Amazon Web Services ブログ
Amazon Braket Hybrid Jobs のご紹介 – 量子/古典ハイブリッドアルゴリズムのワークロードを設定およびモニタリングし、効率的に実行する
量子コンピューティングは魅力的です! 端的に言えば、量子コンピューティングは、0 または 1 の値を持つビットの概念を、2 つの異なる (量子) 状態の組み合わせを持つことができる量子ビットに拡張するものです。
2 つの特性により、量子ビットは非常に興味深いものとなっています。
- 量子ビットの値を見ると、2 つの状態のうち 1 つの状態のみを、その独自の状態がどのように組み合わせられているかに応じて異なる確率とともに確認できます。
- ある量子ビットの状態を変えることで、あるいはその値を読み取るだけでも、他の量子ビットの状態を変えることができるように、複数の量子ビットを「つなぐ」(量子もつれと呼ばれます) ことができます。
これらの特性は、量子力学 (原子および亜原子のレベルで自然の物理的性質を説明する物理学の基礎理論) によって説明される低レベルの性質から得られます。幸いなことに、普通のコンピュータを使うのに半導体のエキスパートである必要がないのと同じように、量子コンピューティングを使うのに量子力学の学位は必要ありません。
研究者は、量子ビットを使用して、古典コンピュータが実現できるよりもはるかに高速になる可能性を秘めている新しいアルゴリズムを設計しています。量子コンピューティング分野における科学研究とソフトウェア開発をスピードアップするために、当社は re:Invent 2019 で Amazon Braket を発表しました。フルマネージドの量子コンピューティングサービスである Amazon Braket では、シミュレーターや量子コンピュータで量子アルゴリズムを構築、テスト、および実行できます。
ハイブリッドアルゴリズムと量子処理装置 (QPU)
多くの異なる領域においてさまざまな態様で活用される量子アルゴリズムは、数十万から数百万の量子ゲートの実行を必要とします。残念ながら、現行世代の QPU はノイズの影響を受けているため、エラー発生前のオペレーションをわずか数百または数千のゲートに制限するエラーを引き起こします。
この問題の解決に役立てるため、機械学習からインスピレーションを得ることができます。すなわち、アルゴリズムを実装するロジックである固定量子回路を使用する代わりに、回路をチューニングするパラメータを調整することによってアルゴリズムに「学習」させ、特定のデバイスでノイズに合わせて適応させることで特定の問題を解決する可能性が高くなるようにします (「自己学習量子アルゴリズム」とお考えください)。
これはコンピュータビジョンと似ています。犬と猫を区別する (このことがコンピュータにとって困難であることは悪名高く知られている事実です) ための機能を人が作業して作成するのではなく、ニューラルネットワークのパラメータを繰り返し調整することによって、機械学習アルゴリズムが適切な特徴を「学習」します。
