Amazon Web Services ブログ
Amazon EMR での Apache MXNet および Apache Spark を使用した分散推論
このブログでは、Amazon EMR で Apache MXNet (incubating) および Apache Spark を使用して大規模なデータセットで分散オフライン推論を実行する方法を説明します。オフライン推論がどのように役立つのか、課題となる理由、および、Amazon EMR で MXNet と Spark を活用して課題を解決する方法を説明します。
大規模データセットでの分散推論 – ニーズと課題
ディープラーニングモデルのトレーニングの後、新しいデータ上で推論を実行して活用します。推論は、不正検出など、その場でのフィードバックが必要なタスクでリアルタイムに実行できます。これは通常オンライン推論と呼ばれています。または、事前計算が役立つ場合は、推論をオフラインで実行できます。オフライン推論のよくあるユースケースは、ユーザーの製品スコアのソートやランク付けを必要とする推奨システムなど、レイテンシー要件が低いサービスです。これらのケースでは、推奨はオフライン推論を使用して事前計算されます。結果は低レイテンシーストレージに保存され、必要に応じて、推奨がストレージから引き出されます。オフライン推論の別のユースケースは、最新モデルから生成された予測による履歴データのバックフィリングです。仮の例として、新聞でこの設定を使用して、人物識別モデルから予測された人物の名前でアーカイブされた写真をバックフィルできます。また、分散推論を使用して、歴史的なデータで新しいモデルをテストし、本番稼働用にデプロイする前により良い結果を生み出すかどうかを確認できます。
通常、分散推論は数百万以上のレコードがあるような大規模なデータセットで実行されます。妥当な時間内にそのような巨大なデータセットを処理するには、ディープラーニングの機能をセットアップされたマシンクラスターが必要です。分散クラスターでは、データ分割、バッチ処理、タスクの並列化を使用した高いスループット処理ができます。ただし、ディープラーニングデータ処理クラスターをセットアップするには課題もあります。
- クラスターのセットアップと管理: ノードのセットアップとモニタリング、高い可用性の維持、ソフトウェアパッケージのデプロイと設定など。
- リソースとジョブの管理: ジョブのスケジューリングと追跡、データ分割とジョブの障害への対処。
- ディープラーニングのセットアップ: ディープラーニングタスクのデプロイ、設定、および実行。
次に、このブログの投稿では、Amazon EMR で MXNet および Spark を使用してこれらの課題に対処する方法を示します。
分散推論のために MXNet および Spark を使用する
Amazon EMR により、Spark および MXNet でスケーラブルなクラスターを起動するのが、簡単で費用効率に優れたものとなっています。Amazon EMR は秒単位で課金され、Amazon EC2 スポットインスタンスを使用してワークロードあたりのコストを下げることができます。
Amazon EMR と Spark の組み合わせにより、クラスターのタスクと分散ジョブの管理が簡素化されます。Spark は、さまざまなデータ処理アプリケーションを利用可能にするクラスターコンピューティングのフレームワークです。また、Spark は処理を並列化するため、クラスター内のデータを効果的に分割します。Spark は Apache Hadoop エコシステムおよびその他のいくつかのビッグデータソリューションと緊密に統合されています。
MXNet は、CPU および GPU でのパフォーマンスに最適化された高速でスケーラブルなディープラーニングフレームワークです。
Amazon EMR で Spark および MXNet を使用して、大規模なデータセットで分散推論をセットアップして実行する手順をチュートリアルで示します。MXNet model zoo で入手できる事前トレーニング済みの ResNet-18 イメージ認識モデルを使用します。60,000 のカラーイメージを含み一般公開されている CIFAR-10 データセットに対して推論を実行します。この例では、CPU で推論を実行しますが、GPU での使用にも簡単に活用できます。
セットアップと実行に必要なステップは以下のリストに示されており、次のセクションで詳細を説明します。
- Amazon EMR で MXNet と Spark をセットアップします。
- Spark アプリケーションを初期化します。
- クラスターにデータをロードし分割します。
- データを取得し Spark エグゼキューターにロードします。
- エグゼキューター で MXNet を使用して推論します。
- 予測を収集します。
- spark-submit を使用して推論アプリケーションを実行します。
- Spark アプリケーションをモニタリングします。
Amazon EMR で MXNet および Spark クラスターをセットアップする
Amazon EMR を使用して Spark および MXNet でクラスターを作成し、EMR 5.10.0 を使用してそれをアプリケーションとしてインストールできます。AWS CLI を使用して c4.8xlarge タイプのコアインスタンス 4 つと、m3.xlarge タイプのマスター 1 つのクラスターを作成しますが、Amazon EMR コンソールを使用してクラスターを作成することもできます。
