Amazon Web Services ブログ
EMRFS S3 最適化コミッターを使用して、Apache Parquet 形式での Apache Spark 書き込みパフォーマンスを向上させる
EMRFS S3 最適化コミッターは、Amazon EMR 5.19.0 以降の Apache Spark ジョブで使用可能な新しい出力コミッターです。このコミッターは、EMR ファイルシステム (EMRFS) を使用して Apache Parquet ファイルを Amazon S3 に書き込む際のパフォーマンスを向上させます。この記事では、この新しい最適化されたコミッターを既存のコミッターアルゴリズム、つまり FileOutputCommitter アルゴリズムのバージョン 1 および 2 と比較するためにパフォーマンスベンチマークを実行します。最後に、新しいコミッターに対する現在の制限について検討し、可能な限り回避策を提供します。
FileOutputCommitter との比較
Amazon EMR バージョン 5.19.0 以前では、Parquet を Amazon S3 に書き込む Spark ジョブは、デフォルトで FileOutputCommitter という Hadoop コミットアルゴリズムを使用していました。このアルゴリズムには、バージョン 1 と 2 の 2 つのバージョンがあります。どちらのバージョンも、中間タスクの出力を一時的な場所に書き込むことに依存しています。その後、名前変更操作を実行して、タスクまたはジョブの完了時にデータが表示されるようにします。
アルゴリズムバージョン 1 には、2 つのフェーズの名前変更があります。1 つは個々のタスク出力をコミットするため、もう 1 つは完了/成功したタスクからのジョブ全体の出力をコミットするためです。タスクは名前変更ファイルを直接最終出力場所にコミットするので、アルゴリズムバージョン 2 がより効率的です。これにより、2 番目の名前変更フェーズが除外されますが、ジョブが完了する前に部分的なデータが表示されるため、すべてのワークロードが許容されるわけではありません。
実行される名前変更は、Hadoop Distributed File System (HDFS) での高速なメタデータだけの操作です。ただし、出力が Amazon S3 などのオブジェクトストアに書き込まれると、データをターゲットにコピーしてからソースを削除することによって、名前変更が行われます。この名前変更による「ペナルティ」は、ディレクトリの名前変更によって悪化します。これは、FileOutputCommitter v1 の両方のフェーズで発生する可能性があります。これらは HDFS での単一のメタデータのみの操作ですが、コミッターは S3 で N 回のコピーと削除の操作を実行する必要があります。
これを部分的に軽減するために、Spark で EMRFS を使用して Parquet データを S3 に書き込む時に、Amazon EMR 5.14.0+ 以降のデフォルトは FileOutputCommitter v2 になります。新しい EMRFS S3 最適化コミッターは、Amazon S3 マルチパートアップロードのトランザクションプロパティを使用することによって、名前変更操作を完全に回避するためにその作業を改善しています。その後、タスクはデータを最終的な出力場所に直接書き込むことができますが、タスクのコミット時までそれぞれの出力ファイルの完了は延期されます。
パフォーマンステスト
次の INSERT OVERWRITE Spark SQL クエリを実行して、さまざまなコミッターの書き込みパフォーマンスを評価しました。SELECT * FROM range(…) 句は、実行時にデータを生成しました。これにより、Amazon S3 内の正確に 100 の Parquet ファイルにわたって約 15 GB のデータが生成されました。
