Amazon Web Services ブログ
Amazon Redshift の速度とスケーラビリティの向上
2012 年に Amazon Redshift がリリースされて以来、その焦点は常に、可能な限り最高のパフォーマンスを、大規模に、そして可能な限り低コストで提供することでした。世界中のほとんどの組織にとって、データウェアハウスに送信されるデータの量は指数関数的に増加しており、そのデータから洞察を得たいと考えている人の数は日に日に増えています。このため、Amazon Redshift は、増え続けるデータを処理し、洞察に対する需要に応えるために継続的に革新を続けています。
Amazon Redshift は、最も要求の厳しいワークロードに対して、大規模な高速パフォーマンスを提供します。そこにたどり着くのは簡単ではありませんでした。これを実現するには、さまざまな技術的な重点領域にわたって一貫した投資が必要です。この記事では、世界最速のクラウドデータウェアハウスを構築するために何が必要だったかを詳しく説明します。
Redshift のパフォーマンスへの投資は、幅広いニーズに基づいており、何万ものお客様からの広範なフリートテレメトリデータを使用して開発作業を進めています。ニーズは、データウェアハウスのサイズ、同時ユーザー数、ユーザーのスキルセット、それに使用頻度やクエリのレイテンシーなどのワークロード特性を含めたさまざまな要因に応じて異なります。
これに基づいて、Amazon Redshift は次の 4 つの主要な領域に重点を置いてパフォーマンス投資を行いました。
- 標準のパフォーマンス – Amazon Redshift の詳細設定なしで発揮できるパフォーマンスは、6 か月前に比べて 2 倍以上高速化しており、追加の手動による最適化や調整を行わなくても高速化し続けています
- 自動最適化 – Amazon Redshift は自己学習、自己最適化を行い、常に実際のワークロードに適応して、可能な限り最高のパフォーマンスを提供します
- スケーラビリティ – Amazon Redshift は、スループットを 35 倍に向上させて、同時ユーザーの増加をサポートし、幅広いワークロードに対して線形にスケーリングできます
- コストパフォーマンス – Amazon Redshift は、リソース使用率を最適化することにより、他のデータウェアハウスソリューションよりも大幅に低い総コストで予測可能なパフォーマンスを提供します
標準のパフォーマンス
Amazon Redshift では、メモリを静的にパーティション化し、同時クエリの数を指定することで、常に手動でワークロードのパフォーマンスを調整できます。Amazon Redshift は、高度な機械学習 (ML) アルゴリズムも使用して、構成設定を自動的に調整し、データウェアハウスのパフォーマンスを最適化します。
このアルゴリズムは、1 日 2 エクサバイトを超えるデータの処理から生成された実際のテレメトリデータでトレーニングされるため、非常に効果的です。さらに、Amazon Redshift は他のどのクラウドデータウェアハウスよりも多くのお客様を抱えているため、テレメトリデータにより ML アルゴリズムからの推奨設定がさらに正確になります。
さらに、Amazon Redshift Advisor は、ソートキー、分散キーなどを推奨することで最適化をガイドします。Amazon Redshift の学習、セルフチューニング動作をオーバーライドする場合でも、きめ細かく制御できます。
Amazon Redshift の標準のパフォーマンスは継続的に向上しています。2019 年 11 月、Cloud Data Warehouse のベンチマーク [1] は、Amazon Redshift の標準のパフォーマンスが 6 か月前の 2 倍の速さであることを示しました。このパフォーマンスの継続的な改善は、多くの技術革新を結集したものです。この記事では、最も大きな影響を与えた 3 つの改善点をご紹介します。
圧縮の改善
