Amazon Web Services ブログ
AWS DMS を用いてイベントソーシングとCQRSを利用し、レガシーデータベースをモダナイズする
この記事は、Modernize legacy databases using event sourcing and CQRS with AWS DMS を翻訳したものです。
モノリスからマイクロサービスに移行する場合、モノリスから複数のダウンストリームのデータストアに同じデータを送信しなければならないことがあります。これらには、マイクロサービスが利用するデータベース、データレイクを構築するための Amazon Simple Storage Service(Amazon S3)、または書き込みと読み取りを分割することにより、高トランザクションな書き込み要求と分析用の読み取り要求を実現させるコマンドクエリ責任分離(CQRS)アーキテクチャなどが含まれます。
イベントソーシングは、ソース側の順序つけられた変更不可能なイベントを提供することにより、上記のユースケースを実現します。
ウィジェットの生成を追跡するアプリケーションを例にとってみましょう。このシステムでは、イベントソーシングと CQRS アーキテクチャを実装したものとなります。システム構成例を次の図に示します。
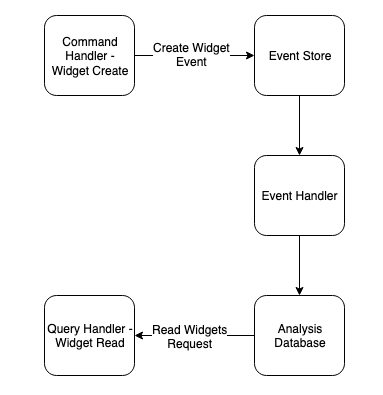
アプリケーションのコマンド (書き込み) は、オンライン トランザクション処理 (OLTP) のデータ ストアの状態を変更するステートメントです。その後、イベントストリームは、発生したイベントをイベントストアに送信します。最後に、これらのイベントは、オンライン分析処理 (OLAP) データベース、マイクロサービスで利用するデータベース、データレイクなどのダウンストリームシステムなどに送信されます。
このアーキテクチャを AWS に実装する方法は複数あります。1 つのアプローチは、Amazon Managed Streaming for Apache Kafka(Amazon MSK) などのメッセージブローカーを使用してイベントをコンシューマーに送信する方法です (詳細については、Capture changes from Amazon DocumentDB via AWS Lambda and publish them to Amazon MSKを参照してください)。この構成の場合、イベントを送信するシステムがイベントソーシングを意識する必要があることが欠点となります。例えば、すべてのイベントをキャプチャしてイベントバスまたはイベントストリームに送信するようにアプリケーションを変更する必要があります。これは複雑でエラーが起きやすく、モノリスから脱却するための妨げになります。さらに、リファクタリング中に開発する機能についても、新しいサービスがイベントを送信できるようにするための作業が追加されます。
この問題の解決策の1つとして、AWS Database Migration Service (AWS DMS) が活用できます。AWS DMS では、サポートされている任意のデータソースからサポートされている任意の宛先に対して、単発もしくは継続的に移行できます。ここで重要な事は、継続的な部分です。この継続的な変更データキャプチャ (CDC)は移行に適しているだけでなく、イベントソーシングアーキテクチャの一部としてイベントストアをハイドレートするのにも適しているのです。この記事では、このアプローチを実装するための2つのパターンを記載しています。最初のアプローチでは AWS DMS のみを使用します。2 つ目のアプローチでは、AWS DMS と Amazon MSK を組み合わせて使用します。
