Amazon Web Services ブログ
Amazon SageMaker エンドポイントと IAM を使用した SaaS テナント分離の実装
この記事は、Implementing SaaS Tenant Isolation Using Amazon SageMaker Endpoints and IAM を翻訳したものです。
本投稿は、AWS の Sr. Solutions Architect である Michael Pelts と、DoiT International 社の Sr. Cloud Architect である Joshua Fox により寄稿されました。
 |
マルチテナントの SaaS (Software-as-a-Service) プロバイダーが機械学習サービスの活用を検討する際には、異なるテナントからこれらのサービスに出入りするデータをどのように保護するかを検討する必要があります。
SaaS プロバイダーは、機械学習 (ML) サービスへのリクエストごとに、各テナントのデータがクロステナントアクセス (テナントの境界を超えた相互アクセス) から確実に保護されるような分離構造を導入する必要があります。
(原文寄稿者である) Michael は AWS にて、Joshua は DoiT International 社にて、それぞれデジタルネイティブな企業に対して支援を行うクラウドアーキテクトです。DoiT International 社は AWS アドバンスドコンサルティングパートナーであり、マネージドサービスプロバイダー (MSP) としてインテリジェントなテクノロジーと無制限のアドバイザリー、テクニカル、クラウドエンジニアリングのサポートを提供しています。
私たちの経験では、ML サービスプロバイダーの中には、テナントリソースを分離しているところもあれば、全てのテナントでリソースを共有しているところもあります。
テナントの基礎となるリソースが共有であるか専用であるかにかかわらず、すべての SaaS プロバイダーは、これらのテナントリソースの安全性を確保するために分離ポリシーを適用する必要があります。
この記事では、AWS Identity and Access Management (IAM)を使って機械学習サービスのテナント分離を実現する方法に焦点を当てます。IAM、Amazon SageMaker、その他多くの AWS サービスの統合により、テナント分離の目標を実現するために適用できる豊富なメカニズムを、開発者に提供している方法を見ていきます。
推論アーキテクチャとテナントの分離
まず、機械学習アーキテクチャの典型的な要素である推論コンポーネントを見てみましょう。
まず、分離ソリューションの一部として Amazon SageMaker のエンドポイントを使用することに注目してください。これは、トレーニングされた ML モデルに基づいた推論のための REST API を提供する、1 つ以上の Amazon Elastic Compute Cloud (Amazon EC2) インスタンスのグループを表すコアコンセプトで、エンドポイントごとに 1 つ以上のモデルがあります。
図 1 は、これらのエンドポイントへのアクセスを管理し、それを使ってテナントのデータを分離する方法を示しています。クライアントは、エンドポイントの API に直接アクセスするのではなく、Amazon API Gateway を呼び出し、それが AWS Lambda 関数をトリガーして Amazon SageMaker のエンドポイントを呼び出します。このアーキテクチャについては、AWS Machine Learning Blog の投稿記事で詳しく説明しています。
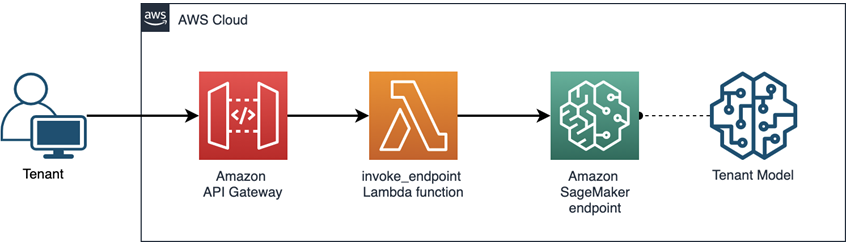
図 1 — Amazon SageMaker での推論の呼び出しフロー
この呼び出しアーキテクチャでは、テナントが自身のリソースにのみアクセスできるようにするために使用される IAM ポリシーを導入します。テナントの境界を越えようとするアクセスは拒否されます。ここで重要なのは、Amazon SageMaker の各エンドポイントへのアクセスを制御するために、テナントのコンテキストを活用するアプローチを定義することです。これにより、テナントは自分の ML モデルにのみアクセスでき、他のテナントに属する ML モデルにはアクセスできません。