クラスターを作成するコマンドは以下のとおりです。ここでは、コマンドの作成に必要な認証情報を持っていることを前提としています。
以下の引数を置き換えます。
- <YOUR-KEYPAIR> – マスターへの SSH 接続のための Amazon EC2 キーペア。
- <YOUR-SUBNET-ID> – クラスターを起動するサブネット。c4.8xlarge のような高い計算能力のインスタンスを作成するにはこの引数を渡す必要があります。
- <AWS-REGION> – クラスターを起動する AWS リージョン
- <YOUR-S3-BUCKET-FOR-EMR-LOGS> – EMR ログを保存する S3 バケット。
--bootstrap-actions は、Git、Pillow および Boto ライブラリのインストールに使用します。
Amazon EMR クラスターのセットアップに必要な IAM ロールの作成と使用の詳細については、AWS ドキュメントを参照してください。
次に説明するコードスニペットは、mxnet-spark フォルダの下にある deeplearning-emr GitHub リポジトリで入手できます。MXNet および Spark を使用して推論を実行するための完全なコードを含んでいます。Spark アプリケーションを送信するために spark-submit を使用する方法についても、続くセクションのいずれかで説明します。 mxnet-spark フォルダ (GitHub repo 内) には 3 つのファイルが含まれています。
- infer_main.py にはドライバーで実行するコードが含まれています。
- utils.py にはいくつかのヘルパーメソッドが含まれていて、
- mxinfer.py には、ワーカーノードでモデルファイルをダウンロードするためのコード、numpy へのロードバイト、イメージのバッチでの実行予測が含まれています。
初期化
PySpark、Spark の Python インターフェイスを使用してアプリケーションを作成します。Spark アプリケーションは、ユーザーの主な機能を実行する単一のドライバープログラムと、さまざまなタスクを並行して実行する 1 つ以上のエグゼキュータープロセスから構成されています。
Spark アプリケーションを実行するために、ドライバーはワークを複数のジョブに分割します。それぞれのジョブはさらにステージに分割され、各ステージは並行して実行する独立した一連のタスクで構成されています。Spark で、タスクはワークの最小単位で、同じコードをそれぞれ異なるデータパーティションで実行します。これは、大規模な分散データセットの論理的なチャンクです。
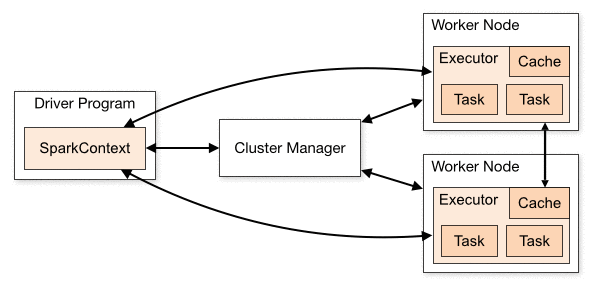
イメージクレジット: Apache Spark Docs
Spark では、分散データセットで動作する抽象化である Resilient Distributed Dataset (RDD) が利用できます。RDD はクラスター内で分割されたオブジェクトのイミュータブルな分散コレクションで、並行して動作できます。RDD は、コレクションまたは外部データセットのいずれかを並列処理することにより作成できます。
おおまかに言うと、分散推論アプリケーションのパイプラインは次のようになります。

デフォルトでは、Spark はエグゼキューターでコアあたり 1 つのタスクを作成します。MXNet はすべての CPU コアを効率的に使用するためのビルトインの並列処理であるため、アプリケーションを設定してエグゼキューターあたり 1 つのタスクのみを作成し、MXNet がインスタンスのすべてのコアを使用するようにします。以下のコードでは、spark.executor.cores の設定キーを 1 に設定し、SparkContext を作成する際に conf オブジェクトを渡します。また、アプリケーションを送信するとき、クラスターの使用可能なワーカーの数に合わせてエグゼキューターの数を設定することが分かります。これにより、ノードあたり 1 つのエグゼキューターになり、エグゼキューターの動的割り当てを無効にします。
クラスターにデータをロードし分割する
CIFAR-10 データはすでに Amazon S3 バケットにコピーしてあります。 mxnet-spark-demo. S3 に保存してあるデータはすべてのノードでアクセスできるので、ドライバーとエグゼキューターの間でデータを移動する必要はありません。ドライバーの S3 キーのみを取得し、boto ライブラリを使用してキーの RDD を作成します。これは、AWS のサービスにアクセスするための Python インターフェイスです。この RDD は分割されてクラスター内のエグゼキューターに配信されるので、エグゼキューターで直接イメージのミニバッチを取得して処理します。
ヘルパーメソッドを使用します。 fetch_s3_keys utils.py から Amazon S3 バケットからのすべてのキーを取得します。また、このメソッドは、該当するプレフィックスで始まるキーをリスト表示するプレフィックスをとります。引数は、メインアプリケーションを送信するときに渡されます。
