Amazon Web Services ブログ
Amazon CloudWatch メトリクスを使用して Amazon RDS についてより適切な意思決定を行う
Amazon Relational Database Service (RDS) を使用している場合、インスタンス設定を変更するのに最適なタイミングを判断する方法について悩んでいるかもしれません。これには、インスタンスクラス、ストレージサイズ、ストレージタイプなどの設定の決定が含まれる場合があります。Amazon RDS は、MySQL、PostgreSQL、SQL Server、Oracle、Amazon Aurora などのさまざまなデータベースエンジンをサポートしています。Amazon CloudWatch は、これらすべてのエンジンをモニタリングできます。CloudWatch メトリクスは、最適なインスタンスクラスを選択するためのガイドとなるだけでなく、適切なストレージサイズとタイプを選択するのにも役立ちます。この記事では、CloudWatch メトリクスを使用して、データベースのパフォーマンスを最適化するために Amazon RDS の変更をどう判断したらよいかを説明します。
CPU とメモリの消費
Amazon RDS では、CPUUtilization、CPUCreditUsage と CPUCreditBalance の CloudWatch メトリクスを使用して CPU をモニタリングできます。すべての Amazon RDS インスタンスタイプは、CPUUtilization をサポートしています。CPUCreditUsage と CPUCreditBalance は、バースト可能な汎用パフォーマンスインスタンスにのみ適用できます。
CPUCreditUsage は、インスタンスが CPU の使用に費やした CPU クレジットの数として定義されます。CPU クレジットは、バースト可能なパフォーマンスインスタンスのベースラインレベルを超えてバーストする機能を管理します。CPU クレジットは、100% の使用率で 1 分間実行されるフル CPU コアのパフォーマンスを提供します。CPUUtilization は、インスタンスでの CPU の使用率を示します。CPU 消費量の不規則な急上昇でデータベースのパフォーマンスが低下することはないかもしれませんが、CPU が高い状態が継続すると、その後のデータベースリクエストを妨げることがあります。データベース全体のワークロードに応じて、Amazon RDS インスタンスの CPU 使用率が高い (70% 〜90%) と、全体的なパフォーマンスが低下する可能性があります。不良または予期しないクエリ、または異常に高いワークロードにより、CPUUtilization の値が高くなった場合は、より大きなインスタンスクラスに移動してもよいかもしれません。Amazon RDS Performance Insights は、大量の CPU を消費する不良 SQL クエリを検出するのに役立ちます。詳細については、「Performance Insights を使用して YouTube 上の Amazon Aurora PostgreSQL のパフォーマンスを分析する」を参照してください。
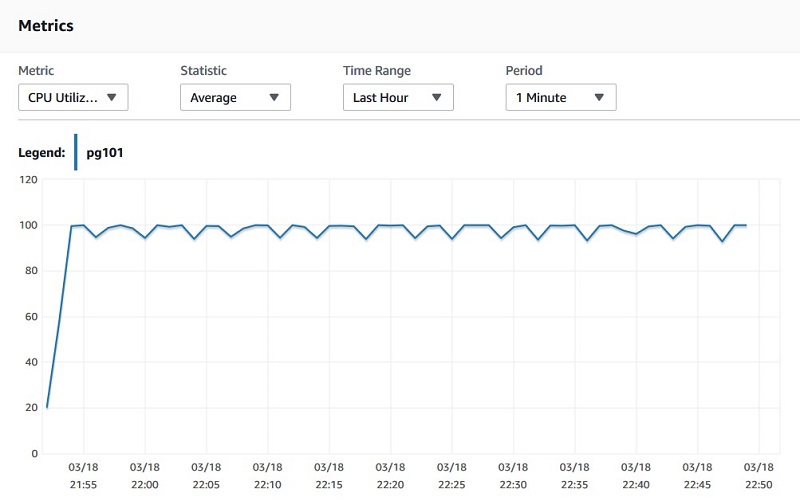
次の CloudWatch グラフは、高い CPU 消費のパターンを示しています。CPU は、長期間にわたって高い状態が続いています。この鋸歯状パターンは、Amazon RDS インスタンスをより高いインスタンスクラスにアップグレードする必要があることを示しています。
メモリは、Amazon RDS のパフォーマンスを決定し、Amazon RDS 設定に関する決定を行うのに役立つもう 1 つの重要なメトリクスです。Amazon RDS は、次のメモリ関連のメトリクスをサポートしています。
- FreeableMemory – システムが使用していない物理メモリの量と、空いていて使用可能なバッファまたはページキャッシュメモリの総量。データベースのワークロードを最適に設定し、1 つ以上の不良クエリが原因で
FreeableMemoryが低くなっているのではない場合、低いFreeableMemoryのパターンから、Amazon RDS インスタンスクラスをより高いメモリ割り当てレベルにスケールアップする必要があることを示しています。FreeableMemoryに基づいて意思決定を行う場合、特にFreeとCachedのように、拡張モニタリングメトリクスを確認することが重要です。詳細については、「拡張モニタリング」を参照してください。 - SwapUsage – DB インスタンスで使用されるスワップ領域の量。Linux でホストされるデータベースでは、
SwapUsageの値が高い場合、通常、インスタンスのメモリが不足していることを示しています。
ディスク容量の消費
Amazon RDS Oracle、MySQL、MariaDB、PostgreSQL エンジンは 64 TiB のストレージスペースをサポートしています。Amazon Aurora ストレージは、自動的に 10 GB 単位で最大 64 TB まで拡張されます。Amazon RDS エンジンは、ストレージの Auto Scaling もサポートしています。このオプションは、ストレージを自動的に 5 GiB または現在割り当てられているストレージの 10% のいずれか大きい方に増やします。CloudWatch メトリクス FreeStorageSpace は、インスタンスの使用可能なストレージスペースの量を測定します。データの量が増えると、FreeStorageSpace グラフに低下が見られます。FreeStorageSpace が約 10% 〜15% である場合は、ストレージをスケーリングするのに良いタイミングです。ストレージの消費量が急増した場合は、データベースのワークロードを確認する必要があることを示しています。大量の書き込みアクティビティ、詳細なログ記録、または大量のトランザクションログは、空き容量の低下に大きく寄与します。
次のグラフは、Amazon RDS PostgreSQL インスタンスの FreeStorageSpace メトリクスを示しています。FreeStorageSpaceが 20 分で約 90% 低下したことを示しています。

