Amazon Web Services ブログ
Verizon Media Group がオンプレミスの Apache Hadoop および Spark から Amazon EMR に移行した方法
Verizon Media Group によるゲスト投稿です。
Verizon Media Group (VMG) が直面した大きな問題の一つに、必要な時間内にコンピューティング能力をスケールアウトできないことがありました。つまり、ハードウェアの取得に数か月かかることがよくあったのです。ハードウェアをスケーリングおよびアップグレードしてワークロードの変更に対応することは、経済的に実行が難しく、冗長管理ソフトウェアのアップグレードにはかなりのダウンタイムが必要で、多大なリスクを伴いました。
VMG では、Apache Hadoop や Apache Spark などのテクノロジーに依存し、データ処理パイプラインを実行しています。以前は Cloudera Manager でクラスターを管理していましたが、リリースサイクルが遅いことがよくありました。そのため、利用可能なオープンソースリリースの古いバージョンを実行しなければならず、Apache プロジェクトの最新のバグ修正やパフォーマンスの改善を利用することができませんでした。こうした理由から、既存の AWSへの投資と合わせて、分散コンピューティングパイプラインを Amazon EMR に移行することを検討したのです。
Amazon EMR は Apache Hadoop や Apache Spark などのビッグデータフレームワークの実行をシンプル化する、マネージドクラスタープラットフォームです。
この投稿では、データ処理のニーズに対応するためのパイプラインの構築中に発生し、解決した問題について説明します。
弊社について
Verizon Media はつまるところ、オンライン広告会社です。今日のほとんどのオンライン広告は、バナー広告またはビデオ広告としても知られるディスプレイ広告を通じて行われます。すべてのインターネット広告は通常、形式に関係なく、さまざまな種類のビーコンを追跡サーバーに送信します。この追跡サーバーは受信したビーコンを 1 つまたは複数のイベントシンクに記録する唯一の責任を持つ、極めてスケーラブルなウェブサーバーをデプロイします。
パイプラインのアーキテクチャ
弊社では主に動画広告を扱っており、複数の地理的な場所にデプロイした NGINX ウェブサーバーを使用しています。これは、ビデオプレーヤーから直接発生するイベントを、リアルタイム処理用には Apache Kafka に、バッチ処理用には Amazon S3 に記録するものです。弊社グループの典型的なデータパイプラインには、このような入力フィードの処理、検証や強化ルーチンの適用、結果データの集計、およびレポート目的の宛先へのレプリケートが含まれます。次の図は、作成した典型的なパイプラインを示しています。
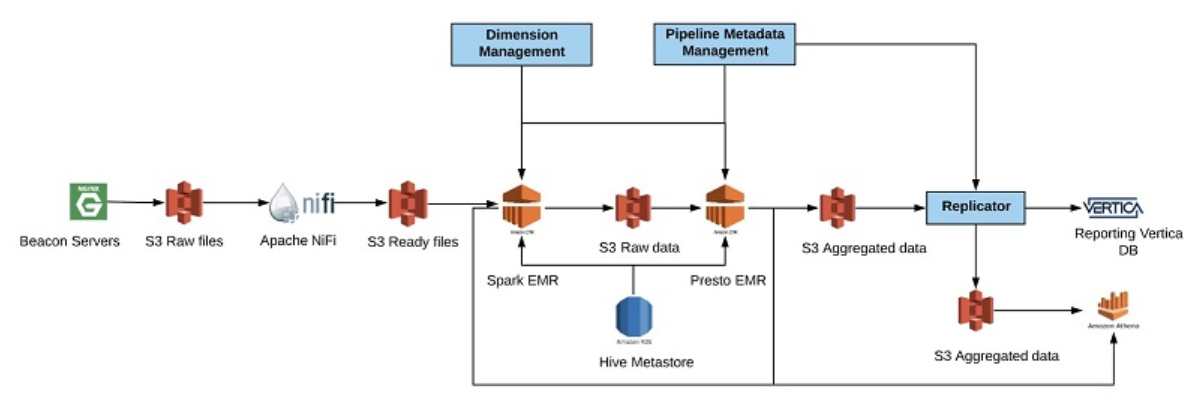
NGINX ビーコンサーバーで、データの取得を開始します。データは 1 分間隔でローカルディスクの gzip ファイルに保存されます。毎分、NGINX サーバーから未加工 S3 データのある場所にデータを移動します。S3 に到着すると、ファイルは Amazon SQS にメッセージを送信します。Apache NiFi は SQS メッセージをリッスンして、ファイルでの作業を開始します。この間、NiFi は小さなファイルを大きなファイルにグループ化し、S3 の仮の場所にある特別なパスに結果を保存します。パス名は逆タイムスタンプを使用して結合され、ボトルネックを読み取らないようにデータをランダムな場所に保存します。