バッチサイズは以下により決定されます。 args['batch'] は、各エグゼキューターで同時に取得し、処理し、推論を実行できるイメージの数です。これは、各タスクで使用可能なメモリの量により制限されます。 args['access_key'] および args['secret_key'] は、インスタンスロールが正しいアクセス権限で設定されている場合の、別のアカウントにある S3 バケットにアクセスするためのオプションの引数です。スクリプトは、起動時にクラスターに割り当てられた IAM ロールを自動的に使用します。
キーの RDD をパーティションに分割し、各パーティションがイメージキーのミニバッチを含むようにします。キーがバッチサイズのパーティションに完全に分割できない場合は、最後のパーティションを最初のキーのセットを再利用して満たします。固定されたバッチサイズにバインディング (以下のコードを参照) するため、これが必要になります。
データを取得し Spark エグゼキューターにロードする
Apache Spark では、RDD で 2 つのタイプのオペレーションを実行できます。 変換 は 1 つの RDD のデータで動作し、新しい RDD を作成します。また、アクション は RDD の結果を計算します。
RDD での変換は、遅延して評価されます。つまり、Spark はアクションがなければ変換を実行しません。代わりに、Spark は、実行計画を形成するアクションへとつながる Directed Acyclic Graph を作成して、異なる RDD 間の依存関係を記録し続けます。これは、オンデマンドでの RDD のコンピューティング、および、RDD のパーティションが失われた場合の復旧に役立ちます。
Spark の mapPartitions を使用します。これは、パーティションのレコードへのイテレーターを提供します。変換メソッドは RDD のパーティション (ブロック) ごとに別々に実行されます。使用するのは download_objects メソッドで、utils.py から RDD パーティションの変換として、Amazon S3 からメモリへすべてのパーティションのイメージをダウンロードします。
メモリ内の各イメージを numpy 配列オブジェクトに変換するため、Python Pillow – Python Imaging Library を使用して、もう 1 つの変換を実行します。 Pillow を使用してメモリ内のイメージ (png 形式) をデコードし、numpy オブジェクトに変換します。これは、mxinfer.py の read_images and load_images で行われます。
注意: このアプリケーションでは、モジュール (numpy、mxnet、pillow など) を、ファイルの一番上に一度にインポートせずに、mapPartitions 関数の中にインポートしています。これは、PySpark では、モジュールレベルでインポートされるすべてのモジュールと任意の依存ライブラリをシリアル化しようとし、ほとんどの場合、モジュールおよびモジュールの他の関連するバイナリの pickle 化に失敗するためです。そうしないと、Spark は、ルーチンやライブラリがノード上で利用可能であると考えます。ルーチンはコードファイルとして送付されます (アプリケーションを以下を使用して送信する場合)。 spark-submit script. ライブラリはすでにすべてのノードにインストールされています。もう 1 つ確認すべき点は、関数でオブジェクトのメンバーを使用すると、Spark はオブジェクト全体をシリアル化してしまうことがあります。
エグゼキューター で MXNet を使用して推論する
前述のとおり、ノードあたり 1 つのエグゼキューターを実行し、このアプリケーションではエグゼキューターあたり 1 つのタスクを実行します。
推論を実行する前に、モデルファイルをロードする必要があります。 MXModel クラス (mxinfer.py 内) では、MXNet Model Zoo からモデルファイルをダウンロードし、MXNet モジュールを作成して最初の使用時に MXModel クラスに保存します。すべての予測でモデルをインスタンス化やロードする必要がないように、シングルトンパターンを実装しています。
download_model_files メソッド (MXModel シングルトンクラス) では、ResNet-18 モデルファイルをダウンロードします。このモデルは、ニューラルネットワークグラフを説明する .json 拡張子の付いたシンボルファイル、および、モデルパラメーターを含む .params 拡張子の付いたバイナリファイルで構成されています。分類モデルには、クラスと対応するラベルを含む synsets.txt があります。
モデルファイルをダウンロードした後、それらをロードして MXNet モジュールオブジェクト ( init_module ルーチン内) をインスタンス化して、以下のステップを実行します。
- シンボルファイルをロードして入力シンボルを作成し、パラメーターを MXNet NDArray にロードし解析する arg_params および aux_params.
