Amazon Web Services ブログ
ECS、S3、Athena、Lambda、AWS Data Exchange を使用して、詳細な暗号通貨市場データを収集して配布する
これは Floating Point Group によるゲスト投稿です。彼らの言葉を借りると、「Floating Point Group は、機関投資家レベルの取引サービスを暗号通貨の世界にもたらすことをその使命としています」。
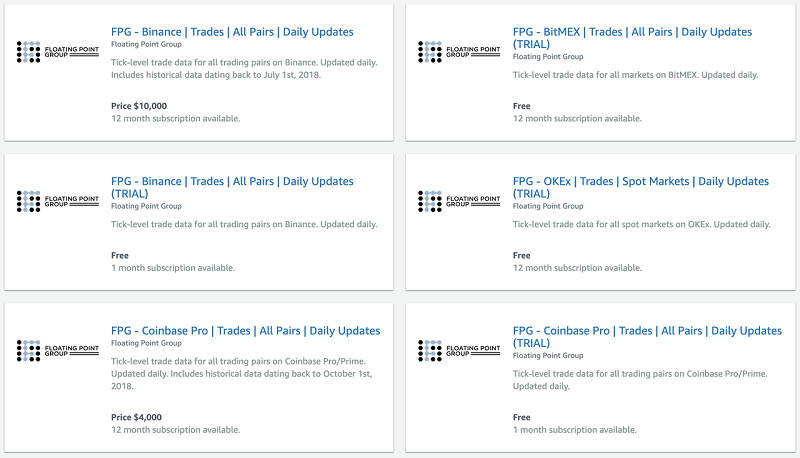
デジタル資産の取引向けに設計された金融インフラの必要性と需要はどれだけあるのかは、はっきりしないかもしれません。コインとトークンは、通貨、商品、株式、債券などの従来の資産に効果的にネイティブに相対するデジタル商品であると、広く受け止められています。この説明はよく、専門家が仮想空間内のさまざまなプロジェクトの価値提案を伝えようとするときに、力強く簡潔に伝えるために繰り返し用いられています (「ビットコインは、アルゴリズムで制御された改ざん防止の財務ポリシーが備わった、単なる通貨です」、または、「イーサリアムは、ガソリンのような金融商品です。それを使って、グローバルコンピューターの計算作業に支払うことができます」)。驚くことではありませんが、FPG である質問をよく耳にします。「暗号通貨が専用の金融サービスであることを保証するのに特別な点は何かありますか? なぜすでに解決された問題の解決策が必要なのですか」
実際、これらの資産とそれを取り巻く広範な公共の利益には、まったく前例がありません。ネットワークトランザクションのイミュータブルな記録として機能する分散型台帳テクノロジー。合理的なアクターを経済的に動機付けてネットワークのセキュリティを維持するためのプルーフオブワークアルゴリズムの巧妙な使用 (プルーフオブワークの概念は少なくとも 1993 年まで遡りますが、このテクノロジーが広く採用される可能性が示されたのは、ビットコインが登場してからです)。人的ミスや強要などの場合に固有の法的課題を引き起こす不可逆的な取引の性質。自己管理の不安定性 (サードパーティの保管ソリューションには、信頼を高める実績はありません)。これらの資産を分類することと、最終的に IRS、SEC、CFTC のようなエンティティによって調整する必要がある通貨交換を仲裁することの両方の困難を伴う規制上の不確実性。これらはすべて、非常に新しく、非常に特異なものです。24 時間取引が行える市場の規模は定期的に 1,000 億 USD を超えており、この記事では特にこれらの資産の取引に関連する問題に焦点を当てます。 確かに、仮想通貨取引は、ウェブフォーラムでビットコインを交換し始め、国際取引所間で 10% の価格スプレッドが確認されて以来、間違いなく成熟してきました。しかし、まだ長い道のりがあります。
