Amazon Web Services ブログ
リクルートマーケティングパートナーズにおけるAmazon EKSとAWS App Meshを使った基盤安定性向上とGitOpsへの挑戦
本番環境でコンテナを利用したワークロードを構築する場合、ほとんどのケースでコンテナオーケストレーションのテクノロジが導入されます。AWS では、Amazon Elastic Container Service (Amazon ECS) や Amazon Elastic Kubernetes Service (Amazon EKS)といったコンテナオーケストレーションに関するサービスを提供しています。
コンテナオーケストレーターの選定においては、各オーケストレーターの持つ機能や思想を理解することが重要です。Amazon ECS は、他の AWS サービスとシームレスに組み合わせることが可能であり、Amazon ECS をビルディングブロックの一つとして多様なワークロードをサポートするシステムを素早く構築可能です。Amazon EKS は、Kubernetes の持つエコシステムの利用や、カスタムリソースをクラスターに追加することにより、EKS クラスター上にワークロードの要件に応じたシステムを柔軟に構築することができます。これらの観点に加えて、ワークロードの要件を考慮した上でコンテナオーケストレーターを選択します。
一方で、ビジネスや組織の成長に伴い、コンテナオーケストレーターとワークロードがマッチしない状況が発生する場合があります。例えば、Amazon EKS でサービスを提供しているチームにおいて、サービスの拡充に伴い管理対象となる EKS クラスターやクラスター上のアプリケーションが増加した結果、Kubernetes バージョンのアップデート作業がチームで抱えきれないような負担になるかもしれません。この状況を解消する手段として、まず思いつくのがコンテナオーケストレーターの再選定ですが、コンテナオーケストレーターの移行には少なからず必要となる作業が見込まれるため、安易に決断することはできません。
しかしながら、コンテナオーケストレーターの移行により得られるベネフィットを評価できる場合、移行によるメリットが作業コストを上回る可能性があります。この評価を行うためには、現在の課題を正確に分析し、移行先となるコンテナオーケストレーターでは解決のためにどのようなアプローチが採用できるのか把握しておく必要があります。
本投稿では、リクルートマーケティングパートナーズが行なった Amazon ECS から Amazon EKS への移行を通じて、コンテナオーケストレーターの移行におけるベネフィットをどのように評価したのかを紹介します。合わせて、リクルートマーケティングパートナーズが Amazon EKS で導入したサービスメッシュと継続的デリバリーについて、その実例を紹介します。
リクルートマーケティングパートナーズ スタディサプリ ENGLISH SRE グループの大島 雅人氏、木村 勇太氏、横山 智大氏によるゲスト投稿
以下の投稿はリクルートマーケティングパートナーズの3つのブログ記事を元に再構成したものです。
概要
- スタディサプリ ENGLISH の基盤を Amazon ECS から Amazon EKS に移行した話
- Amazon EKS で AWS App Mesh を利用して gRPC サーバーを運用している話
- Amazon EKS での Argo CD を使った GitOps CD を実現した話
① スタディサプリ ENGLISH の基盤を Amazon ECS から Amazon EKS に移行した話
こんにちは、スタディサプリ ENGLISH SRE グループの大島です。
オンライン英語学習サービスであるスタディサプリ ENGLISH は 2015 年 10 月のリリースから 5 年が経ち、2 月にはオンライン英会話がセットになったプランなどサービスを拡充させることができています。リリース当初からインフラにはコンテナを採用し、長い間 AWS のコンテナオーケストレーションサービスの Amazon ECS(以下、ECS)で運用してきましたが、この度 ECS から Amazon EKS(以下、EKS)に移行しました。
このセクションでは、その歴史の変遷となぜ EKS にしたのかというところを書いていきたいと思います。
コンテナと歩んできた 5 年間
まず、ECS から EKS に移行しようと思ったきっかけの前に、スタディサプリ ENGLISH のインフラの歴史を少し振り返ります。