ソリューション概要
最初のパターンでは、AWS DMS のみを使用します。これは AWS DMS タスクを使用して、モノリス データベース(ソース)からイベントストア (今回は Amazon Simple Storage Service (Amazon S3)) にレプリケーションします。その後、AWS DMS はこの中間イベントストアを他のデータベースにレプリケーションするためのマーシャリングポイントとして使用します。このアプローチは、すぐに一貫性が必要でない場合に最適です。例えば、データの日次集計ビューのみを必要とするレポートや分析データベース、リアルタイムのレプリケーションが想定されていないデータの遡及的監査などがあります。このパターンを次の図に示します。

2 つ目のパターンでは、ソース側を変更せずにソースからデータを抽出するためのコネクタとして AWS DMS を使用しますが、イベントストアおよびダウンストリームのコンシューマーへのストリーミングには Kafka (今回は Amazon MSK) を使用します。これは、最初のパターンで説明した 2 ホップ方式よりも一般的には高速であり、アプリケーションがストリームから直接コンシュームできる利点があります。このパターンを次の図に示します。

前提条件
ソリューションをテストするには、AWS アカウントが必要です。また、AWS DMS、Amazon MSK、AWS Lambda、および Amazon DynamoDB リソースを作成するAWS Identity and Access Management (IAM) のアクセス権限も必要です。
サンプルのデプロイ
各ソリューションの例として、ご自身のAWSアカウントにデプロイできる AWS Serverless Application Model (AWS SAM) テンプレートを用意しています。また、この例を参考にカスタマイズすることもできます。
AWS SAM テンプレートをデプロイするには、GitHub リポジトリのクローンを作成し、リポジトリの指示通りに行ってください。
ソリューション 1: AWS DMS Only
最初に、AWS DMS のみを利用したシンプルなソリューションを見ていきます。サンプルテンプレートがデプロイされた後、AWS DMS コンソールに移動し、2 つのタスクが作成されていることを確認します。
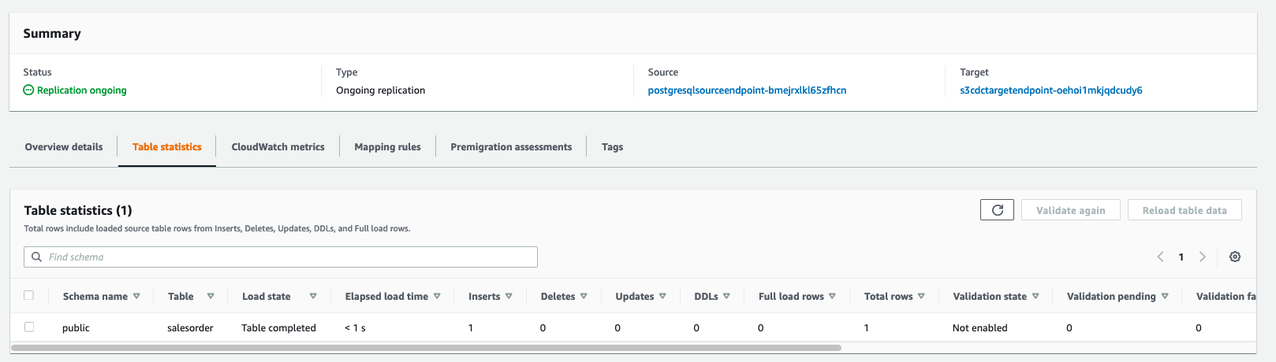
最初のタスクは、ソースデータベース (Amazon Relational Database Service (Amazon RDS) for PostgreSQL )インスタンスの初期フルロードと継続的な CDC です。このタスクは、データを宛先イベントストアの S3 バケットにロードします。
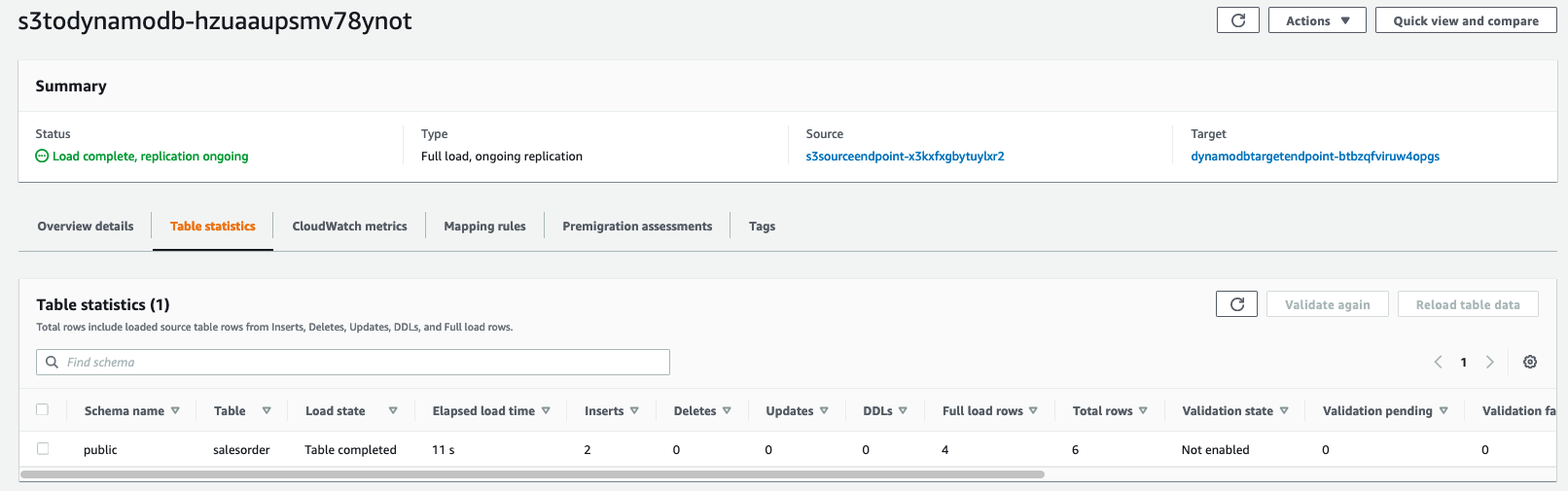
2 つ目のタスクは、イベントストア (Amazon S3) から DynamoDB へのタスクです。今回のシナリオ例では、モノリスをマイクロサービスに分解し、そのジョブに適した専用データベースを選択しています。最初に分解するマイクロサービスである「get widgets」関数は DynamoDB に移行されます。このタスクは、この新しいマイクロサービスへのイベントストアの初期ロードと継続的なレプリケーションを管理します。
レプリケーションタスクの実行