テナント分離モデル
ここでは、マルチテナントのワークロードを分離する際に一般的に使用されるデプロイモデルを見てみましょう。これら 3 つの異なるタイプの SaaS 分離モデルをサイロ (専用)、プール (共有)、ブリッジ (部分共有) と呼びます。
ここからは、サービスプロバイダーがこれらの異なるモデルをどのように選択するかを含め、IAM がこれらの分離戦略を実装するためにどのように使用できるかを掘り下げて説明します。
サイロモデル
サイロモデルでは、各テナントのリソースを完全に分離することに重点を置いています。
推論アーキテクチャでは、各テナントに個別のスタックをデプロイすることでサイロモデルを実現しています。このスタックは、テナントのオンボーディング時 (初期登録時) に自動的にプロビジョニングされます。この例では、各テナントに対して以下のリソースをプロビジョニングする必要があります。
- Amazon API Gateway (各テナント用) — サイロ化されていないアプローチでは、テナントは API Gateway を共有し、テナントコンテキストに基づいてテナント固有の機能にルーティングします。
- AWS Lambda関数 — すべての Lambda 関数は同じコードを持ち、それぞれが呼び出す Amazon SageMaker のエンドポイントは環境変数で定義されることに注意してください。
- Amazon SageMakerのエンドポイント
- エンドポイント内の機械学習モデル
- 実行する各 Lambda 関数のロール — エンドポイントへのアクセスを許可します。
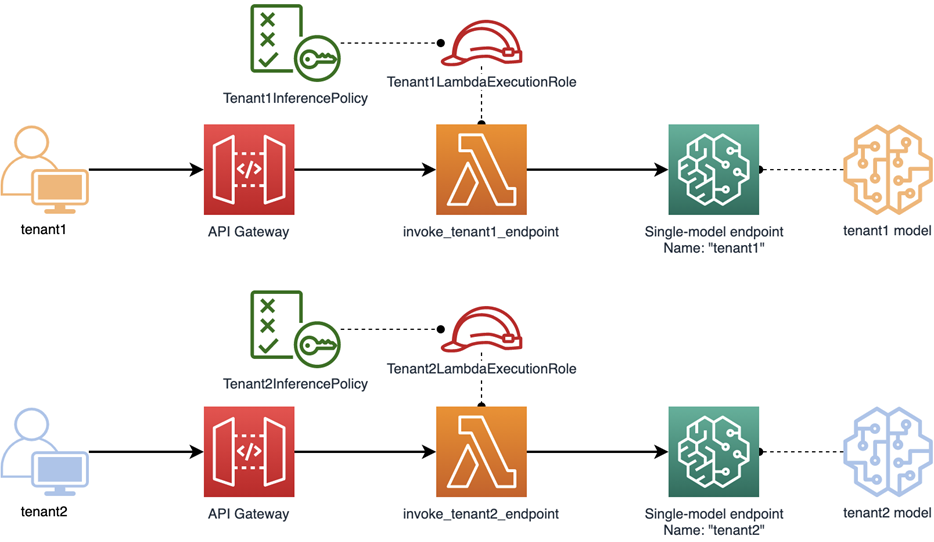
図 2 — リソースが分離されたサイロ型分離モデル
上の図では、サイロモデルの実装方法を確認できます。ここでは、テナント毎にゲートウェイとLambda関数を分けています。テナント毎に個別の関数を持つことで、それぞれの Lambda に独自の実行ロールを与えることができます。
各実行ロールには IAM ポリシーがアタッチされており、このテナントのエンドポイントに対してのみ sagemaker:InvokeEndpoint の許可を与えます。テナントを跨いだ InvokeEndpoint の呼び出しは、ポリシーで指定されたエンドポイントのリソース名にマッチしないため、IAM によって拒否されます。
サイロモデルの重要なポイントは、Lambda 関数、エンドポイント、ロールがそれぞれ個々のテナントに 1 対 1 でマッピングされることです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource":"arn:aws:sagemaker:<region>:<account-id>:endpoint/tenant2"
}
]
}ポリシー 1 — Tenant2LambdaExecutionRole にアタッチされた Tenant2InferencePolicy
上記のポリシーは、このモデルで分離ポリシーを設定する方法の例を示しています。Tenant2InferencePolicy は Tenant2 用です。一方、Tenant1 の Tenant1InferencePolicy は Resource 要素が異なり、Amazon リソースネーム (ARN) の最後の部分が tenant1 になります。
- 実行ロールを使用することで、不用意なアクセスを低減するモデル (侵襲性の低いモデル) を提供します。
- テナント毎のモデルが常にリクエストを処理できる状態にあるため、レイテンシーの増加につながる「ノイジーネイバー問題」を回避できます。
- 障害が発生しても、個々のテナントにしか影響しないため、影響範囲を限定的にできます。
- 開発者は、一時フォルダやグローバル変数などの共有リソースの不適切な使用を心配する必要がなく、異なるテナントからのリクエスト間でデータが公開される可能性がないため、セキュリティ設定が容易になります。