Amazon Redshift は、新しい圧縮エンコーディングである AZ64 を使用しており、高い圧縮率と大幅に改善されたクエリパフォーマンスを実現します。AZ64 を使用すると、ストレージサイズとパフォーマンスの間でトレードオフを行う必要がなくなります。AZ64 は、一般的な高性能 LZO アルゴリズムよりも平均で 35% 多くデータを圧縮し、データを 40% 高速に処理します。AZ64 は、データ値の小さなグループを効率的に圧縮することでこれを実現し、AZ64 エンコード列の並列処理に CPU ベクトル命令と単一命令、複数データ (SIMD) を使用しています。これを利用するには、各列のデータ型を選択するだけで、Amazon Redshift が圧縮エンコード方式を選択します。ローンチから 5 か月が経過して、AZ64 エンコードは、数百万の列を持つ Amazon Redshift で 4 番目に人気のあるエンコードオプションになりました。
効率的な大規模結合操作
複雑なクエリが大きなテーブルを結合すると、ネットワークを介して大量のデータが転送されて、Amazon Redshift コンピューティングノードで結合処理されます。これは、クエリのパフォーマンスに影響を与えるネットワークのボトルネックになっていました。
現在、Amazon Redshift は分散ブルームフィルターを使用して、このようなワークロードの高性能な結合が行えるようになりました。分散ブルームフィルターは、結合関係に一致しないソースの行を効率的にフィルター処理します。これにより、ネットワーク経由で転送されるデータの量が大幅に削減されます。フリート全体で、毎日何百万もの選択的ブルームフィルターがデプロイされており、そのうちのいくつかは 10 億以上の行をフィルタリングしています。これにより、ネットワークがボトルネックになることがなくなり、クエリ全体のパフォーマンスが向上します。Amazon Redshift は、どのクエリがこの最適化に適しているかを自動的に判断し、実行時に最適化を適応させます。さらに、Amazon Redshift は CPU キャッシュに最適化された処理を使用して、大規模な結合と集計でのクエリ実行をより効率的にしています。これらの機能を合わせると、Amazon Redshift が毎日処理するクエリのパフォーマンスが 70% 以上向上します。
クエリプランの強化
クエリプランは、さまざまなクエリプランに関連するコストを評価することにより、特定のクエリを処理する最も速い方法を決定します。コストには、多くの要因が含まれます。たとえば、必要な I/O 操作の数、ディスクバッファースペースの量、ディスクから読み取る時間、クエリの並列処理、および行の数や列の個別の値の数などのテーブル統計などが関係してきます。
Amazon Redshift クエリプランナーは、ネットワークスタックを含む最新のハードウェアの機能を考慮して、ハードウェアが提供するパフォーマンスを最大限に活用します。その統計収集プロセスは自動化されており、HyperLogLog (HLL) などのアルゴリズムを使用して統計を計算します。これにより、統計の品質が向上し、コストベースのプランナーがより適切な選択を行えるようになります。
自動最適化
Amazon Redshift は、ML 技術と高度なグラフアルゴリズムを使用して、継続的にパフォーマンスを向上させています。ワークロードが異なればデータアクセスパターンも異なり、Amazon Redshift はワークロードを観察して学習し、適応させます。それにより、データレイアウト、分散キー、クエリプランを自動的に調整して、特定のワークロードに最適なパフォーマンスを実現します。
Amazon Redshift の自動最適化は、ノード間でデータを分散する方法、頻繁に一緒にクエリされて同じ場所に配置する必要があるデータセット、データの並べ替え方法、クエリの複雑さに基づいてシステムベースで実行する必要がある並列クエリと同時クエリの数といった点でインテリジェントな決定を行います。Amazon Redshift は、データウェアハウスを使用するときに、これらの設定を自動的に調整してスループットとパフォーマンスを最適化します。このような最適化によってワークロードが中断されないようにするために、Amazon Redshift は、クラスターの使用率が低い期間にのみ、これらを段階的に実行します。
メンテナンスオペレーションを行う場合、Amazon Redshift は、頻繁にアクセスされるテーブルとそれらのテーブル内の部分のみを操作することにより、必要なコンピューティングリソースの量を削減します。Amazon Redshift は、クエリパターンを分析して、操作するテーブルの部分に優先順位を付けます。関連する場合、Amazon Redshift Advisor の推奨事項を通じて規範的なガイダンスを示します。その後、必要に応じてこれらの推奨事項を評価および適用できます。
