Amazon Web Services ブログ
Amazon CloudWatch を使用して Amazon DynamoDB のテーブルサイズとアイテム数のメトリクスをモニタリングする方法
Amazon DynamoDB は、オペレーションに関するメトリクスを Amazon CloudWatch に送信します。この記事の執筆時点では、スループットの消費量とプロビジョニング量、アカウントとテーブルの制限、リクエストの待ち時間、システムエラー、ユーザーエラーなどの33 のメトリクスが含まれています。ただし、DynamoDB テーブルのサイズとアイテム数の 2 つのメトリクスは含まれていません。これらの値は、DynamoDB の AWS マネジメントコンソールで確認する事ができ、DescribeTable API 呼び出しを使用して取得する事もできますが、CloudWatch には送信されません。
この記事では、これらメトリクスの過去データをトラックすることの重要性を示し、AWS Lambda と Amazon EventBridge を使用して、これらのメトリクスを CloudWatch に送信する設計について説明し、AWS Cloud Development Kit (AWS CDK) を使ってモニタリングを自分のアカウントにデプロイする手順について説明します。この手順を実施する事で、CloudWatch 内で DynamoDB テーブルとインデックスのサイズ、アイテム数にアクセスできるようになり、次の図1に示すようにデータを簡単にトラックしてグラフ化したり、アラートを設定する事が可能になります。
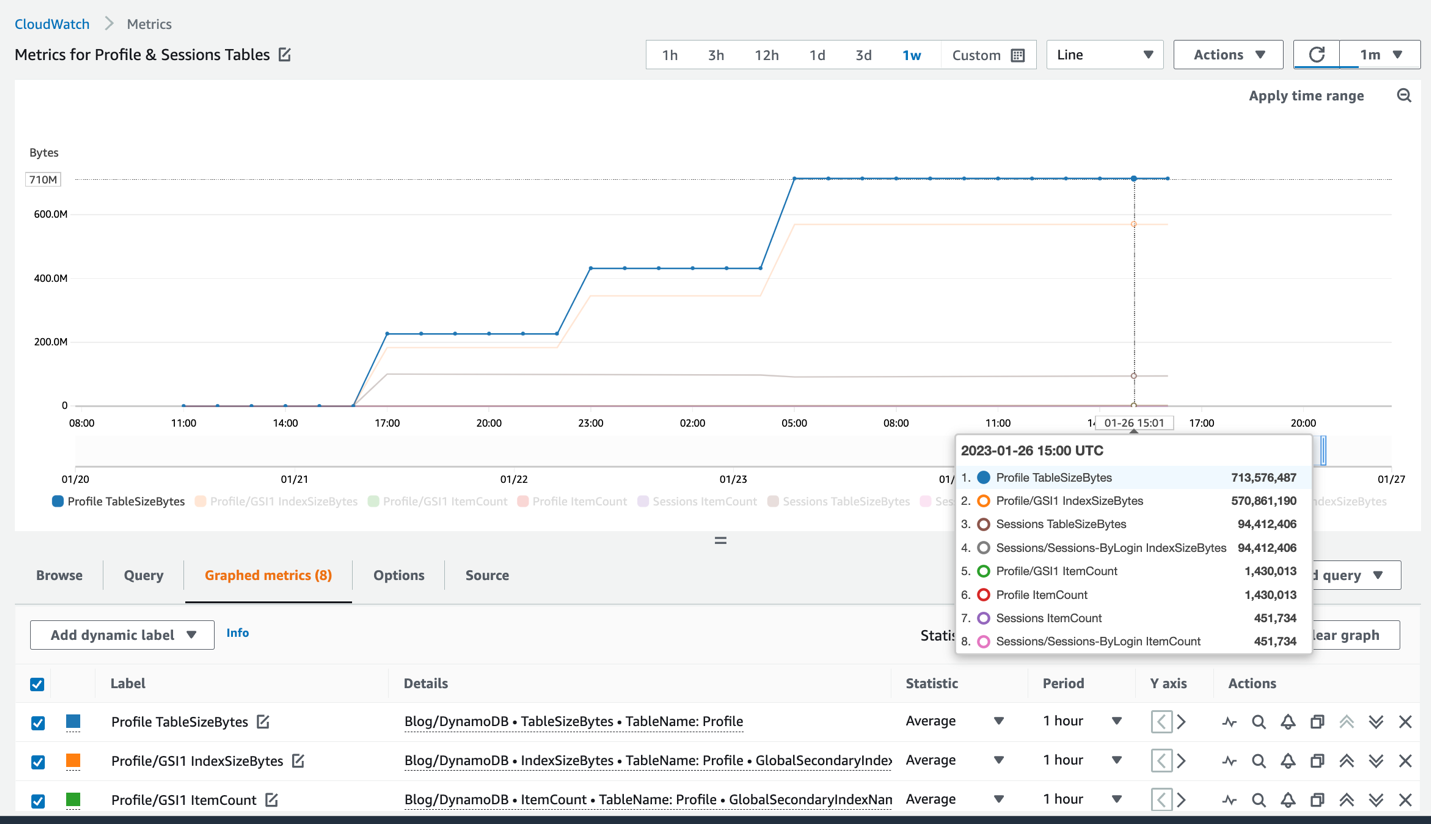
図1:CloudWatchで表示されるテーブルとインデックスのメトリクスビュー
ソリューションの概要
DynamoDB は全てのテーブルとセカンダリインデックスの合計サイズ(バイト単位)とアイテム数を自動的にトラックします。これらのメトリクスは、テーブルのメタデータの一部として利用可能であり、およそ6時間ごとに無料で更新されます。テーブル全体またはインデックススキャンから取得したライブなアイテム数を確認するよりも、これらの値を使用する方が望ましいです。なぜなら、スキャンには実行に時間がかかり、読み取り容量ユニットを消費するからです。
これらの値の過去のトレンドラインを知る事は、以下のようなさまざまな質問に答えるのに役立ちます。
- データサイズはどのくらいの速度で拡大していますか?
- 過去1年間で平均アイテムサイズは変化しましたか?(平均アイテムサイズはサイズとカウントから計算できます)
- 最近1日あたりにいくつのアイテムが追加されましたか?