機関投資家のために取り組むことを目指す上で抱える主な問題点の 1 つに、流動性 (またはより正確には、流動性の欠如) の問題があります。簡単に言えば、暗号通貨の売買は多くの異なる取引の場 (取引所) で行われ、流動性 (特定の価格で特定の量の資産を売買するオファー) は、新しい取引所が出現するにつれて断片化し続けています。100 ビットコインを購入しようとしているとしましょう。あなたは売りたい人から買う必要があります。最良の (最も安い) オファーを取得するにつれ、残りのオファーはどんどん高価になります。注文を完了するまでに (この例では、100 ビットコインをすべて購入するまでに)、たとえば注文の最初のビットコインに支払った価格よりも平均的にはるかに高い価格を支払うことになったかもしれません。この現象はスリッページと呼ばれています。スリッページを最小限に抑える 1 つの簡単な方法は、オファーの検索範囲を広げることです。そのため、1 つの取引所のオファーを見るのではなく、数百の取引所のオファーを見るのです。このプロセスは、従来スマートオーダールーティング (SOR) と呼ばれ、当社が提供するコアサービスの 1 つです。当社の SOR サービスにより、トレーダーは数十の取引所の流動性を積極的に監視することで、システムが複数の取引所で利用できる最高のオファーとマッチする注文を簡単に送信できます。
最良の価格を求めて大量注文を出すことは、かなり直感的で広く適用できる概念です。株式の約 75% が SOR を介して売買されています。けれども、暗号化市場向けのこのようなサービスの価値は特に顕著です。既存の取引所が行き詰まる中、新しい取引所が人気を博すという永続的なサイクルのため、取引所全体で流動性が絶え間なく断片化されています。けれどもトレーダーは、取引所に依存しない考え方を持つ傾向があります。ある特定量の資産にとって最良の価格を見つけることにのみ関心があるのです。
SOR サービスが機能するには、リアルタイムと過去の両方の市場データへのアクセスが不可欠です。当社が特定の市場で取得することを期待できる最高に詳細なデータには、売買の板に適用されるすべての取引とすべての変更が含まれます。これにより、いつでも市場の状態を効果的に再現できます。WebSocket ストリームを介して提供される更新は、板の再構築には不十分です。また、定期的に板のスナップショットを取得して保存する必要があります。これは、取引所の REST API を使用して実行できます。スナップショットを取得し、対応する更新をストリームから適用することで、板を「再生」できます。
幸い、多くの取引所が WebSocket API を介して市場データのリアルタイムフィードを提供しているため、このデータは自由に利用できます。このデータセットへのサブスクリプションを販売するサードパーティベンダーがいくつか見つかりました。通常、データセットは CSV ダンプの形式で毎週または毎月のリズムで配信されます。これは、構築するのか、購入するのかという問題を引き起こします。当社はリアルタイムの市場データを比較的短時間で取り込み、ベンダーからデータを購入する数分の 1 のコストで堅牢で信頼性の高いシステムを構築できると感じていたため、すでに構築する方に傾いていました。さらに調査を進めると、購入することの魅力がどんどん低下していきました。