Amazon Web Services ブログ
AWS Glue を使用して Salesforce.com データを抽出し、Amazon Athena で分析する
Salesforce は、広く使用されている人気の高い顧客関係管理 (CRM) プラットフォームです。連絡先情報、取引先、見込み客、販売機会など、見込み客やお客様の情報を 1 か所にまとめて管理できます。Salesforce に保存されている見込み客情報を、データレイク内の他の構造化データおよび非構造化データと組み合わせることで、多くの有用な情報を引き出すことができます。
この記事では、AWS Glue を使用して Salesforce.com アカウントオブジェクトからデータを抽出し、それを Amazon S3 に保存する方法を説明します。次に、Amazon Athena を使用して、Salesforce.com のアカウントオブジェクトデータと別の注文管理システムの注文データを結合してレポートを生成します。
データを準備する
無料の Salesforce.com アカウントにサインアップすると、多数の Salesforce.com オブジェクトが入った少数のサンプルレコードが付いてきます。AWS Glue コードの SOQL クエリを変更することで、組織の開発用 Salesforce.com アカウントを使用して、同時に複数のオブジェクトからデータを取得できます。これらのオブジェクトからデータを抽出する方法を示すため、Account オブジェクトのみを使用してクエリを単純なものにします。
Amazon Athena を使用して Salesforce.com データを別のシステムのデータと結合する方法を示すために、注文管理システムから出される注文を示すサンプルデータファイルを作成します。
AWS Glue ジョブを設定する
Apache Spark と Salesforce.com を接続するため、オープンソースの springml ライブラリを使用します。このライブラリには、Apache Spark フレームワークを使用して Salesforce.com オブジェクトの読み取り、書き込み、および更新を可能にする便利な機能が多数付属しています。
springml GitHub リポジトリから JAR ファイルをコンパイルするか、Maven リポジトリから依存関係を付けてダウンロードすることができます。この JAR ファイルを S3 バケットにアップロードして、それぞれのフルパスを書き留めます。
AWS マネジメントコンソールで、サービスを実行するリージョンの AWS Glue を選択します。[ジョブ]、[ジョブの追加] を選択します。必要な詳細を入力してウィザードに従ってください。