- 次の第2四半期について、どの程度のストレージコストが予想されますか?
- 現在のストレージサイズの増加率で、このテーブルがDynamoDB Standard-Infrequent Access (DynamoDB 標準 – IA) テーブルクラスの候補になるのはいつですか?(標準 – IA は、ストレージコストがスループットコストの半分を超える場合に検討すべきものです)
この記事では、DynamoDB テーブルをループ処理し、各テーブルに対して DescribeTable 関数を呼び出し、ベーステーブルとインデックスのサイズとアイテム数を抽出して、メトリクスを CloudWatch に送信する Lambda 関数を提供します。EventBridge は Lambda 関数を定期的に呼び出します。このプロセスを以下の図2に示します。
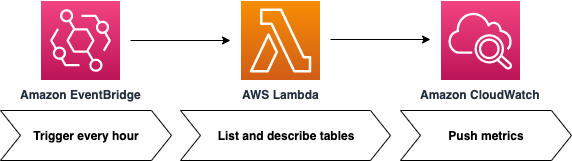
図2:EventBridge は、メトリクスを収集して CloudWatch に送信する Lambda 関数を呼び出す
Lambda コードの解説
以下は Lambda 関数コードの簡略版です。実際のコードには、より多くのエッジケース、最適化、およびエラー処理が含まれています。この記事の後半で、本番の自動デプロイメントについて説明します。
まず、関数はテーブルをリストする必要があります。テーブルリストのリクエストは、1ページあたり最大100件のアイテムを返す為、組み込みのページネーターを使用し、必要に応じて追加のリクエストを自動的かつ透過的に処理します。各テーブルに対して、DescribeTable 関数を使用し、テーブルのメタデータを構造化された形式で取得します。TableStatus が ACTIVE なテーブルの場合、そのメタデータを append_metrics() に渡します。
def handler(event, context):
metrics = []
paginator = dynamodb.get_paginator('list_tables')
for response in paginator.paginate():
for table_name in response['TableNames']:
try:
response = dynamodb.describe_table(
TableName=table_name
)
if response['Table']['TableStatus'] == 'ACTIVE':
append_metrics(metrics, table_name, response)