簡単にまとめると、コンテナーオーケストレーションは、fleet から始まり、Kubernetes 導入を試みるも断念し ECS へ、そして、事業・チームの拡大に伴い Kubernetes を再検討し EKS に移行したという流れになっています。システムのアーキテクチャについては途中から gRPC を利用したマイクロサービス化に舵を切り、事業としても初めは一つのサービスのみでしたが TOEIC コース、ビジネス英語コースなど提供するサービスを増やしながら運営を行ってきました。
なぜ ECS から EKS に移行したのか
前置きとして、本記事では ECS より EKS がよいと言っている訳ではありません。OpsWorks で動いていた我々のサービスの移行先として ECS Fargate を選定したこともある通り、それぞれ適材適所があると考えています。その上で EKS に移行したのは、以下のようなユースケースが重なっている我々の状況においてはメリットがあると判断したためです。
- Infrastructure as Code を実践している
- サービス全体が数十のマイクロサービスで稼働している
- 複数のチームが同時並行で複数のアプリケーションの機能開発をする
- サービス間の内部通信があり gRPC を採用している
- たくさんの開発環境だけでなくコンテンツの入稿の環境なども必要になってくる
以下に具体的にスタディサプリ ENGLISH のユースケースにおける Kubernetes にするメリットについて述べていきます。
メリット1: 複数の環境を作る際に Kubernetes だけで完結しやすい
ECS は様々なサービスを組み合わせて構築をする
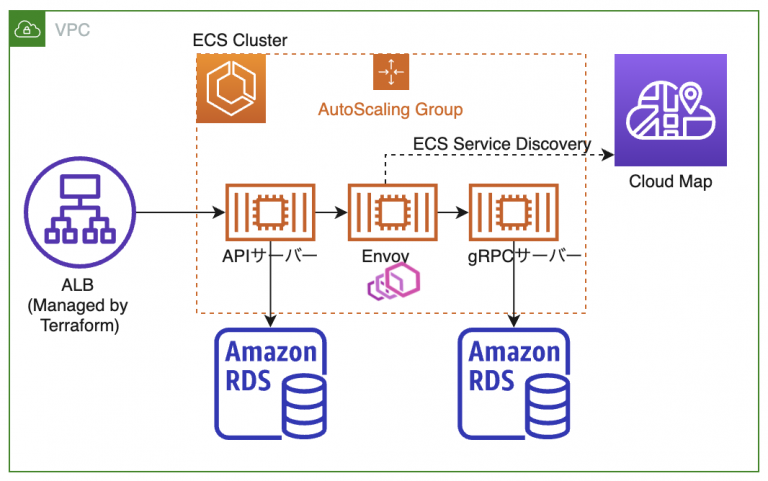
ECS ではサービス間通信や負荷分散を行う場合は、ALB、Target Group、Listener Rule、ECS サービスディスカバリ、Route 53 などの機能を組み合わせることで実現します。それぞれの機能自体は高いレベルで安定性があり機能には問題はありません。
ただ、複数の開発環境や数十の複数のサービス間内部通信を取り扱う際に、Terraform で ALB やListener Rule、ECS Cluster、ECS サービス、ECS サービスディスカバリを作成し、一方でそれぞれの環境ごとの YAML(Task Definition)を用意するところが煩雑になってしまい、インフラのライフサイクルとアプリケーションのライフサイクルの違いをうまく吸収できていませんでした。
Kubernetes だけで完結することができる
Kubernetes の場合は基本的に複数の環境を作る際に Kubernetes だけで完結することができます。例えば、Service を使って内部のサービス間通信を行うことができます。また、複数環境を作成する際にも、namespace を利用して一つのクラスターを論理的に分割することができます。外部からのルーティングも Ingress を利用することで Kubernetes の resource として YAML で統一的に記述することができます。
Kubernetes の周辺エコシステムが充実していたこともあり、YAML の管理も Kustomize の overlay を利用した環境差分の吸収、Helm の chart を利用したミドルウェアのインストールの仕組みや、kubectl の高度な apply の差分チェックアルゴリズムを利用することで簡単に複数環境のデプロイについても対応できたことが大きいです。
メリット2: GitOps による継続的デリバリー (CD) を適用しやすい
ECS のデプロイまわりで感じていた課題
デプロイについては、recruit-mp/kangol という自社で作成したツール経由で行っていました。ECS や CodeDeploy の機能追加に追従する必要がありましたが、初期の頃の ECS の仕様で作ったツールのため、新機能をなかなか取り込めず新しいメンバーが独自のデプロイの仕様を把握するのに時間がかかるという問題がありました。
サービスや開発環境が複数あると、現在どこに何がデプロイされてるのかというのを把握するのが難しく、AWS CLI で取ってくるにもしても、イメージの tag を取得するには複数の API を呼び出して組み合わせることが必要です。
mpon/ecswalk というツールを作成し、把握しやすいように工夫はしていましたがツールのメンテナンス等を考えると手間がかかっていました。
さらに、gRPC のロードバランシングをするために、envoy の ECS サービスを前段にたて ECS サービスディスカバリを利用して接続先を切り替えるということを行っていましたが、単純に ECS サービスのローリングアップデートに任せると、STOP 済のコンテナの IP が返ってきてしまいリクエストが落ちてしまいます。
