Amazon Web Services ブログ
クラウドにヘルスデータを格納し、変換と分析を行う Amazon HealthLake
医療機関が日々必要とする患者情報には、臨床的な所見や家族の病歴から、診断内容と処方箋にいたるまで、膨大な量が含まれます。これらすべてのデータは、患者に関する医療情報の全体像を把握し、より優れた医療サービスを提供できるようにするために使用されます。現在のところ、こういったデータは、さまざまなシステム (電子カルテ、検査システム、医療画像リポジトリなど) の間で、数十種類の互換性のないフォーマットで保存されています。
FHIR (高速医療情報相互運用リソース) などの新しい規格は、このような課題に対処しようとしたものです。この規格では、それらの医療システム間で構造化データを記述および変換に適応した形式が提供されます。しかし、このデータの多くは非構造化情報であり、医療記録 (臨床記録) 、文書 (PDF 形式の検査結果) 、書式用紙 (保険請求) 、画像 (X線、MRI) 、音声 (会話記録) 、時系列データ (心電図) などの形で保存されているため、それらの形式から情報を抽出することは 1 つの課題となります。
医療機関が、これらのデータをすべて収集し、変換 (タグ付けやインデックス作成) 、構造化、分析などのための準備を完了するには、数週間、場合によっては数か月を要することがあります。さらに、そのすべての作業を行うためのコストと運用上の複雑さは、ほとんどの医療機関で許容しきれないものとなります。

この度、当社では、Amazon HealthLake を発表できる運びとなりました。これは、HIPAA 適合の完全マネージド型サービス (現在はプレビュー版) であり、医療関係およびライフサイエンスのお客様は、さまざまな形式でサイロ化された医療情報を、一元化された AWS データレイクに集約するためにご利用いただけます。HealthLake では、機械学習 (ML) モデルにより医療データの正規化が行われます。医療データ内の意味のある情報が自動的に理解され抽出されるので、すべての情報が簡単に検索できるようになります。その後、お客様はデータに対しクエリと分析を行い、関連性の把握や傾向を割り出したりしながら、それらを予測に利用することができます。
仕組み
Amazon HealthLake を使用することで、オンプレミスのデータを AWS クラウドにコピーします。クラウドに保存された構造化データ (検査結果など) と非構造化データ (カルテなど) には、HealthLake により、FHIR に対応したタグ付けや構造化が行われます。すべてのデータは、標準的な医療用語を使用して完全にインデックス化されるため、患者の医療情報の照会や検索、分析、および更新が、すばやく簡単に実行できます。