- テナントレベルのコスト計測は、リソースにタグを付けることで可能になります。例えば、キー名を
CostCenter、値をテナント名としたタグを付ければ、コスト分析ツールを使用して、Amazon SageMaker のエンドポイント費用のうち、各テナントに関連する費用がどれくらいあるかを判断することができます。
しかし、サイロモデルにはいくつかの欠点があります。
- 各エンドポイントには 1 つ以上の EC2 インスタンスが割り当てられているため、テナントの数が増えれば増えるほど費用も増加します。これらの専用リソースにより、テナントのアクティビティと実際のリソース消費を一致させることが困難になります。
- Amazon SageMaker のエンドポイントやその他のリソースに対して、AWS のサービスクォータを超える可能性があります。
- テナント毎にスタック全体をプロビジョニングすると、オンボーディングに時間がかかる可能性があります。
- 管理と運用の複雑さは、テナントの数に比例して増加します。
プールモデル
プールモデルでは、テナントはリソースを共有します。テナントが共有インフラを使用している環境では、テナント間で同じ値を適用する必要があるため、分離がより困難になります。
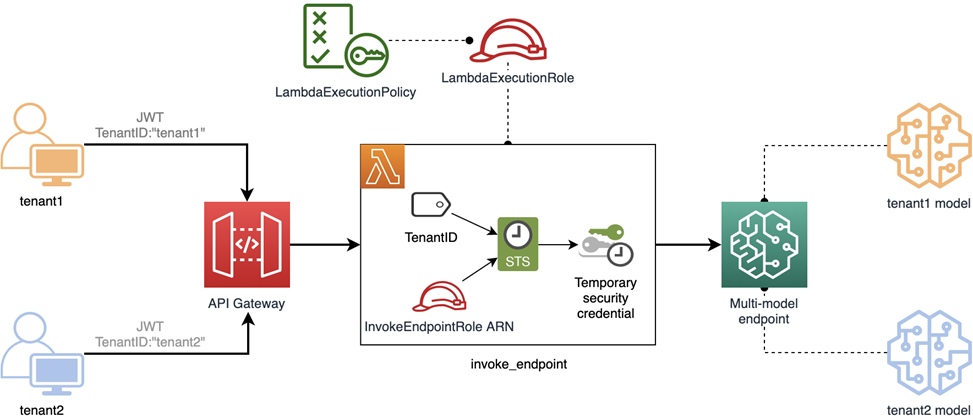
図 3 — 共有リソースを用いたプール型分離モデル
上の図は、プールモデルをどのように実装するかを示したものです。複数のテナントで共有する API Gateway と Lambda 関数を使用していることがわかります。また、テナント間で共有されるマルチモデルの Amazon SageMaker エンドポイントを採用し、複数の ML モデルを公開しています。
これらのモデルは、Amazon Simple Storage Service (Amazon S3) に保存され、必要なときだけエンドポイントのメモリにロードされます。マルチモデルエンドポイントの作成と使用方法については、AWS Machine Learning Blog の投稿記事 (日本語翻訳記事はこちら) をご覧ください。
エンドポイントは複数のテナントで共有されているため、テナントリソースを保護するには、きめ細かい IAM ポリシーを使用する必要があります。
この例では、前のサイロモデルと同様に Lambda の実行ロールがあります。ただし、サイロモデルの例とは異なり、実行ロールは特定のテナントに制約されることはありません。代わりに、すべてのテナントからのリクエストを処理できなければなりません。
さて、各リクエストが Lambda 関数に入ってくると、入ってきたテナントのコンテキストに基づいてポリシーを動的に適用する必要があります。このコンテキストは、属性ベースのアクセスコントロール (ABAC) を使用して適用されます。これは、基本的なロールベースのアクセスコントロール (RBAC) よりも柔軟性が高く、ロールにアタッチされたパラメータ化されたポリシーを使用して、アクセスを許可するリクエストを詳細に定義することができます。
(別のアプローチでは、動的に生成された IAM ポリシーを使用します。これについては、AWS SaaS Factory チームによる投稿記事をご覧ください。)
各リクエストに対して、Lambda 関数は一時的な IAM ロールセッションを動的に作成し、TenantID タグをアタッチします。このセッションは、エンドポイントにアクセスする際のセキュリティコンテキストを定義します。そして、セッションタグがリソース名と一致した場合にのみアクセスが許可され、現在のテナントで有効なモデルのみにアクセスが絞られます。
なお、Lambda 自体で一時的なセッションを作成する代わりに、API Gateway Lambda Authorizer を利用することもできます。その場合は、sts:AssumeRole が返す一時的な認証情報をレスポンスのコンテキストに渡します。すると、下流の Lambda では、この認証情報を使って Amazon SageMakerのエンドポイントにアクセスできます。