次に続く append_metrics() 関数の役割は、テーブルのメタデータから ItemCount と TableSizeBytes を抽出し、メタデータに含まれる他のセカンダリインデックスのメトリクスに対しても同様の処理を行います。値を抽出する際には、それらを CloudWatch に送信するのに適した形式でメトリクス配列に格納します。Dimensions 配列にはテーブル(またはインデックス)の名前が含まれます。MetricName は、それがアイテム数なのかサイズなのかを示します。Value はメタデータから抽出された数値です。Unit は ItemCount をカウントとして、TableSizeBytes と IndexSizeBytes をバイト単位で指定します。
def append_metrics(metrics, table_name, response):
metrics.extend([
{
'Dimensions': [
{
'Name': 'TableName',
'Value': table_name
},
],
'MetricName': 'ItemCount',
'Value': response['Table']['ItemCount'],
'Unit': 'Count'
},
{
'Dimensions': [
{
'Name': 'TableName',
'Value': table_name
}
],
'MetricName': 'TableSizeBytes',
'Value': response['Table']['TableSizeBytes'],
'Unit': 'Bytes'
}
])
if 'GlobalSecondaryIndexes' in response['Table']:
for gsi in response['Table']['GlobalSecondaryIndexes']:
metrics.extend([
{
'Dimensions': [
{
'Name': 'TableName',
'Value': table_name
},
{
'Name': 'GlobalSecondaryIndexName',
'Value': gsi['IndexName']
},
],
'MetricName': 'ItemCount',
'Value': gsi['ItemCount'],
'Unit': 'Count'
},
{
'Dimensions': [
{
'Name': 'TableName',
'Value': table_name
},
{
'Name': 'GlobalSecondaryIndexName',
'Value': gsi['IndexName'],
},
],
'MetricName': 'IndexSizeBytes',
