Amazon Web Services ブログ
Kinesis Data Firehose で Amazon S3 への動的パーティショニングのサポートを開始
Amazon Kinesis Data Firehose は、ストリーミングデータをデータレイク、データストア、および分析サービスに確実にロードするための便利な方法を提供します。Amazon Simple Storage Service (Amazon S3)、Amazon Redshift、Amazon OpenSearch Service、汎用 HTTP エンドポイント、および Datadog、New Relic、MongoDB、Splunk などのサービスプロバイダーにストリーミングデータをキャプチャ、変換、配信することができます。Amazon Kinesis Data Firehoseは、データのスループットに合わせて自動的にスケーリングされるフルマネージドサービスであり、継続的な管理を必要としません。また、データストリームをロードする前にバッチ、圧縮、変換、暗号化できるため、ストレージの使用量が最小限に抑えられ、セキュリティが向上します。
Amazon Kinesis Data Firehose を使用するお客様は、多くの場合、分析のためにデータを送信先に送る前に、各コードに含まれる情報に基づいて受信データを動的に分割したいと考えています。その一例として、モノのインターネット (IoT)から受信したデータを生成したデバイスの種類 (Android、iOS、FireTV など) に基づいてセグメント化することが挙げられます。以前は、この機能を実現するには、データが Amazon S3 に書き出されたあとに全く別のジョブを実行してデータをパーティショニングし直す必要がありました。
Kinesis Data Firehose の動的パーティショニングは、Amazon S3 に配信される前に転送中のデータを自動でパーティショニングすることにより、ストリーミングデータの Amazon S3 データレイクへの取り込みを簡素化します。これにより、分析ツールでデータセットをすぐに利用できるようになり、クエリを効率的に実行できるようになり、データのきめ細かいアクセス制御が強化されます。たとえば、マーケティングオートメーションの顧客は、顧客 ID でデータをその場で分割できます。これにより、顧客固有のクエリで、より小さなデータセットに対してクエリすることができ、より早くクエリ結果を配信することができます。IT 運用またはセキュリティ監視を行うお客様は、ログに埋め込まれたイベントのタイムスタンプに基づいてグループを作成できるため、より小さなデータセットに対してクエリを実行することができ、より早く結果を得ることができます。
この記事では、Kinesis Data Firehose の新機能である動的パーティショニング機能、動的パーティショニング配信ストリームの作成方法について説明し、Amazon S3 に配信される動的にパーティショニングされたデータが、システム全体のパフォーマンスとスケーラビリティを向上させることができる具体例について説明します。次に、良いパーティションキーを作る条件、ネストされたフィールドの扱い方、前処理とエラー処理のための Lambda との統合に関するベストプラクティスについて説明します。最後に、Kinesis Data Firehose の動的パーティショニングの制限とクォータ、およびいくつかの料金シナリオについて説明します。
Kinesis Data Firehose を使用した動的パーティショニング
まず、Kinesis Data Firehose に標準搭載されているタイムスタンプベースのデータパーティショニングの代わりに動的パーティショニングを使用する理由について説明します。Amazon S3 のデータレイクにある分析データを特定のフィールド (顧客識別情報 customer_id など) に従ってフィルタリングする必要があるシナリオを考えてみましょう。標準のタイムスタンプベースの方法を使用すると、データは次のようになります。<DOC-EXAMPLE-BUCKET>はバケット名を表します。
このような一連のデータの中から特定の顧客を見つけ出すのは困難です。個々の顧客を見つけ出すためには、フルファイルスキャンが必要になります。次に、識別フィールドである customer_id によって分割されたデータを考えてみましょう。
