Amazon Web Services ブログ
Amazon Redshift で slowly changing dimension を実装する
本記事は Amazon Web Services, Data Warehouse Specialist Solutions Architect である Milind Oke と Analytics Specialist Solutions Architect である Bhanu Pittampally によって投稿されたものです。
Amazon Redshift は、フルマネージドな、ペタバイトスケールのクラウドデータウェアハウスサービスです。データウェアハウス内での使用に最適化されたデータのスキーマとして、スタースキーマが挙げられます。スタースキーマとは、ディメンションという、ファクト(注:ビジネス関連の測定データ)やメジャーなどの情報をカテゴライズし、ビジネスクエスチョンに回答するための構造です。ディメンションテーブルの属性(カラム)は、ファクトテーブルのメジャーに対してビジネス上の意味を与えます。ディメンションテーブル内のレコードは、顧客 ID などのユニークなキーによって特定され、ファクトテーブルのレコードはディメンションテーブルの主キーに対して外部キーを持ちます。ディメンションテーブルとファクトテーブルは、これらそれぞれの主キーと外部キーを介して結合されます。
ディメンションテーブルのレコードは、時間の経過とともに徐々に変化していくことがあります。例えば、顧客の配送先住所は変化します。この事象を slowly changing dimension (SCD) と呼びます。しばしばレポーティングのために、顧客の配送先住所の変化があったという事実を記録しておく必要があります。このような SCD を管理する方法として、Type 1 から Type 7 の方法から選択できます。Type 0 は日付など、ディメンションの変化がないときの場合に適用されます。最も一般的に使用されるのが以下の Type 1, 2, 3 です。
- Type 1 (履歴なし) – ディメンションテーブルは常に最新のバージョンで、履歴は保持しない
- Type 2 (履歴保持) – 全ての変更は記録され、日付とフラグで追跡される
- Type 3 (直前の値) – 最新から一つ古い属性の値が、別の属性として管理される
事前準備
この記事では、以下の準備が必要です。
- AWS アカウント
- Amazon Redshift クラスター
ソリューションの概要
この記事では、Amazon Redshift クラスター上で SCD を実装し、ベストプラクティスやアンチパターンにも触れます。デモンストレーションとして、TPC-DS ベンチマークデータセット の customer テーブルを使用します。変化する対象カラムを作成し、ETL での結合テクニックを用いて Type 2 のディメンションテーブルを作成する方法をデモンストレーションします。
次の図は、処理フローの図です。

次の図では、通常のディメンションテーブルがどのようにして Type 2 のディメンションテーブルに変化するかを解説しています。
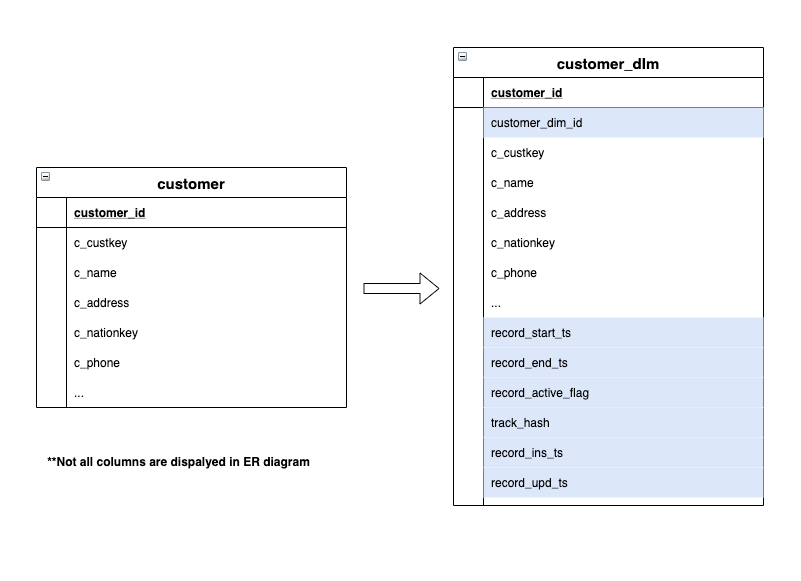
slowly changing dimensions の実装
開始するために、Amazon Redshift Labs にある二つの AWS CloudFormation テンプレートのうち一つを使用します。
- lab2.yaml – TPC データを既存のクラスタに読み込む
- lab2_cluster.yaml – 新規クラスタを作成し、TPC データを読み込む
この記事では、重要な SQL ステートメントのみを取り上げますが、完全な SQL のコードは scd2_sample_customer_dim.sql にあります。
あるディメンションテーブルに SCD を実装するための最初のステップは、SCD 追跡属性を追加するところです。例えば、レコードの有効化日付・無効化日付、レコード有効フラグなどは、属性の有効・無効の記録のため一般的に追加されます。これらのフィールドは、以降 SCD フィールドと呼ぶこととします。
これらの SCD フィールドは、フィールドの変更のために追加されます。例えば、顧客住所が変更されたときに、ディメンションテーブルの既存のレコードは無効とフラグされ、新たなレコードが有効フラグ付きで挿入されます。こうすることで、全ての SCD 属性の変更がテーブルに記録され、ビジネスユーザーはクエリをすることで対象属性の過去の変更状況を見ることが可能となります。さらに、以下のテクニックを紹介します。
- ハッシュ値を記録し、より簡単に顧客データのフィールドが変更されたかを確認する。このハッシュ値は全てのフィールドに対して計算されるので、全てのフィールドを比較しなくても変更が検知できる。
- 挿入・更新のタイムスタンプを記録することで、実際にディメンションカラムがいつテーブルに追加・更新されたかを捉える。
以下のコードで、追加された SCD フィールドを定義しています。
drop table if exists customer_dim cascade;
create table customer_dim (
customer_dim_id bigint generated by default as identity(1, 1),
c_custkey bigint distkey,
c_name character varying(30),
c_address character varying(50),
c_nationkey integer,
c_phone character varying(20),
c_acctbal numeric(12, 2),
c_mktsegment character varying(10),