サンプルデータが生成された後 (1 ~ 2 分)、レプリケーションタスクを実行できます。以下のステップを完了してください。
- AWS DMS コンソールで、Amazon S3 への初期ロードと継続的なレプリケーションを行うタスクを見つけます。
- タスクのステータスが「準備完了」であることを確認します。
- タスクを選択し、「アクション」メニューで「再起動/再開」を選択してタスクを実行します。
- 最初のタスクの実行中に、これらの手順を繰り返して、DynamoDB へのフルロードと継続的なレプリケーションである 2 番目のタスクを実行します。
- 各タスクを選択して進捗状況を表示し、レコードが転送されたことを確認します。
このサンプルアプリケーションでは、Amazon EventBridge のスケジュールルールが Lambda 関数を毎分呼び出してRDSに新しいレコードを書き込み、既存のモノリスへの本番トラフィックをシミュレートしています。これは、コマンドとクエリの分離の「コマンド」部分となります。移行とテストの段階を通じて、書き込みは引き続きレガシーデータストアに接続され、読み取りは新しいマイクロサービスデータストアから提供されます。
次のスクリーンショットは、データが Amazon S3 にレプリケーションされていることを確認しています。
数秒後、次のスクリーンショットに示すように、タスクがイベントストアから DynamoDB にデータがレプリケーションされていることがわかります。
Amazon S3データの検証
イベントストアから始めて、関連するさまざまなコンポーネントでこのデータを調べてみましょう。システム内のイベントの不変で追記のみのログを使用して、将来のダウンストリームのマイクロサービスを活用したり、適切な場所で分析機能を提供したりできます。
- Amazon S3 コンソールで、AWS CloudFormation スタックによって作成されたバケットに移動します。バケットには、初期ロードフォルダーと CDC フォルダの 2 つのフォルダーがあります。
- CDC フォルダーを選択し、ソースシステムから送信されたイベントを含むファイルを確認します。

- CSV ファイルの 1 つをダウンロードし、お好みのテキストエディターで開きます。
- ソースシステムからのインサートが存在することを確認します (最初の列に「I」という文字が表示されています)。
エンティティーが変更可能な場合は、update (U) および delete (D) タイプのイベントも存在することになります。
次のスクリーンショットは、サンプルイベントファイルとなります。

DyanamoDBのデータ検証
DynamoDB でデータを表示するには、以下の手順を実行します。
- DynamoDB コンソールで [項目を探索] に移動し、CloudFormation スタックによって作成されたテーブルを選択します。
- [アイテムのスキャン/クエリ] セクションで [スキャン] を選択し、[実行する] を選択します
- ソースシステムのすべてのウィジェットがイベントストアを介してマイクロサービスデータストアにレプリケーションされていることを確認します。
これで、新しいマイクロサービスが DynamoDB から直接イベントを利用できるようになり、これらのイベントを使用する新しい機能は、モノリスにコードを追加することなく、新しいデータストアに対して開発することができます。

ソリューションの利点
RDSからDynamoDBに1ステップで直接レプリケーションするのではなく、2ステップで行ったのなぜでしょうか?