'Value': gsi['IndexSizeBytes'],
'Unit': 'Bytes'
}
])この時点で、Lambda 関数は最新のメトリクスを含んだ CloudWatch に送信できる形式の配列を作成しました。関数は、アカウントに多数のテーブルやインデックスがある場合にパフォーマンスを向上させる為、メトリクスを1つずつプッシュする事を避けています。CloudWatch では、1回の呼び出しで最大1,000個のエントリ(または 1MB のデータ) まで許容します。次のコードでは、1,000個のブロック単位でエントリを送信します:
# Loop over metrics and send in batches of 1,000 (max allowed)
while len(metrics) > 0:
write_metrics_batch(metrics[:1000])
metrics = metrics[1000:]
各バッチを CloudWatch に送信するコードは次です:
def write_metrics_batch(batch):
cloudwatch.put_metric_data(
Namespace = namespace,
MetricData = batch
)
CloudWatch では、受信するメトリクスを事前に通知する必要はなく、通常メトリクスは送信後2分以内に CloudWatch に表示されます。新しいメトリクス名がメトリクス名リストに表示されるまでには最大15分かかる場合もあります。
名前空間は、CloudWatch 内の受信メトリクスのコンテキストを提供します。公式の DynamoDB メトリクスは全て AWS/DynamoDB 名前空間を使用します。この記事で提供しているコードは Blog/DynamoDB 名前空間をデフォルトとして設定しており、公式のメトリクスと混同しないようにしています。名前空間は、以下の図3に示すように Lambda 関数で Namespace 環境変数を設定する事で変更可能です。これは Lambda 関数によって読み込まれ、put 呼び出しに渡されます。
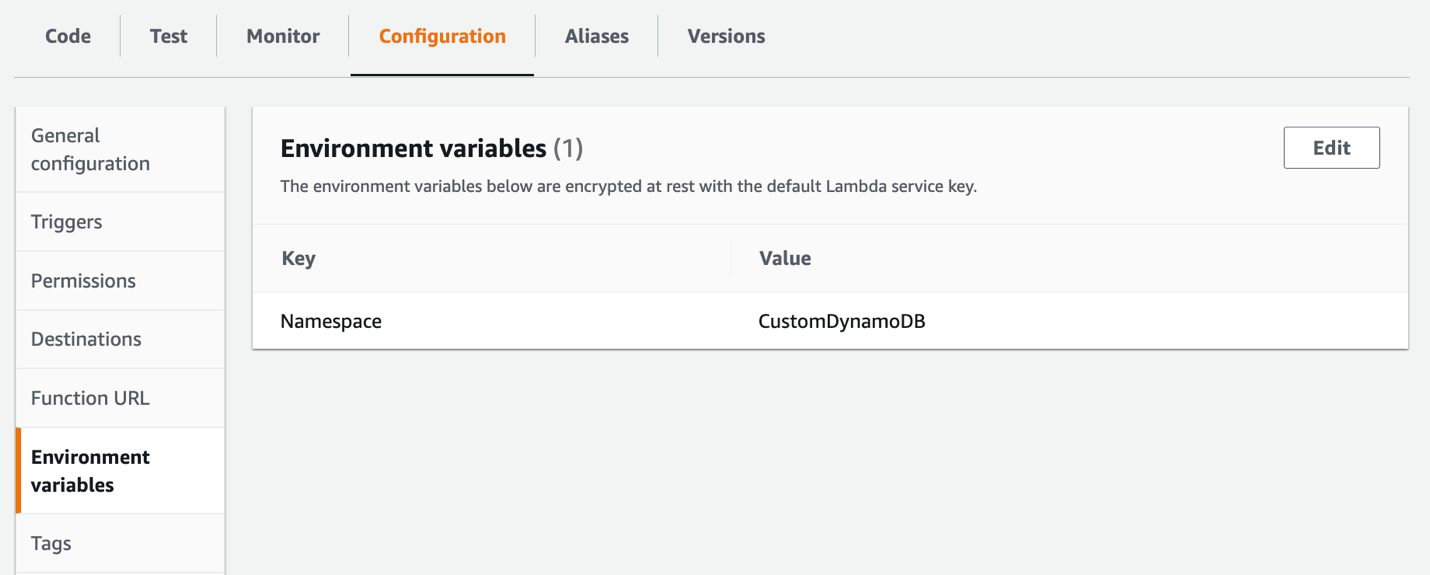
図3:Lambda の設定環境変数を使用してカスタムメトリクスの名前空間を指定する
この関数が呼び出されるたびにローカル AWS リージョンの全てのテーブルとインデックスの最新のサイズとカウントデータを CloudWatch に送信します。EventBridge を使用すると、関数を定期的に自動で呼び出す事ができます。1時間ごとに1回実行する事を推奨しています。この関数を1時間ごとに実行すると、テーブルのメタデータの更新(約6時間ごとにバックグラウンドで実行されますが、スケジュールは予測できません)が CloudWatch に送信されるまでの時間は最大で60分、平均で30分程度になります。
