Amazon Web Services ブログ
Moovit は、Amazon Redshift クラスターを拡張して毎日何十億ものデータポイントを分析することにより、データレイクアーキテクチャを活用
Amazon Redshift は高速なフルマネージド型クラウドネイティブデータウェアハウスで、標準 SQL や既存のビジネスインテリジェンスツールを使用して、すべてのデータをシンプルかつコスト効率よく分析できます。
Moovit は、Mobility as a Service (MaaS) ソリューションプロバイダーで、都市型モバイルアプリのトップメーカーです。Moovit は、103 か国の 3,200 を超える都市の 8 億人を超えるユーザーに効果的かつ便利に街を歩き回るようにガイドを提供してきて、過去数年間でサービスが飛躍的に成長しました。同社は、1 日あたり最大 60 億の匿名データポイントを収集し、トランジットデータと都市モビリティデータの世界最大のリポジトリに追加します。これは、他では活用されない都市のローカル交通情報をマッピングおよび維持するのを支援する 685,000 人を超える Moovit のローカル編集者のネットワークで支えられています。
Moovit と同様に、今日多くの企業が Amazon Redshift を使用してデータを分析し、データをさまざまな形に変換しています。ただし、データが成長し、さらに重要になるにつれて、企業はデータから貴重な洞察を引き出すためのより多くの方法を模索するようになりました。これには、ビッグデータ分析、多数の機械学習 (ML) アプリケーション、新しいユースケースとビジネスプロセスを促進するさまざまなツールなどがあります。企業はいつでもすべてのデータにどのユーザーもアクセスでき、迅速な回答を得られるようにすることを求めています。これらすべての要件を満たす最適なソリューションは、企業がデータレイクを構築することです。データレイクは、規模を問わず、すべての構造化データ、半構造化データ、および非構造化データを格納できる中央リポジトリです。
Amazon Simple Storage Service (Amazon S3) で構築されたデータレイクを用いると、Amazon EMR や AWS Glue などのサービスを使用してビッグデータ分析を簡単に実行できます。Amazon Athena や Amazon Redshift Spectrum を使用して、構造化データ (CSV、Avro、Parquet など) および半構造化データ (JSON や XML など) をクエリすることもできます。また、Amazon SageMaker などの ML サービスでデータレイクを使用して、洞察を得ることもできます。
Moovit は Amazon Redshift クラスターを使用して、さまざまな企業のチームが膨大な量のデータを分析できるようにしています。チームは、収集したデータをデータレイクに拡張し、追加の分析チームがより多くのデータにアクセスして新しいアイデアやビジネスケースを探索できるようにする方法を求めていました。
さらに、Moovit はストレージコストを管理し、よりクールなデータを S3 で最も低いコストで維持できるモデルに進化させ、最も効率的なクエリパフォーマンスを実現するために Redshift で最もホットなデータを維持することを目指していました。それに対して、Amazon Redshift Spectrum を使用してホット/コールドストレージパターンを実装し、Amazon Redshift クラスターのローカルディスク使用率を削減して、コストが確実に維持されるようにするソリューションが提案されました。Moovit は現在、マネージドストレージを備えた新しい RA3 ノードには高い柔軟性があると評価しています。これにより、ホット/コールドストレージの量を無制限に簡単にスケーリングできます。
この記事では、AWS のサポートを受けて、Moovit が次のベストプラクティスを採用してレイクハウスアーキテクチャを実装した方法を示します。
- Amazon Simple Storage Service (Amazon S3) へのデータのアンロード
- Amazon Redshift Spectrum を使用してホット/コールドパターンを設定する
- AWS Glue を使用してデータをクロールしてカタログを作成する
- Athena を使用したデータのクエリ
ソリューションの概要
以下の図は、このソリューションのアーキテクチャを示しています。

ソリューションには次の手順が含まれます。
- Amazon Redshift から Amazon S3 にデータをアンロードする
- AWS Glue クローラを使用して AWS Glue データカタログを作成する
- Amazon Athena のデータレイクにクエリを実行する
- Amazon Redshift Spectrum を使用して Amazon Redshift とデータレイクにクエリを実行する
前提条件
このチュートリアルを完了するには、次の前提条件が必要です。