複数のベンダーがデータの品質と一貫性を保証できないことについて謳った免責事項を読んでも、信頼が高まることはありませんでした。サンプルデータセットを調べると、元のデータストリームで提供されたいくつかの必須フィールドが欠落していることが明らかになりました。この必須フィールドは、任意の時点で市場の状態を再現するという目標を達成するために必要なフィールドです。また、毎週または毎月の配信スケジュールにより、比較的最近の市場データを調査する能力が制限されることを把握しました。
この記事では、リアルタイムの市場データを取得および保存する方法と、AWS Data Exchange API を使用してデータセットをプログラムで整理および公開する方法の概要を説明します。システムの機能は、データの取り込み、正規化、永続性をはるかに超えています。当社は、データ検証、すべての市場の最新の取引および板のキャッシュ、派生指標の計算と保存のための専用サービス、それにデータの正確性を保護し、取引システムのレイテンシーを最小限に抑える他のサービスを実行しています。
データの取り込み
データを消費するために接続する WebSocket ストリームは、多くの場合、取引所の取引ダッシュボードにリアルタイムの更新情報を提供するのと同じ API です。
WebSocket 接続は、データを個別のメッセージとして送信します。個々のメッセージのコンテンツがブラウザにストリーミングされる際、それを検査できます。たとえば、次のスクリーンショットは、板の更新のバッチを示しています。

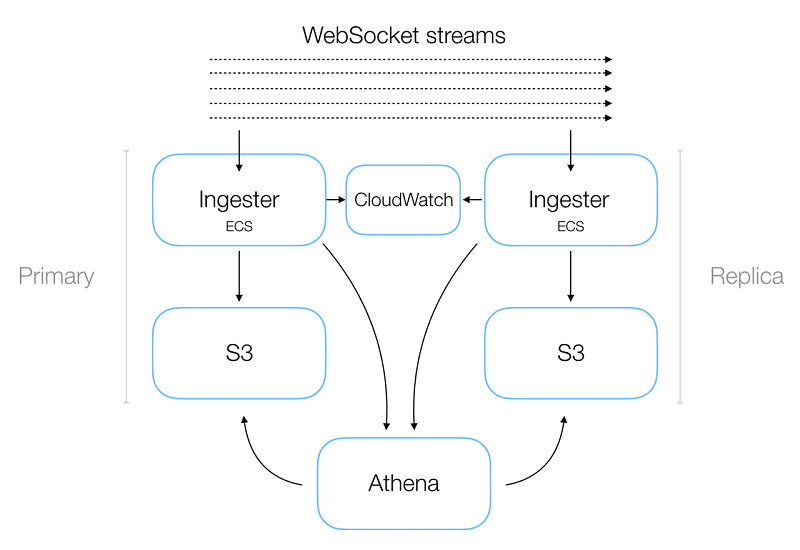
更新は、Bid と Ask の配列として表され、板に追加または削除されます。クライアント側のコードが各更新を処理するため、マーケットの板がリアルタイムでレンダリングされます。実際には、データ取り込みサービス (Ingester) は単一のストリームではなく、数千の異なるストリームを読み取っています。これにより、複数の取引所にわたるすべての市場のさまざまなデータフィードをカバーしています。このような広範なカバレッジに相当数の接続が必要なことと、その結果データを大量に受信することで、データ損失に対する明らかな懸念が生じます。このような懸念を緩和するために、Ingester サービスの任意の数のインスタンスを起動できる冗長なシステム設計など、いくつかの対策を講じました。ほとんどのマイクロサービスと同様に、Ingester は Amazon ECS で実行される Dockerized サービスで、Terraform を介してデプロイされます。
これらのインスタンスはすべて、同じデータフィードを互いに消費しますが、ダウンストリームメカニズムは重複排除を処理します (これについては、この記事の後半で詳しく説明します)。また、Amazon CloudWatch アラートも設定しました。これにより、着信データにギャップがあることを示す不連続のメッセージを検出したときに通知を受けられます。アラートはデータ損失を直接軽減しませんが、調査を促す重要な役割を果たします。