コストに関する考慮事項
次にこのソリューションに関連するコストについて考えてみましょう。DynamoDB コントロールプレーン API をポーリングするための追加コストはありません。Lambda のコストは実質的にゼロです:256 MB の Lambda 関数を毎秒 0.5 秒実行する場合、月に 720 リクエストと 90 GB-s が消費されます。Lambda の無料利用枠には 100万のリクエストと 400,000 GB-s が含まれています。
考慮すべきコストは CloudWatch です。カスタムメトリクスは月額0.30 USD (この記事を公開した時点での米国東部(バージニア北部)リージョンでの価格)です。5つのテーブルをトラックし、それぞれにセカンダリインデックスがある場合、10のエンティティがトラックされ、それぞれ2つのカスタムメトリクスが生成される為、合計で月額6 USD のコストが発生します。
テーブルとインデックスの追加と除外
上記のコストを考慮すると、CloudWatch でどのテーブルとインデックスをトラックするか慎重に選択する必要があるかもしれません。デフォルトでは、Lambda 関数は指定されたアカウントとリージョン内の全てのテーブルとインデックスのメトリクスを送信します。しかし、Lambda 環境変数を使用して、特定のテーブルやインデックスを追加・除外する事ができます。
Includes 環境変数を使用すると、トラックするテーブルとインデックスをカンマ区切りで指定できます。Includes 変数に指定されていないアイテムは追跡されません。変数値が存在しないか空の場合は、全てをトラックする事を意味します。インデックス名にワイルドカードの使用がサポートされており、tablename/* は指定したテーブルの全てのセカンダリインデックスを含める事を意味します。
Excludes 環境変数では、トラックしないテーブルとインデックスをカンマ区切りで指定できます。Includes の代わりに使用する事で、一部のアイテムを除外したい場合に便利です。Includes とExcludes の両方に一致するものは除外されます。こちらもワイルドカードがサポートされており、tablename/* は指定されたテーブルの全てのセカンダリインデックスのトラックを回避する事を意味し、*/* は全てのテーブルのセカンダリインデックスのトラックも除外する事を意味します。(ただし、ベーステーブルのトラックは除外されません)
これらの変数は、以下の図4に示すように Lambda の構成に Key と Value のペアで指定します。
