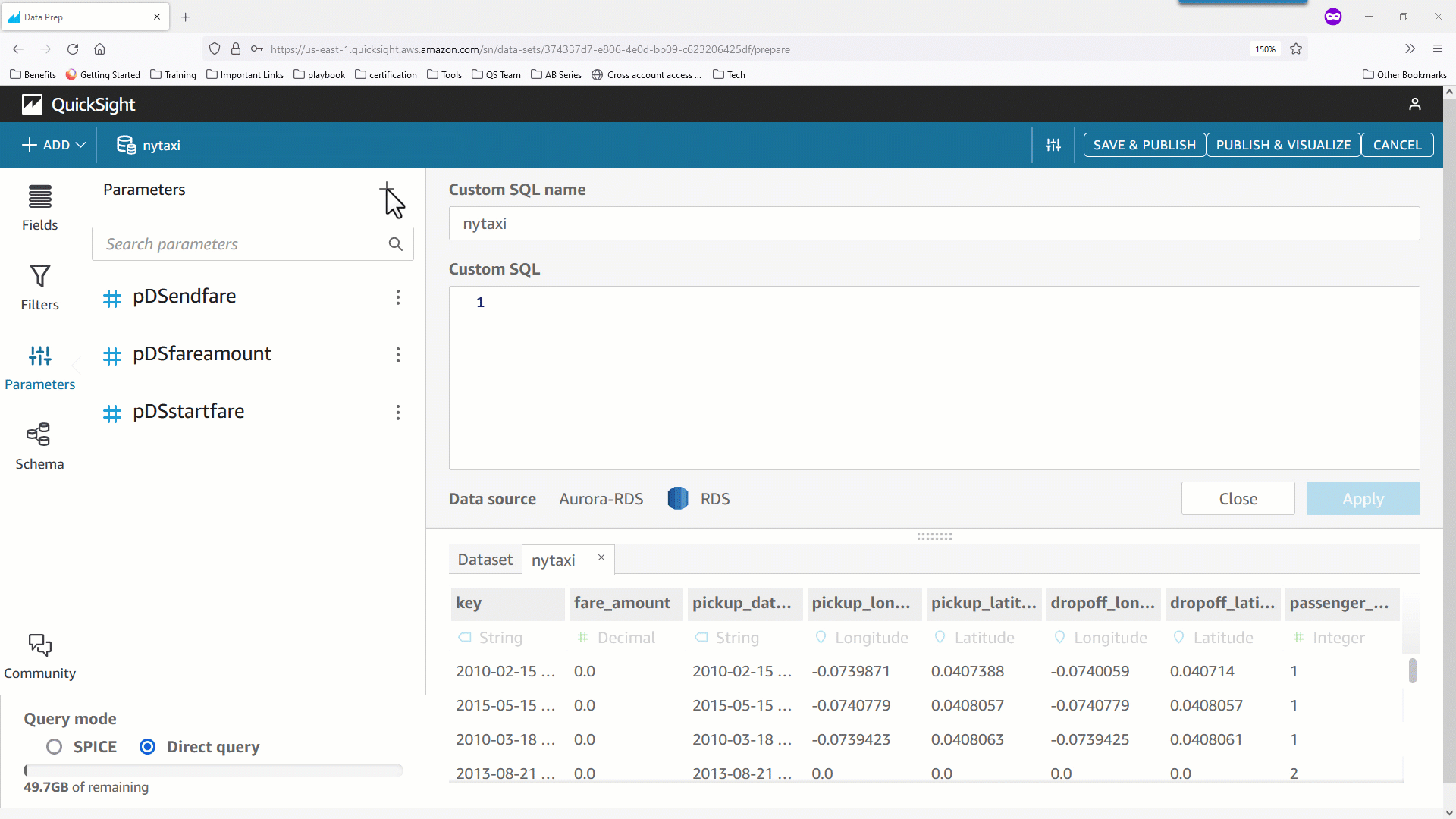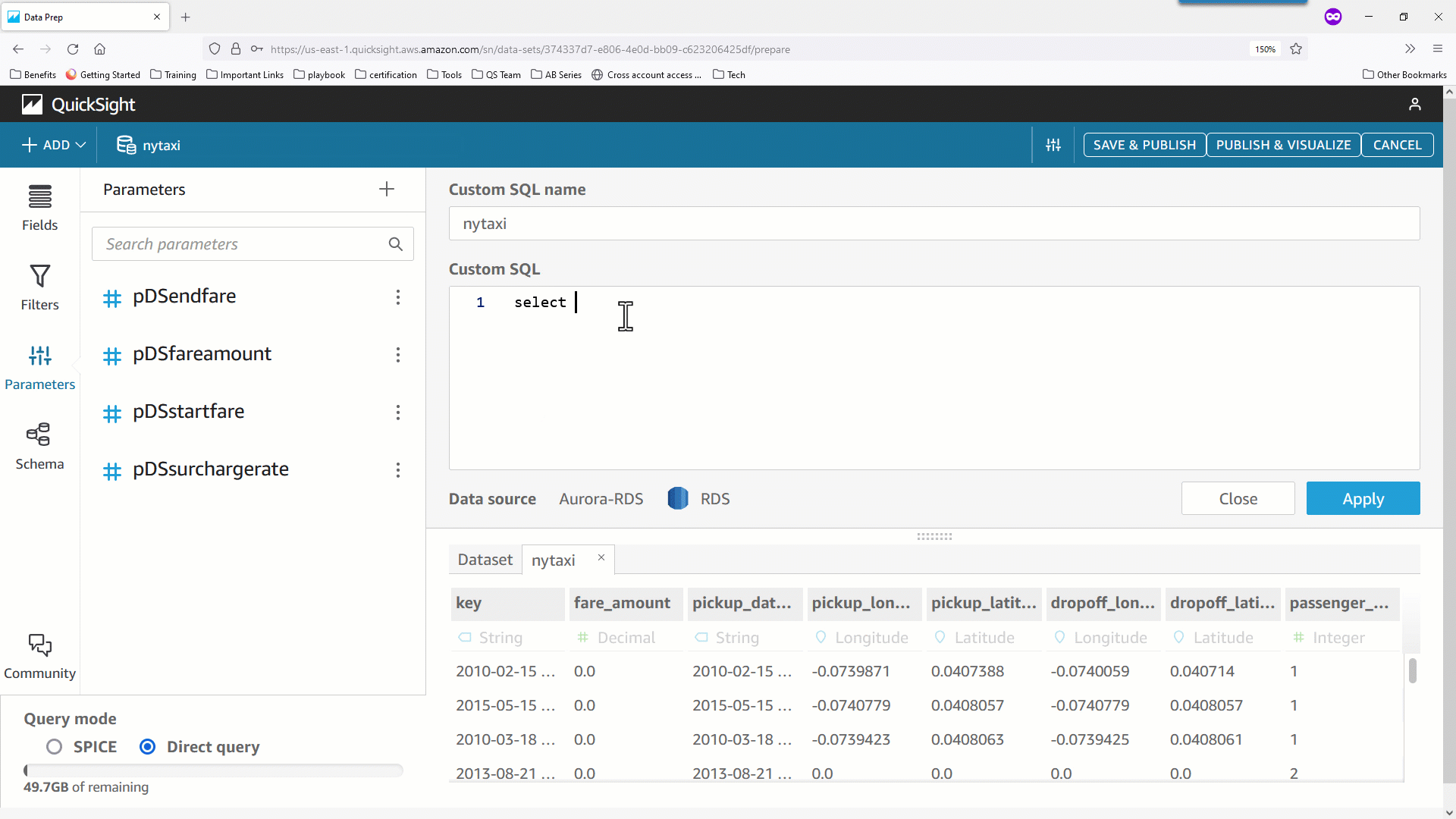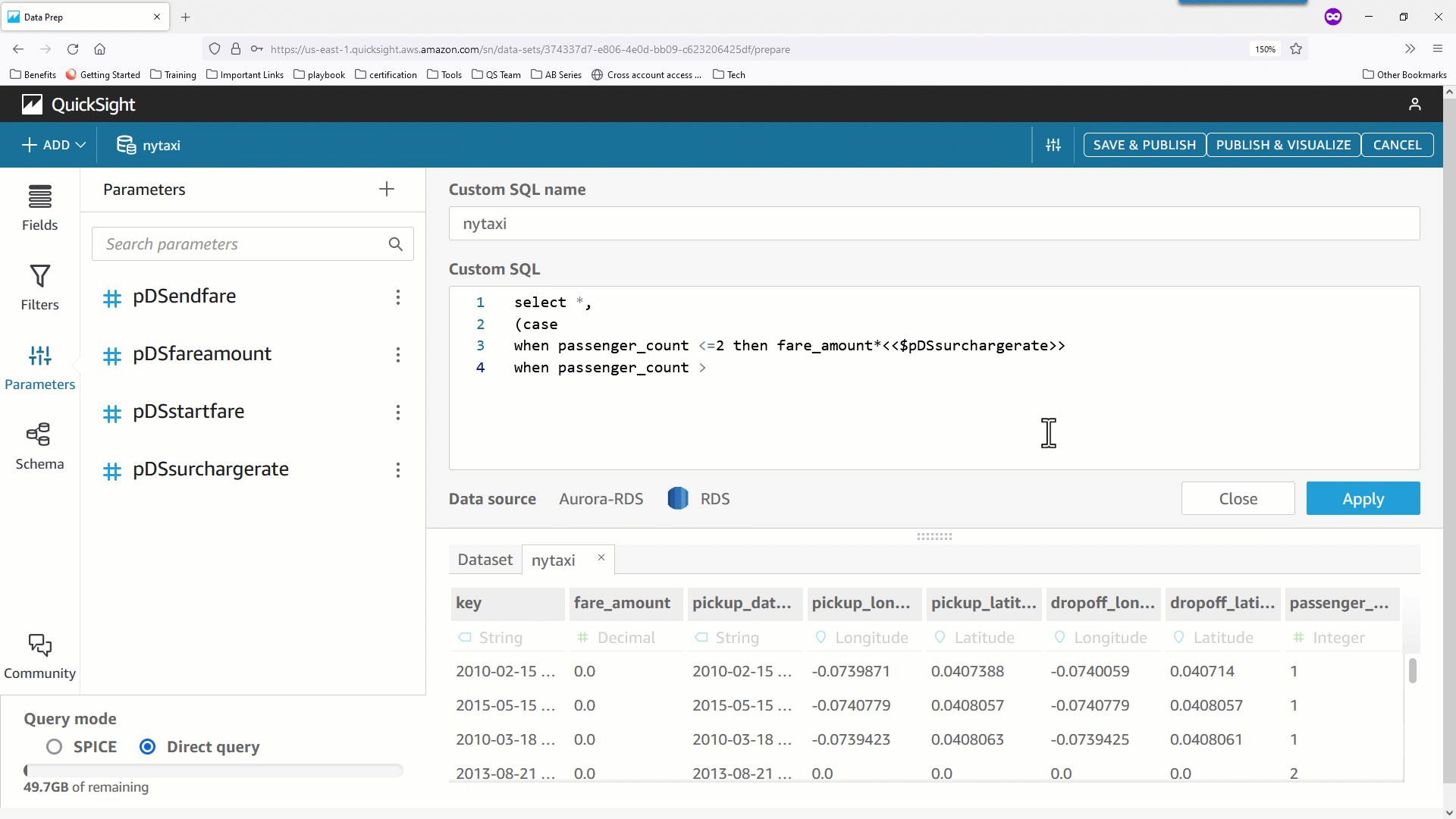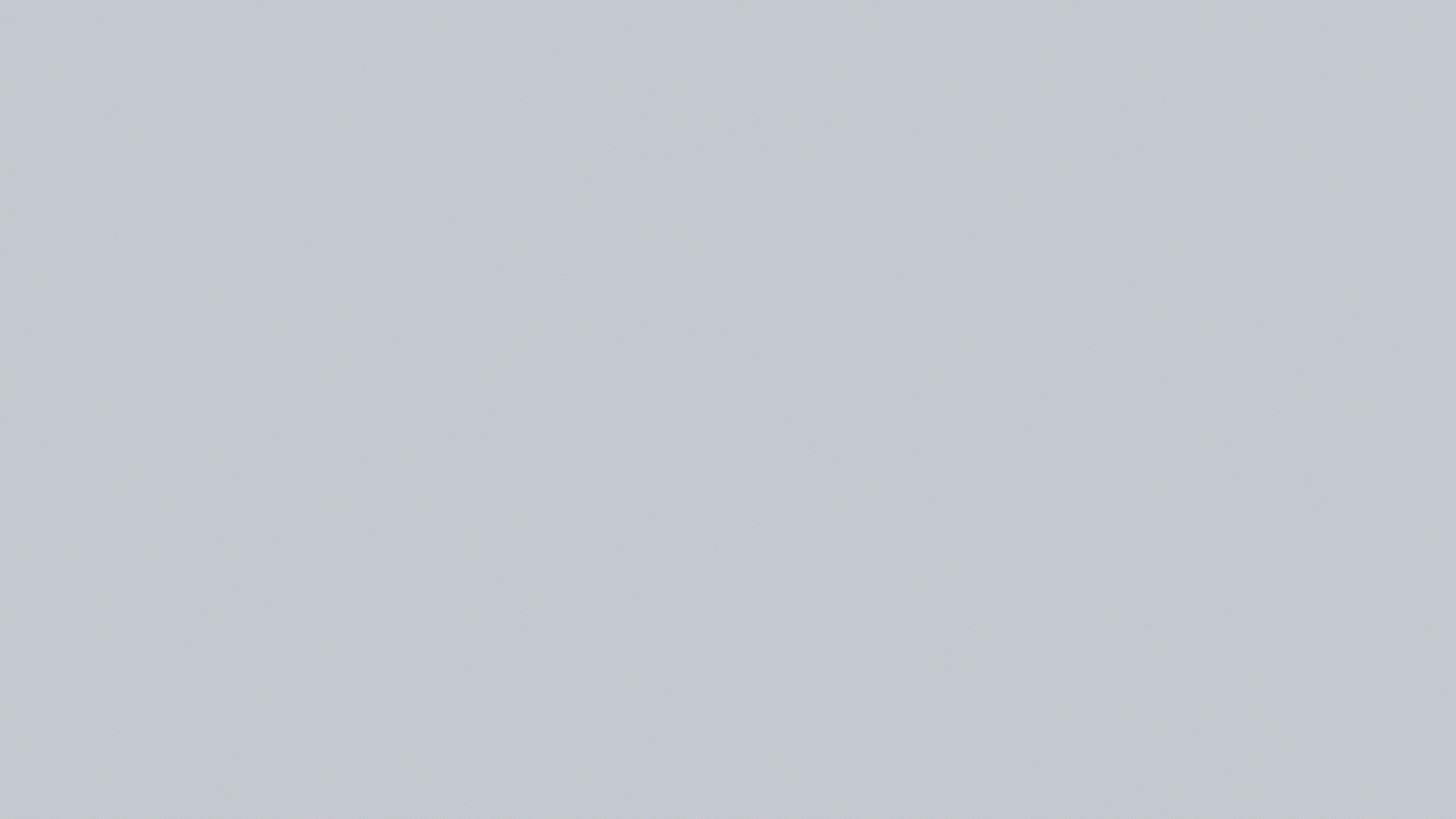
- 最後の例は、分析でパラメータを使用している計算を、データセット側に移動して再利用する手順を示しています。
データセットパラメータの制約
QuickSight でデータセットパラメータを操作する際に生じる可能性のある既知の制約は次の通りです(この原文記事の執筆時点)。
- データセットパラメータは SPICE に保存されているデータセットのカスタム SQL には挿入できません。
- 動的デフォルトは、データセットを使用している分析の分析ページでのみ設定できます。データセットのレベルでは動的デフォルトを設定することはできません。