1 時間ごとに Amazon EMR で Spark クラスターをスケールアウトし、未加工データを処理します。この処理には、データの強化と検証が含まれます。このデータは、S3 の永続的な場所のフォルダーに Apache ORC 列形式で保存されます。また、AWS Glue データカタログを更新して、問題を調査する必要がある場合に備えて、このデータを Amazon Athena に公開します。未加工データの処理が終了したら、Spark EMR クラスターをダウンスケールし、Presto on Amazon EMR を使用して定義済みの集計テンプレートに基づいてデータの集計を開始します。集計データは S3 の特別な場所に、集計データ用に ORC 形式で保存されます。
さらに、Athena でクエリできるよう、データの場所でデータカタログを更新します。加えて、レポート用に S3 から Vertica にデータをレプリケートし、内部および外部の顧客にデータを公開します。今回のシナリオでは、Vertica の災害対策 (DR) ソリューションとして Athena を使用します。レポートプラットフォームが Vertica の状態が悪いと判断すると、Amazon Athena に自動的にフェールオーバーします。このソリューションは、私たちにとって非常に費用対効果が高いことが分かりました。この投稿では説明を割愛しますが、リアルタイム分析では Athena のユースケースがもう一つあります。
移行に関する課題
Amazon EMR への移行では、最良の結果を得るために設計を変更する必要がありました。クラウドでビッグデータパイプラインを実行する場合、運用コストの最適化がすべてです。主要なコストは 2 つあり、ストレージとコンピューティングです。従来のオンプレミス Hadoop ウェアハウスでは、これらはストレージノードとして結合され、計算ノードとしても機能していました。これで、データの局所性から生まれるパフォーマンス上の利点が得られます。しかしこの結合の欠点は、メンテナンスなどのストレージレイヤーへの変更が計算レイヤーにも影響を与える可能性があることです。AWS などの環境では、ストレージに S3 を使用し、コンピューティングには Amazon EMR を使って、ストレージとコンピューティングを分離できます。これは、すべてのクラスターが一時的なものであるため、クラスターのメンテナンスを扱う際に柔軟性という大きな利点をもたらします。
コストをさらに節約するため、計算レイヤーで最大限の使用率を達成する方法を考え出す必要がありました。つまり、異なるパイプラインに複数のクラスターを使用するようにプラットフォームを切り替える必要があったことを意味します。これで、各クラスターはパイプラインのニーズに応じて、自動的にスケーリングされるようになります。
S3 への切り替え
S3 で Hadoop データウェアハウスを実行する際には、追加の考慮事項があります。S3 は HDFS のようなファイルシステムではないため、HDFS が持つような即時的な整合性を保証しません。S3 にアクセスするための REST API を備えた最終的な整合性を持つオブジェクトストアと S3 を見ることができます。
名前変更
S3 との主な違いは、名前変更はアトミック操作ではない点です。S3 の名前変更操作はどれも、コピーを実行してから削除を実行します。S3 で名前変更を実行することは、実行時間のコストを考えると望ましい方法ではありません。S3 を効率的に使用するには、名前変更操作の使用を削除する必要があります。名前変更は、アトミック操作として一時ディレクトリを最終的な宛先に移動するなど、さまざまなコミット段階において Hadoop ウェアハウスで一般的に使用されています。名前変更操作を避け、代わりにデータを一度書き込むのが最も良いアプローチです。
出力コミッター