動的パーティションニングを使えば、 1 つのフォルダをスキャンするだけで特定の顧客に関連するデータを検索することができます。これは、Amazon Athena、Amazon Redshift Spectrum、Presto などの分析クエリエンジンで機能するように設計されている方法です。クエリ実行中に不要なパーティションを刈り取ることで、スキャンおよび転送されるデータの量を削減します。このようにデータを分割すると、全体的にスキャンされるデータが少なくなります。
主な機能
Kinesis Data Firehose の動的パーティショニングの提供開始により、新しい Kinesis Data Firehose 配信ストリームを作成するときに、AWS マネジメントコンソール、AWS コマンドラインインターフェイス(AWS CLI)、または AWS SDK 上でデータ内容に基づく動的パーティショニングを有効にできるようになりました。
Kinesis Data Firehose の動的パーティショニングを使用すると、使いやすいクエリエンジンで JSON データフィールドを選択して抽出できるため、受信レコードから配信ストリームにキーを簡単に抽出できます。
Kinesis Data Firehose の動的パーティショニングとキー抽出により、Amazon S3に格納されるファイルサイズは大きくなりますが、クエリエンジンと相性の良い Apache Parquet のような列指向のデータ形式を使用できます。
Kinesis Data Firehose の動的パーティショニングでは、区切り文字を指定して、受信レコードを検出または追加することができます。これにより、Amazon Athena や AWS Glue のようなクエリエンジンが期待するような形式でデータをクリーンアップし、整理することができます。これにより、時間が節約されるだけでなく、事後処理のプロセスも削減され、プロセスのコストが削減される可能性があります。
Kinesis Data Firehose には、JSON 形式のレコードを分割するためのキーを抽出するための方法が組み込まれています。jq 構文を使用して、パーティショニングで使用する JSON データフィールドを選択して抽出できます。これらのフィールドは、Amazon S3 に配信されるときにデータがどのように分割されるかを指定します。この記事後半のチュートリアルで説明するように、動的パーティションニングを使用する Kinesis Data Firehose 配信ストリームを最適化するには、適切に分散されたパーティションキーの組み合わせを選択することが不可欠です。
受信データが圧縮、暗号化されている、またはその他のファイル形式である場合は、PutRecord または PutRecords API でパーティション分割用のデータフィールドを呼び出すことができます。統合された Lambda 関数を独自のカスタムコードとともに使用して、レコードを解凍、復号化、または変換して、パーティション分割に必要なデータフィールドを抽出して返却することもできます。これは、Kinesis Data Firehose で現在利用可能な既存の変換 Lambda 関数を拡張したものです。同じ Lambda 関数を使用して、データフィールドを変換、解析、および返却することができます。
データを Amazon S3 に格納するときに大きなファイルサイズを実現するために、Kinesis Data Firehose は受信ストリーミングデータを Amazon S3 に配信する前に、指定されたサイズまたは期間にバッファリングします。データが Amazon S3 に配信されるときのバッファサイズの範囲は 64 MiB から 128 MiB で、バッファリング間隔は 1 分から 15 分の範囲です。
パーティション構造の例
次のクリックストリームイベントを考えてみましょう。
動的パーティショニングを使えば customer_id でデータを分割できるようになります。動的パーティションキーとして機能する JSON フィールドを指定するだけで、Kinesis Data Firehose は同じ customer_id を持つすべてのイベントを自動的にグループ化し、宛先 S3 バケット内の別々のフォルダに配信します。このとき新しいフォルダは自動的に作成されます。
今回、S3 データレイクに次のフォルダ構造が必要であると仮定しましょう。
先程の例を実現する Kinesis Data Firehose の設定は、次のスクリーンショットのようになります。
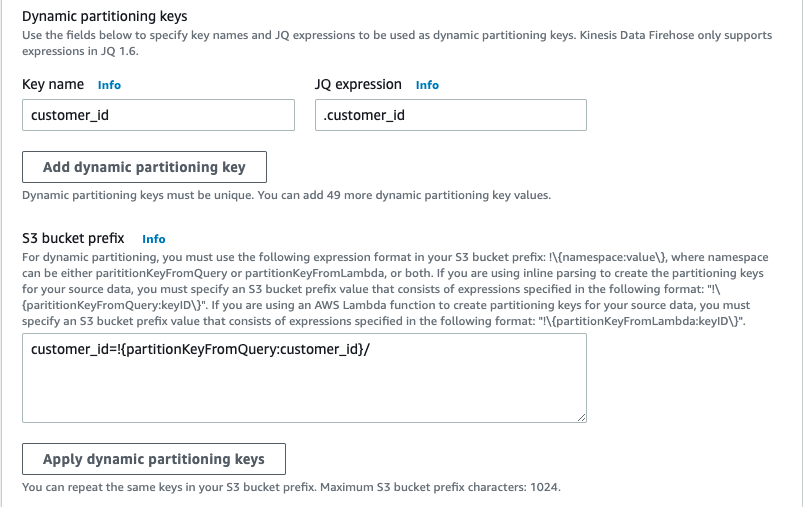