また、AWS は、専門家による人の手の調整などの従来の方法と比較して、ML ベースの自己学習システムが高速クエリパフォーマンスの提供にどれほど効果的であるかを常に評価および査定しています。
Amazon Redshift は何年も前から自動最適化を追加しています。次のタイムラインは、過去 12 か月に提供された自動最適化の一部を示しています。
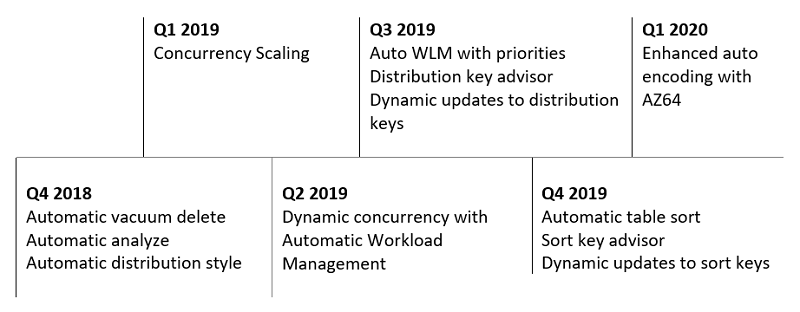
特定の最適化の詳細については、
自動 VACUUM DELETE、自動 ANALYZE、分散キーの推奨、ソートキーの推奨、自動テーブルソート、および自動配布スタイルの記事を参照してください。
スケーラビリティ
Amazon Redshift は、スループットを 35 倍以上向上させて、同時ユーザーの増加をサポートし、単純なワークロードと混合ワークロードに対して直線的にスケーリングします。
増え続けるユーザーをサポートするためのスケーリング
データウェアハウスにアクセスするユーザーの数が増えると、クエリの応答に遅延が発生することはなくなります。ほとんどの場合、ワークロードは予測不可能であり、1 日を通じて変動する可能性があります。従来のデータウェアハウスは、通常、遅延や SLA の未達を回避するためにピーク時の使用に対してプロビジョニングされ、最終的には十分に使用していないリソースに料金を支払うことになっていました。
Amazon Redshift の同時実行スケーリングにより、データウェアハウスは、必要に応じて基盤となるリソースを柔軟にスケーリングすることにより、一貫して SLA を維持しながら、ワークロードの急増に対処します。Amazon Redshift は、指定されたワークロードを継続的にモニタリングします。ユーザーアクティビティのバーストが原因でクエリがバックログされ始めた場合、Amazon Redshift は一時的なクラスター容量を自動的に追加し、リクエストをこの新しいクラスターにルーティングします。この一時的な容量は数秒で利用できるため、クエリは低レイテンシーで引き続き処理されます。Amazon Redshift は、クラスターでアクティビティが減少すると、追加した一時的な容量を自動的に削除します。
特定のワークロードに柔軟にスケーリングするかどうか、および単純な 1 ステップの設定でどれだけ拡張するかを選択できます。Amazon Redshift メインクラスターを 24 時間使用するごとに、1 時間のクレジットが発生します。これにより、97% 以上のユースケースで同時実行スケーリングが無料になります。
Amazon Redshift データウェアハウスは、追加の容量を自動的に追加および削除する機能により、全体的なスループットを 35 倍以上向上させることができます。この記事では、次の実験により、同時ユーザーの要求を満たすために、どれほど多くコンピューティング能力を動的に割り当てることができるかを示しています。まず、Cloud Data Warehouse ベンチマークと 5 人の同時ユーザーを使用してベースライン測定を行います。次に、同時実行スケーリングを有効にして、反復ごとにユーザーを追加できます。Amazon Redshift はキューイングを検出するとすぐに、追加のスケーリングクラスターを自動的に割り当てます。最終的に、この実験では Amazon Redshift で 200 を超える同時クエリを実行し、35 倍以上のスループットを生成しました。この多数の同時実行クエリは、同時ユーザーが数千いることを表します。これは、Amazon Redshift データウェアハウスで事実上無制限に同時ユーザーをサポートできることを示しています。
同時ユーザーのスケーリングも線形です。同時実行スケーリングクラスターに追加の料金を支払うごとに、パフォーマンスが一貫して向上します。これにより、ビジネスニーズの拡大に合わせてデータウェアハウスのコストを予測可能に保つことができます。同時実行スケーリングを使用すると、AWS は 1 時間あたり数万のクエリでベンチマークテストを実行でき、数百のクエリを同時に実行して線形スケールを提供できます。これは、数千の同時ユーザーがデータウェアハウスに接続している企業の実際のワークロードに相当します。