急速に発展している量子コンピューティングの研究分野では、機械学習で GPU が使用されるのと同じように、量子コンピュータが使用するプロセッサである QPU を使用しています。量子回路はパラメータ化され、いくつかの値で初期設定されて、QPU で実行されます。ニューラルネットワークの重みと同様に、これらのパラメータはコンピューティング結果に基づいて繰り返し調整されます。これらのいわゆるハイブリッドアルゴリズムは、古典コンピュータと QPU 間の高速で反復的なコンピューティングに依拠しています。

ハイブリッドアルゴリズムを実行するには、古典的なインフラストラクチャを手動でセットアップし、必要なソフトウェアをインストールして、ハイブリッドアルゴリズムの実行中、量子コンピューティングプロセスとクラシックコンピューティングプロセス間のインタラクションを管理する必要があります。その後、カスタムモニタリングソリューションを構築して、アルゴリズムの進行状況を視覚化し、想定どおりに解に収束するようにするか、必要に応じて介入してアルゴリズムのパラメータを調整する必要があります。
もう 1 つの大きな課題は、QPU が共有されており、伸縮自在ではないリソースであるため、アクセスをめぐって他のユーザーと競合することです。これにより、アルゴリズムの実行速度が低下する可能性があります。別の顧客からの 1 つの大きなワークロードによってアルゴリズムが停止し、ランタイムの合計時間が数時間長くなる可能性があります。これは不便なだけでなく、今日の QPU は定期的な再キャリブレーションが必要であり、ハイブリッドアルゴリズムの進捗を無効化する可能性があるため、結果の質にも影響します。最悪の場合、アルゴリズムが失敗し、予算と時間が無駄になります。
Amazon Braket Hybrid Jobs のご紹介
本日、Amazon Braket の新機能である Amazon Braket Hybrid Jobs をご紹介します。この機能を使用することで、ハイブリッド量子古典アルゴリズムのセットアップ、モニタリング、および効率的な実行のプロセスが簡素化されます。ジョブはフルマネージドであるため、インフラストラクチャやソフトウェアの大規模な管理を回避でき、QPU にオンデマンドで優先的にアクセスできるため、迅速かつ予測どおりに、確信に基づいてアルゴリズムを実行できます。
ジョブを作成する際、Amazon Braket はジョブインスタンスをスピンアップし Amazon Elastic Compute Cloud (Amazon EC2) インスタンスに基づいて CPU 環境を提供します)、アルゴリズムを (量子ハードウェアまたはシミュレーターを使用して) 実行して、ジョブが完了するとリソースを解放するため、お支払いいただくのは使用した分の料金のみとなります。また、アルゴリズムのカスタムメトリクスを定義することもできます。カスタムメトリクスは Amazon CloudWatch によって自動的にログ記録され、アルゴリズムの実行時に Amazon Braket コンソールにほぼリアルタイムで表示されます。これにより、アルゴリズムの進行状況に関するライブインサイトを得ることができ、必要に応じてアルゴリズムを調整したり、より迅速にイノベーションを起こしたりする機会が生まれます。
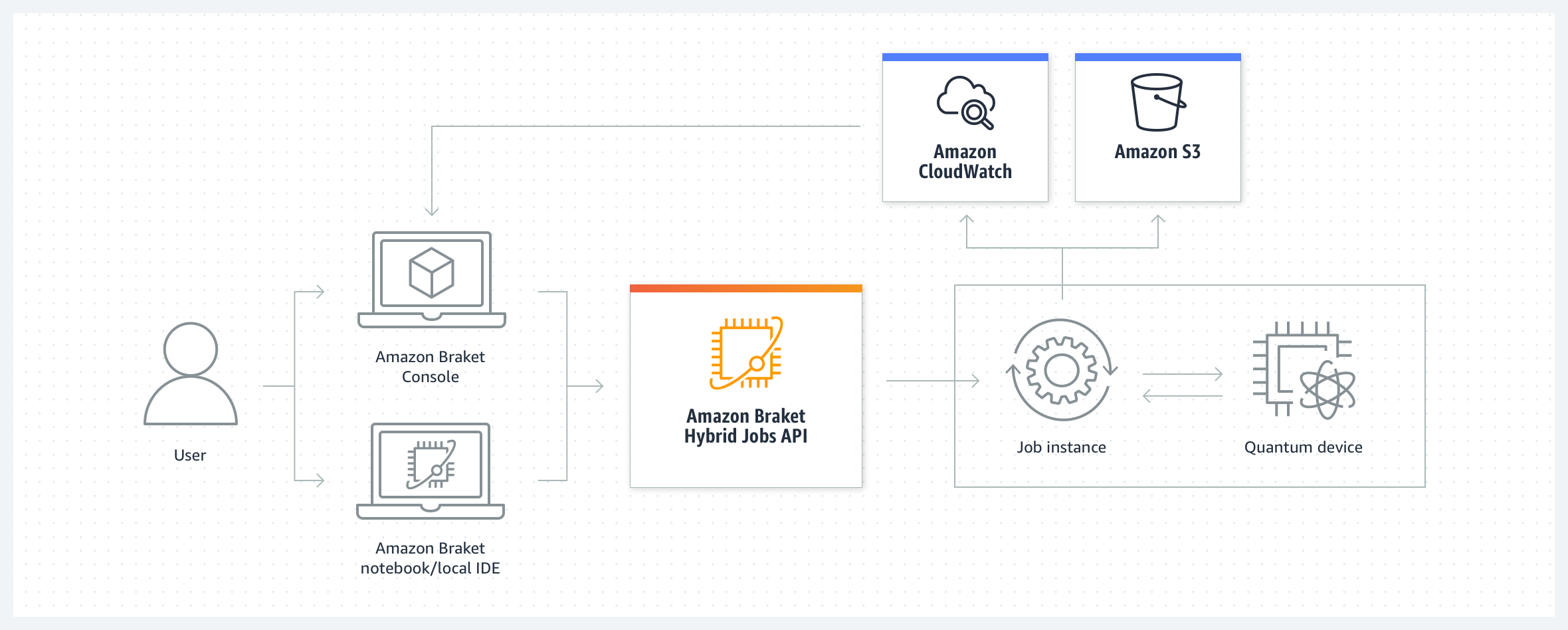