セキュリティ設定、スクリプトライブラリ、およびジョブパラメータ (オプション) セクションの下で、Dependent JAR パスに、前述の 4 つの JAR ファイルのパスをコンマで区切ってリストします。
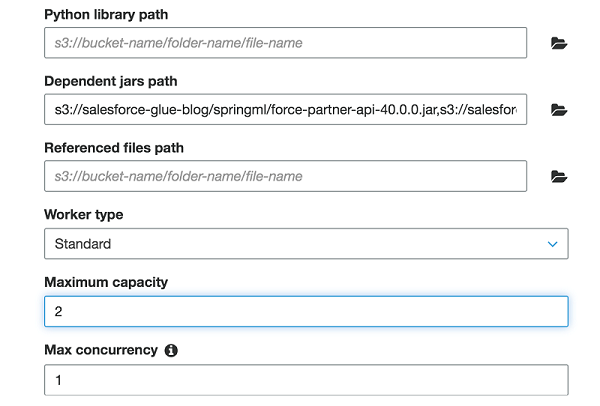
このジョブでは、最大容量 を「2」に割り当てました。 このフィールドは、このジョブの実行時にシステムが割り当てることができる AWS Glue データ処理ユニット (DPU) の数を定義します。DPU は、4 つの vCPU のコンピューティング容量と 16 GB のメモリで構成される処理能力の相対的な尺度です。Apache Spark ETL ジョブを指定すると、2〜100 DPU を割り当てることができます。デフォルトは 10 DPU です。
AWS Glue ジョブを実行して Salesforce.com オブジェクトからデータを抽出する
次の Scala コードは、Salesforce.com の Account オブジェクトからいくつかのフィールドを抽出し、それらを Apache Parquet ファイル形式のテーブルとして S3 に書き込みます。
このコードは、次のいくつかの主要コンポーネントに依存しています。
このコード例は、Salesforce.com との接続を確立し、Account オブジェクトに対して SOQL 互換クエリを送信し、返されたレコードを Spark DataFrame にロードします。パスワードとプロファイルのセキュリティトークンの組み合わせとして、username を Salesforce.com のユーザー名とパスワードに置き換えることを忘れないでください。
ハードコードする代わりに AWS Secrets Manager を使用してパスワードを保存および取得することがベストプラクティスです。簡単にするために、この例ではハードコードしたままにしました。
このクエリは単純で、少数のレコードのみを返すことに注意してください。大量のデータの場合は、クエリによって返される結果を制限したり、一括クエリやチャンクのような他の手法を使用することができます。Salesforce.com がサポートする機能の詳細については、springml ページを確認してください。
このコードは S3 バケットへのすべての書き込みを行います。この例では、Industry セグメントでデータを集計します。そのため、データを Industry フィールドで分割する必要があります。
また、コードは Parquet 形式で書きます。Athena は、クエリごとにスキャンされたデータ量で課金します。データを分割したり、圧縮したり、あるいは Parquet のような列形式に変換したりすると、コストを削減してパフォーマンスを向上させることができます。
AWS Glue でこのコードを実行した後は、シンクが指す S3 バケットに移動して、次のような構造を見つけることができます。