この問題に対応するために、Blue/Green デプロイを Jenkins とシェル、kangol を組み合わせて実現していましたが、設定ミスによりデプロイ時に障害を発生させてしまったこともありました。デプロイ周りの課題に関しては ECS の課題というより我々のツールの問題ですが、各社苦労している部分なのではないかと思います。
Kubernetes は GitOps が採用しやすい
どこに何がデプロイされているか把握したいという課題については、GitOps を採用することで解決すると考えていました。
Kubernetes を利用した場合、Reconciliation Loop というアーキテクチャのおかげで常にリポジトリとの差分をチェックしておくということを実現しやすくなっています。
そのため、GitOps を実現するためのエコシステムも発展しており、Argo CD や Flux CD など高機能な GitOps のツールが揃っています。
また、メリット 1 でも述べたように AWS の複数のサービスを組み合わせることなく Kubernetes の resource として管理できる部分が増えるので、クラスターを動作させるために必要なものをほとんど GitOps でデプロイできるようになるという利点があります。
スタディサプリ ENGLISH では Argo CD と Kustomize を採用し、Argo CD が提供している dashboard や、公式ツールとして提供される高機能な kubectl の恩恵により、状況が把握しやすくなりました。
Argo CD を採用することで自作ツールのような独自仕様でなくなったため、今後新しいメンバーが入ってきたときも理解しやすくなり、継続的デリバリーで抱えていた課題を解決することができました。
ECS と EKS 移行後のシステム概要図
ここまで移行の背景を述べてきましたが、最後に移行前と移行後の構成を簡単に紹介します。
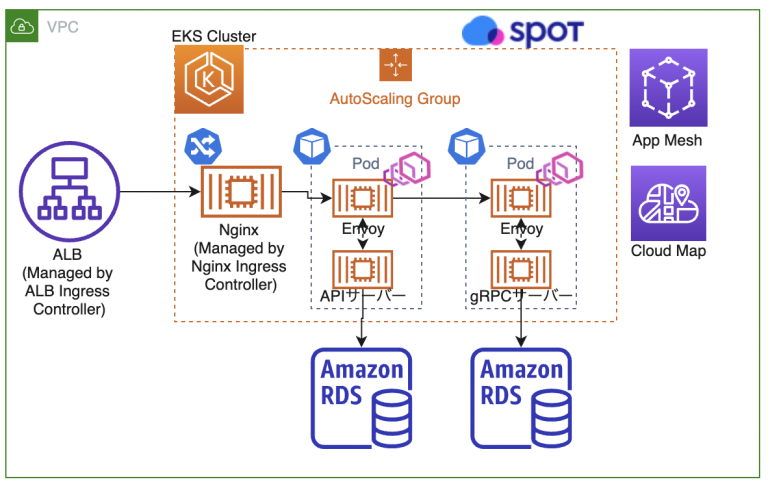
以前は、gRPC のロードバランサーとして単体の ECS サービスとして Envoy をおいていましたが、EKS 移行後は App Mesh と App Mesh Controller for k8s を利用して Envoy を Inject するようにしています。
App Mesh の導入により動的にルーティングを切り替えられるようになり、Spot Ocean を利用した、より柔軟なクラスターのオートスケーリングも可能になりました。
また、ALB を ALB Ingress Controller と Nginx Ingress Controller を組み合わせた構成に変更し、 Terraform で作成していたリソースを Kubernetes の controller に作成してもらうようにすることができ、環境の増減に対応しやすくなりました。
ECS の時の構成図
EKS 移行後の構成図
まとめ
ECS から Kuberntes に移行するぞと考え始めたのは、2017 年の頭で当時はすぐにできそうと思っていましたが、全ての環境を EKS に一本化するまで長い道のりでした。
今後は、App Mesh を導入したことでシステムの可視化がしやすくなったこともあり、可視化に力を入れてシステムの品質を高めていきたいと思ってます。
② Amazon EKS で AWS App Mesh を利用して gRPC サーバーを運用している話
こんにちは、スタディサプリ ENGLISH SRE グループの横山です。
前述の通り、スタディサプリ ENGLISH のインフラ基盤を ECS から EKS に移行しました。このセクションでは、この EKS 移行に伴い AWS App Mesh (以下、App Mesh) の導入をしたので、これに関連した話を書いていきたいと思います。
なぜ App Mesh 導入を検討し始めたか
インフラ基盤が ECS だった頃、gRPC の負荷分散に Envoy と Amazon ECS サービスディスカバリを利用していました。(※なお、今でしたら ALB で gRPC 負荷分散をやりますが、当時はなかったのでこのような構成になっています。)この構成にした当初は、デプロイ時に ECS サービスのローリングアップデートのみを利用していました。