- AWS アカウント。
- Amazon Redshift クラスター。
- 次の AWS のサービスとアクセス: Amazon Redshift、Amazon S3、AWS Glue、Athena。
- Amazon Redshift Spectrum および AWS Glue が Amazon S3 バケットにアクセスするための適切な AWS Identity and Access Management (IAM) アクセス許可。詳細については、「Amazon Redshift Spectrum 用の IAM ポリシー」と「AWS Glue 用の IAM アクセス許可の設定」を参照してください。
チュートリアル
データアーキテクチャ中に Moovit が使用したプロセスを示すために、TPC 組織が一般公開している業界標準の TPC-H データセットを使用します。
Orders テーブルには次の列があります。
| Column | Type |
| O_ORDERKEY | int4 |
| O_CUSTKEY | int4 |
| O_ORDERSTATUS | varchar |
| O_TOTALPRICE | numeric |
| O_ORDERDATE | date |
| O_ORDERPRIORITY | varchar |
| O_CLERK | varchar |
| O_SHIPPRIORITY | int4 |
| O_COMMENT | varchar |
| SKIP | varchar |
Amazon Redshift から Amazon S3 へのデータのアンロード
Amazon Redshift では、Apache Parquet ファイル形式へのデータレイクエクスポートを使用してデータをアンロードできます。Parquet は、分析用の効率的なオープンカラムナストレージ形式です。Parquet 形式は、テキスト形式と比較して、Amazon S3 で最大 2 倍の速さでアンロードし、最大 6 分の 1 のストレージしか消費しません。
Amazon Redshift から Amazon S3 にコールドデータまたは履歴データをアンロードするには、(IAM ロール ARN に代えて) 次のコードのような UNLOAD ステートメントを実行する必要があります。
目的のクエリパターンに基づいて、Amazon S3 スキャンを最小限に抑えるパーティションキーまたは列を定義することが重要です。多くの場合、クエリパターンは日付範囲によるものです。このユースケースでは、o_orderdate フィールドをパーティションキーとして使用しています。
アンロード時のもう 1 つの重要な推奨事項は、ファイルサイズを 128 MB から 512 MB の間に収めることです。デフォルトでは、UNLOAD コマンドは結果をノードスライス (Amazon Redshift クラスターの仮想ワーカー) ごとに 1 つまたは複数のファイルに分割します。これにより、Amazon Redshift MPP アーキテクチャを使用できます。ただし、これにより、すべてのスライスで作成されるファイルが小さくなる可能性があります。Moovit のユースケースでは、PARALLEL ON を使用したデフォルトの UNLOAD により、数十の小さな (数 MB の) ファイルが生成されました。Moovit では、PARALLEL OFF がすべてのスライスの作業を LEADER ノードに集約し、MAXFILESIZE オプションを使用してファイルサイズを制御する単一のストリームとして書き出したため、最良の結果が得られました。
このユースケースに対して行われたもう 1 つのパフォーマンス強化は、Parquet の最小統計と最大統計を使用できるようにすることでした。Parquet ファイルには、行グループごとに min_value および max_value 列の統計があり、これにより Amazon Redshift Spectrum がクエリの範囲外の行グループをプルーニング (スキップ) できます (範囲制限スキャン)。行グループのプルーニングを使用するには、頻繁に使用する列でデータをソートする必要があります。最小/最大プルーニングにより、Amazon S3 からスキャンするデータが少なくなり、パフォーマンスが向上し、コストが削減されます。
データレイクにデータをアンロードした後、Amazon S3 で Parquet ファイルのコンテンツを表示できます (128 MB 未満であると想定)。[Actions] ドロップダウンメニューから、[Select from] を選択します。

これで、AWS Glue クローラを使用してデータカタログを設定する準備が整いました。
AWS Glue クローラを使用してデータカタログを作成する
Athena を使用してデータレイクをクエリするには、データのカタログを作成する必要があります。データカタログは、データの場所、スキーマ、およびランタイムメトリックのインデックスです。