注意: EMR クラスターは、S3 バケットと同じ AWS リージョンで実行されました。trial_id プロパティは UUID ジェネレータを使用して、テスト実行間で矛盾が生じないようにしました。
テストは、emr-5.19.0 リリースラベルで作成された EMR クラスターで実行されました。マスターグループに 1 つの m5d.2xlarge インスタンス、コアグループに 8 つの m5d.2xlarge インスタンスがありました。このクラスター設定に対して、Amazon EMR によって設定されたデフォルトの Spark 設定プロパティを使用しました。これには、以下が含まれます。
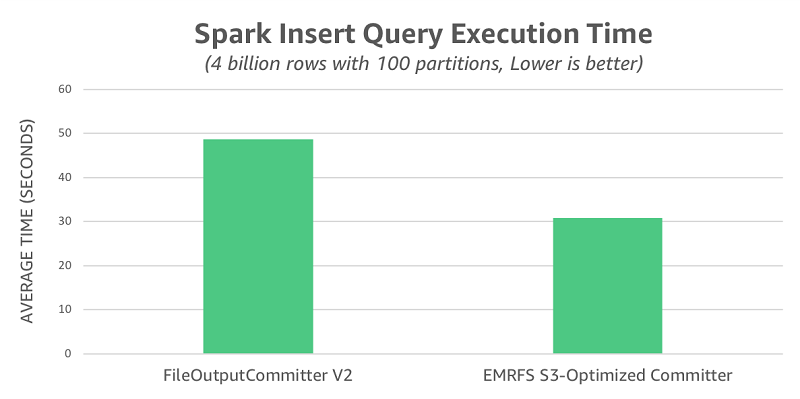
それぞれのコミッターについて 10 回試行した後、クエリの実行時間を取得して、次の表にまとめました。FileOutputCommitter v2 は平均 49 秒でしたが、EMRFS S3 最適化コミッターは平均 31 秒で、1.6 倍のスピードアップでした。
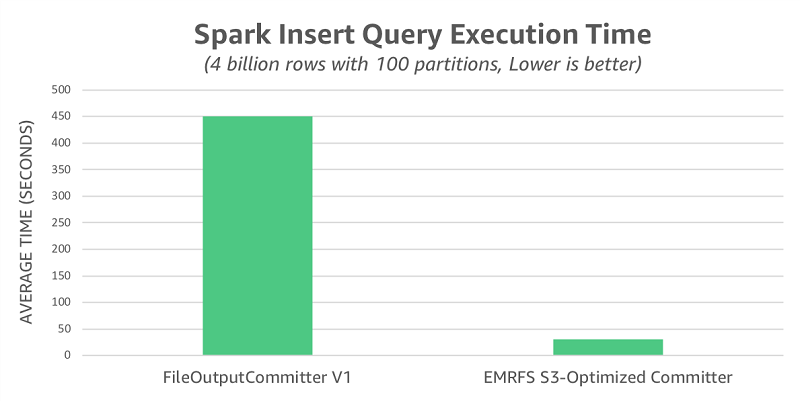
前述したように、FileOutputCommitter v2 では、FileOutputCommitter v1 で使用される名前変更操作の一部 (すべてではありません) が除外されています。S3 に対する名前変更のパフォーマンスへの完全な影響を説明するために、FileOutputCommitter v1 を使用してテストを再実行しました。このシナリオで、平均実行時間 450 秒を観察しました。これは、EMRFS S3 最適化コミッターよりも 14.5 倍低速です。
最後に評価したシナリオは、EMRFS の整合性のあるビューが有効になっている場合です。これは、Amazon S3 データの整合性モデルが原因で発生する可能性がある問題に対処しています。このモードでは、EMRFS S3最適化コミッターの時間はこの変更による影響を受けず、平均 30 秒でした。一方、FileOutputCommitter v2 は平均 53 秒で、整合性のあるビューの機能をオフにしたときよりも遅く、全体的なパフォーマンスの違いは 1.8 倍に拡大しました。

ジョブの正確さ
EMRFS S3 最適化コミッターには、FileOutputCommitter v2 と同じ制限があります。これは、どちらも個々のタスクにコミットの責任を完全に委任することによってパフォーマンスを向上させているためです。以下は、この設計における選択が与える顕著な影響についての検討です。
不完全または失敗したジョブからの部分的な結果
両方のコミッターがそれぞれのタスクに最終出力場所への書き込みを行わせるので、どちらかを使用すると、その出力場所の並列リーダーは部分的な結果を見ることになります。ジョブが失敗すると、ジョブ全体が失敗する前にコミットしたタスクからの部分的な結果が残ります。最初に出力場所をクリーンアップせずにジョブを再実行すると、この状況で出力が重複する可能性があります。
この問題を軽減する 1 つの方法は、ジョブが実行されるたびに必ず異なる出力場所を使用し、ジョブが成功した場合にだけその場所を下流のリーダーに公開することです。次のコードブロックは、Hive テーブルを使用するワークロードに対するこの戦略の例です。ジョブが実行されるたびに output_location が一意の値に設定され、残りのクエリが成功した場合にだけ、テーブルパーティションが登録されることに注意してください。リーダーがテーブル抽象化を介してデータに排他的にアクセスする限り、ジョブが終了する前に結果を見ることはできません。
このアプローチでは、パーティションが指す場所を不変として扱う必要があります。パーティションの内容を更新するには、S3 ですべての結果を新しい場所に再書き込みしてから、その新しい場所を指すようにパーティションのメタデータを更新する必要があります。