Kinesis Data Firehose は実行時にプレフィックス式を評価します。評価された S3 プレフィックス式に一致するレコードを 1 つのデータセットにグループ化します。その後、Kinesis Data Firehose は各データセットを評価された S3 プレフィックスに配信します。S3 へのデータセット配信の頻度は、配信ストリームバッファの設定によって決まります。
jq JSON プロセッサを使用すると、ネストされたフィールドにアクセスしたり、複雑なクエリを作成してデータ内の特定のキーを識別したりするなど、さらに多くのことが行えます。
次の例では、特定の顧客のモバイルデバイスによってスキャンできるようにイベントを保存することにしました。
イベントは先程と同じものを利用しています。次のスクリーンショットに示すように、Kinesis Data Firehose プレフィックス式の device フィールドと customer_id フィールドの両方を使用します。deviceはネストされた JSON フィールドであることに注意してください。
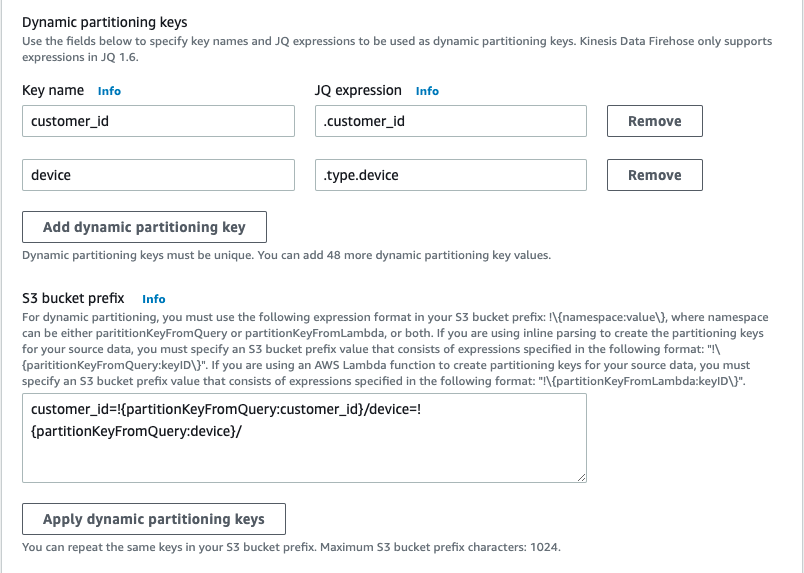
生成される S3 フォルダ構造は次のようになります。<DOC-EXAMPLE-BUCKET>はバケット名です。
ここで、イベントが実際に送信された時刻に基づいてデータを分割すると仮定します。
Kinesis Data Firehose がネイティブサポートするApproximateArrivalTimestampを使用する場合、レコードが正常に受信されてストリームに格納された時刻をUTCで表したものが使用されます。この時刻はレコード内に記載されているevent_timestampフィールドの時刻とは異なる場合があります。 また、event_timestampには別のタイムゾーンが用いられていることもあるかもしれません。
Kinesis Data Firehose の動的パーティショニングを使用すると、フィールド値をその場で抽出し、変換できます。次のスクリーンショットに示すように、event_timestamp フィールドを使用して、イベントを年、月、日で分割します。jqにはエポック秒を日時に変換するstrftime関数が用意されています。

前述の式は、次の S3 フォルダ構造を生成します。<DOC-EXAMPLE-BUCKET>はバケット名です。
動的にパーティション分割された配信ストリームの作成
動的に分割されたデータを Amazon S3 に配信する設定を行います。
マネージメントコンソールからKinesisを検索・選択してAmazon Kinesis コンソールページに移動します。
そこで Kinesis Data Firehose のラジオボタンをクリックし、配信ストリームを作成 を選択し、ソースと宛先を選択します。
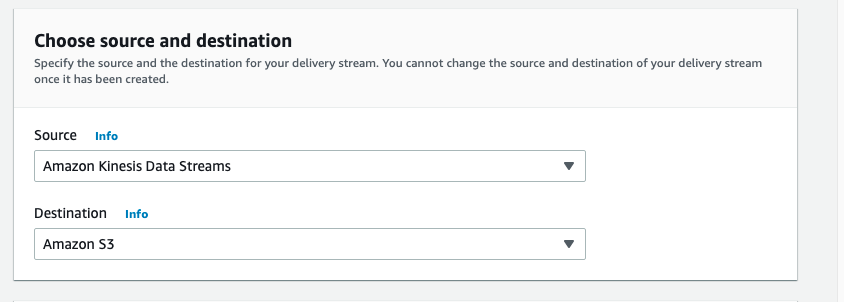
この例では、Kinesis Data Stream からデータを受信しますが、配信ストリームのソースとして Direct PUT またはその他のソースを選択することもできます。
宛先として、Amazon S3 を選択します。
次に、読み込み元の Kinesis Data Stream を選択します。以前に作成した Kinesis Data Stream がある場合は、Browse を選択してリストから選択します。そうでない場合は、Kinesis Data Stream の作成方法に関するこのガイドに従ってください。
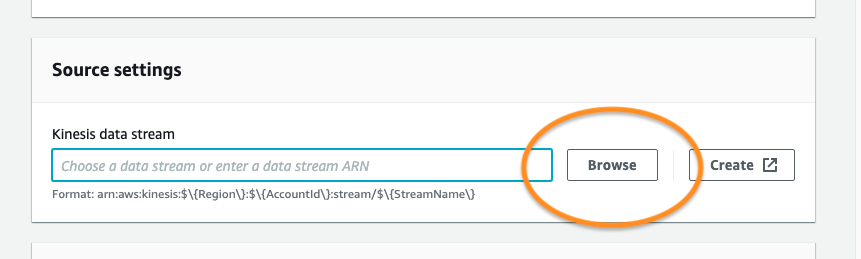
配信ストリームに名前を付け、作成ウィザードの Transform and convert records セクションに進みます。
AWS Lambda でソースレコードを変換するために、データ変換を有効にすることができます。このプロセスは次のセクションで説明します。また、AWS Lambda 変換とレコード形式の変換の両方を無効にしておきます。
S3 の送信先として、配信ストリームがアクセス権限を持つ S3 バケットを選択または作成します。

指定した jq クエリに基づいて異なる S3 バケットプレフィックスにデータを配信するためには、この箇所で動的パーティショニングを有効にします。

上のスクリーンショットに示すように、次の機能を有効にするオプションが追加されました。
- マルチレコードの集約解除 – 配信ストリームに入るレコードを、有効なJSON条件または改行区切り文字(