Spark と Apache MapReduce のジョブには、複数の分散ワーカーが生成した出力ファイルを最終出力ディレクトリにコミットするコミット段階があります。出力コミッターがどのように動作するかの説明はこの投稿では割愛しますが、重要なのは、HDFS で動作するように設計された標準のデフォルト出力コミッターは名前変更操作に依存するという点です。前述のように、S3 のようなストレージシステムではパフォーマンスが低下します。弊社で上手くいった簡単な戦略は、投機的実行を無効にし、出力コミッターのアルゴリズムバージョンを切り替えることでした。これだと、名前変更に依存しない独自のカスタムコミッターを作成することも可能です。たとえば、Amazon EMR 5.19.0 の時点で、AWS は S3 への書き込みを最適化する Spark 用のカスタム OutputCommitter をリリースしています。
結果整合性
S3 を使用する際での主な課題の一つに最終的に整合する点が挙げられますが、一方で HDFS は強い一貫性があります。S3 は新しいオブジェクトの PUTS に読み込み後に書き込みを保証しますが、これだと一貫した分散パイプラインを構築するのに必ずしも十分とはいえません。ビッグデータ処理でよく発生する一般的なシナリオに、あるジョブはファイルのリストをディレクトリに出力し、もう 1 つのジョブがそのディレクトリから読み込むというものがありますこの 2 つ目のジョブを実行するには、ディレクトリを一覧表示して、読み込む必要があるすべてのファイルを見つけなければなりません。S3 にはディレクトリはありません。同じプレフィックスを持つファイルをリストするだけです。つまり、最初のジョブの実行が終了した直後に、新しいファイルがすべて表示されない場合があります。
この問題に対処するため、AWS は EMRFS を提供しています。EMRFS は S3 の上に追加された整合性レイヤーであり、一貫性のあるファイルシステムのように動作します。EMRFS は Amazon DynamoDB を使用して、S3 上のすべてのファイルに関するメタデータを保持します。簡単に言えば、S3 プレフィックスを一覧表示する際に EMRFS を有効にすると、実際の S3 応答が DynamoDB のメタデータと比較されるのです。不一致がある場合、S3 ドライバーは少し長くポーリングし、S3 にデータが表示されるのを待ちます。
全体的に見て、データの整合性を確保するには EMRFS が必要であることが分かりました。一部のデータパイプラインでは、PrestoDB を使って S3 に保存されているデータを集計しています。このとき、弊社は EMRFS のサポートなしで PrestoDB を実行することを選択しました。このため、アップストリームジョブは最終的な整合性リスクにさらされるものの、ダウンストリームデータとアップストリームデータの不一致をモニタリングし、必要に応じてアップストリームジョブを再実行することで、これらの問題を回避できることが分かりました。私たちの経験では、整合性の問題はほとんど起こっていませんが、起こる可能性はあります。EMRFS なしで実行することを選択した場合は、それに応じてシステムを設計する必要があります。
自動スケーリング戦略
Amazon EMR 自動スケーリング機能の活用方法を見つけることは、ある意味で取るに足らない一方で重要な課題でした。最適な運用コストを達成するには、アイドル状態のサーバーがないことを確認する必要があります。
これを実現する方法は明らかで、長時間実行する EMR クラスターを作成し、即座に利用できる自動スケーリング機能を使用して、クラスターで利用可能な空きメモリなどのパラメータに基づいてクラスターのサイズを制御します。しかし、一部のバッチパイプラインは 1 時間ごとに開始し、きっちり 20 分間実行されるため、計算量が非常に多くなります。処理時間は極めて重要ですので、時間を無駄にしたくありません。最適な戦略は、特定の大きなバッチパイプラインを開始する前に、カスタムスクリプトを使用して先にクラスターのサイズを変更することです。
加えて、すべてのパイプラインはわずかに異なるため、単一クラスターで複数のデータパイプラインを実行し、任意の時点で最適な容量を維持しようとするのは困難です。その代わり、弊社はすべての主要なパイプラインを独立した EMR クラスターで実行することを選択しました。これだと多くの利点があり、欠点はわずかしかありません。利点は、各クラスターを必要な時間に正確にサイズ変更し、そのパイプラインに必要なソフトウェアバージョンを実行して、他のパイプラインに影響を与えずに管理できることです。小さな欠点としては、余分な名前ノードとタスクノードを実行するため、計算の無駄が少しあることです。