しかし、ECS サービスディスカバリで登録している IP のレコードが Route 53 から消えるタイミングとコンテナの終了のタイミングを調整するのが難しく、STOP 済みのコンテナの IP へリクエストが行ってしまうという問題がありました。一般的に、クライアントサイドロードバランシングを利用する場合にはリトライまでクライアント側の責務なので、サーバサイドロードバランシングに最適化されていた本アプリケーションを改修することで本問題に対処すべきでしたが、アプリケーションに手を加えずにインフラ側で改善したいという要件があったため別の手段を探す必要がありました。結果、この問題に対処するためには ECS サービスを同種のサービスで 2 つ用意し、サービス毎入れ替える Blue/Green デプロイを行い、それを自前のデプロイツールで制御、Jenkins のシェルで sleep を入れる等、少々複雑なことを行っていました。
また、スタディサプリ ENGLISH の拡大と共に Service が増えていく中で、この ECS 時代の構成だと、 Sevice を増やす度に Envoy の ECS サービスを増やす必要があるため Envoy の設定ファイルを個別に管理する量が増えていく、デプロイツールや Jenkinsfile の修正を都度修正していく必要がある、等の手間が増えてきたという課題も出てきました。
そこで、自前の仕組みを減らし AWS や Kubernetes の仕組みに可能な限り全て乗せたいというモチベーションが出てきました。私たちは App Mesh に関しては以前から注目しており、将来的にサービスメッシュを本格的に導入し、サービス全体の通信の可視化や安定化のためのトラフィック制御を強化していきたいという考えがありました。
Envoy 管理という課題に対しては、App Mesh を利用することで容易になるのではないかという案があり、完全に解決できていなかったリクエストが落ちてしまう問題や、デプロイ周りの複雑さに対しても、Kubernetes の Pod の設定での制御や App Mesh のトラフィック制御等で対処できないかという案がありました。
このような背景があり、今回 EKS 移行と共に App Mesh を本番導入していくことを決定しました。
App Mesh を EKS (k8s) 上で管理する
App Mesh を導入する上で、まずは App Mesh 自体の設定をどう行うか調査をしていきました。
AWS App Mesh Controller For K8s (以下、App Mesh Controller) というものがあり、これを利用することで Kubernetes の CRD として AWS 上の App Mesh リソースを全て管理することができ、私たちの EKS 移行の目的の 1 つであるインフラ基盤の全てをなるべく EKS (Kubernetes) の世界で完結させたいという点に非常にマッチしていたため、採用を決めました。
また、App Mesh Controller の EKS クラスタへのインストールには、helm chart が AWS のリポジトリで用意されているためこれを利用しました。
以下では、実際に App Mesh の設定をする manifest の一部を紹介したいと思います。まずは Mesh の定義です。
上記のように Mesh の設定ができ、Mesh ラベルを Namespace に付与することで、該当の Namespace 内で作成した Virtual Node はラベルで付与した Mesh に自動的に登録されるようになります。
appmesh.k8s.aws/sidecarInjectorWebhook ラベルは、Pod 起動時に Sidecar コンテナとして Envoy を Inject させるかどうかの制御で、これを enable にしておくとその Namespace 内で起動した Pod 全てに Envoy が Inject されるようになります。
また、全ての Pod に Envoy を Inject させたくない場合は、いくつか方法はありますが、例えば appmesh.k8s.aws/sidecarInjectorWebhook: enabled にしておき、Inject させたくない Pod に下記の annotation を付与するという方法があります。
次に、Envoy を Inject させるサービス側に設定する Virtual Node 等は下記のような Manifest になります。
元々、API サーバーから gRPC サーバーへのリクエストを負荷分散させるために Envoy を入れていた箇所です。
EKS + App Mesh への移行時には下記のような構成になっています。

上記の Manifest は全て App Mesh の CRD で、API サーバーや gRPC サーバー側の Manifest には Sidecar で Envoy を入れる設定を書く必要がありません。