この問題のトラブルシューティング中に、パラメータ log_min_duration_statement が 0 に設定されました。つまり、各 SQL ステートメントがログに記録され、トランザクションログファイルがいっぱいになりました。これらのトラブルシューティング手順と CloudWatch グラフは、データベースエンジンを調整するタイミングやインスタンスストレージをスケールアウトするタイミングを決定するのに役立ちます。
データベース接続
DatabaseConnections メトリクスは、使用中のデータベース接続の数を決定します。ワークロードを最適化するには、現在の接続数が最大接続数の約 80% を超えないようにする必要があります。max_connections パラメータは、Amazon RDS で認められる接続の最大数を決定します。これはパラメータグループで変更できます。詳細については、「DB パラメータグループの操作」を参照してください。
このパラメータのデフォルト値は、インスタンスの合計 RAM によって異なります。たとえば、Amazon RDS MySQL インスタンスの場合、デフォルト値は式 {DBInstanceClassMemory/12582880} によって導出されます。
データベース接続の数が一貫して約 80% の max_connections である場合は、より高い RAM を持つ Amazon RDS インスタンスクラスに移動する必要があります。これにより、Amazon RDS がより多くのデータベース接続を持つことができるようになります。たとえば、Amazon RDS PostgreSQL インスタンスは db.t2. スモールインスタンスでホストされ、式 LEAST({DBInstanceClassMemory/9531392},5000) はデフォルトで max_connections を 198 に設定します。
このインスタンスの値は、Amazon RDS コンソールと AWS コマンドラインインターフェイス (CLI) を介して、またはインスタンスに接続することで確認できます。次のコードを参照してください。
次の CloudWatch グラフは、データベース接続が 12:40 から 12:48 の間に max_connections 値を複数回超えたことを示しています。