ハイブリッドアルゴリズムをジョブとして実行するには、Amazon Braket SDK を使用するか、ハイブリッド量子コンピューティング向けのオープンソースライブラリである PennyLane を使用してアルゴリズムを定義します。いくつかの例を通じて、これが実務でどのように機能するかを見てみましょう。
Amazon Braket Hybrid Jobs の使用
トレーニング可能な量子アルゴリズムを構築する前に、一連の固定量子演算を実行することから始めましょう。これを量子タスクと呼びます。Python と Amazon Braket SDK を使用して、いわゆるベル状態を構築する回路を定義します。ベル状態とは、2 つの状態それぞれに解決される確率が同じである状態をいいます。コイントスと同等の量子コンピューティングです。
algorithm_script.py ファイルの内容は次のとおりです。
import os
from braket.aws import AwsDevice
from braket.circuits import Circuit
from braket.jobs import save_job_result
def start_here():
print("Test job started!")
device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"])
results = []
bell = Circuit().h(0).cnot(0, 1)
for count in range(5):
task = device.run(bell, shots=100)
print(task.result().measurement_counts)
results.append(task.result().measurement_counts)
save_job_result({ "measurement_counts": results })
print("Test job completed!")このスクリプトでは、環境変数 AMZN_BRAKET_DEVICE_ARN を使用して、ジョブの作成時に選択したデバイスをインスタンス化します。
量子コンピューティングは確率論的なものです。このため、正確な結果を得るには、回路を複数回評価する必要があります。1 回の実行をショットといいます。ショット数が多いほど、結果の精度は高くなります。この事例では、回路は 100 ショット分実行されます。
save_job_result 関数を使用して、最後に分析できるようにジョブの結果を保存します。
Amazon Braket コンソールで、左側のパネルで [Jobs] (ジョブ) を選択し、[Create job] (ジョブを作成) を選択します。最初に、そのジョブに名前を付けます。

その後、アルゴリズムを使用してファイルを渡します。ハイブリッドアルゴリズムの CPU コンポーネントはコンテナ内で実行されます。使用するコンテナイメージを選択できます。例えば、PennyLane、TensorFlow、または PyTorch など、アルゴリズムが依存するソフトウェアを含む事前構築済みのコンテナイメージを使用したり、独自のカスタムイメージを使用したりできます。ここでは、外部の依存関係がないため、Base コンテナイメージを選択します。