App Mesh Controller の機能で、Pod 起動時に Sidecar で Envoy を Inject してくれます。これによって App Mesh の設定と各サービスの Manifest は個別にできるため、アプリケーションとインフラの設定を分離した状態で管理することができるという利点があります。
また補足ですが、gRPC サーバー側のサービスディスカバリには下記のように AWS Cloud Map を利用しています。
これは、Service Discovery に DNS を指定すると Logical DNS が使われ gRPC の負荷分散に使えないためです (参照: https://docs.thinkwithwp.com/app-mesh/latest/userguide/virtual_nodes.html)。
このように App Mesh Controller を使うと、App Mesh に必要な設定を全て Kuberenetes の Manifest で管理することができます。
開発環境を増やす場合は、私たちは Manifest 管理に kustomize を使っているため、overlay で環境毎の差分を追記するだけで App Mesh の設定も楽に増やせます。
また、Service を増やす場合でも他の Service とほぼ同様の Manifest で良いです。デプロイ周りの設定も自前のツール等は用意せず、最終的に Kubernetes (とデプロイに利用している Argo CD) の機能のみ利用で本番導入できたため非常に簡潔になりました。
デプロイ時にリクエストが落ちる問題への対処
App Mesh 検証時点で、予想通りデプロイ時にリクエストが落ちるという既存の構成と同様の問題がありました。しかし、ECS 時代のように自前でデプロイ周りの仕組みを用意する必要はなく、App Mesh 周りの設定と Kubernetes の Pod の制御で解決できたので紹介していきます。
App Mesh best practices に沿った retry の追加、Deployment の maxSerge の設定
「App Mesh best practices」というものが AWS のドキュメントにあり、これに沿って設定を修正しました。retry の設定については、Virtual Node の Manifest に入れるだけで設定できます。下記は前章で紹介した Virtual Node の Manifest の retry 設定部分の抜粋です。
Cloud Map 経由で作るレコードの TTL を 0 に
ECS 時代でも同様のことがありましたが、STOP したコンテナの IP へリクエストが行ってしまうためリクエストが落ちるという事象が起きていました。少しでも STOP したコンテナの IP へリクエストが行く可能性を減らすため、Cloud Map 経由で作るレコードの TTL を 0 に設定しました。
このレコードは Virtual Node の設定経由で Cloud Map で設定されるもので、TTL の値を App Mesh Controller から変更できます。
Pod の preStop で sleep を入れて調整
上記までの試みで軽減されてはいましたが、まだリクエストが落ちる問題が残っていました。
Kubernetes のサービスから Pod が切り離されるタイミングと Cloud Map から Pod の IP が削除されるのが完全に同期できないことが原因であると思われるので、sleep を挟んで少し待つことで対処しています。
以上、これらの方法で、本番導入しても問題はない程度にリクエストが落ちる問題の対処をすることができました。
retry や preStop の sleep は、デプロイ時だけでなくコンテナの異常終了時も同じ挙動になるため、あらゆる場面での Pod の入れ替わり時において、リクエストが落ちてしまう問題に対応することができるようにもなっています。
今回の本番導入の時点では、App Mesh の Virtual Router を利用したトラフィックの切り替え等の活用までは至りませんでしたが、さらなる安定化のため今後検証を進めていく予定です。
gRPC の負荷分散はどうなったか
元々、ECS 時代に Envoy を入れた目的は gRPC の負荷分散でした。App Mesh 導入後も gRPC の負荷分散が以前と同様にできているかの検証も行ったので、簡単に比較していきます。1 つの Service のコンテナ毎の CPU 使用率のグラフです。

上図の通り、App Mesh 移行後も問題なく gRPC の負荷分散ができていることが確認できています。
まとめ