Ingester は着信メッセージの個別のバッファを構築し、data-type/exchange/market で分割されます。 その後、一定の時間間隔を空けた後、各バッファは gzip 圧縮された JSON ファイルとして Amazon S3 にフラッシュされます。バッファとフラッシュのサイクルが繰り返されます。
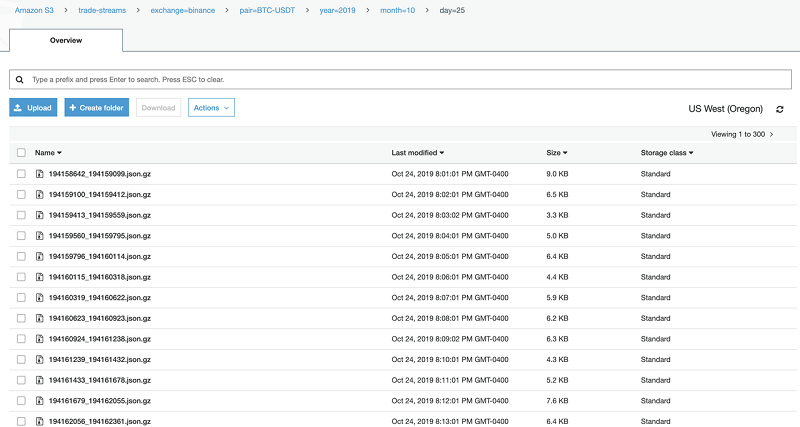
次のスクリーンショットは、ファイルのコンテンツの一部を示しています。

このコードスニペットは、上記のスクリーンショットのファイルから、きれいに印刷された単一の JSON レコードです。
Ingester はさらに、取引所固有のフィールド名の事前定義されたマッピングを内部フィールド名に適用するなどの機能もあります。データの正規化は、システムが市場のダイナミクスを総合的に理解できるようにするために必要な多くのプロセスの 1 つです。
ほとんどの分散システム設計と同様に、当社のサービスは、水平方向のスケーラビリティを最優先事項として作成されています。データ取り込みサービスの設計にも同じアプローチを採用しましたが、典型的な水平方向にスケーラブルなマイクロサービスとは少し異なる機能もいくつかあります。特定のサービスのインスタンス数を調整する最も一般的な動機は、負荷分散とスループットの調整です。システムでバックプレッシャーが発生し、コンシューマーサービスがその圧力を軽減するためにスケーリングするか、コンシューマーが過剰にプロビジョニングされて、節約のためにインスタンス数を縮小するかのどちらかです。ただし、データ取り込みサービスの場合、複数のインスタンスを実行する動機は、冗長性によるデータ損失を最小限に抑えることです。各インスタンスは同じ作業を行うため、各インスタンスの CPU 使用率はインスタンス数に依存しません。
たとえば、単一のキューからメッセージをプルすることでバックプレッシャーを緩和するのではなく、データ取り込みサービスの各インスタンスは、同じ WebSocket ストリームに接続し、同じ量の作業を実行します。データ取り込みサービスを水平方向にスケーリングする上であまり見慣れず、ややこしいのは、ステータスに関する側面です。当社は、メモリ内のレコードをバッチ処理し、レコードを 1 分ごとに S3 にフラッシュしています (不一致となるシステムのタイムスタンプではなく、着信メッセージのタイムスタンプに基づいて)。冗長性は、データ損失を最小限に抑えるための主要な手段ですが、レコードが重複しないように、各インスタンスがファイルを S3 に書き込む必要もあります。最初に考えたのは、レコードをすでに保持しているかどうかを確認できるキャッシュを維持するなど、インスタンス全体のアクティビティを調整するメカニズムが必要だということです。しかし、インスタンス間の調整を行うことなく重複を排除できることに気付きました。使用するメッセージストリームのほとんどは、シーケンス ID を使ってメッセージを発行します。シーケンス ID と受信メッセージのタイムスタンプを組み合わせて、重複排除メカニズムを実現できます。