その他のすべての設定はデフォルト値のままにします。このように、量子タスクの実行には、量子ハードウェアではなく SV1 シミュレーターを使用します。

しばらくするとジョブが完了し、Amazon Simple Storage Service (Amazon S3) コンソールへのリンクをたどって結果をダウンロードします。想定どおり、結果では、5 つのタスクそれぞれについて、00 と 11 の状態の比率がおよそ 50:50 であることが示されています。量子コンピューティングの確率論的な性質上、比率はわずかに異なります。
{
"braketSchemaHeader": {
"name": "braket.jobs_data.persisted_job_data",
"version": "1"
},
"dataDictionary": {
"measurement_counts": [
{
"00": 51,
"11": 49
},
{
"00": 44,
"11": 56
},
{
"11": 51,
"00": 49
},
{
"00": 56,
"11": 44
},
{
"00": 49,
"11": 51
}
]
},
"dataFormat": "plaintext"
}この例は、タスクを開始する以外に古典的なロジックを実行していないため、非常に基本的なものです。実際の値を確認するために、タスクごとに量子回路のパラメータを繰り返し微調整するハイブリッドアルゴリズムでどのように機能するかを見てみましょう。
ハイブリッドアルゴリズムを用いた Amazon Braket Hybrid Jobs の使用
より高度な例として、Braket コンソールからノートブックを作成する際に Amazon Braket によって提供される例に含まれる、量子近似最適化アルゴリズム (QAOA) と呼ばれる実際のハイブリッドアルゴリズムのよく知られた例を使用します。QAOA は、組合せ最適化の問題の近似解を生成する量子アルゴリズムです。この例は、この GitHub リポジトリでもご覧いただけます。
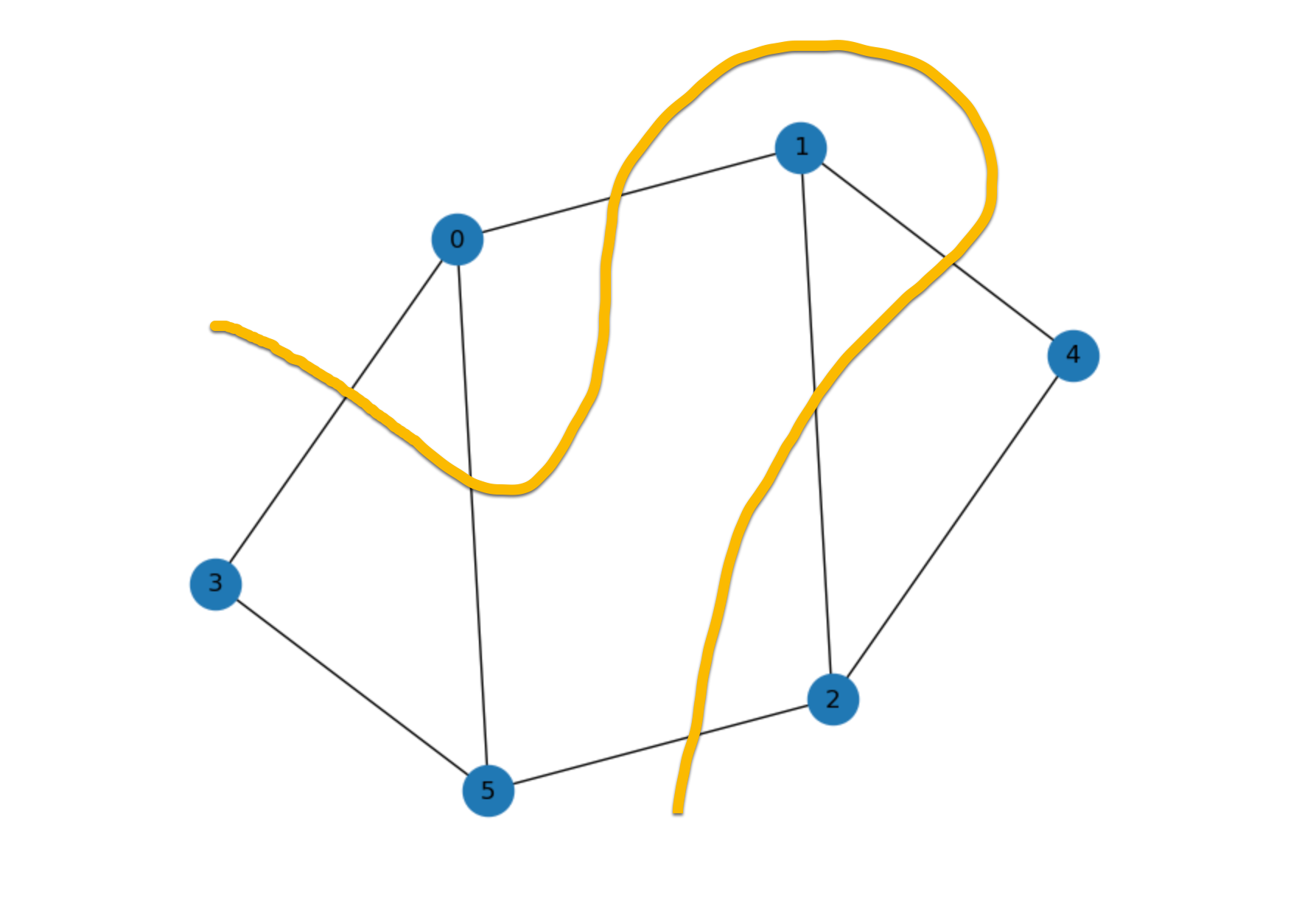
この事例では、QAOA を使用して Max-Cut 問題 (グラフのノードを 2 つに分割する場合、2 つの部分の間のノードを接続するエッジの最大数はいくつかという問題) を解決します。 例えば、次の図では、8 つのエッジで接続された 6 つのノードがあります。黄色の太い線は、6 つのエッジを交差させてノードを 2 つのセットに分割します。
QAOA の例では、量子タスクの連続ラウンドの実行に使用されるパラメータのチューニングは、TensorFlow や PyTorch などのツールを使用して、古典的なコンピューティング環境 (EC2 インスタンスなど) で最適化されています。ノートブックセルの 1 つでは、機械学習トレーニングの場合と同様の方法で、パラメータとその他のハイパーパラメータのチューニングに使用するインターフェイスを選択できます。