今回は EKS 移行と共に App Mesh を本番導入し、gRPC サーバの負荷分散等、既存の要件を維持しつつ EKS 移行前にあった課題を解決できた話を紹介させていただきました。
まだ App Mesh を、Envoy の管理を App Mesh Controller で楽にする、retry 等を使用したリクエストが落ちてしまう問題へ対処等にしか活用できていないため、これらの点に絞った話にはなってしまいましたが、今回 App Mesh を導入したことでサービスの通信可視化等、スタディサプリ ENGLISH のインフラ基盤の安定性向上のために様々なものを取り入れていく土台ができたと思っています。
App Mesh のロードマップを見ると今後も様々な機能のリリースが予定されているようなので、役立ちそうなものを検証していき積極的に取り入れていきたいと考えています。
③ Amazon EKS での Argo CD を使った GitOps CD を実現した話
こんにちは。スタディサプリ ENGLISH SRE グループの木村です。
このセクションでは私たちが Kubernetes の CD になぜ Argo CD を選んだのか?どのよう導入したのかという部分を説明していきたいと思います。
Argo CD について
Argo CD は GitOps を行うためのツールの一つです。
Argo Project というオープンソースで Kubernetes ネイティブな Workflows, Events, CI, CD を扱うために作られた中の 1 プロジェクトです。元々は Applatix という Cloud でのプラットフォーム構築のコンサルタントをしていた会社が中心となって作成していましたが、2018 年に Intuit が Applatix を買収し、現在は Intuit のエンジニアが中心となって開発しており、2020 年 4 月に CNCF のインキュベータプロジェクトに Argo が入っています。
Why? Argo CD
早い段階で GitOps を利用したいということは決めていたのですが、GitOps を導入できるツールには複数のものがあります。有名なものでは Weaveworks 社が作っている Flux だったり、Kubernetes のプロジェクトでも使われている JenkinsX などがあります。
なぜ私たちが Argo CD を採用したかという点を書いていきたいと思います。
GUI
Argo CD にはデプロイを行ったアプリケーションを GUI で確認することができる GUI 機能があります。
現時点では SRE が基本的に Argo CD や Kubernetes の manifest を管理していますが、将来的にはデベロッパー自身で管理・運用できるようにしていきたいという気持ちがあり、最初の導入障壁を考えると、どのように resource が反映されているか?ということを把握できる GUI は大きな利点だと考えました。
Sync Phase/Sync Wave
DB migration と API の依存関係
私達の環境では DB migration に Play Framework の Evolutions を利用して自動化しています。その関係上で実際に API をデプロイする前に Evolutions を実行するタスクを実行する必要があります。
また私たちはアーキテクチャにマイクロサービスを採用し、内部 API の context 間の通信に gRPC を採用しており、デプロイ時の API 依存によるリクエストが落ちる問題を最小限にするため、後方互換が維持されている gRPC のサーバーから先に反映したいという要件もありました。
Argo CD には Sync Phase と Sync Wave という 2 つの概念があり、Sync Phase には PreSync, Sync, PostSync の 3 つの Phase があり、Sync Wave で各 Sync Phase の間の Sync の順序を制御できます。
私たちの場合は PreSync で ConfigMap の作成→DB migration、Sync で internal API (gRPC)→external API (REST) を行うようにしています。
Sync順序のイメージ図

manifest管理・運用について
Argo 社のブログでは「5 GitOps Best Practices」という Argo CD を運用するするためのベストプラクティスをまとめた記事があり、その中で「Two Repos: One For App Source Code, Another For Manifests」という Application のソースと manifest のレポジトリを分けて管理するべきというのがあります。
