Amazon Web Services ブログ
SaaS プラットフォームと Amazon SageMaker の統合で ML アプリケーションを実現する
Amazon SageMaker は、データの取り込み、変換、バイアスの測定や、学習、デプロイ、本番環境でのモデルの管理を行うための幅広い機能を備えたエンドツーエンドの 機械学習 (ML) プラットフォームです。そして Amazon SageMaker Data Wrangler, Amazon SageMaker Studio, Amazon SageMaker Canvas, Amazon SageMaker Model Registry, Amazon SageMaker Feature Store, Amazon SageMaker Pipelines, Amazon SageMaker Model Monitor, Amazon SageMaker Clarify などの、クラス最高のコンピュートとサービスと共に利用されています。SageMaker は開発者とデータサイエンティストに共通のツールセットを提供するため、多くの組織は SageMaker を ML プラットフォームとして採用しています。多くの AWS 独立系ソフトウェアベンダー (ISV) パートナーは、彼らの SaaS プラットフォームのユーザーが SageMaker とトレーニング、デプロイ、モデルレジストリを含む様々な SageMaker の機能を利用できるようにするために、既に統合環境を構築しています。
この投稿では、SaaS プラットフォームを SageMaker と統合するメリットや、可能な統合の範囲、そしてこれらの統合を開発するプロセスについて説明しています。また、これらの統合を促進するために、最も一般的なアーキテクチャと AWS リソースについて深掘りして説明します。これは同様の統合環境を構築している ISV パートナーや他の SaaS プロバイダーの市場投入までの時間を短縮し、SaaS プラットフォームのユーザーである顧客が、これらの統合によって SaaS プロバイダーと提携することができるように促すことを目的としています。
SageMaker と統合することのメリット
SaaS プロバイダーが自身の SaaS プラットフォームと SageMakerを統合するメリットは、多くあります。
- SaaS プラットフォームのユーザーが、SageMaker の包括的な ML プラットフォームを利用できます。
- ユーザーが、SaaS プラットフォーム内外のデータを利用して ML モデルを構築し、活用できます。
- SaaS プラットフォームと SageMaker 間のシームレスな体験をユーザーへ提供します。
- ユーザーは生成系 AI アプリケーションの構築に、 Amazon SageMaker JumpStart の基盤モデルを利用できます。
- 組織内の業務を SageMaker で標準化することができます。
- SaaS プロバイダーは、自身のコア機能に集中し、ML モデルの開発用に SageMaker を提供することができます。
- SaaS プロバイダーは、AWS を使用して共同ソリューションを構築し、市場投入する基盤を得ることができます。
SageMaker の概要と統合オプション