バッチに追加されたメッセージに、バッチ内の前のメッセージに関連する適切なシーケンスIDがあることを確認するサービスコードを記述することにより、まったく同じデータを含む同じ正確なファイル名を決定論的に生成できます。そして着信メッセージのタイムスタンプを使用して、各バッチの正確な開始と終了を決定します (通常、UNIX タイムスタンプを取得し、次のクロック分にロールオーバーしたときにチェックします)。これにより、単純に S3 のキーの競合を利用して重複を排除できます。
AWS は、Amazon Kinesis Data Streams に関連するわずかに異なる問題に対して同様のソリューションを提案しています。詳細については、「重複レコードの処理」を参照してください。
このスキームでは、レコードが複数回処理される場合でも、結果として得られる Amazon S3 ファイルは同じ名前と同じデータを持っています。再試行の結果、同じデータが同じファイルに複数回書き込まれます。
データを保存したら、最小限の設定でインフラストラクチャのオーバーヘッドをまったく必要としないクエリサービスである Amazon Athena を使用して、S3 に保存した数十億件のレコードに対して簡単な分析クエリを実行できます。Athena にはパーティションの概念があります (基礎となるサービスの 1 つである Apache Hive から継承しました)。パーティションは、仮想列 (この場合、pair、year、month、day) と対応するデータが保存されている S3 ディレクトリとの間のマッピングです。
S3 のファイルシステムは実際には階層構造ではありません。ファイルには、バケットのコンテンツを参照するときに AWS コンソールでディレクトリとしてレンダリングされる長いキープレフィックスが追加されます。これは、大規模なデータセットでクエリまたはフィルタリングを行う際に、パフォーマンスに少なからず影響を及ぼします。
次のスクリーンショットは、一般的なディレクトリパスを示しています。
![]()
Athena をデータの特定のサブセットに直接ポイントすることにより、明確に定義されたパーティションスキームは、クエリの実行時間とコストを大幅に削減できます。アドホックビジネス分析クエリは主に利便性のために実行するものです。けれども、最も一般的なアクセスパターンのいくつかに基づいて、Athena の健全なマルチレベルパーティションスキームを時間をかけて選択する価値があると思いました。パーティション構造が適切に設計されていないと、Athena が大量のデータを不必要にスキャンしてしまい、最終的にサービスが使いものにならなくなる可能性があります。

データ公開

数千の小さな gzip 圧縮された JSON ファイルをクリーンな CSV に変換して AWS Data Exchange にロードするためのパイプラインには、3 つの異なるジョブが含まれます。そのそれぞれのジョブが、AWS Lambda 関数として表されます。
ジョブ 1
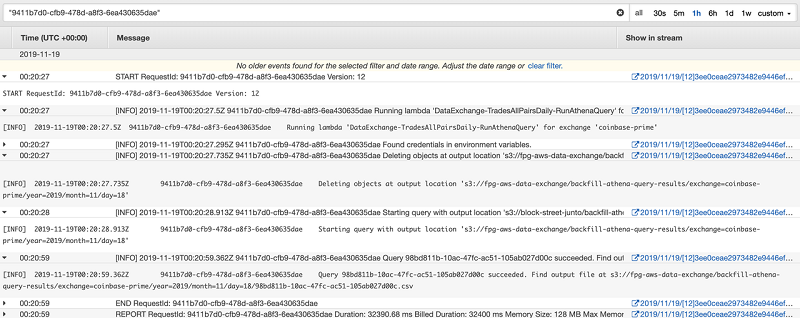