\nなど)に基づいて分離します。これは、特定の形式で配信ストリームに入力されるデータで、その後利用する分析エンジンに合わせて再フォーマットする必要がある場合に便利です。 - 改行区切り文字 — Amazon S3 に配信されるオブジェクト内のレコード間に新しい行区切り文字 (
\nなど) を追加するように配信ストリームを設定します。 - JSON のインライン解析 — 動的パーティショニングキーとして使用するデータレコードパラメータを指定し、各キーに値を指定します。

パーティショニングに掛かる設定は、パーティショニンに用いるキーと値のペアを追加し、Apply dynamic partitioning Keys を選択して、S3 バケットプレフィックスにパーティショニングスキーマを設定するだけです。続行する前に S3 バケットのエラープレフィックスも指定する必要があることに注意してください。
S3 バッファリング条件は、ユースケースに合わせて適切に設定します。私の例では、バッファリングは配信されるデータが 1 MiB 以上になったとき、または60秒毎に Amazon S3 にデータを配信するように設定しました。
残りの設定はデフォルトのままにして、配信ストリームの作成 を選択します。
データがパイプラインに流れ始めると、指定したバッファ間隔の後に、データはKinesis Data Firehose 内の設定に従ってパーティション化されS3 に送信されます。
動的パーティショニング機能が有効になっていない配信ストリームの場合、すべての受信データに対して 1 つのバッファが存在します。動的パーティショニングを有効にすると、Kinesis Data Firehose は、受信レコードに基づいて、パーティションごとにバッファを持ちます。デリバリーストリームは、サイズまたは間隔の制限に達すると、他のパーティションとは無関係に、データの各バッファを単一のオブジェクトとして配信します。
非 JSON レコードの Lambda 変換
Kinesis Data Firehose を通過するデータが圧縮、暗号化済み、または JSON 以外のファイル形式である場合、動的パーティションニング機能では、 jq 構文を使用して個々のフィールドを解析することはできません。非 JSON レコードで動的パーティショニング機能を使用するには、Kinesis Data Firehose と統合された Lambda 関数を使用して、jq を使用してデータを適切にパーティション分割するために必要なフィールドを変換および抽出します。
次の Lambda 関数は、ユーザーペイロードをデコードし、Kinesis Data Firehose の動的パーティションニングキーに必要なフィールドを抽出し、パーティションキーが外側のペイロードにカプセル化された適切な Kinesis Data Firehose ファイルを返します。
Lambda を使用して動的パーティショニングに必要なフィールドを抽出すると、暗号化データと圧縮データの利点と、レコードフィールドに基づいてデータを動的にパーティション分割する利点の両方を享受できます。
制限とクォータ
Kinesis Data Firehose 動的パーティショニング では、データをアクティブにバッファリングしている間、配信ストリームあたり 500 のアクティブパーティションの制限があります。これは、設定されたバッファリングヒント中に配信ストリームに存在するアクティブなパーティションの数です。この制限は調整可能で、引き上げたい場合は、制限引き上げのためのサポートチケットを送信する必要があります。
jq 選択クエリによって決定される新しい値ごとに、Kinesis Data Firehose 配信ストリームに新しいパーティションが作成されます。パーティションには、評価されたパーティションプレフィックスで Amazon S3 に配信されるデータのバッファが関連付けられています。Amazon S3 への配信時に、以前にそのデータを保持していたバッファと関連パーティションが削除され、Kinesis Data Firehose のアクティブなパーティション数から差し引かれます。
配信ストリームに送信された次のレコードを考えてみましょう。
動的パーティショニングに customer_id を使用し、異なるプレフィックスにレコードを配信する場合、すべての顧客のレコードの取り込みを続けると、3 つのアクティブなパーティションが作成されます。customer_id: "123" のレコードがない場合、Kinesis Data Firehose はバッファを削除し、2 つのアクティブなパーティションのみを保持します。