HealthLake を使用する医療機関は、患者の医療情報の収集と変換を数分の内に完了し、その治療履歴を包括的に表示できるようになります。この情報は、業界標準の FHIR 形式で構造化されるので、検索とクエリのための強力な機能を利用できます。
AWS マネジメントコンソールから HealthLake API を使用すると、医療機関はオンプレミスの医療データを、安全な AWS のデータレイクに対し、数回のクリックだけでコピーできます。使用中のソースシステムが FHIR 形式でデータを送信できる構成ではない場合は、リストから AWS パートナーを選択し、レガシーの医療データの FHIR 形式への変換を簡単に依頼することができます。
機械学習によって機能する HealthLake
HealthLake では、自然言語処理 (NLP) など専用の ML モデルを使用することで、生データが自動的に変換されます。これらのモデルに対しては、構造化されていない医療データの中から意味のある情報を理解し抽出するための、トレーニングが実施されています。
例えば HealthLakeでは、治療履歴、診断書、医療画像記録などから、患者情報を正確に識別できます。変換後のデータには、タグ付け、インデックス作成、および構造化が行えます。この機能により、病状、診断結果、処方箋、治療方法などに関する標準的な用語での検索が可能になります。
こういったような、数万件におよぶ患者記録に対するクエリも、非常に簡単に実行できます。医療機関は、例えば病名に関する標準リストから “糖尿病” を選択し、治療メニューからは “経口薬” を選択し、さらに性別を指定しながら検索をすることで、薬剤の類似性に基づいた糖尿病患者のリストを作成することができます。
また、Amazon SageMaker の Juypter Notebook テンプレートを使用する医療機関では、診断結果や再入院の確率の予測、あるいは手術室の使用率などの予測といった一般的なタスクのために、正規化されたデータの分析を迅速かつ簡単に実行できます。これらのモデルは、医療機関が病気の発症を予測するのにも役立ちます。例えば、事前に構築済みのノートブックでの数回のクリックだけで、治療履歴データに ML を適用することができるので、医療機関では、糖尿病患者が今後 5 年間で高血圧を発症するかもしれない時期を予測することが可能です。またオペレータは、AWS マネジメントコンソールから直接 Amazon SageMaker を使用して、データに対して独自の ML モデルを構築、トレーニング、デプロイすることもできます。
独自のデータストアを作成してテストをしてみる
HealthLake の使用開始は簡単です。AWS マネジメントコンソールにアクセスし、[Create a datastore (データストアの作成)] をクリックします。
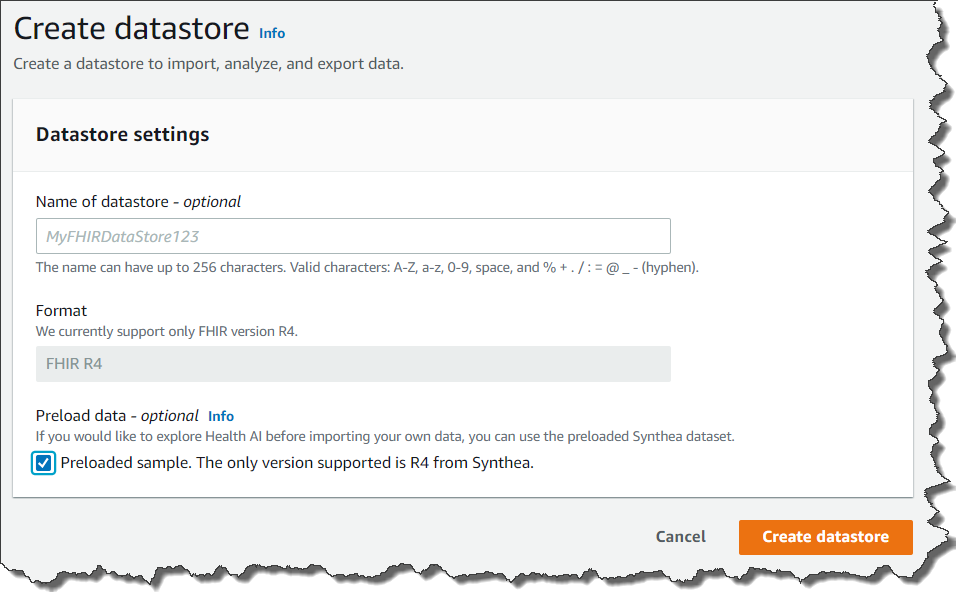 [Preload data (データを事前ロード)] をクリックすると、テストデータが HealthLake によりロードされるので、機能のテストを開始できます。FHIR 4 に準拠した既存のデータをお持ちであれば、それを独自のデータとしてアップロードすることもできます。このデータは、S3 バケットにアップロードした上で、バケット名を設定しながらインポートして使用します。
[Preload data (データを事前ロード)] をクリックすると、テストデータが HealthLake によりロードされるので、機能のテストを開始できます。FHIR 4 に準拠した既存のデータをお持ちであれば、それを独自のデータとしてアップロードすることもできます。このデータは、S3 バケットにアップロードした上で、バケット名を設定しながらインポートして使用します。
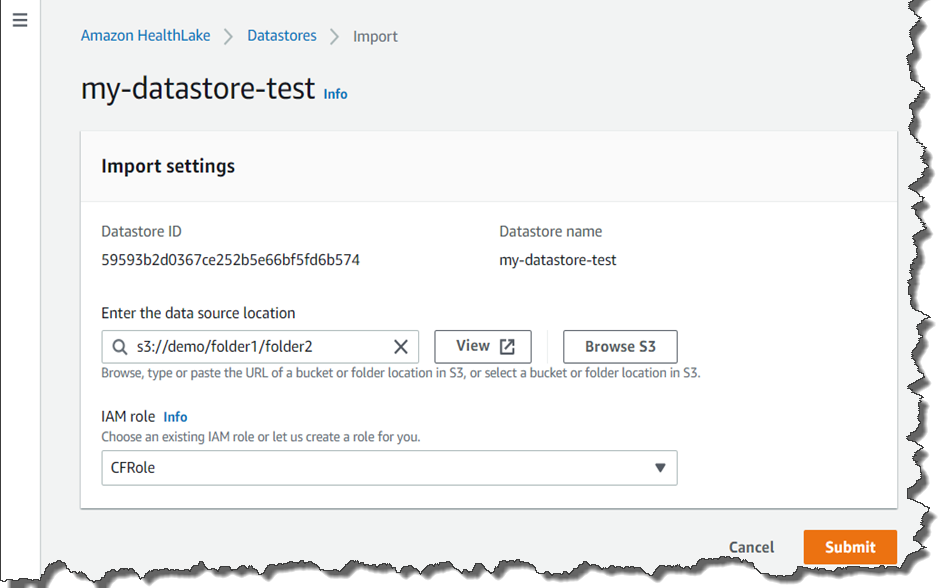
データストアが作成されたら、検索、作成、読み出し、更新、または削除などの、FHIR のクエリ操作を実行できます。たとえば、ニューヨークにいるすべての患者のリストが必要な場合、クエリの設定は次のスクリーンショットのようになります。FHIR の仕様に従って、削除されたデータは解析や結果から非表示になるだけです。サービスから削除されることはなく、バージョンの更新だけが行われます。

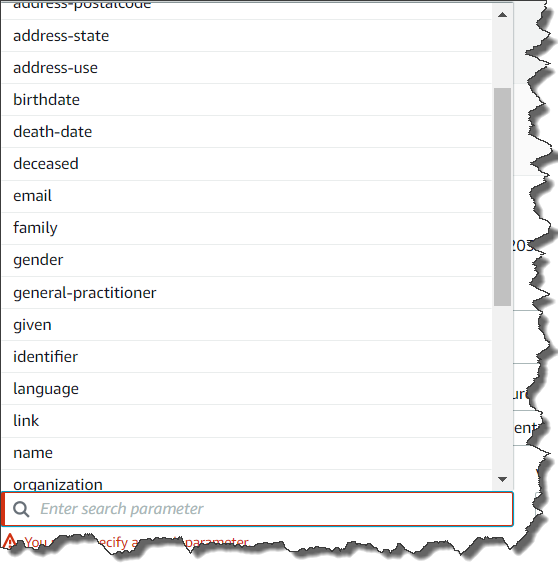
次に示すように、[Add search parameter (検索パラメータを追加)] を選択することで、より多くの条件がネストされたクエリを実行できます。
Amazon HealthLake はプレビュー版で提供中
現在のところ、Amazon HealthLake は、米国東部 (バージニア北部) でプレビュー提供が開始されています。詳細については、当社のウェブサイトでご確認ください。
– Kame