複数の混合ワークロードを実行している間のスケーリング
時間の経過とともにデータウェアハウスが増加するにつれて、データウェアハウスで実行されるワークロードの数と複雑さも増大します。たとえば、オンプレミスのデータウェアハウスから Amazon Redshift に移行する場合、最初に従来の分析ワークロードを実行し、最終的にはより多くの運用データとリアルタイムデータをクラスターに取り込むことで、新しいユースケースとアプリケーションを構築します。データウェアハウスを効果的に拡張するには、複数のタイプのワークロードに同時に優先順位を付けて管理できる必要があります。自動ワークロード管理 (WLM) とクエリの優先順位付けは、Amazon Redshift に最近追加された機能で、簡単に目的の操作を実行できます。
自動 WLM は、動的で予測不可能なワークロードであっても、クラスターリソースを効率的に使用できるようにします。自動 WLM では、Amazon Redshift は ML を使用して、メモリと処理要件に基づいて着信クエリを分類し、適切な内部キューにルーティングして、並列実行を開始します。Amazon Redshift は、全体的にスループットとパフォーマンスを最適化するために、並行して実行するクエリの数を動的に調整します。大量のリソースを必要とするクエリがシステムにある場合 (たとえば、大きなテーブル間のハッシュ結合)、同時実行性は低くなります。軽めのクエリ (挿入、削除、単純な集計など) を送信すると、同時実行性が高くなります。システムの使用率を継続的にモニタリングし、クラスターへのルーティングを調整するフィードバックループがあります。
ただし、すべてのクエリが同等に重要であるとは限りません。1 つのワークロードまたは一連のユーザーのパフォーマンスが他のワークロードよりも重要である場合があります。Amazon Redshift のクエリの優先順位付けがこれに対処します。一貫性のあるクエリパフォーマンスを実現するために、忙しい時間帯により多くのリソースを使うことを含め、優先度の高いワークロードを優先的に処理することができます。Amazon Redshift のワークロード管理では、インテリジェントなアルゴリズムを使用して、優先度の低いクエリが継続して進行し、停止しないようにします。
Amazon Redshift 同時実行スケーリングと自動 WLM をクエリの優先順位づけと組み合わせて、複雑なデータウェアハウスのユースケースを解決できます。たとえば、次のテーブルは、ETL と分析ワークロードを効果的に組み合わせた Amazon Redshift 設定をまとめたものです。
| WLM キュー | キューの優先順位 | 同時実行スケーリング | メモ |
| ETL | 高 | オフ | ETL を実行すると、ETL が最優先されます |
| BI クエリ | 普通 | オン | BI ワークロードが突然増加すると、同時実行スケーリングにより容量が追加されて、ユーザー SLA を維持します |
| ワンタイムクエリまたは探索クエリ | 低 | オフ | クラスターは、リソースが利用可能な場合に、カジュアルユーザーとデータサイエンティストに分析アクセスを提供します |
このユースケースなどでは、SLA を維持し、クラスターの利用効率を高め、ビジネスの優先順位に従って投資するための十分な柔軟性を得ることができます。
コストパフォーマンス
消費されたコンピューティングサービスの総コストと実行されたコンピューティング作業の総量の両方を計算することで、コストパフォーマンスを測定できます。最小のコストで最大のパフォーマンスを実現することで、最高のコストパフォーマンスが得られます。
データウェアハウスが拡大するにつれて、Amazon Redshift の効率が向上します。ニーズが拡大しても、コストの増加を抑え、コストを予測可能に保ちます。これにより、Amazon Redshift は、ユーザー数の増加に応じて料金が大幅に上昇するマーケットの他の製品と一線を画しています。