- 新しい MXNet モジュールを作成しシンボルを割り当てます。
- シンボルをバインドしてデータを入力します。
- モデルパラメーターを設定します。
予測メソッドの最初の呼び出しで 1 回 MXModel オブジェクトをダウンロードしてインスタンス化します。また、予測変換メソッドは 4 次元配列をとり、バッチ ( args['batch'] のサイズ) のカラーイメージ (他の 3 次元の RGB) を持ち、MXNet モジュールフォワードメソッドを呼び出してそのイメージのバッチの予測を生成します。
注意: 前のノートで説明した理由により、mxnet および numpy のモジュールをこのメソッド内にインポートします。
推論 Spark アプリケーションを実行する
まず、MXNet と Spark を使用して推論を実行するためのコードを含む deeplearning-emr GitHub リポジトリをクローンします。
使用するのは spark-submit スクリプトを使用して Spark アプリケーションを実行します。
注意: <YOUR_S3_BUCKET> を、結果を格納する Amazon S3 バケットに置き換えてください。パスアクセス/シークレットキーのいずれかを持っているか、インスタンス IAM ロールでアクセス権限を持っている必要があります。
spark-submit の引数は次のとおりです。
- --py-files: ワーカーに送られる必要があるコードファイルのカンマ区切りリスト (スペースなし)。
- --deploy-mode: クラスターまたはクライアント。アプリケーションをクラスターモードで実行すると、Spark はドライバとエグゼキューターを実行するワーカーの 1 人を選択します。クラスターモードでの実行は、クラスターが大規模で、EMR クラスターのマスターノードが Hadoop、Spark 向けのウェブサーバーを実行しているときに便利です。また、クライアントをデプロイモードでアプリケーションを実行することもできます。
- --master: yarn. EMR は YARN をリソースマネージャとして構成します。
- --conf spark.executor.memory 各エグゼキューターが使用できるメモリの量。
- --conf spark.executorEnv.LD_LIBRARY_PATH および --driver-library-path: を に設定します。 LD_LIBRARY_PATH
- --num-executors: EMR クラスター内のコアノードとタスクノードの総数。
- infer_main.py: Spark アプリケーションを起動するメインプログラムで、S3 バケット、S3 キープレフィックス、バッチサイズなどの引数をとります。
- --batch: 各エグゼキューターで同時に処理できるイメージの数。これは、各ワーカーノードで使用可能なメモリと CPU によって制限されます。
予測の収集
最後に、Spark の収集アクションを使用して各パーティションに対して生成された予測を収集し、それらの予測を Amazon S3 に書き込みます。結果が書き込まれる S3 の場所 (args['output_s3_bucket'], args['output_s3_key']) は、引数として infer_main.py に渡すことができます。
Spark アプリケーションのモニタリング
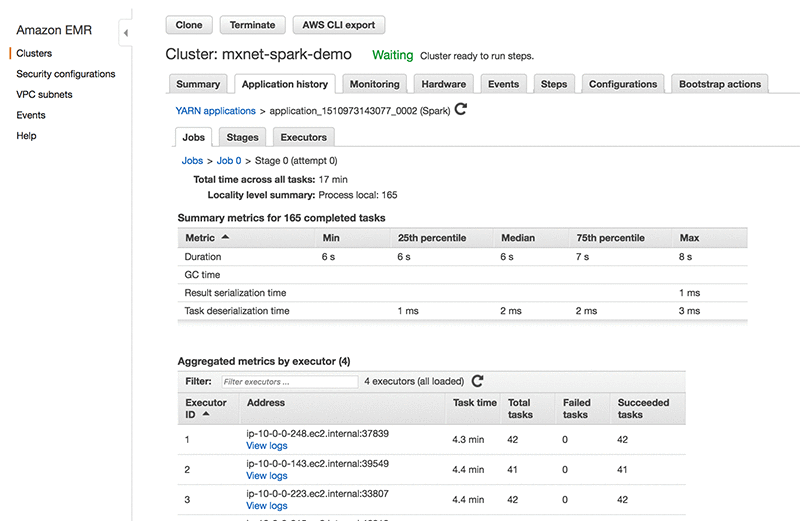