機械学習モデルはファイルに保存されるため、IAM ポリシーでモデルファイルへのアクセスを制御する条件を定義する必要があります。以下の InvokeEndpointPolicy を見ると、リクエストコンテキストの PrincipalTag/TenantID タグが、エンドポイント内で起動されるモデルのファイル名と一致するかどうかを検証していることがわかります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource": "*",
"Condition": {
"StringEquals": {
"sagemaker:TargetModel":"${aws:PrincipalTag/TenantID}.tar.gz"
}
}
}
]
}ポリシー 2 — InvokeEndpointRole にアタッチされた InvokeEndpointPolicy
動的なセッションの作成とタグ付けのプロセスは、この SaaS Factory の投稿記事 (日本語翻訳記事はこちら) で説明されています。この投稿記事では、Lambda が InvokeEndpointRole を引き受けるために必要な信頼ポリシーと、Lambda で使用できる一時的なセッションを作成してタグ付けする Boto3 の関数も紹介しています。
なお上記のポリシーでは、テナントの識別子がモデルのファイル名全体に一致するのではなく、.tar.gz の接尾辞がない部分、例えば tenant2 と tenant2.tar.gz に一致すると仮定しています。
テナント識別子を選択する際には、S3 のファイル名とタグ値を照合しているため、S3 のオブジェクトキー名のガイドラインに従わなければならないことに注意してください。
この ABAC チェックにより、同じ Lambda 関数の異なる呼び出しは、クロステナントでの推論呼び出しを拒否する特定のセキュリティコンテキストで実行されます。
プールモデルの利点は以下の通りです。
- エンドポイントのコストを含め、スケールメリットが向上します。推論をほとんど行わないテナントがある場合は、特にその節約効果が大きくなります。
- AWSのサービスクォータや制限に抵触するリスクを軽減できます。
- 追跡すべき AWS リソースが少なくなるため、管理しやすくなります。
- Infrastructure as Code (IaC) を使用して大量のリソースをプロビジョニングする必要がないため、プロビジョニング時間が短縮されます。
- 管理やデプロイモデルを他順位することができます。
プールモデルのデメリットは以下の通りです。
- 使用頻度の低いモデルを起動する際に、コールドスタートによるレイテンシー制約が発生することがあります。
- 特に規制の厳しい業界では、共有コンポーネントはコンプライアンスのニーズを満たさない可能性があります。
- 影響範囲が広く、1 つの EC2 インスタンスまたは他のクラウドリソースで障害が発生した場合、複数のテナントが影響を受けます。
ブリッジモデル
ブリッジモデルは、サイロモデルとプールモデルを組み合わせたものです。ここでは、インフラの一部のレイヤーが共有され、他のレイヤーは特定のテナント専用となっています。このようにして、サイロとプールの利点を、特定のニーズに基づいて適用することができます。
Amazon SageMaker 推論のブリッジアプローチでは、API Gateway と Lambda 関数は共有されていますが、Amazon SageMaker のエンドポイントはサイロ化されており、各テナントに個別のモデルが用意されています。
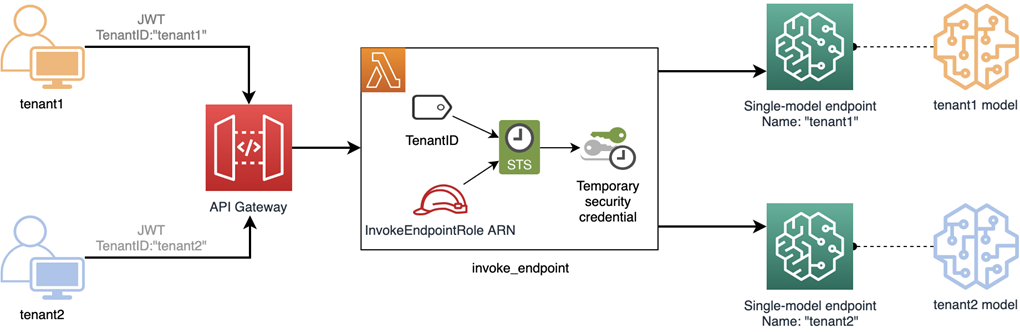
図 4 — 共有リソースと分離リソースを持つブリッジの呼び出しモデル
上の図では、ソリューションのエントリーポイントがプールモデルによく似ていることがわかります。ABAC と動的ポリシーのきめ細かい柔軟性を利用して、テナントのアクセスを制御します。また、このアプローチでは Lambda からのすべての呼び出しが共有 Lambda 実行ロールの下にあることが必要です。