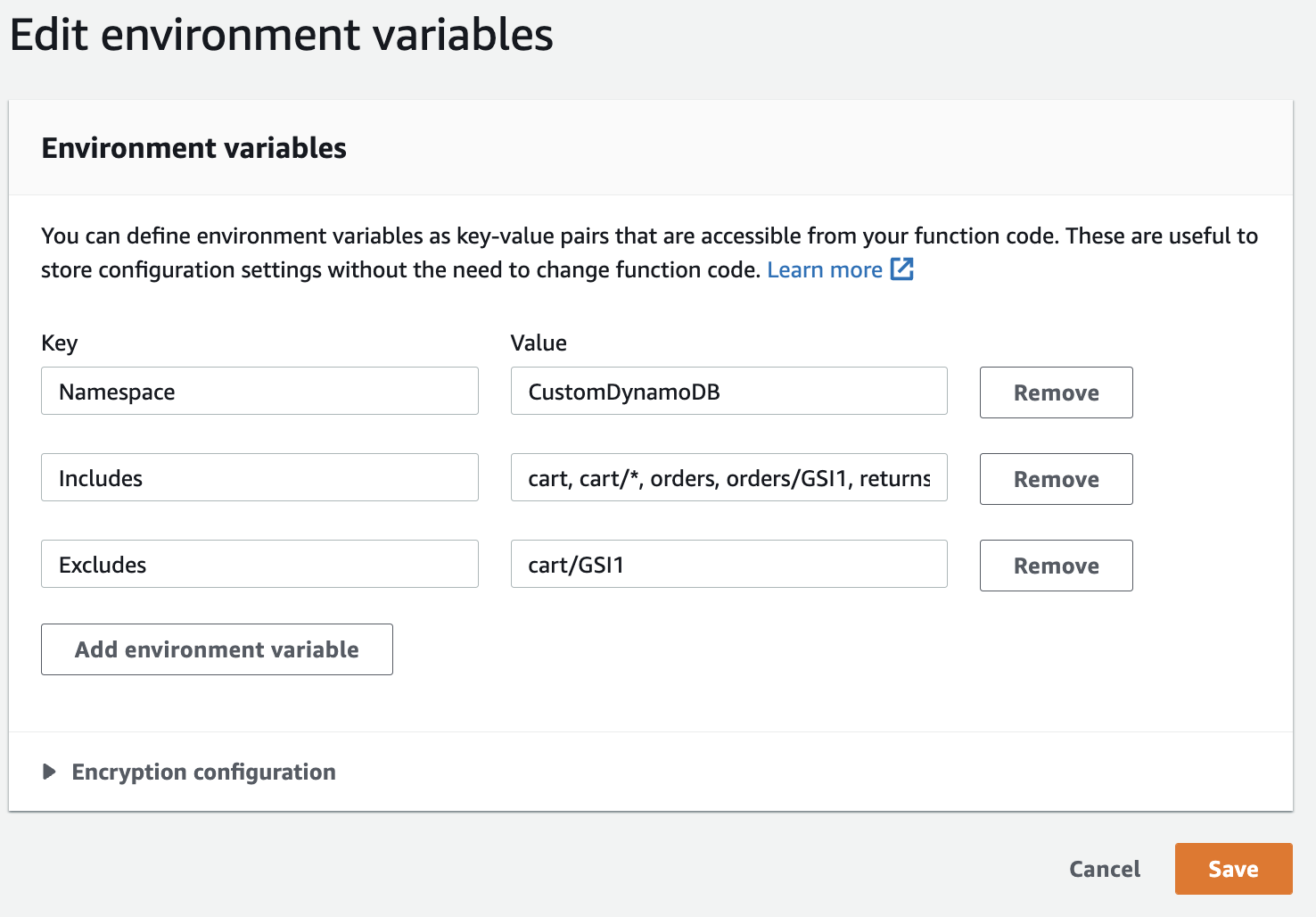
図4:Includes と Excludes の Lambda 環境変数を使用して、どのメトリクスをトラックするかを制御する
例:
cart、orders、returnsテーブルと、cartの全てのセカンダリインデックス、ordersのGSI1セカンダリインデックス、returnsのセカンダリインデックスをトラックIncludes: cart, cart/*, orders, orders/GSI1, returnsdevテーブルとdevテーブルの全てのセカンダリインデックスを除外Excludes: dev, dev/*cartテーブルとGSI1を除くcartテーブルの全てのセカンダリインデックスをトラックIncludes: cart, cart/* Excludes: cart/GSI1- テーブルのみトラックし、全てのセカンダリインデックスを除外
Excludes: */*
AWS CDK を使用してサーバーレスアプリケーションのデプロイを設定する
このセクションでは、AWS CDK がプログラムによってサーバーレスアプリケーションをインストールする方法について説明します。インストールされるコンポーネントは以下の通りです。
- Lambda 関数
- 1時間ごとに Lambda 関数を呼び出す EventBrigde ルール
- DynamoDB からの読み取り、及び CloudWatch への書き込み権限を Lambda 関数に与える AWS Identity and Access Management (IAM) ポリシー
これらのコンポーネントは AWS CDK を使用してデプロイできます。CDK は、(Python を含むさまざまな言語で)構成をスクリプト化できるプログラミングシステムです。実行すると、設定が AWS CloudFormation スタックに合成され、アカウントにデプロイされます。YAML ファイルや Lambda 関数コードの圧縮について考える必要はありません。CDK を使用する事で、更新されたコードのデプロイが簡略化されます。カスタマイズしたい場合は提供されている Lambda コードを編集し、1つのコマンドで編集内容をデプロイできます。
以下は、この記事のコードをデプロイするための Python コードです。AWS CDK では、CloudFormation YAML 設定ファイルの代わりに次のようなコードを使用します。
class DynamoDBCustomMetricsStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