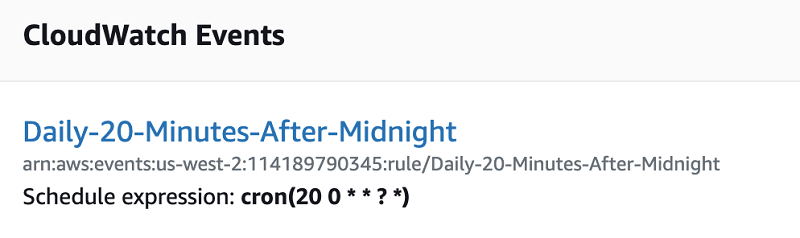
ジョブ 1 は、UTC 深夜 0 時を過ぎるとすぐに、cron でスケジュールされた CloudWatch イベントで開始します。前述のように、データ取り込みサービスのバッチ処理メカニズムにより、定期的に各バッチを S3 にフラッシュします。着信メッセージのタイムスタンプ (サーバー側に適用) は、取り込みサービスのシステムタイムスタンプとは対照的に、ある間隔から次の間隔へのロールオーバーを決定します。まれに、バッチ n の最終メッセージとバッチ n+1 の最初のメッセージを消費する間にかなりの時間が経過することがあります。そのため、UTC 時間の 0 時 20 分から最初の Lambda 関数を開始することで、書き込み保留中のデータを省略してしまう可能性を最小限に抑えます。
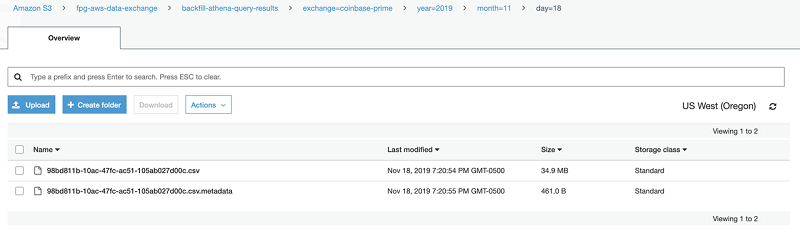
ジョブ 1 は、日付とデータソースの値を Athena クエリテンプレートにフォーマットし、クエリ結果を S3 の指定されたプレフィックスパスへの CSV として出力します。(DDL ステートメントは CSV を出力しませんが、すべての Athena クエリはクエリ結果の .metadata ファイルと CSV ファイルを生成します)。 S3 へのこの PUT リクエストは、S3 イベント通知をトリガーします。
冗長性の追加レイヤーとして、完全なレプリカデータ取り込みシステムを実行します。coalesce 条件式を使用して、ジョブ 1 の Athena クエリはプライマリシステムのデータをレプリカシステムの対応するデータとマージし、冗長レコードを重複排除しながらギャップを埋めます。
ジョブ 1 で実行された ETL 関連の作業に対して、AWS Glue と PySpark を使用してかなり広範囲に実験しました。すべての小さなソースファイルを 1 つにマージし、プライマリデータセットとレプリカデータセットを結合し、単一の Athena クエリで結果をソートすることができることに気付いたとき、この一見シンプルでエレガントなアプローチを使い続けることにしました。
次のコードは、Athena クエリテンプレートの 1 つを示しています。
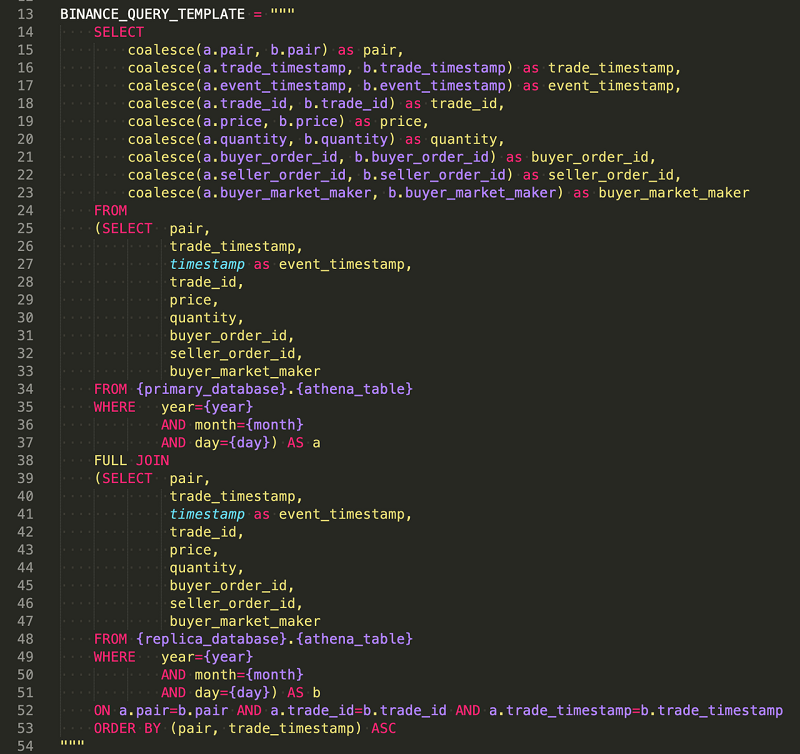
ジョブ 2
ジョブ 2 は、ジョブ 1 の S3 イベント通知によってトリガーされます。ジョブ 2 は、クエリ結果の CSV ファイルを同じ S3 バケット内の別のキーに単純にコピーします。
このステップの動機は 2 つあります。まず、Athena クエリ結果の CSV ファイルの名前を指定することはできません。名前は、Athena クエリ ID に自動的に設定されます。次に、S3 オブジェクトを AWS Data Exchange リビジョンにアセットとして追加すると、アセットの名前が S3 オブジェクトのキーに自動的に設定されます。そのため、AWS Data Exchange で CSV ファイル名がどのように表示されるかを指定するには、まず名前を変更する必要があります。名前を変更するには、指定した S3 キーにコピーします。