Spark アプリケーション履歴と YARN アプリケーションステータスは、Amazon EMR コンソールで直接表示できます。アプリケーションの履歴は、実行時にほぼリアルタイムで更新され、クラスターを終了した後であってもアプリケーションが完了してから最大 7 日間履歴を利用できます。また、メモリ使用量、S3 読み取り、HDFS 使用率などの高度なメトリクスを 1 か所で提供します。これにより、YARN UI を使用する場合と異なり、SSH 転送の必要性もなくなります。EMR コンソールの Spark アプリケーション履歴で機能とその使用方法を確認できます。
次の EMR コンソールでのアプリケーション履歴のスクリーンショットは、アプリケーションタスク、実行時間などを示しています。
Amazon EMR 上で動作する Spark アプリケーションは、ドライバホスト上のポート 8088 の Yarn ResourceManager Web UI を使用して監視することもできます。Amazon EMR クラスターで利用可能なさまざまな Web UI とそのアクセス方法を次に示します。EMR での YARN Web UI
次のスクリーンショットは、ウェブモニタリングツールです。実行のタイムライン、ジョブ継続時間、およびタスクの成功と失敗を確認できます。

Amazon EMR のもう 1 つの大きな特徴は、Amazon CloudWatch との統合です。これは、クラスターリソースとアプリケーションのモニタリングを可能にします。以下のスクリーンショットでは、クラスターノード間の CPU 使用率が 25% 以下に抑えられています。

まとめ
要約すると、MXNet を使用して Amazon S3 に保存された 10000 のイメージに分散推論を実行し、5 (4.4) 分以内に処理を完了する 4 ノードの Spark クラスターを設定する方法について説明しました。
詳細
- Amazon Elastic MapReduce
- Apache Spark – 高速クラスターコンピューティング
- Apache MXNet – 柔軟かつ効率的なディープラーニング
- MXNet シンボル – ニューラルネットワークのグラフと自動微分
- MXNet モジュール – ニューラルネットワークのトレーニングと推論
- MXNet – 事前トレーニング済みモデルの使用
- Spark クラスターの概要
- Spark アプリケーションの送信
今後の改善
- コンピューティング/IO アクセスの最適化 – このアプリケーションでは、エグゼキューター上のコンピューティング/IO アクセスは、IO (コンピューティングなし) とコンピューティング (IO なし) が交互になる方形波パターンを持つことがわかりました。これは IO とコンピューティングをインターリーブすることで最適化できれば理想的です。ただし、各ノードで 1 つのエグゼキューターしか使用していないため、各ノードのリソース使用率を手動で管理するのは難しくなります。
- GPU の使用: GPU を使用してバッチデータの推論を実行できることも、大きな改善点です。
今回のブログの投稿者について
 Naveen Swamy は、Amazon AI のソフトウェア開発者で、革新的なディープラーニングツールを構築しています。彼の関心は、スキルを活用してアプリケーションに適用するために、ソフトウェアエンジニアがディープラーニングにアクセスできるようにすることです。趣味は、家族と時間を過ごすことです。
Naveen Swamy は、Amazon AI のソフトウェア開発者で、革新的なディープラーニングツールを構築しています。彼の関心は、スキルを活用してアプリケーションに適用するために、ソフトウェアエンジニアがディープラーニングにアクセスできるようにすることです。趣味は、家族と時間を過ごすことです。