自動スケーリング戦略を開発する際、パイプラインを実行する必要があると、まずクラスターを作成および削除しようとしました。しかし、クラスターをゼロからブートストラップするには、思った以上に時間がかかることがすぐに判明しました。代わりに、これらのクラスターを常時実行し、パイプラインが開始する前にタスクノードを追加してクラスターをアップサイズし、パイプラインが終了するとすぐにタスクノードを削除しました。すると、タスクノードを追加するだけで、パイプラインの実行がはるかに高速に開始できることが分かりました。実行時間の長いクラスターで問題が発生した場合、すぐにリサイクルして新しいクラスターを最初から作成できます。これらの問題については、引き続き AWS と連携して対処していきます。
弊社のカスタム自動スケーリングスクリプトは簡単な Python スクリプトで、通常ではパイプラインが開始する前に実行されます。たとえば、パイプラインが単一のマッピングおよびリデュースフェーズを持つ単純な MapReduce ジョブで構成されているとしましょう。また、マッピングフェーズの方が計算コストが高いとします。次の 1 時間に処理する必要があるデータの量を調べ、Hadoop ジョブと同じ方法でこのデータを処理するのに必要なマッパーの量を計算する、簡単なスクリプトを作成します。マッピングタスクの量が分かったら、すべてのマッパータスクを並列して実行するサーバーの数を決定できます。
Spark のリアルタイムパイプラインを実行する場合は少し複雑です。アプリケーションの実行中に、計算リソースを削除しなければならないことがあるためです。弊社で上手くいった簡単な戦略は、既存のクラスターと並列して別のリアルタイムクラスターを作成し、過去 1 時間に処理したデータ量に基づいて必要なサイズに拡張し、さらに容量を増やして、新しいクラスターでリアルタイムアプリケーションを再起動するというものです。
運用コスト
EC2 見積ツールであらゆる AWS のコストを事前に評価できます。ビッグデータパイプラインを実行する際の主なコストは、ストレージとコンピューティングです。EMRFS を使用する場合、わずかですが DynamoDB などの追加コストもあります。
ストレージコスト
最初に考慮すべきコストは、ストレージにかかる費用です。HDFS のデフォルトのレプリケーション係数は 3 なので、1 PB ではなく 3 PB のストレージ容量が実際に必要になります。
S3 に 1 GB を保存するには、1 か月あたり 0.023 USD 前後かかります。S3 はすでに非常に冗長であるため、複製係数を考慮する必要はありません。このため、コストがすぐに 67% 削減されます。書き込みまたは読み込み要求の他のコストも考慮する必要がありますが、通常、これらは小さい傾向にあります。
コンピューティングコスト
ストレージに次いで大きいコストは、コンピューティングです。コンピューティングコストを削減するには、リザーブドインスタンスの料金を可能な限り活用しましょう。AWS に 16 個の VCPU を搭載する m4.4xlarge インスタンスタイプだと、3 年間予約すると 1 時間あたり 0.301 USDかかります。料金はすべて前払いです。オンデマンドインスタンスの料金は 1 時間あたり 0.8 USD で、62% の料金差があります。これは、定期的な容量計画を実行するような大規模な組織では、簡単に実現できます。Amazon EMR プラットフォームを使用するには、すべての Amazon EMR マシンに 1 時間あたり 0.24 USD の料金が追加されます。Amazon EC2 スポットインスタンスを使用することで、さらにコストを削減できます。詳細については、インスタンス購入オプションをご参照ください。