まず、イベントストアは、システム内で生成されたイベントの信頼できるソースとなるように設計されています。モノリスから移行した時でさえ、私たちは今でもイベントストアをシステムの中核として使用しています。この信頼できるイベントストアは、複数のダウンストリームのコンシューマーが、この単一のイベントストアからハイドレートできることを意味します。例えば、複数のマイクロサービスでは、異なるアクセスパターンで同じデータのサブセットにアクセスする必要があります。(単一のウィジェットのキーバリュー検索と、ウィジェットの曖昧検索を考えてみてください)
次に、これらの追加アクセスパターンの中で最も一般的なものは分析です。一部のシステムには、データウェアハウスと入念に設計されたスタースキーマを備えた専用のレポートサービスがありますが、一部の分析ワークロードではデータウェアハウスは必要ない場合があります。Amazon Athena などのクエリツールによるアドホック分析や、Amazon QuickSight などの視覚化およびビジネスインテリジェンスプラットフォームへ取り込むために、Amazon S3に半構造化フォーマットの未加工データにアクセスすることができれば十分かもしれません。イベントソーシングアーキテクチャにはこの機能が組み込まれています。
ソリューション 2: AWS DMSとAmazon MSKの利用
次に、AWS DMS と Amazon MSK を使用したソリューションを見ていきます。この記事の冒頭で述べたように、これはリアルタイムレプリケーションに近いので、より最新のデータを必要とするアプリケーションには、こちらが適切です。ただし、レプリケーションは非同期であるため、多少の遅延が発生します。その為、アプリケーションは結果整合性を許容する必要があります。
レプリケーションタスクの実行
進行中のレプリケーションタスクを開始するには、以下の手順を実行します。
- サンプルリポジトリから CloudFormation テンプレートをデプロイします。テンプレートをデプロイする方法については、リポジトリの指示に従ってください。
- テンプレートのデプロイには約 15 分かかります。テンプレートがデプロイされたら、サンプルデータが生成されるまで 1 ~ 2 分待ちます。
- AWS DMS コンソールで、テンプレートによって作成されたタスクを開始します。このタスクは、フルロードと継続的なレプリケーションの両方を実行します。
- タスクを選択して、データがレプリケーションされていることを確認します。

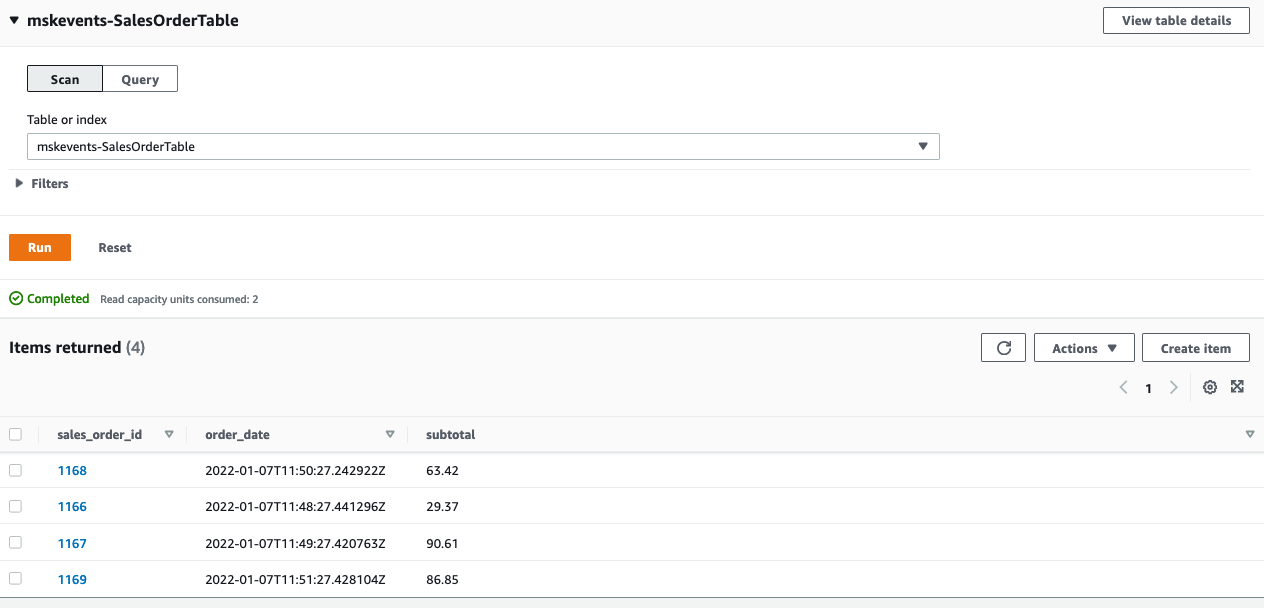
このデータは MSK クラスター内の Kafka トピックにレプリケーションされています。このトピックには2つのコンシューマーがあります。1 つ目は DynamoDB テーブルです。これにハイドレートさせるために、Kafka からデータを読み取って DynamoDB に書き込む Lambda 関数があります。DynamoDB コンソールに移動すると、次のスクリーンショットに示すように、新しいテーブルにデータが表示されます。
このトピックの 2 つ目のコンシューマーは MSK Connect コネクタです。このコネクタには、Confluent S3 Sink プラグインを使用しています。このプラグインを使用して Amazon MSK を設定する方法の詳細については、こちらの例を参照してください。このコネクタは、イベントストリームを S3 イベントストア用バケットにレプリケーションするマネージドサービスを提供します。Amazon S3 コンソールに移動して、テンプレートで作成されたバケットを開くと、Kafka からの未加工のイベントがバケットに直接ストリーミングされていることがわかります。