自動最適化、標準のパフォーマンス、およびスケールへの投資はすべて、Amazon Redshift が実現する比類のないコストパフォーマンスに貢献しています。一般的なお客様の見積もりと投資を比較すると、Amazon Redshift のコストが他のクラウドデータウェアハウスより 50% 〜75% 低いことがわかります。
性能測定
AWS は、パフォーマンス、スループット、コストパフォーマンスを毎夜測定します。AWS はまた、より大規模で包括的なベンチマークを定期的に実行して、テストがお客様の現在のニーズを上回るようにしています。ベンチマーク結果が有用であるためには、それらが明確に定義され、簡単に再現できる必要があります。AWS は、クエリやデータを変更せずに TPC ルールと要件に準拠して、現在の TPC-DS および TPC-H ベンチマークに基づいた Cloud DW ベンチマークを使用しています。
誰でもこれらのベンチマークを再現できることが重要です。ベンチマークコードとスクリプトは GitHub から、付随するデータセットは公開 Amazon S3 バケットからダウンロードできます。
まとめ
Amazon Redshift は自己学習、自己最適化を行い、常に実際のワークロードのテレメトリを使用して、可能な限り最高のパフォーマンスを発揮しています。Amazon Redshift は、詳細設定しない状態で 6 か月前に比べて 2 倍以上高速であり、手動による最適化やチューニングを行わなくても高速化を続けています。Amazon Redshift は、スループットを 35 倍以上向上させて、同時ユーザーの増加をサポートし、単純なワークロードと混合ワークロードに対して直線的にスケーリングします。
ソフトウェアの改善に加えて、AWS は利用できる最高のハードウェア上にデータウェアハウスを構築し続けています。マネージドストレージを備えた新しい RA3 ndoe タイプは、ローカルキャッシュとして高帯域幅ネットワーキングとかなりの高性能 SSD を備えています。RA3 ノードは、ワークロードパターンと高度なデータ管理技術 (自動の細粒度データ削除やインテリジェントデータプリフェッチなど) を使用して、ローカル SSD のパフォーマンスを提供しながら、ストレージを自動的に Amazon S3 にスケーリングします。AQUA (Advanced Query Accelerator) を使ったプレビューでのハードウェアベースのパフォーマンスの向上により、劇的なパフォーマンスの向上がもたらされ、新しい分散およびハードウェアアクセラレーションキャッシュによりコストが削減できます。
これらのパフォーマンスの向上は、自動最適化、標準のパフォーマンス、スケーラビリティなど、複数の分野にわたって戦略的かつ持続的な製品投資と技術革新を何年も積み上げてきた成果です。さらに、コストパフォーマンスが優先事項であり続けているため、最高の価値を手に入れることができます。
各データセットとワークロードには固有の特性があり、概念実証は、独自の状況で Amazon Redshift がどのように実行されるかを理解するための最良の方法です。独自の概念実証を実行するときは、適切なメトリクス (1 時間あたりのクエリ数で表されるクエリのスループット) とワークロードのコストパフォーマンスに焦点を当てることが重要です。
[1]
データ主導の意思決定は、概念実証で支援をリクエストするか、システム統合およびコンサルティングパートナーとの協力により行うことができます。また、データウェアハウスが現在のニーズでどのように機能するかだけでなく、ワークロード、データセット、ユーザーがますます複雑になる中での将来のパフォーマンスも考慮することが重要です。
Amazon Redshift の最新の動向に関する最新情報を入手するには、Amazon Redshift の新機能 RSS フィードをご購読ください。
———
[1] TPC Benchmark、TPC-DS および TPC-H は、トランザクション処理性能評議会 (Transaction Processing Performance Council、www.tpc.org) の商標です
著者について
 Naresh Chainani は、Amazon Redshift のシニアソフトウェア開発マネージャーで、優秀ななチームを率いてクエリ処理、クエリパフォーマンス、分散システム、ワークロード管理を指揮しています。Naresh はお客様がタイムリーに物事の実態を見抜く力を獲得し、重要なビジネス上の意思決定ができるようにするための高性能のデータベースを構築することに情熱を傾けています。余暇には、本を読んだりテニスをしたりして楽しんでいます。