# Defines an AWS Lambda resource
my_lambda = _lambda.Function(
self, 'Handler',
runtime=_lambda.Runtime.PYTHON_3_9,
memory_size=256, # Runs 2x faster than 128
architecture=_lambda.Architecture.ARM_64, # ARM tests as 8% faster
code=_lambda.Code.from_asset('lambda'),
handler='lambda_function.handler',
environment={
},
# Execution is fast but describing 2,500 tables can take a while
# If you have many tables, limit the scope via Includes and Excludes env variables!
timeout=Duration.seconds(60), # extended the duration from 3 seconds to a minute
)
# Add CloudWatch and DynamoDB permissions to Lambda
my_lambda.add_to_role_policy(iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
'dynamodb:DescribeTable',
'dynamodb:ListTables',
'cloudwatch:PutMetricData',
],
resources=[
'*',
],
))
# Add eventbridge rule which runs the Lambda function each hour
lambda_target = targets.LambdaFunction(handler = my_lambda)
event_rule = Rule(self, "ScheduleRule",
schedule=Schedule.rate(Duration.seconds(3600)),
targets=[lambda_target]
)
init 関数は最初に Lambda 関数を定義します。Python 3.9、256 MB のメモリ、ARM プロセッサ、および 60秒のタイムアウトを使用するように設定されています。Lambda コードは実行されるコードと同じ場所にある lambda フォルダから取得してパッケージ化するように指示されています。
次に、この関数の IAM ポリシーを定義します。Lambda 関数には、DynamoDB テーブルのリストと説明、及びメトリクスデータを CloudWatch に送信するための権限が必要です。
最後に EventBridge ルールを作成し、関数を1時間ごとに呼び出すように設定します。これにより、関数が定期的に実行されるようになります。
AWS CDK デプロイコマンドを実行する
このセクションでは、このサーバーレスアプリケーションを自分のAWS アカウントにアクティブにデプロイする方法について説明します。
AWS CDK を使用して、任意のコンピューティングシェル環境でデプロイできます:自分のラップトップ、Amazon Elastic Compute Cloud (Amazon EC2) インスタンス、または(ここで使用する)多くのAWS リージョンで簡単に利用できるブラウザベースのシェル環境である AWS CloudShell、など
デプロイコマンドを実行するための手順は以下の通りです:
- CloudShell をサポートしている任意のリージョンを使用して CloudShell コンソールを開きます。目的のリージョンが CloudShell をサポートしていない場合、後述のように別のリージョンからクロスリージョンでインストールできます。
図5:CloudShell サービスによって提供されるコマンドラインアクセス
- 次のコマンドを実行し、zip ファイルを CloudShell にダウンロードします。
wget https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/DBBLOG-2540/DynamoDBCustomMetrics.zipこの.zip ファイルは GitHub にホストされているソースを元にビルドされました。
図6:wget を使用して、.zip ファイルを CloudShell 環境に取得
- ファイルを解凍し、
cdで新しいフォルダに移動します。
図7:ファイルを解凍し、宛先フォルダに移動
pip3 install -r requirements.txtを実行して Python CDK 環境を準備します

図8:必要な Python パッケージのインストール
- CDK を
cdk bootstrapでブートストラップします。これは、CDK がそのリージョンで必要なもの(デプロイメントをサポートする専用の S3 バケットなど)を作成するためにリージョンごとに1回実行する必要があります。

図9:CDK のブートストラップ
cdk deployを使用してセットアップをデプロイします
図10:実際のデプロイに向けて準備
「y」を入力すると、選択したリージョンに完全にデプロイされます。今後lambdaフォルダ内のコードを編集したい場合、2回目のcdk deployを行う事で編集されたコードが適用されます。
注意:別のリージョンにデプロイする場合、そのリージョンでこのプロセスを繰り返すか、ファイル内のコメントに従ってapp.pyコードを編集し、別のアカウントまたはリージョンを指定して一括デプロイする事もできます。
クリーンアップ
インストールしたものを全て削除するには、cdk destory を実行します。CDK は CloudFormation スタックを使用している事がわかります。記録された CloudWatch のメトリクスは残ります。

図11:インストールされたものをクリーンアップ
まとめ
DynamoDB のテーブルとインデックスは、自動的にアイテム数と合計サイズに関する統計情報を保持し、約6時間ごとに自動更新されますが、過去の値を自動追跡する事はできません。EventBridge から定期的に呼び出される Lambda 関数を使用し、メトリクスを CloudWatch に送信する事で、これらの統計情報の過去の記録をトラック、グラフ化、予測、アラートに利用できます。AWS CDK を使用してサーバーレスアプリケーションをデプロイできます。リージョンごとに別のインストールが必要です。Lambda の環境変数を使用して、どのテーブルとインデックスをトラックするか、どの名前空間にメトリクスを配置するかを制御できます。
もしコメントや質問があれば、コメントセクションにコメントして下さい。DynamoDB に関する投稿や、Jason Hunter が執筆したその他の投稿については AWS Database Blog をご覧下さい。
著者について
 |
Jason Hunterはカリフォルニア州に拠点を置く、DynamoDB を専門とするシニアソリューションアーキテクトです。彼は2003年以来、NoSQL データベースに取り組んでいます。Java、オープンソース、及び XML への貢献で知られています。 |
 |
Vivek Natarajanはパデュー大学のコンピューターサイエンス専攻であり、AWS でソリューションアーキテクトのインターンをしています。 |
本記事は 2023/04/04に投稿された How to use Amazon CloudWatch to monitor Amazon DynamoDB table size and item count metrics を翻訳した記事です。翻訳はソリューションアーキテクトのKenta Nagasueが担当しました。