c_comment character varying(120),
track_hash bigint,
record_start_ts timestamp without time zone
default '1970-01-01 00:00:00'::timestamp without time zone,
record_end_ts timestamp without time zone
default '2999-12-31 00:00:00'::timestamp without time zone,
record_active_flag smallint default 1,
record_upd_ts timestamp without time zone default current_timestamp,
record_insert_ts timestamp without time zone default current_timestamp)
diststyle key
sortkey (c_custkey);次に、ディメンションテーブルへの初期データ挿入を行います。初回の挿入なので、SCD 追跡属性は全て有効化します。例えば、レコード有効化日付は 1900-01-01 などの昔の日付を設定したり、有効化されたのがいつかを記録するビジネス的に意味のある日付に設定します。レコード無効化日付は 2999-12-31 などの未来の日付を設定し、レコード有効フラグは有効の意味を示す 1 を設定します。
初期データ挿入の完了の後、ソースシステムからの変更をロードするためのステージングテーブルを作成します。このテーブルは変更の一時的な記録場所として使用されます。与えられたレコードが変更されたかを検知するためには、このステージングテーブルを、主キー (c_custkey) を介して顧客ディメンションテーブルに左外部結合します。左外部結合を使用することによって、マッチの有無に関わらずレコードを射影します。そのため、マッチしたレコードは更新されたものとして扱われ、マッチしないレコードは挿入されたものとして扱われます。
このデータウェアハウスでは、以下のビジネス要求を満たさねばならないと仮定します。
- 住所と電話番号のフィールドのみ変更を追跡する (レコードの有効化日付・無効化日付を使用した Type 2)
- 他の属性は、新たに記録せず最新のもののみ保持する (Type 1)
- ソースシステムは段階的な変更のレコードを出力する
ソースシステムが段階的な変更のレコードを出力することができず、一括で更新処理を行うような場合では、データウェアハウスはレコードの変更を検知するためにロジックを実装する必要があります。このようなワークロードでは、Amazon Redshift のビルトインハッシュ関数を変更を検知したいディメンションカラム全てに適用することでユニークな値を生成します。今回の場合、顧客住所と電話番号が SCD として記録されます。FNV_HASH を使用し、1.84 x 10^19 通りのユニークな値を表現できる 64 ビットの符号付き整数を生成します。より小さいディメンションテーブルでは、CHECKSUM を使用して 4.4 x 10^9 通りのユニークな値を表現できる 32 ビットの符号付き整数を生成することも可能です。
ディメンションのレコードが新しいかを判定するのに new_ind フラグを使用し、ディメンションカラムが変更されたかを検知するためにはレコードのハッシュ値と track_ind 値を比較します。
変更は、次に示すコードのように、ステージングテーブルとディメンションテーブルを主キーで結合することで検知されます。
truncate table stg_customer;
insert into stg_customer
with stg as (
select
custkey as stg_custkey, name as stg_name,
address as stg_address, nationkey as stg_nationkey,
phone as stg_phone, acctbal as stg_acctbal,
mktsegment as stg_mktsegment, comment as stg_comment,
effective_dt as stg_effective_dt,
FNV_HASH(address,FNV_HASH(phone)) as stg_track_hash
from
src_customer
)
select
s.* ,
case when c.c_custkey is null then 1 else 0 end new_ind,
case when c.c_custkey is not null
and s.stg_track_hash <> track_hash then 1 else 0 end track_ind
from
stg s
left join customer_dim c
on s.stg_custkey = c.c_custkey
;マッチしないレコード (new_ind = 1 のような全く新しいレコード) については、ディメンションテーブルに SCD 追跡属性を付加された状態 (有効化フラグが 1) で挿入されます。
マッチするレコードについては、2 パターンの変更が考えられます。
- SCD Type 2 フィールドの変更 – この場合、以下の 2 ステップのプロセスで既存の顧客レコードも保持しつつ新たな顧客レコードの Type 2 フィールドを記録します。これによって、最初のビジネス要求に応えることが可能です。
- Step 1 – ディメンションテーブルの既存のレコードを無効化します。具体的には、レコード無効化日付を現在のタイムスタンプに設定し、有効フラグを 0 にします。