Naresh Chainani は、Amazon Redshift のシニアソフトウェア開発マネージャーで、優秀ななチームを率いてクエリ処理、クエリパフォーマンス、分散システム、ワークロード管理を指揮しています。Naresh はお客様がタイムリーに物事の実態を見抜く力を獲得し、重要なビジネス上の意思決定ができるようにするための高性能のデータベースを構築することに情熱を傾けています。余暇には、本を読んだりテニスをしたりして楽しんでいます。
 Berni Schiefer は、アマゾン ウェブ サービスの EMEA のシニア開発マネージャーで、ドイツのベルリンで Amazon Redshift 開発チームを率いています。ベルリンチームは、Redshift のパフォーマンスとスケーラビリティ、SQL クエリのコンパイル、空間データのサポート、および Redshift Spectrum に重点を置いています。Berni は、以前はプライベートクラウド、Db2、Db2 ウェアハウス、BigSQL の領域に従事した IBM フェローで、SQL ベースのエンジン、クエリの最適化、パフォーマンスに重点を置いていました。
Berni Schiefer は、アマゾン ウェブ サービスの EMEA のシニア開発マネージャーで、ドイツのベルリンで Amazon Redshift 開発チームを率いています。ベルリンチームは、Redshift のパフォーマンスとスケーラビリティ、SQL クエリのコンパイル、空間データのサポート、および Redshift Spectrum に重点を置いています。Berni は、以前はプライベートクラウド、Db2、Db2 ウェアハウス、BigSQL の領域に従事した IBM フェローで、SQL ベースのエンジン、クエリの最適化、パフォーマンスに重点を置いていました。
 Neeraja Rentachintala は、アマゾン ウェブ サービスの経験豊富な製品管理および GTM リーダーで、業界をリードするデータ製品とプラットフォームの分野で 20 年以上製品ビジョン、戦略、リーダーシップの役割で培ってきた経験を持ち込んでいます。キャリアの中で、彼女は分析、ビッグデータ、データベース、データとアプリケーションの統合、AI/ML の分野の製品を提供し、Fortune 500 企業、MapR (HPE が買収) などのベンチャー、Microsoft、Oracle、Informatica、Expedia.com を顧客として抱えていました。現在 Neeraja は、アマゾン ウェブ サービスのプリンシパルプロダクトマネージャーで、Amazon Redshift を構築しています。Amazon Redshift は、世界で最も人気があり、最高のパフォーマンスと最もスケーラブルなクラウドデータウェアハウスです。Neeraja は、インド工科大学で電子通信工学の技術学士号を取得し、さらにワシントン大学、MIT スローン経営大学院、スタンフォード大学でさまざまなビジネスプログラム認定を取得しています。
Neeraja Rentachintala は、アマゾン ウェブ サービスの経験豊富な製品管理および GTM リーダーで、業界をリードするデータ製品とプラットフォームの分野で 20 年以上製品ビジョン、戦略、リーダーシップの役割で培ってきた経験を持ち込んでいます。キャリアの中で、彼女は分析、ビッグデータ、データベース、データとアプリケーションの統合、AI/ML の分野の製品を提供し、Fortune 500 企業、MapR (HPE が買収) などのベンチャー、Microsoft、Oracle、Informatica、Expedia.com を顧客として抱えていました。現在 Neeraja は、アマゾン ウェブ サービスのプリンシパルプロダクトマネージャーで、Amazon Redshift を構築しています。Amazon Redshift は、世界で最も人気があり、最高のパフォーマンスと最もスケーラブルなクラウドデータウェアハウスです。Neeraja は、インド工科大学で電子通信工学の技術学士号を取得し、さらにワシントン大学、MIT スローン経営大学院、スタンフォード大学でさまざまなビジネスプログラム認定を取得しています。