Athena でデータをクエリする
コードが正しいパーティションとフォーマットで Salesforce.com データを S3 バケットにドロップした後、AWS Glue はデータセットをクロールできます。AWS Glue Data Catalog に適切なスキーマを作成します。AWS Glue がテーブルを作成するのを待ちます。その後、Athena はそのテーブルにクエリを実行し、カタログ内の他のテーブルと結合できます。
まず、AWS Glue クローラを使用して、以前 S3 バケットに保存した Salesforce.com Account データを見つけます。クローラの使用方法の詳細については、「AWS Glue Data Catalog の生成」を参照してください。
この例では、Salesforce.com Account データを保存した S3 出力プレフィックスをクローラに向けて実行します。クローラは、最後に停止する前に新しいカタログテーブルを作成します。
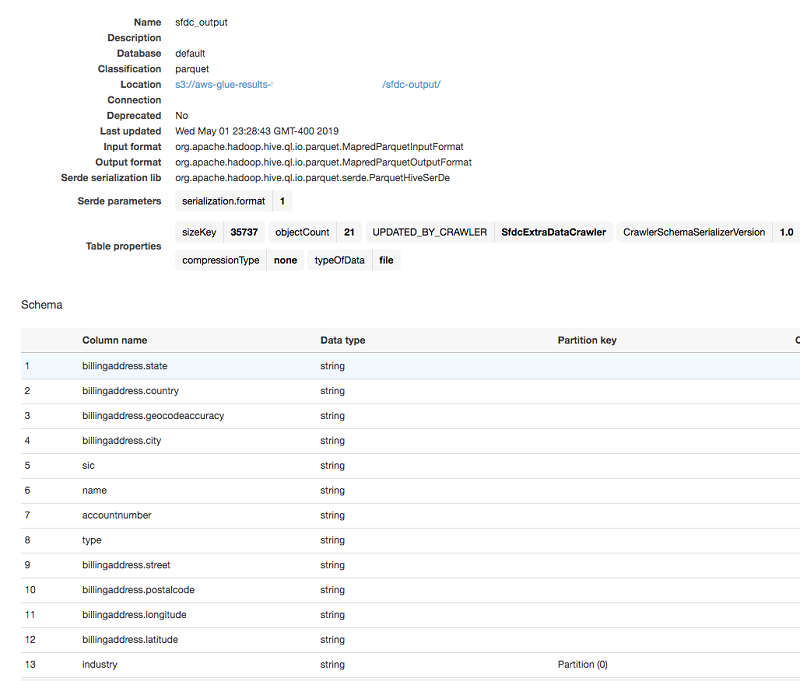
AWS Glue Data Catalog テーブルは、使用されているすべての列名、タイプ、パーティション列を自動的に取得し、すべてを Parquet ファイル形式で S3 バケットに保存します。これで Athena を使ってこのテーブルをクエリすることができます。そのテーブルに対する単純な SELECT クエリは、S3 バケットからのデータのスキャン結果を示しています。

これで、Athena は Salesforce.com データをクエリできるようになりました。この例では、S3 のこのサンプル 注文管理システムからのサンプル注文とこのデータを結合します。AWS Glue クローラがサンプル注文データのカタログ化を完了したら、Athena はそれをクエリできます。
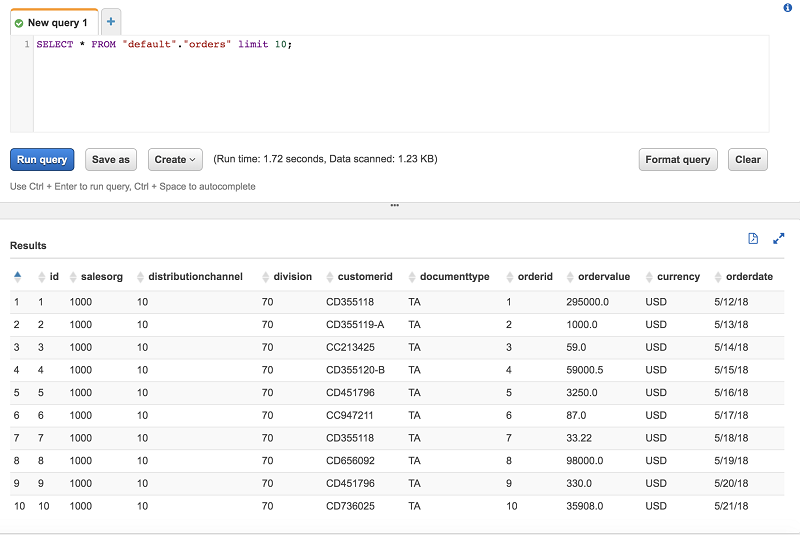
最後に、Athena を使用して集計クエリで両方のテーブルを結合します。
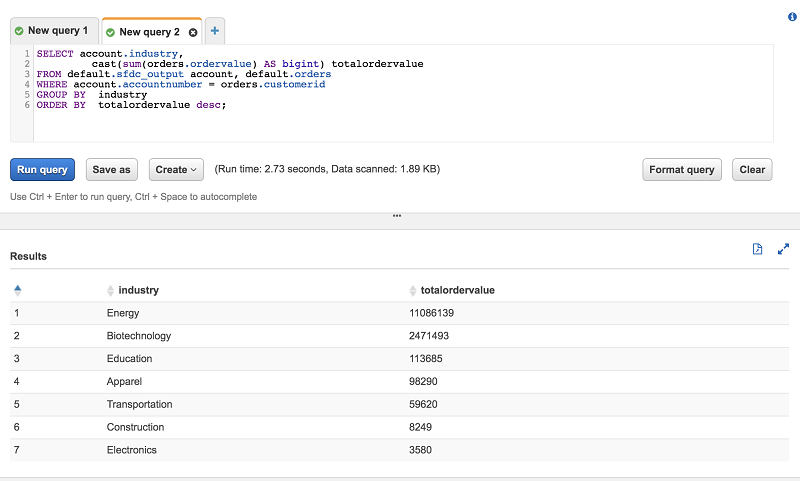
結論
この記事では、AWS Glue と Apache Spark を使用して Salesforce.com オブジェクトデータを抽出して S3 に保存する簡単な例を示しました。その後、S3 データを AWS Glue Data Catalog にカタログ化し、Athena がそれをクエリできるようにしました。このメカニズムが整っていれば、Salesforce データを AWS ベースのデータレイクに簡単に組み込むことができます。
コメントやフィードバックがある方は、下の欄に残してください。
著者について

Behram Irani は、アマゾン ウェブ サービスのデータアーキテクトです。