ここからは、前に説明したのと同じ方法で、このイベントストリームを使用できます。抽出、変換、読み込み (ETL) プロセスのステージングエリアを提供したり、Athena と QuickSight によるインプレース分析を促進したり、追加のマイクロサービスなど下流のコンシューマーにハイドレートしたりすることができます。
ソリューションの利点
AWS DMS のみを利用したソリューションではなく、このソリューションをデフォルトにしないのはなぜでしょうか? Amazon MSK を使用した実装ではレイテンシーは低くなりますが、MSK クラスターを永続的に実行することによる追加コストと、この追加稼働部分の複雑性が増します。より高度な操作やレイテンシーの影響を受けやすい操作の場合、このトレードオフは価値があります。レポートや分析など、最終的には秒単位の結果整合性が許容される一部のアプリケーションでは、AWS DMS のみを利用したソリューションの方がよりシンプルで費用対効果の高いソリューションとなる場合があります。
クリーンナップ
この記事で説明したサービスのいくつかは AWS 無料利用枠に含まれるため、これらのサービスの料金が発生するのは、無料利用枠の使用制限を超えた場合のみです。詳細な料金表については、Lambda、DynamoDB、Amazon RDS、Amazon MSK の価格ページをご覧ください。
予想外の料金が発生しないようにするには、未使用のリソースをすべて削除する必要があります。サンプルの AWS SAM テンプレートをデプロイした場合は、AWS CloudFormation コンソールから CloudFormation スタックを削除します。
結論
この投稿では、AWS DMS を使用してイベントソースシステムを実装する 2 つの方法について説明しました。従来のモノリシックなソリューションから脱却し、将来を見据えたソリューションを設計するためにイベントソーシングと CQRS を実装する企業が増えるにつれて、イベントソーシングと CQRS はますます一般的になりつつあります。どちらのソリューションでも重要なことは、Amazon S3 内の不変で追加専用イベントストアです。これが、新しいマイクロサービス、分析ソリューション、代替アクセスパターンを提供する基盤となります。
しかし、おそらく最も重要なのは、アーキテクチャの将来性を保証できることです。現在、アプリケーションに最適なデータストアが、5年後、10年後のアプリケーションに最適なデータストアでなくなっているかもしれません。データのポータビリティがあり、これらのイベントを将来的にどのデータストアでも再生できるようになれば、非常に柔軟性が高まります。また、各サービスのイベントストアからデータレイクやデータメッシュアーキテクチャを作成できるため、データの発見可能性が高まり、より大きな価値が得られます。
サンプルリポジトリをクローンして、今すぐソリューションを試してみてください。これらおよびその他の CQRS の実装や AWS でのイベントソーシングに関するコメントで、ご意見をお寄せください。
翻訳はソリューションアーキテクトの関藤 寛喜が担当しました。原文はこちらです。