その後、Braket ジョブは、アルゴリズムの古典的なコンピューティング部分と量子コンピューティング部分の実行、およびそれらの間のパラメータと結果の交換を調整します。気を張ることなくアルゴリズムが収束するのを待ち、以前と同じように S3 から結果を取得して、より深い分析を行うことができます。
ローカルモードでのハイブリッドアルゴリズムの実行
Amazon Braket SDK では、ハイブリッドアルゴリズムのテストとデバッグを迅速に行うために、ローカルモードでジョブを実行できます。ローカルモードでは、Braket のジョブはご利用のマシン (ラップトップなど) でローカルに実行されます。この方法によれば、アルゴリズムの開発中に、迅速にフィードバックを得て、反復作業をすばやく実行できます。
ローカルモードでジョブを実行するのに必要なのは、AwsQuantumJob を LocalQuantumJob に置き換えることだけです。AwsQuantumJob は braket.aws からインポートされ、LocalQuantumJob は braket.jobs.local からインポートされることに留意してください。
利用可能なリージョンと料金
Amazon Braket Hybrid Jobs は、Amazon Braket が利用可能なすべての AWS リージョンで今すぐご利用いただけます。詳細については、AWS リージョン別のサービス表をご覧ください。
Amazon Braket Hybrid Jobs では、使用したリソースの料金のみをお支払いいただきます。古典的なインフラストラクチャをデプロイ、設定、および管理する必要がないため、アルゴリズムの実験と改善を繰り返し行うことが容易になります。詳細については、Amazon Braket の料金のページをご覧ください。
理論的研究に依拠する代わりに、ハイブリッドアルゴリズムを理解して改善し、産業や研究のユースケースへの適用性をテストするための主要なツールとして量子コンピュータを使用し始めることができます。この方法によれば、実験のためにこれらのさまざまなコンピューティングリソースの設定や調整を行うのではなく、研究に集中できます。
この新機能の開発中、当社はお客様やパートナーと話し合ってニーズを理解しました。「アプリケーションデベロッパーとして感じるのは、Braket Hybrid Jobs が、ハイブリッド変分アルゴリズムの可能性をお客様とともに探求する機会を与えてくれるということです」と QCWare のエンジニアリング担当責任者である Vic Putz 氏は述べています。「当社は、Amazon Braket との統合を拡張できることを嬉しく思っています。当社独自の専有アルゴリズムライブラリをカスタムコンテナで実行できるということは、当社が安全な環境で迅速にイノベーションを起こせるということを意味しています。Amazon Braket の運用上の成熟度と、さまざまな種類の量子ハードウェアへの優先アクセスの利便性により、当社は確信に基づいてこの新しい機能をスタックに組み込むことができます」
Amazon Braket Hybrid Jobs を使用して、ハイブリッド量子古典ワークロードの実行を簡素化します。
– Danilo
原文はこちらです。