SageMaker は ML ライフサイクルのすべてのステップに対応するツールを備えています。SaaS プラットフォームは、以下の図が示すように、データのラベリングと準備から、モデルのトレーニング、ホスティング、監視、様々なコンポーネントを含むモデルの管理に至るまで、 ML ライフサイクルの全体にわたって SageMaker と統合することができます。要件に応じて、ML ライフサイクルの一部またはすべてを、顧客の AWS アカウントか、SaaS の AWS アカウントで実行することが可能で、 AWS Identity and Access Management (IAM) ポリシーやサードパーティが提供するユーザーベースのアクセスツールを利用して、それらのアカウント間でデータとモデルを共有することができます。この統合における柔軟性により、SageMaker は顧客と SaaS プロバイダーにとって標準化を行うための理想的なプラットフォームとなります。
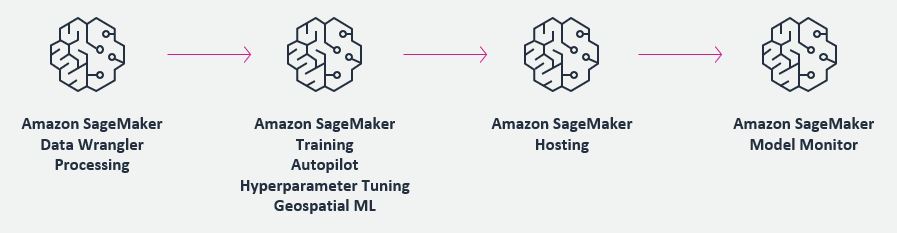
統合プロセスとアーキテクチャ
このセクションでは、統合プロセスを4つの主要なステージに分けて、一般的なアーキテクチャを説明します。これらに加えて、他の統合ポイントも存在する可能性がありますが、それらはあまり一般的ではないことに注意してください。
- データアクセス – SaaS プラットフォーム内のデータに SageMakerからどのようにアクセスするか
- モデルのトレーニング – モデルがどのようにトレーニングされるか
- モデルのデプロイとアーティファクト – モデルがどこにデプロイされ、どのようなアーティファクトが生成されるか
- モデルの推論 – SaaS プラットフォームで推論がどのように行われるか
以下のセクションの図は、SageMaker が顧客の AWS アカウントで実行されることを想定しています。説明されているオプションのほとんどは、SageMaker が SaaS の AWS アカウントで実行されている場合にも適用可能です。場合によっては、ISV が顧客の AWS アカウントにソフトウェアをデプロイすることがあります。これは通常、顧客専用の AWS アカウントであり、SageMaker が実行されている顧客の AWS アカウントへのクロスアカウントアクセスが依然として必要であることを意味します。
SaaS プラットフォーム内のデータが SageMaker からアクセスされ、ML モデルが SaaS プラットフォームから呼び出される際、AWS アカウント間で認証を実現するには、いくつか異なる方法があります。推奨する手段は、 IAM ロールを利用する方法です。別の手段としては、アクセスキー ID とシークレットアクセスキーで構成される AWS アクセスキーを利用する方法です。
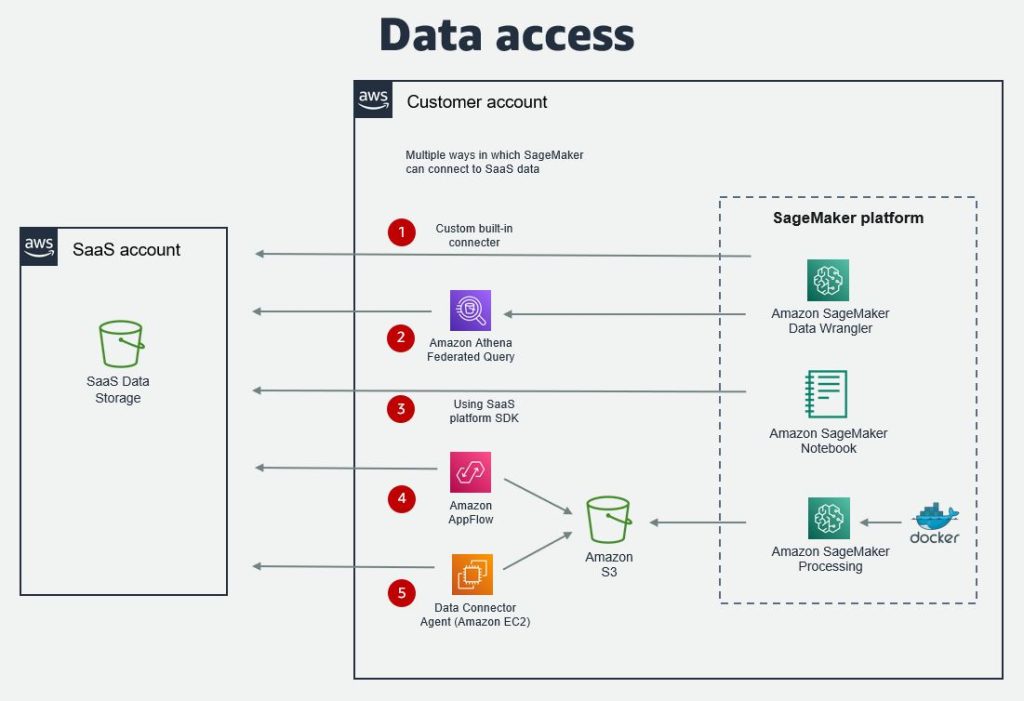
データアクセス
SaaS プラットフォーム内のデータが SageMaker からアクセスできるようにする選択肢は、複数あります。データは SageMaker ノートブックや、ユーザーがML 用にデータ準備を行える SageMaker Data Wrangler、あるいは SageMaker Canvas からアクセスすることができます。最も一般的なデータアクセスの選択肢は次の通りです。
- SageMaker Data Wrangler ビルトインコネクタ – SageMaker Data Wrangler コネクタを使用すると、SaaS プラットフォームからデータをインポートし、ML モデルのトレーニングの準備を行うことができます。