最適な運用コストを達成するには、コンピューティングクラスターがアイドル状態にならないようにし、クラスターが特定の瞬間に行っている作業量に基づいて動的にダウンスケールするようにしてください。
最後に考察すべきこと
弊社は Amazon EMR でビッグデータパイプラインを 1 年以上運用し、データはすべて S3 に保存しています。リアルタイム処理パイプラインが 1 秒あたり 200 万件を超えるイベントの処理でピークに達することが時折ありました。このとき、最初のイベントから更新済み集計までの合計処理レイテンシーは 1 分でした。Amazon EMR の柔軟性と、数分でクラスターを分解し再び作成できる能力の恩恵を受けています。Amazon EMR プラットフォームの全体的な安定性に満足しており、今後も AWS と協力して改善を続けていきます。
前述したように、コストは考慮すべき主要な要素です。Hadoop を自分のデータセンターで実行する方が安い可能性があると言う人もいるかもしれません。しかしこの議論は、組織が効率的にそれを行える能力があるかどうかにかかっています。隠れた運用コストがあるだけでなく、順応性が低い場合があるからです。オンプレミスでの実行という作業は軽視するべきではなく、きちんと計画しメンテナンスを行う必要があることを、私たちは直接の経験から理解しています。Amazon EMR などのプラットフォームは、ビッグデータシステムを設計する際に多くの利点をもたらすと考えています。
免責事項:この記事の内容および意見は第三者の作者によるものであり、AWS はこの記事の内容または正確性について責任を負いません。
著者について
 Lev Brailovskiy は Verizon Media のサプライサイドプラットフォーム (SSP) で、サービスエンジニアリンググループを率いるエンジニアリングディレクターです。ソフトウェアシステムの設計と構築に 15 年以上携わってきました。過去 6 年間、Lev はプライベートデータセンターとパブリッククラウドの両方で、大規模なレポートやデータ処理ソフトウェアの設計、開発、および実行に取り組んできました。LinkedIn を使って連絡してください。
Lev Brailovskiy は Verizon Media のサプライサイドプラットフォーム (SSP) で、サービスエンジニアリンググループを率いるエンジニアリングディレクターです。ソフトウェアシステムの設計と構築に 15 年以上携わってきました。過去 6 年間、Lev はプライベートデータセンターとパブリッククラウドの両方で、大規模なレポートやデータ処理ソフトウェアの設計、開発、および実行に取り組んできました。LinkedIn を使って連絡してください。
 Zilvinas Shaltys は Verizon の Video Syndication クラウドデータウェアハウスプラットフォームのテクニカルリードです。かなり大きな規模でデプロイされたさまざまなビッグデータテクノロジーを使用してきた、長年の経験があります。以前は、ビッグデータパイプラインの AOL データセンターから Amazon EMR への移行を担当していました。現在、既存のバッチおよびリアルタイムビッグデータシステムの安定性とスケーラビリティの改善に取り組んでいます。LinkedIn を使って連絡してください。
Zilvinas Shaltys は Verizon の Video Syndication クラウドデータウェアハウスプラットフォームのテクニカルリードです。かなり大きな規模でデプロイされたさまざまなビッグデータテクノロジーを使用してきた、長年の経験があります。以前は、ビッグデータパイプラインの AOL データセンターから Amazon EMR への移行を担当していました。現在、既存のバッチおよびリアルタイムビッグデータシステムの安定性とスケーラビリティの改善に取り組んでいます。LinkedIn を使って連絡してください。