ジョブ 3
ジョブ 3 は、それぞれの API により、AWS Data Exchange と AWS Marketplace Catalog に関連するすべての作業を処理します。これらの API とのインターフェイスには、AWS の Python SDK である boto3 を使用します。AWS Marketplace Catalog API は、すでに公開されている製品にデータセットリビジョンを追加するために必要です。詳細については、「チュートリアル: 公開されたデータ製品への新しいデータセットリビジョンの追加」を参照してください。
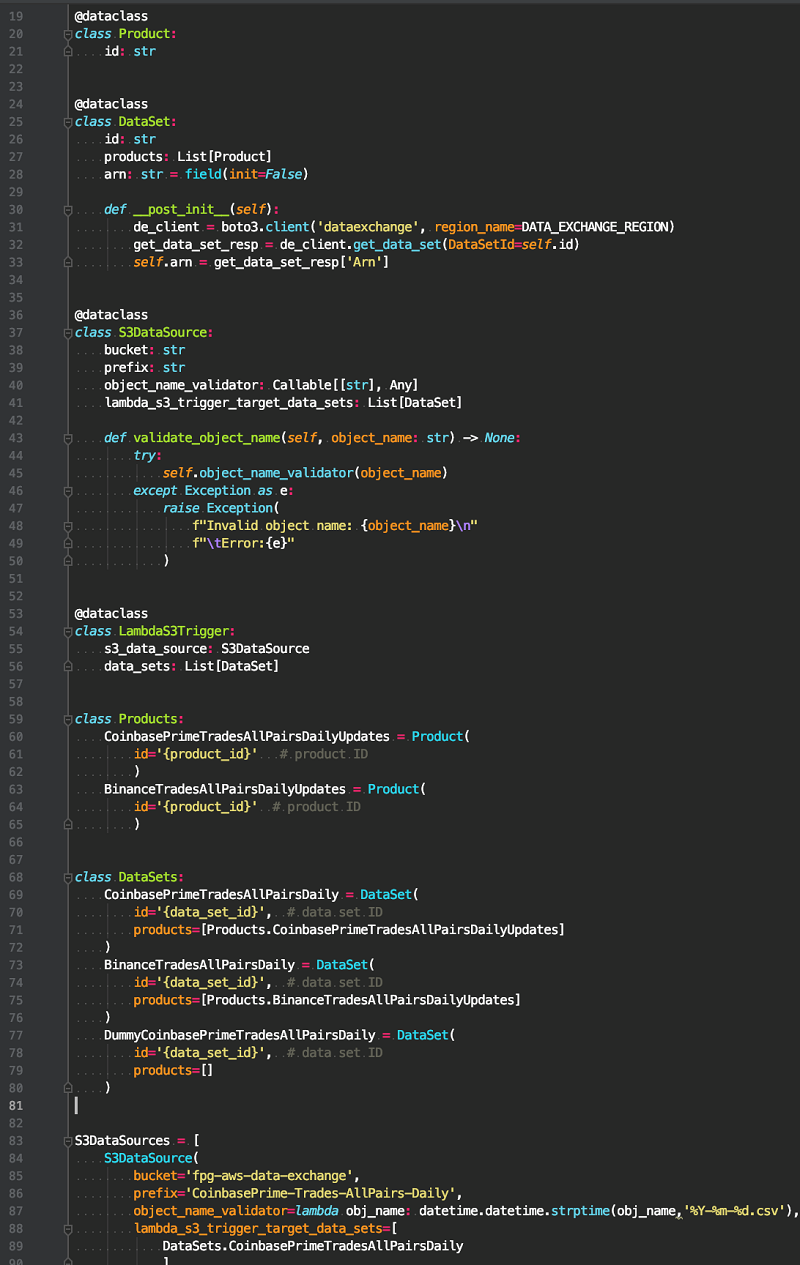
このコードは、次の構造を持つマッピングを明示的に定義します。
データソース / データセット / 製品
次のコードは、データソース、データセット、および製品間の関係を設定する方法を示しています。
データソースは通常、取引所とデータタイプの組み合わせ (Binance trades や CoinbasePro 板など) で表されます。特定のデータソースの新しいファイルはそれぞれ、特定のデータセットの単一の新しいリビジョン内の単一のアセットとして配信されます。
S3 トリガーが Lambda 関数を開始します。トリガーは、単一のデータセットにマッピングされる指定プレフィックスにスコープされます。AWS Lambda の関数エイリアス機能により、同じ基になる Lambda 関数を再利用しながら、各データセットに一意の S3 トリガーを定義できます。ジョブ 3 は次の手順を実行します (手順 1~5 については「AWS Data Exchange API」を参照し、手順 6 と 7 については「AWS Marketplace Catalog API」を参照)。
CreateRevisionにより、対応するデータセットの新しいリビジョンを作成するリクエストを送信します。IMPORT_ASSETS_FROM_S3ジョブタイプを使用して、CreateJobで Lambda 関数をトリガーしたファイルを新しく作成されたリビジョンに追加します。このジョブを送信するには、いくつかの値を指定する必要があります。ファイルの S3 バケットとキー値は Lambda イベントメッセージからプルし、RevisionID 引数は 前の手順のCreateRevision呼び出しへの応答から取得します。StartJobでジョブを開始し、前の手順のCreateJob呼び出しへの応答からJobID引数を取得します。GetJobによりジョブのステータスをポーリングし (前の手順でStartJob呼び出しへの応答のジョブ ID を使用して)、ファイル (アセット) がリビジョンに正常に追加されたことを確認します。UpdateRevisionでリビジョンを確定します。DescribeEntityを使用してマーケットプレイスエンティティの説明をリクエストし、ハードコーディングされたマッピングに保存されている製品 ID をEntityIDとして渡します- StartChangeSet によりエンティティ ChangeSet を開始し、前のステップのエンティティ ID を渡し、前のステップの DescribeEntity レスポンスのエンティティ ID を