冪等でないタスクからの重複した結果
両方のコミッターが誤った結果を生み出す可能性があるもう 1 つのシナリオは、冪等でないタスクで構成されるジョブが各タスク試行ごとに非決定論的な場所に出力を生成する場合です。
以下は、問題を説明するクエリの例です。タイムスタンプベースのテーブル分割スキームを使用して、タスクの試行ごとに確実に異なる場所に書き込むようにします。
このシナリオで重複した結果の問題を回避するには、タスクの試行によらずタスクが一貫した場所に書き込むようにします。たとえば、タスク内の現在のタイムスタンプを返す関数を呼び出す代わりに、現在のタイムスタンプをジョブへの入力として指定することを検討します。同様に、乱数ジェネレータをジョブ内で使用する場合は、タスクの再試行で同じ値が使用されるように、固定シードまたはタスクのパーティション番号に基づくものを使用することを検討します。
注意: Spark の組み込みランダム関数 rand()、randn()、uuid() は、これを念頭に置いて設計されています。
EMRFS S3 最適化コミッターの使用を有効にする
Amazon EMR バージョン 5.20.0 以降、EMRFS S3 最適化コミッターはデフォルトで有効になっています。Amazon EMR バージョン 5.19.0 では、Spark 内から、またはクラスターを作成するときに spark.sql.parquet.fs.optimized.committer.optimization-enabled プロパティを true に設定することで、コミッターを有効にすることができます。Spark に組み込まれた Parquet サポートを使用して EMRFS によって Parquet ファイルを Amazon S3 に書き込むと、コミッターが有効になります。これには、Spark SQL、DataFrame、Datasets で Parquet データソースを使用することが含まれます。ただし、EMRFS S3 最適化コミッターが有効にならない場合や、Spark が完全にコミッターの外側で独自の名前変更を実行する場合があります。コミッターおよびこれらの特別な場合についての詳細は、Amazon EMR リリースガイドの EMRFS S3 最適化コミッターの使用を参照してください。
関連作業 – S3A コミッター
EMRFS S3 最適化コミッターは、S3A ファイルシステムをサポートするコミッターで使用されている概念に触発されました。重要なことは、これらのコミッタが S3 マルチパートアップロードのトランザクションの性質を使用して、名前変更コストの一部または全部を排除することです。これは、EMRFS S3 最適化コミッターによって使用される中核的概念でもあります。
S3A ファイルシステムをサポートするものを含む、エコシステム内で利用可能なさまざまなコミッターについての詳細は、公式の Apache Hadoop ドキュメントを参照してください。
まとめ
EMRFS S3 最適化コミッターは、FileOutputCommitter と比較して、書き込みパフォーマンスを向上させます。Amazon EMR バージョン 5.19.0 以降では、Spark の組み込み Parquet サポートと共に使用することができます。詳細については、Amazon EMR リリースガイドの EMRFS S3 最適化コミッターの使用を参照してください。
著者について
 Peter Slawski は、アマゾン ウェブ サービスのソフトウェア開発エンジニアです。
Peter Slawski は、アマゾン ウェブ サービスのソフトウェア開発エンジニアです。
 Jonathan Kelly は、アマゾン ウェブ サービスのシニアソフトウェア開発エンジニアです。
Jonathan Kelly は、アマゾン ウェブ サービスのシニアソフトウェア開発エンジニアです。