- SaaS プラットフォーム用の Amazon Athena Federated Query – Federated queries を使用すると、ユーザーは SaaS プロバイダーにより開発されたカスタムコネクタを利用して、Amazon Athena 経由で SageMaker ノートブックからプラットフォームにクエリを実行できるようになります。
- Amazon AppFlow – Amazon AppFlow を使用すると、カスタムコネクタを利用して Amazon Simple Storage Service (Amazon S3) へデータを抽出でき、その後は SageMaker からアクセスできるようになります。その SaaS プロバイダー用のコネクタは、AWS または SaaS プロバイダーにより開発が可能です。オープンソースの Custom Connector SDK を使用すると、Python または Java を使用して、プライベート、共有、またはパブリックのコネクタを開発することが可能です。
- SaaS platform SDK – もし SaaS プラットフォームに Python SDK のような SDK (Software Development Kit) がある場合は、SageMaker ノートブックから直接データにアクセスするために利用できる可能性があります。
- その他の選択肢 – これらに加えて、SaaS プロバイダが API 経由で、あるいはファイルやエージェントの利用でデータを公開しているかどうかに応じて、他の選択肢がある可能性があります。エージェントは、 Amazon Elastic Compute Cloud (Amazon EC2) または AWS Lambda にインストールできます。あるいは、AWS Glue やサードパーティの抽出、変換、ロード (ETL) が行えるツールを、データ変換のために利用可能です。
次の図は、データアクセスの選択肢について説明しています。
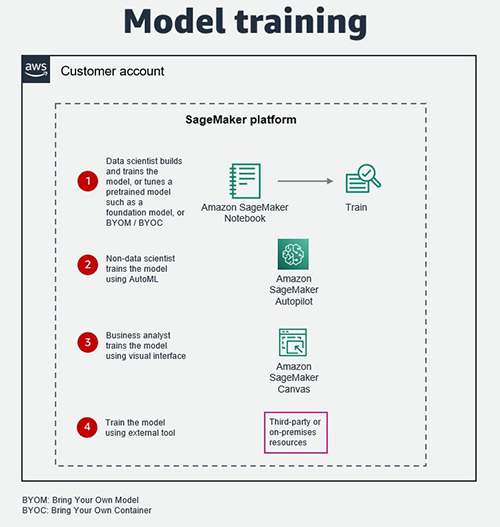
モデルのトレーニング
モデルは、データサイエンティストが SageMaker Studio でトレーニングすることも、データサイエンティスト以外が Amazon SageMaker Autopilot を使用することも、ビジネスアナリストが SageMaker Canvas でトレーニングすることもできます。SageMaker Autopilot は、特徴量エンジニアリング、アルゴリズムの選択、ハイパーパラメータの設定など、ML モデルの構築時の重労働を取り除き、SaaS プラットフォームに直接統合することも比較的容易です。SageMaker Canvas は、ML モデルのトレーニングの際に、ノーコードのビジュアルインターフェースを提供します。
上記に加えてデータサイエンティストは、Alexa、AI21 Labs、Hugging Face、Stability AI のようなソースからの基盤モデルを含む、事前トレーニング済みのモデルを SageMaker JumpStart で利用することができます。そしてそれらを自身の生成系 AI のユースケースのためにファインチューニングを行うことができます。
あるいは、モデルのアーティファクトがアクセス可能で読み取り可能であれば、サードパーティまたはパートナーが提供するツール、サービス、インフラストラクチャ (オンプレミスリソースを含む) でモデルをトレーニングすることもできます。