DB 接続の数が max_connections 値を超えると、次のエラーメッセージが表示されます。
この状況では、データベース接続の数が多い原因を特定する必要があります。ワークロードにエラーがない場合は、より多くのメモリを備えた Amazon RDS インスタンスクラスにスケールアップすることをご検討してください。
1 秒あたりの I/O 操作 (IOPS) メトリクス
ストレージのタイプとサイズにより、Amazon RDS SQL Server、Oracle、MySQL、MariaDB、および PostgreSQL インスタンスでの IOPS 割り当てが決まります。汎用 SSD ストレージでは、ベースライン IOPS は GiB のストレージ量の 3 倍として計算されます。インスタンスのパフォーマンスを最適化するには、ReadIOPS と WriteIOPS の合計が、割り当てられた IOPS を下回る必要があります。
バースト容量を超えると、IOPS の使用量が増えて、パフォーマンスが低下する可能性があります。これは、ReadLatency、WriteLatency、および DiskQueueDepth の増加として現れます。合計 IOPS ワークロードが常にベースライン IOPS の 80% 〜90% である場合は、インスタンスを変更し、より高い IOPS 容量を選択することをご検討ください。これを実現するには、汎用 SSD ストレージを増やすか、ストレージタイプをプロビジョンド IOPS に変更するか、Aurora を使用するといった方法があります。
汎用 SSD ストレージの増加
汎用 SSD ストレージを増やして、インスタンスが GiB の 3 倍のストレージ容量を取得できるようにします。MySQL、MariaDB、Oracle、および PostgreSQL の Amazon RDS DB インスタンスを最大 64 TiB のストレージで作成できますが、達成できる最大ベースラインパフォーマンスは 16,000 IOPS です。つまり、5.34 TiB から 64 TiB のストレージボリュームの場合、インスタンスのベースラインパフォーマンスは最大 16,000 IOPS になります。ReadIOPS が合計 IOPS 消費に貢献していることがわかった場合は、より多くの RAM を持つより高いインスタンスクラスに移動する必要があります。データベースのワーキングセットがほぼすべてメモリ内にある場合、ReadIOPS は小さく、安定しているはずです。
次の例では、Amazon RDS PostgreSQL インスタンスが 100 GiB GP2 ストレージで設定されています。このストレージは、300 IOPS の容量と長期間のバースト機能を提供します。次のグラフが示すように、3 月 27 日の 12:48 の WriteIOPS は 480 で、ReadIOPS は 240 でした。これらの合計 (720) は、ベースライン容量の 300 をはるかに超えていました。これにより、WriteLatecny と DiskQueueDepth が高くなりました。
次のグラフは、12:48 の時点で WriteIOPS 値が 480 であることを示しています。