AWS Glue クローラは、データストアにアクセスし、メタデータ (フィールドタイプなど) を抽出し、データカタログにテーブルスキーマを作成します。手順については、「AWS Glue コンソールでのクローラの使用」を参照してください。
Athena でデータレイクをクエリする
クローラを作成したら、AWS Glue と Athena でスキーマとテーブルを確認し、すぐに Athena でデータのクエリを開始できます。次のスクリーンショットは、Athena クエリエディタのテーブルを示しています。
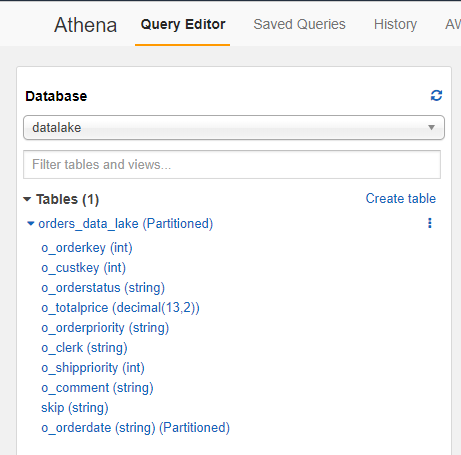
Amazon Redshift Spectrum の統合ビューを使用して Amazon Redshift とデータレイクをクエリする
Amazon Redshift Spectrum は Amazon Redshift の機能で、複数の Redshift クラスターがレイクの同じデータからクエリを実行できるようにします。これにより、レイクハウスアーキテクチャが可能になり、データウェアハウスクエリが他のテーブルと同様にデータレイク内のデータを参照できるようになります。Amazon Redshift クラスターは、SQL クエリが Amazon S3 に保存されている外部テーブルを参照するときに、Amazon Redshift Spectrum 機能を透過的に使用します。Amazon Redshift Spectrum を外部テーブルで使用して行をスキャン、フィルタリング、集計し、Amazon S3 から Amazon Redshift クラスターに返すことにより、大規模な複数のクエリを並列で実行できます。
Moovit はベストプラクティスに従って、すべてのデータを Amazon S3 データレイクに保持し、ホットデータのみを Amazon Redshift に保存することを決定しました。Amazon Redshift Spectrum を使用して、1 つのクエリでホットデータセットとコールドデータセットの両方をクエリできます。
最初のステップは、データカタログのデータベースをマッピングする Amazon Redshift で外部スキーマを作成することです。次のコードを参照してください。
クローラが外部テーブルを作成した後、前に作成したマッピングされたスキーマを使用して Amazon Redshift でクエリを開始できます。次のコードを参照してください。
最後に、ホットデータとコールドデータを結合する遅延バインディングビューを作成します。
まとめ
この記事では、Moovit が Amazon Redshift からデータレイクにデータをアンロードする方法を示しました。そうすることで、組織内の多くのグループに追加でデータを公開し、データを民主化できました。Moovit 内のさまざまなチームがデータにアクセスし、さまざまなツールでデータを分析し、新しい洞察を得ることができるため、データの民主化には大きな利点があります。
その他の利点として、Moovit は、Amazon Redshift で利用されるストレージを削減しました。これにより、クラスターサイズを維持し、Amazon Lakeshift クラスター内のすべての履歴データとホットデータのみを保持することで、追加費用の発生を回避できます。Amazon Redshift クラスターにホットデータのみを保持することで、Moovit がデータを頻繁に削除するのを防ぎ、IT リソース、時間、および労力を節約します。
データウェアハウスをデータレイクに拡張し、ビッグデータ分析および機械学習 (ML) アプリケーションのためにさまざまなツールを活用することを検討している場合は、このチュートリアルでご紹介した方法を試してみることをお勧めします。
著者について
 Yonatan Dolan は、アマゾン ウェブ サービスのビジネス開発マネージャーです。彼はイスラエル在住で、お客様が AWS 分析サービスを利用してデータを活用し、洞察を得て、価値を引き出すのを支援しています。
Yonatan Dolan は、アマゾン ウェブ サービスのビジネス開発マネージャーです。彼はイスラエル在住で、お客様が AWS 分析サービスを利用してデータを活用し、洞察を得て、価値を引き出すのを支援しています。
 Alon Gendler は、アマゾン ウェブ サービスのスタートアップソリューションアーキテクトです。 AWS のお客様と協力して、セキュアで回復力があり、かつスケーラブルで高性能なアプリケーションをクラウドに展開するのを支援しています。
Alon Gendler は、アマゾン ウェブ サービスのスタートアップソリューションアーキテクトです。 AWS のお客様と協力して、セキュアで回復力があり、かつスケーラブルで高性能なアプリケーションをクラウドに展開するのを支援しています。
 Vincent Gromakowski は、アマゾン ウェブ サービスのスペシャリストソリューションアーキテクトです。
Vincent Gromakowski は、アマゾン ウェブ サービスのスペシャリストソリューションアーキテクトです。