アクティブなパーティションの最大数を超えると、配信ストリームの残りのレコードは S3 エラープレフィックスに配信されます。詳細については、このブログ投稿の「エラー処理」セクションを参照してください。
1 秒あたり 25 MB の最大スループットは、アクティブなパーティションごとにサポートされます。この制限は調節できません。perPartitionThroughput という新しいメトリクスを使用して、スループットを監視できます。
ベストプラクティス
適切なパーティション分割は、Amazon Athena などの分析サービスによってスキャンされるデータ量に関連するコストを節約するのに役立ちます。一方、過剰なパーティショニングは、より小さなオブジェクトが作成され、コストパフォーマンスの利点がなくなる可能性があります。
Amazon Athenaでの適切なパーティショニングやパフォーマンス・チューニングについてはAmazon Athena のパフォーマンスチューニング Tips トップ 10を参照してください。
2 つのシステム間の互換性を高めるために、パーティションキーを後続の分析クエリと一致させることをお勧めします。同時に、高いカーディナリティが動的パーティショニングのアクティブパーティション制限にどれだけ影響するかを考慮してください。
動的パーティション分割に使用するフィールドを決定する際は、ビジネスケースに一致するフィールドを選択することと、パーティション数の制限を考慮することのバランスが重要です。新しいメトリック partitionCount を使用してアクティブなパーティションの数を監視し、バイナリメトリック partitionCountExceeded を使用して、パーティション数が制限を超えたかどうかを監視できます。
コストを最適化するもう 1 つの方法は、イベントを 1 つの PutRecord および PutRecordBatch API 呼び出しに集約することです。Kinesis Data Firehose は取り込みデータの GB 単位で課金されます。これは、サービスに送信するデータレコードの数と、最も近い 5 KB に切り上げられた各レコードのサイズを乗算して計算されるため、取り込み呼び出しごとにさらに多くのデータを配置できます。
動的パーティショニング機能は、データが集約解除された後に実行されるので、各イベントは、各イベント内の partitionKey フィールドに基づいて、対応する Amazon S3 プレフィックスに送信されます。
エラー処理
次のレコードが Kinesis Data Firehose 配信ストリームに入るとします。
動的パーティションクエリがこのレコードをスキャンすると、指定されたキー customer_id を見つけることができないため、エラーが発生します。このシナリオでは、Kinesis Data Firehose ストリームを作成または変更するときに、S3 エラープレフィックス を使用することをお勧めします。

失敗したレコードはすべて エラープレフィックスに配信されます。そのため、パーティションキーとして指定したフィールドのないイベントはエラープレフィックスで見つかるでしょう。
コストと料金の例
Kinesis Data Firehose の動的パーティショニングは、S3 に配信されたパーティション化されたデータの GB ごと、オブジェクトごと、およびjqを使用した場合にはデータ解析の jq の処理時間ごとに課金されます。料金は、ストリームを作成した AWS リージョンによって異なる場合があります。
詳細については、料金ページをご覧ください。
まとめ
この記事では、Kinesis Data Firehose の動的パーティショニング機能について紹介し、この機能がパイプラインのパフォーマンスの向上に役立つユースケースを検討しました。また、動的パーティショニングを使用して Kinesis Data Firehose パイプラインを開発および最適化する方法と、信頼性の高い配信ストリームの構築に関するベストプラクティスについても説明しました。
Kinesis Data Firehose の動的パーティショニングは、ローンチ時にすべてのリージョンで利用できるようになります。是非、この新機能をお試しいただき、配信ストリームとクエリエンジンのパフォーマンスをいかに簡素化できるかをご確認ください。新機能に関するご意見は、お気軽にお知らせください。
翻訳はソリューションアーキテクトの児玉が担当しました。原文はこちらです。本記事は翻訳にあたり、一部記述を追加しています。