次のグラフは、12:48 の時点で ReadIOPS 値が 240 であることを示しています。

次のグラフは、12:48 の時点で WriteLatency が 78 ms と高いことを示しています。

次のグラフは、12:48 の時点で DiskQueueDepth が 38 と高いことを示しています。

プロビジョンド IOPS
インスタンスに 16,000 を超えるベースライン IOPS または低い I/O レイテンシーと一貫した I/O スループットが必要な場合は、ストレージタイプをプロビジョンド IOPS に変更することをご検討ください。MariaDB、MySQL、Oracle、PostgreSQL では、1000〜80,000 の範囲の PIOPS を選択できます。
Amazon Aurora
データベースの IOPS パフォーマンスが特定の数に制限されていない場合は、Amazon Aurora の使用をご検討ください。制限は、ストレージボリュームのサイズまたはタイプによって決まる場合があります。Aurora には同じタイプの IOPS 制限はなく、IOPS 容量を管理、プロビジョニング、または拡張する必要はありません。インスタンスサイズは、主に Aurora ワークロードのトランザクションとコンピューティングのパフォーマンスを決定します。IOPS の最大数は、Aurora インスタンスの読み取り/書き込みスループット制限に左右されます。IOPS が原因でスロットルされることはありませんが、インスタンスのスループット制限が原因でスロットルされることはあります。詳細については、「DB インスタンスクラスの選択」を参照してください。
Aurora は、MySQL および PostgreSQL 互換のリレーショナルデータベースソリューションで、分散型のフォールトトレラントな自己修復ストレージシステムを備えています。Aurora ストレージは自動的に 64 TiB まで拡張します。Aurora は、1 つのリージョンで最大 5 つのレプリカを提供する Amazon RDS エンジンと比較して、最大 15 のリードレプリカを提供します。
スループット制限
Amazon RDS インスタンスには、2 種類のスループット制限があります。インスタンスレベルと EBS ボリュームレベルの制限がそれです。
WriteThroughput と ReadThroughput のメトリクスを使用してインスタンスレベルのスループットをモニタリングできます。WriteThroughput は、ディスクに書き込まれた 1 秒あたりの平均バイト数です。ReadThroughput は、ディスクから読み取られた 1 秒あたりの平均バイト数です。たとえば、db.m4.16xlarge インスタンスクラスは、最大で 1,250 MB/s のスループットをサポートします。EBS ボリュームのスループット制限は、16 KiB I/O サイズに基づく GP2 ストレージでは 250 MiB/s、プロビジョンド IOPS ストレージタイプでは 1,000 MiB/s です。スループットのボトルネックが原因でパフォーマンスが低下した場合は、これらの両方の制限を検証し、必要に応じてインスタンスを変更する必要があります。
Amazon RDS Performance Insights
Performance Insights はデータベースインスタンスのワークロードをモニタリングするため、データベースのパフォーマンスをモニタリングおよびトラブルシューティングできます。データベースのロードと待機イベントデータを利用して、インスタンスの状態の全体像を把握できます。データベース全体のパフォーマンスを向上させるために、このデータをインスタンスまたはワークロードの変更に活用できます。
次の CloudWatch グラフは、Aurora PostgreSQL インスタンスで高い CommitLatency を示しています。CommitLatency は 15:33 の時点で 68 ms です。

次のグラフは、15:33 と 15:45 の間に IO:XactSync が高いことを示しています。

Performance Insights を見ると、CommitLatency が高いときに待機イベント IO:XactSync も高かったことがわかります。この待機イベントは CommitLatency に関連付けられており、トランザクションのコミットが永続的になるまで待機するのに費やされた時間です。これは、セッションが安定したストレージへの書き込みを待機しているときに発生します。この待機は、システムでコミットアクティビティが頻繁に発生する場合に最もよく発生します。このレイテンシーの間、Aurora は Aurora ストレージが永続性を確認するのを待機しています。この場合、ストレージの永続性は、必要な CPU で、CPU を集中的に使用するデータベースワークロードと競合する可能性があります。このシナリオを緩和するには、これらのワークロードを減らすか、より多くの vCPU を備えた DB インスタンスにスケールアップします。
まとめ
この記事では、Amazon RDS と Performance Insights に関連する CloudWatch メトリクスと、それらを用いてデータベースに関する決定を行う方法について説明しました。これらのメトリクスは、コンピューティングとストレージのスケーリング、データベースエンジンのパフォーマンスチューニング、およびワークロードの変更を決定するのに役立ちます。
この記事では、Amazon RDS が提供するさまざまなストレージクラスと、Amazon Aurora の動作が EBS ボリュームを使用する Amazon RDS インスタンスと比較してどう異なるかについても確認しました。この点を理解していると、Amazon RDS をトラブルシューティングし、評価し、その変更を決定する際に役立ちます。
詳細については、「CloudWatch メトリクスを使用して RDS データベースの汎用またはプロビジョンド IOPS を決定する方法」と「Amazon RDS Performance Insights の使用」を参照してください。
著者について

Vivek Singh は、Amazon RDS/Aurora PostgreSQL エンジンを専門とする AWS のシニアデータベーススペシャリストです。Vivek はエンタープライズカスタマーと連携して、PostgreSQL の運用パフォーマンスに関する技術的なサポートを提供し、データベースのベストプラクティスをもたらしています。