EntityIDとして渡し、 以前の CreateRevision への呼び出しに対する応答から解析されたリビジョン ARN を RevisionArn として渡し、さらにデータセット ARN を DataSetArn として渡します。データセット ARN は、AWS Data Exchange API の GetDataSet を使用して、コードのランタイムの開始時にフェッチしたものです。
上記の手順を実行するために作成したシンラッパークラスを次に示します。
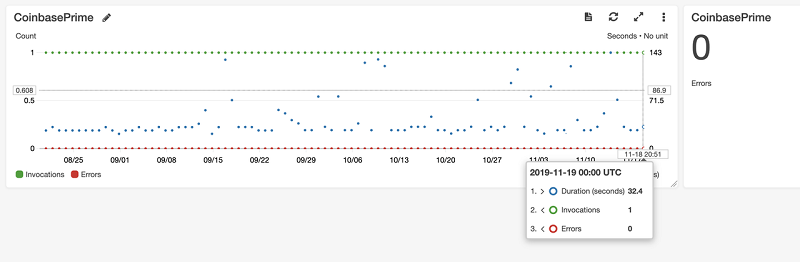
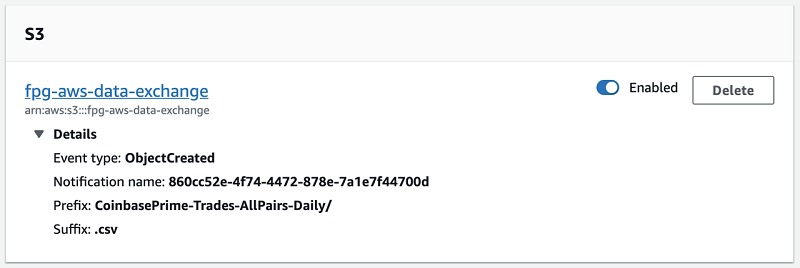
次のスクリーンショットは、ジョブ 3 の S3 トリガーを示しています。
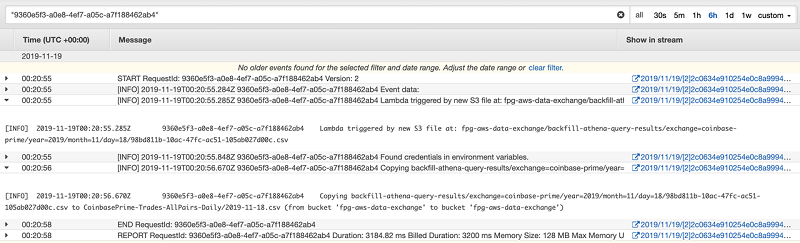
次のスクリーンショットは、ジョブ 3 の CloudWatch Logs の例を示しています。
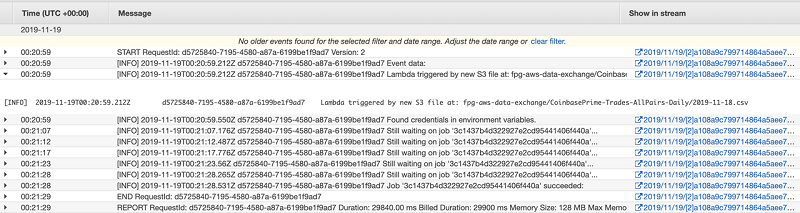
次のスクリーンショットは、ジョブ 3 の CloudWatch アラームを示しています。
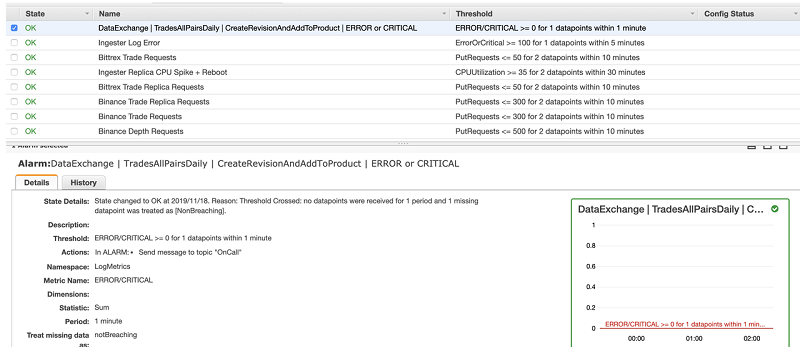
最後に、AWS コンソールを通じて、リビジョンが対応するデータセットと製品に正常に追加されたことを確認できます。
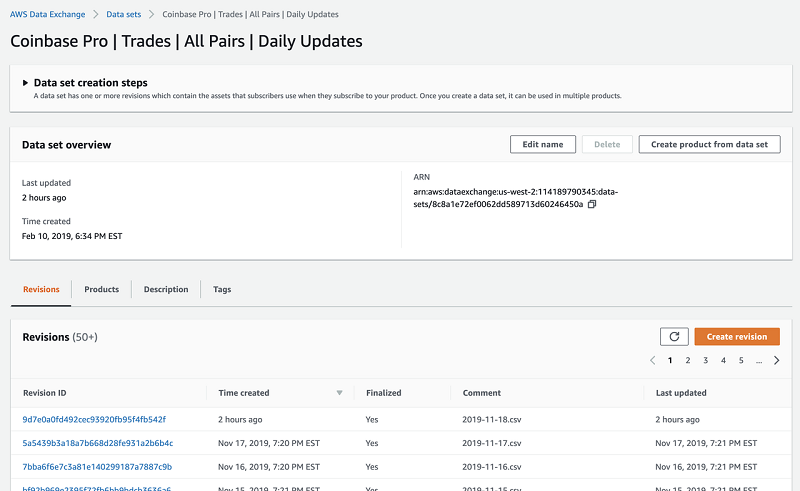
AWS Data Exchange は、AWS アカウント ID のプライベートオファーを作成でき、各製品に期待どおりにリビジョンが表示されることを確認する便利な手段になります。
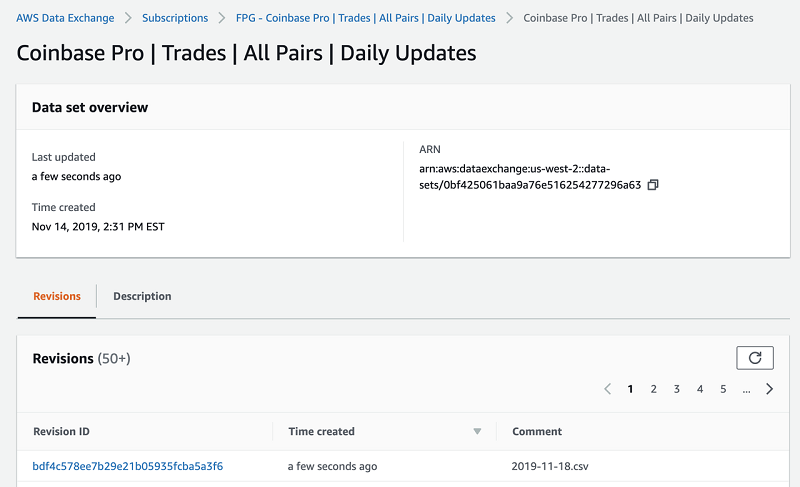
まとめ
この記事では、AWS Data Exchange を既存のデータパイプラインにスムーズに統合する方法を示しました。AWS Data Exchange のプライベートプレビューに参加するよう招待していただいたことを嬉しく思います。さらに、そのサービス自体、当社のシステムを洗練され自然な形で拡張できるものであると証明されたことを大変喜ばしく思います。
過去 1 年間、AWS Data Exchange チームの Kyle Patsen と Rafic Melhem の両氏には大変お世話になりました。両氏は、私の問題提起に寛大にも対応してくれました (また私のとりとめのない話にも辛抱強くお付き合いいただきました)。また、Lucas Adams には、この記事で説明したシステムの設計を手伝ってくれたこと、そしてさらに重要なことに、揺るぎない信頼を寄せてくれたことに感謝申し上げます。
FPG の詳細に興味がある方は、お気軽にお問い合わせください。