以下の図は、それらの選択肢を説明しています。
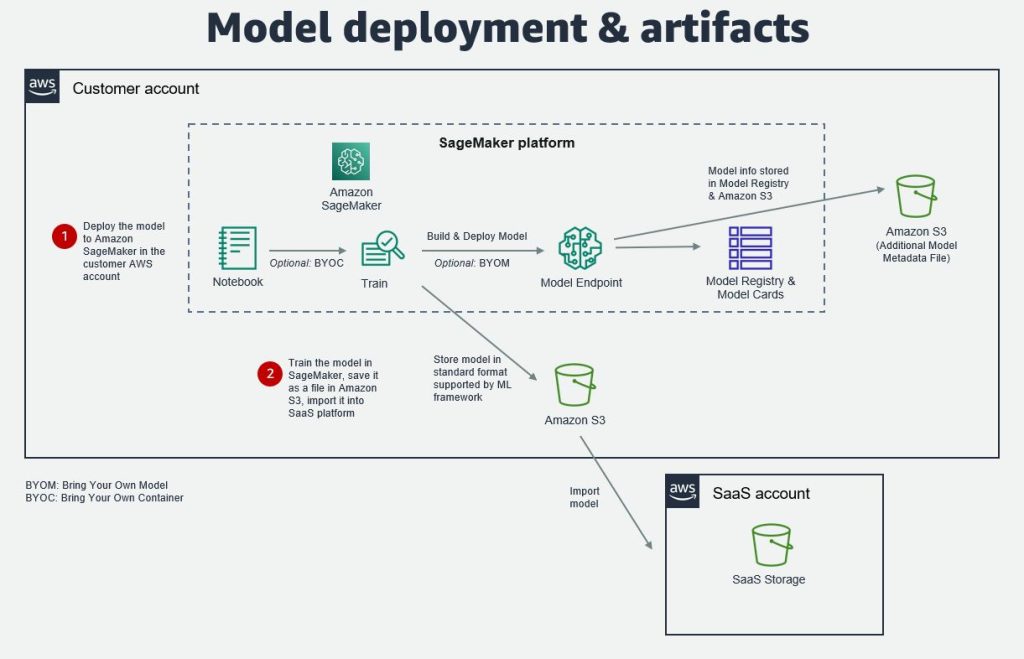
モデルのデプロイとアーティファクト
モデルのトレーニングとテストの後は、顧客のアカウト内の SageMaker モデルエンドポイントにデプロイするか、SageMaker からモデルをエクスポートし、SaaS プラットフォームのストレージへインポートすることが可能です。モデルは、pickle、joblib、ONIX (Open Neural Network Exchange) のような一般的な ML フレームワークによりサポートされた標準フォーマットで保存し、インポートすることが可能です。
もし ML モデルが SageMaker モデルエンドポイントにデプロイされている場合、追加のモデルのメタデータを SageMaker Model Registry や SageMaker Model Cards、S3 バケット内のファイルに保存できます。この情報は モデルのバージョン、モデルのインプットとアウトプット、モデルの作成日、推論の仕様、データのリネージュ情報などです。モデルパッケージ に利用可能なプロパティがない場合、データはカスタムメタデータとして、または S3 ファイルに保存できます。
そのようなメタデータを作成すると、SaaS プロバイダーは ML モデルのエンドツーエンドのライフサイクルをより効率的に管理できるようになります。この情報は、SaaS プラットフォーム内の モデルのログに同期し、ML モデルの変更や更新を追跡するために利用することができます。その後、このログを使用して、SaaS プラットフォームでその ML モデルを使用するダウンストリームのデータとアプリケーションを更新するかどうかを決定できます。
以下の図は、このアーキテクチャを説明しています。
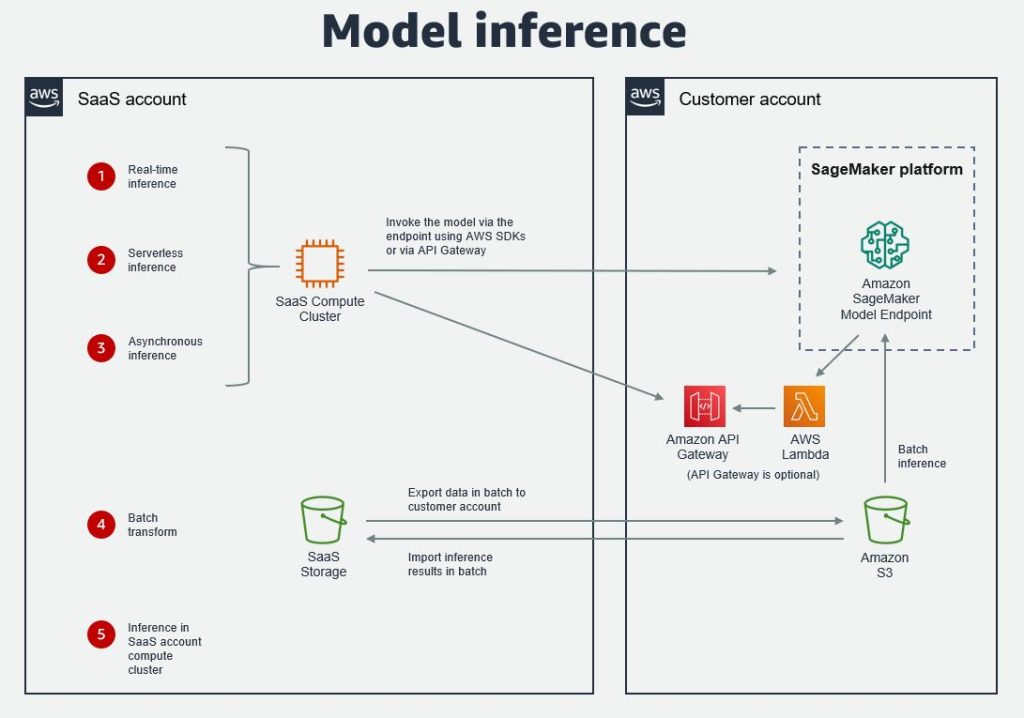
モデルの推論
SageMaker は、ML モデルの推論 のための4つのオプションを提供します。リアルタイム推論、サーバレス推論、非同期推論、バッチ変換です。始めの 3 つは、モデルは SageMaker モデルエンドポイントにデプロイされ、SaaS プラットフォームが AWS SDK を使用して呼び出します。推奨する選択肢は、Python SDK です。これらの各推論パターンは、predictor の predict() または predict_async() メソッドが使用されます。クロスアカウントアクセスは、ロールベースアクセスを使用して実現できます。
Amazon API Gateway を使用してバックエンドを隠し、保護されたプライベートネットワークで実行される Lambda 関数を介してエンドポイントを呼び出すこともできます。
バッチ変換を行うには、SaaS プラットフォームからのデータをまず顧客の AWS アカウントの S3 バケットにバッチでエクスポートする必要があります。その後、このデータに対して推論がバッチで実行されます。推論は、最初にトランスフォーマージョブ、またはオブジェクトを作成し、次にデータがある S3 の場所を指定して transform() メソッドを呼び出すことで実行されます。結果は、データセットとしてバッチで SaaS プラットフォームにインポートされ、バッチ パイプラインジョブの一部としてプラットフォーム内の他のデータに結合されます。