- Step 2 – 新たな顧客レコードをステージングテーブルからディメンションテーブルに挿入します。レコード有効化日付を現在のタイムスタンプに設定し、無効化日付は未来の値に設定します。有効フラグを 1 にします。
- SCD Type 1 フィールドの変更 – この場合、現在のディメンションテーブルのレコードを、ステージングテーブルの最新のレコードをもとに更新します。この時、SCD 追跡属性やフラグは変更しません。このステップで、Type 1 フィールドに対して常に最新のレコードを保持し、2 つ目のビジネス要求に応えることが可能です。
ディメンションテーブルへの変更は次のコードで適用されます。
-- merge changes to dim customer
begin transaction;
-- close current type 2 active record based of staging data where change indicator is 1
update customer_dim
set record_end_ts = stg_effective_dt - interval '1 second',
record_active_flag = 0,
record_upd_ts = current_timestamp
from stg_customer
where c_custkey = stg_custkey
and record_end_ts = '2999-12-31'
and track_ind = 1;
-- create latest version type 2 active record from staging data-- this includes Changed + New records
insert into customer_dim
(c_custkey,c_name,c_address,c_nationkey,c_phone,c_acctbal,
c_mktsegment,c_comment,track_hash,record_start_ts,record_end_ts,
record_active_flag, record_insert_ts, record_upd_ts)
select
stg_custkey, stg_name, stg_address, stg_nationkey, stg_phone,
stg_acctbal, stg_mktsegment, stg_comment, stg_track_hash,
stg_effective_dt as record_start_ts, '2999-12-31' as record_end_ts,
1 as record_active_flag, current_timestamp as record_insert_ts,
current_timestamp as record_upd_ts
from
stg_customer
where
track_ind = 1 or new_ind = 1;
-- update type 1 current active records for non-tracking attributes
update customer_dim
set c_name = stg_name,
c_nationkey = stg_nationkey,
c_acctbal = stg_acctbal,
c_mktsegment = stg_mktsegment,
c_comment = stg_comment,
record_upd_ts = current_timestamp
from
stg_customer
where
c_custkey = stg_custkey
and record_end_ts = '2999-12-31'
and track_ind = 0 and new_ind = 0;
-- end merge operation
commit transaction;ベストプラクティス
Amazon Redshift クラウドデータウェアハウスを用いることで、多量の更新を効率よく処理することが可能です。このために、対象となるディメンションテーブルに対して同様のスキーマをもったステージングテーブルを用意します。そして、以前のコードブロックでも示したように、ステージングとディメンションテーブルを結合することで更新・挿入処理をトランザクションブロック内で行うことが可能です。このオペレーションはディメンションテーブルへ一括で更新・挿入を行うため、パフォーマンスを出すことが可能です。
Amazon Redshift のシェアードナッシングアーキテクチャでは一般的に、ノード間のデータ移動が最小で、各ノード内で処理が独立に行われるときにパフォーマンスが最大化します。ディメンションテーブルと中間ステージングテーブルが共通の分散キーを持つ場合、各処理はノード内で完結し、パフォーマンスが最大化されています。
アンチパターン
カーソルを使用して、ディメンションレコードを一行づつ比較し、ディメンションの更新や挿入を行うことも可能です。小さなテーブルではこの方法を使うこともできますが、大きなテーブルでは、この記事のように一括で処理することを推奨します。
クリーンアップ
今後の課金が発生しないよう、CloudFormation スタックを削除することでリソースを削除します。
まとめ
この記事では、slowly changing dimensions (SCD) の概要に触れ、Amazon Redshift で SCD を実装し、中間ステージングテーブルを使用してディメンションテーブルに対して ETL 処理をするベストプラクティスを紹介し、最後にアンチパターンの紹介をしました。
より詳しい情報や他のベストプラクティスは、データをロードするための Amazon Redshift のベストプラクティスを参照してください。更新や挿入処理の実装方法は、新しいデータの更新と挿入を参照してください。
原文はこちらです。