- データセットパラメータに紐づけられている分析パラメータの複数値コントロールではすべて選択オプションがサポートされていません(ただし、ワークアラウンド はあります)。
- データセットパラメータではカスケードコントロールがサポートされていません。
- データセットパラメータは、データセットが直接クエリを使用している場合にのみ、データセットフィルターとして使用できます。
- ダッシュボード閲覧者がレポートを電子メールで送信するようスケジュールする場合、選択したコントロールは電子メールに添付されたレポート内のデータセットパラメータに反映されません。代わりにパラメータのデフォルト値が使用されます。
より詳細な情報はAmazon QuickSight でのデータセットパラメータの使用をご参照ください。
まとめ
この投稿では、 QuickSight のデータセットパラメータを作成して分析パラメータに紐づける方法を説明しました。データセットパラメータは、最適化された SQL を生成することで、直接クエリ形式のカスタム SQL データセットを使用している QuickSight ダッシュボードのパフォーマンス向上に役立ちます。また、 SQL 比較演算子や計算項目、ユーザー定義されたスカラー関数、CASE文などでデータセットパラメータを使用する例もいくつか紹介しました。
データセットパラメータにより、データセットの所有者は、パラメータに依存する計算フィールドをデータセットレベルで一元的に作成および管理できます。このような計算フィールドは複数の分析で再利用でき、分析作成者が改ざんすることはできません。
QuickSight のデータセットパラメータが皆様のお役に立てば幸いです。我々は既にこの機能がさまざまなユースケースで創造的に活用されている様子を見てきました。既存 QuickSight 環境内の直接クエリ形式のカスタム SQL データセットを確認して最適化できそうな候補を探すか、データセットパラメータのその他の利点を享受できないかご検討頂くことをお勧めします。例えば、パラメータとして異なる値を持つ共通データセットに対し、さまざまなスライス分析(例えば、地域、製品、業種別顧客などの切り口での分析)を行う際、データセットパラメータを用いることでデータセット再利用の恩恵を享受することができます。
レガシーレポートを QuickSight に移行することを検討しているでしょうか?データセットパラメータは、企業の BI 開発者が既にパラメータ化された SQL を含むレガシーレポートを移行する際の作業負荷を軽減するのに役立ちます。これらの SQL は、QuickSight API によりパラメータとともに QuickSight データセットとして自動的に引き継ぐことができます(パラメータでエラーマークが表示された場合はクエリを多少調整することもできます)。
データセットパラメータの詳細については、 Amazon QuickSight でのデータセットパラメータの使用 を参照してください。
また是非 Quicksight コミュニティ に参加してQuickSightについて、質問したり、回答したり、他の人と一緒に学んだり、その他のリソースを探索したりしましょう。
このブログはソリューションアーキテクトの中嶋理人が翻訳しました。原文はこちらです。