他の推論のオプションは、SaaS アカウントのコンピュートクラスターへ直接推論を行うことです。これは SaaS プラットフォームへモデルがすでにインポートされているケースとなります。この場合、SaaS プロバイダーは ML 推論に最適化された幅広い種類のEC2インスタンス から選択することができます。
以下の図は、それらの選択肢を説明しています。
統合の例
様々な ISV が彼らの SaaS プラットフォームと SageMaker 間の統合を構築しています。統合例についてより学びたい場合は、以下を参照してください。
- Snowflake と Amazon SageMaker を利用してデータ中心の AI を実現する
Enabling Data-Centric Artificial Intelligence Through Snowflake and Amazon SageMaker - Amazon SageMaker Autopilot と Domo を使用した すべての人のための機械学習
Machine Learning for Everyone with Amazon SageMaker Autopilot and Domo - AWS と Domino Data Lab で モデルのエンドツーエンドの開発、監視、メンテナンスを設計する方法
How to architect end-to-end development, monitoring, and maintenance of your models in AWS and Domino Data Lab
まとめ
この投稿では、SageMaker と SaaS プラットフォームとの統合のプロセスを4つのパーツに分割し、一般的な統合アーキテクチャを説明することで、SaaS プロバイダーが SageMaker を自身の SaaS プラットフォームと統合する理由と方法を説明しました。SageMaker との統合を構築しようとしている SaaS プロバイダーは、これらのアーキテクチャを利用できます。もし他の SageMaker コンポーネントなど、この投稿で説明した内容を超えるようなカスタム要件がある場合は、AWS アカウントチームにお問い合わせください。統合が構築され検証されると、ISV パートナーは AWS Service Ready Program for SageMaker に参加して、様々なメリットを利用できるようになります。
また、SaaS プラットフォームのユーザーであるお客様には、Amazon SageMaker との統合への関心を、 担当のAWS アカウントチームに登録していただくようお願いしています。これは、SaaS プロバイダーの開発を刺激し、促進する助けとなるからです。
本記事は、Integrate SaaS platforms with Amazon SageMaker to enable ML-powered applications を翻訳したものです。
翻訳はソリューションアーキテクトの加藤 菜々美が担当しました。
著者について
| Mehmet Bakkaloglu は、Data Analyst、AI/ML、ISV にフォーカスしている、AWS の Principal Solutions Architect です。 | |
| Raj Kadiyala は、AWS の Principal AI/ML Evangelist です。 |