この設計では、テナントの識別子をエンドポイント名として使用し、比較できるようにしています。Lambda 関数はコンテキストからエンドポイント名を取得しますが、通常は JWT のカスタムクレームとして渡されます。(エンドポイント名が環境変数に由来するサイロとは対照的です。)
プールモデルと同様に、InvokeEndpointRole は InvokeEndpoint を呼び出すことができます。しかし、ブリッジモデルでは、(前述のモデルファイル名ではなく) エンドポイント名を参照します。この値は、PrincipalTag/TenantID の値と完全に一致する必要があります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource":"arn:aws:sagemaker:<region>:<account-id>:endpoint/${aws:PrincipalTag/TenantID}"
}
]
}ポリシー 3 — 単一モデルのエンドポイントのための InvokeEndpointRole にアタッチされた InvokeEndpointPolicy
このアプローチには、サイロモデルとプールモデルに共通する利点があり、それぞれのモデルのバランスをとることで、一部の組織には適していると考えられます。
利点は以下の通りです。
- サイロモデルと同様に、ブリッジモデルには、単一モデルの推論エンドポイントによって提供される一貫した低レイテンシーと、より明確に管理されたセキュリティ境界という利点があります。
- Lambda 関数を共有することで、管理下にあるリソースの数が増加するため、ある程度シンプルになります。
- プールモデルと同様に、テナント毎に新しい静的なロールを生成する必要はなく、ロールの数が制限されるリスクもありません。代わりに、新しいテナントのモデルは ABAC によって自動的に保護されます。
このアプローチは、サイロモデルやプールモデルと同様にいくつかのデメリットがあります。
- サイロモデルと同様に、テナントの追加に伴いエンドポイントのコストが急激に上昇します。
- また、プールモデルと同様に、開発者は呼び出し間で機密データを分離するように注意する必要があります。
簡易比較表
| メリット | デメリット | 適用するケース | |
| サイロ |
|
|
|
| プール |
|
|
|
| ブリッジ |
|
|
|
まとめ
Amazon SageMaker の推論で複数のテナントをサポートする際、SaaS プロバイダーは、低コスト、低レイテンシー、効率的な管理、セキュリティなどの複数の要件のバランスを取りながら、提供するサービスのニーズに最も適したデプロイモデルを見つける必要があります。
SaaS プロバイダーは、ビジネスや法的要件に応じて、サイロモデル、プールモデル、ブリッジモデルのいずれかを選択し、多くのテナントに推論用エンドポイントを提供することができます。サイロモデルではセキュリティとパフォーマンスのためにテナントを完全に分離し、プールモデルでは共有リソースによりコストを削減し、ブリッジモデルでは両者のバランスをとります。
コンピューティングリソースは共有することも、分離することもできます。共有リソースが使用されている場合、IAM と ABAC を使用すると、サービスプロバイダーは複数のテナントを安全かつ便利にサポートできます。
さらに詳しく知りたい方は、以下の資料をご覧になることをお勧めします。
- Whitepaper: SaaS Tenant Isolation Strategy (SaaS テナント分離戦略)
- How to implement SaaS tenant isolation with ABAC and AWS IAM (ABAC と AWS IAM による SaaS テナント分離の実装方法)
- Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda (Amazon API Gateway と AWS Lambda を使用した Amazon SageMaker モデルのエンドポイントの呼び出し)
翻訳はソリューションアーキテクト 杉本 晋吾 が担当しました。原文はこちらです。