私たちの環境では早い段階から IaC を徹底しており、自然にこのプラクティスに則った形でインフラとサーバーのデプロイの設定ファイルは専用のレポジトリを作成して運用しており、自然と管理しやすい形になっていました。manifest の環境差分の管理には kustomize を採用しています。
manifest ディレクトリ
現状では api や job, argo などの大きな枠で依存しないと思われるディレクトリを三階層で分けその中に各 manifest を分けています。(※テストディレクトリは manifest のテストに関するスクリプトをまとめている) 数が多く全ては紹介しきれないのですが、api, argo, cluster の一部のディレクトリを紹介します。
API
各 API 毎に service と argocd_application の 2 つのディレクトリを作り、その中で各環境用の overlays を作成しています。
argocd_application以下には application の yaml を配置service側には deployment や Evolutions の job の manifest, App Mesh などの application が動作するために必要な manifest を配置- 運用としては初回のみ
argocd_applicationを apply して利用
することを想定しています。
apiディレクトリ構造
argocd
このディレクトリには Argo CD の関連の resource を管理しています。
Argo CD 本体の管理には以下の工夫をしています。
- Argo CD を Argo CD application で管理する
- 初回のみ Argo CD を手作業でapplyした後、手作業で apply した Argo CD を Argo CD の管理下に置くことができる。初回構築時以降のバージョンアップは PR ベースでできるようになる。
- 公式でもこの方式で管理できることが記載されています: https://argoproj.github.io/argo-cd/operator-manual/declarative-setup/#manage-argo-cd-using-argo-cd
- remote build
- kustomize の機能で github 上にある manifest を扱うことができる機能。私たちの環境では自分たちが変更したい部分を
patchesStrategicMergeで上書き、主要な部分は remote build から取得することで Argo CD 本体のアップデートの手間を省いています。
- kustomize の機能で github 上にある manifest を扱うことができる機能。私たちの環境では自分たちが変更したい部分を
- 実際の kustomization.yaml:
argo-notifications は argo-cd-labs org で開発されている、Argo CD の通知ツールです。
argocd-app-projects には Argo CD の CRD の App Project の manifest を別途配置しています。argocd とは別のディレクトリに配置してある理由は同時に apply した場合、argocd の CRD が反映されるまえにApp Project が apply されるとエラーが発生することがあるので別のタイミングで apply できるように異なるディレクトリに配置してあります。
argocdディレクトリ構造
cluster
共通で必要な ingress controller や datadog agent、fluent-bit などの manifest を管理、一部のものは Argo CD の Helm Chart Repositories の機能で入れるようにしております。cluster の構築と node の管理に関しては、Terraform と Spot を利用しています。
cluster 構築の後に必要な resource は全て Argo CD で管理しているので、argocd_application を cluster に apply させることで、必要な設定のほとんどは反映出来るような形です。
clusterディレクトリ構造
Manifest に対する CI
CI テストに関しては CircleCI 上で、3 種類のテストを行っています。
- kustomize build を行った結果に対して、kubeval をかけるテスト
- kustomize build を行った結果に対して、自前で Golang で書いた manifest に想定した値や設定されているかのテスト
- kind を使って、実際の cluster を作成できるかのテスト
1 のテストに関しては、私たちの repository には Argo CD と App Mesh の CRD が入っているので、--ignore-missing-schemas オプションをつけることで CRD の場合のチェックを外すようにしています。また indent ずれなどで設定したつもりの値が設定されていないなどが起きたため、その resource に存在しない key が設定した場合失敗としてくれる --strict のオプションをつけています。
2 に関しては CPU、resource が設定されているか、想定のパターンの env が設定されているか、ReadinessProbe が設定いるかなどの kubeval では検知出来ない部分のテストを実行しています。当初は conftest の導入も検討したのですが、実際に書いてみると rego の記述が複雑になってしまう可能性とチームの中で Golang を書くことができる人が多かったので、最初は小さくテストを初めていきたいなどの点から現時点では Golang を利用し、自分たちでテストを書くという形にしています。
3 に関しては、kind を使って、実際に CI 環境上に cluster を構築してテストをしています。全体の manifest をテストするのは CI 環境上では現状では大変なため、現在は Argo CD が立ち上がるかのテストのみを実行しています。
将来的には cluster update 時のテストのため、AWS などの public cloud 環境などで実際に cluster を立てるテストなども考えて行きたいと思っています。
Special thanks
自前でテストを書く部分に関しては、cybouzu さんの neco project の test 部分がすごく参考になりました。
非常に感謝しています!
デプロイフロー
PR が作成されて merge されたら、Argo CD が差分を検知し、cluster への反映がされるような形です。
私たちの実際のフローとしては、アプリケーションの build と PR の作成には Jenkins を利用しており、デペロッパーには環境 deploy したい component を選択してもらい、Jenkins で build, PR 作成をするという形になっています。
現状は PR 作成時に手作業が発生してしまう点が懸念点なので、master merge 時に自動で PR 作成をする方法も今後は考慮していきたいなと考えています。
cluster 毎の差分
cluster としては development, staging, production の 3 cluster を管理しています。
Staging と production は本番同等環境として運用しているので、各 cluster に API 用の namespace を一つずつ、PR を master に merge することで運用、development 環境に関しては、1 namespace が 1 環境というような形で、複数の環境を運用する形にしています。
Development 環境については、現在は deploy 用の branch を作成し、前述の Jenkins から直接 branch に push をする形で運用しています。
Git を single source of truth という形で運用しているので仕方ない部分はあるのですが、 開発環境のような頻繁に deploy が発生する可能性がある箇所では Git 非依存での deploy する機能ができて欲しい気持ちがあります。他の Argo CD を運用している人がこの点をどう運用しているかは是非知りたいと思っています。
まとめ
本記事では私たちが行った Argo CD を使ったデプロイフローに関して紹介をさせていただきました。
GitOps の重要な利点として、環境の正しい状態を Git の yaml を読むことで把握できるようになりました。また、Argo CD は custom controller を利用して、GitOps を実現しています。開始するには Argo CD を入れるだけで、Argo CD を止めたい場合は Argo CD の resource を消してしまえば、やめることができるという利点もあります。
まだまだ manifest の管理の方法やテスト方法など、課題やベストプラクティスを模索している状態ではあるのですが、今回の記事が GitOps や Argo CD の導入を検討している人たちの助けになると嬉しいです。