Amazon Web Services ブログ
Amazon Comprehend と Amazon Relational Database Service を利用してテキスト分析ソリューションを構築する
これまで、大量の構造化されていないか、半分構造化されているコンテンツからの値の抽出は困難で、機械学習 (ML) のバックグラウンドが必要でした。Amazon Comprehend はエントリの障害をなくし、データエンジニアと開発者が豊富で継続的にトレーニングされた、自然言語処理サービスに簡単にアクセスできるようにします。 Amazon Comprehend からの分析を関連するビジネス情報と結合して貴重な傾向分析を構築することにより、完全な分析ソリューションを構築できます。たとえば、ブランド、製品、またはサービスについて取り上げている記事では、どの競合製品が最も頻繁に書かれているのかを理解することができます。顧客は顧客プロファイル情報と顧客のフィードバックのセンチメントも結合して、新製品を発売したときにどのタイプの顧客が特定の反応を見せるのかをより良く理解することもできます。
収集され、S3 に保存されるソーシャルメディアの投稿、ニュース記事や毎日の顧客のフィードバックなどの造化されていないか、半分構造化されているコンテンツの急速な増加により、S3 は分析できるときにもたらされる貴重な洞察の絶好の機会を提供してきました。Amazon Comprehend は Amazon Relational Database Service (RDS) とシームレスに機能します。このブログ投稿において、私たちは自然言語処理モデルの機械学習について学ぶ必要なく、データベースから豊かなテキスト分析ビューを構築する方法を紹介します。
私たちはこのことを Amazon Comprehend を Amazon Aurora-MySQL と AWS Lambda と結合して利用することで行います。これらは、センチメントを判別し、それをデータベースに返して保存するためにデータが挿入されるときに発せられる Aurora の一連のトリガーと統合されます。その後、より迅速な洞察をもたらす上で役立つ、データベースの追加データと結合できます。この同じパターンは、Amazon Translate などの他のアプリケーションレベルの ML サービスを統合して、コンテンツ自体を翻訳するために使用することもできます。
重要 -このパターンを使用しないとき: このパターンは、高速の Insert コール (1 秒間に数十を超える行数の挿入) を伴うワークロードを対象としていません。これらのトリガーは非同期ではないため、アドホック操作にのみお勧めします。Lambda 関数のコールを Insert ステートメントの後に置くことにより、各ステートメントに数十ミリ秒を追加します。トラフィックの多いデータソースの場合は、poll-aggregate-push アプローチを使用して、主たる Insert 書き込みパスから Lambda コールを削除する必要があります。
アーキテクチャ
次のダイアグラムは、このブログで設定するフローを示します。
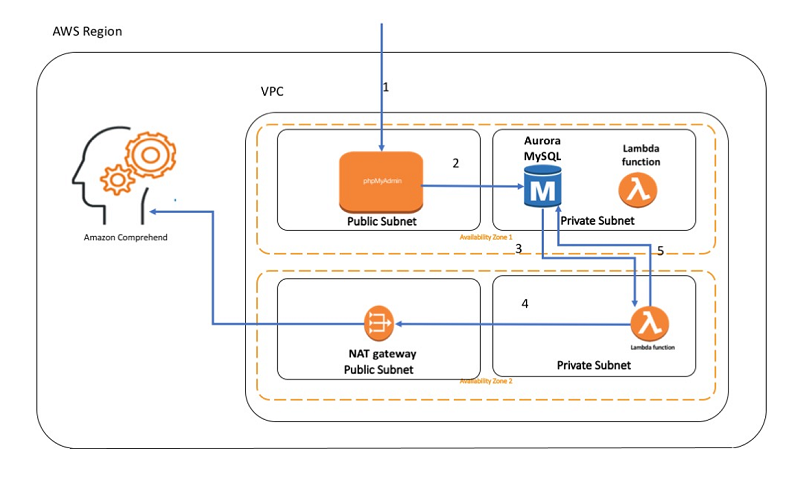
ダイアグラムの矢印は、次のステップを示します。
- MySQL のウェブベースの管理ツールである phpMyAdmin に接続します。
重要: 読者が容易に使用できるように、ここでは phpMyAdmin を使用します。Apache で SSL/TLS を有効にしていない限り、phpMyAdmin を使用することをお勧めしません。それ以外の場合、お使いのデータベース管理者パスワードとその他のデータは、インターネット上で安全でない方法で送信されます。 - 新規レコードを Aurora MySQL データベースに挿入します。
- INSERT で発せられるように設定されたトリガーが、Lambda 関数を呼び出します。
- Lambda 関数は、テキストのセンチメントを判別するために、Amazon Comprehend をコールします。
- センチメントは、テーブルの行と共に保存されます。
設定
AWS マネジメントコンソールで、CloudFormation テンプレートを起動します。
![]()
注記: キーペアを忘れずに選択してください (異なる名前があることがあります)。 DB パスワードも書き留めてください。

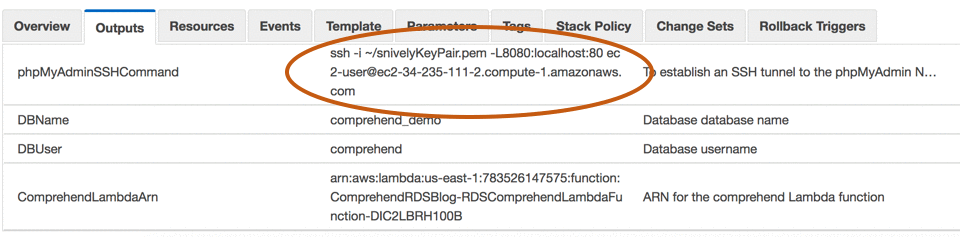
スクリプトが終了するまでお待ちください。通常は、スタック全体が立ち上がるまで、約 15 分間かかります。AWS CloudFormation スクリプトには、キーペアのパスが正しいと想定して、SSH コマンドの表示形式を示す出力があります。
データベース構成の設定
ローカルの http ポートに SSH 経由で接続するように、ポート転送を設定します。
詳細については、こちらをご覧ください。
https://thinkwithwp.com/premiumsupport/knowledge-center/connect-ec2-linux-windows/
- ポート転送を設定した後で、phpMyAdmin に接続します。
http://localhost:8080/phpMyAdmin/ - 次に、phpMyAdmin にログインします。CloudFormation スクリプトの config から DB のユーザー名/パスワードを使用します。

- 一番上のナビゲーションウィンドウで SQL を選択します。

- レビュー用のテーブルを作成します。次を貼り付けて、Go を選択します。
これは、リレーショナルデータベースのレビュー情報を示すためのものですが、NLP を実行する必要のある他のテキストフィールドでもかまいません。
- ここで、新しいデータを入手したときのストアドプロシージャを呼び出すトリガーを作成します。一番上で SQL をもう一度選択して、以下を貼り付けて、Go を選択します。
- 最後に、ストアドプロシージャを作成します。後に続く Lambda 関数名を必ず置き換えてください。
注記: Lambda ARN は、CloudFormation スクリプトの出力にあります。「ComprehendLambdaArn」というラベルの出力です。

クラスターの IAM の設定
CloudFormation スクリプトは自動的に DB クラスターパラメータグループでパラメータを設定しますが、この演習では。手動ステップとしてIAM 許可をクラスターに添付したままにしています。
- RDS コンソールのクラスターにアクセスします。
https://console.thinkwithwp.com/rds/home?region=us-east-1#dbclusters - クラスターを選択し (CloudFormation スクリプトに基づいた異なる名前を指定する場合があります)、[Cluster アクション] の下の [IAM ロールの管理] を選択します。

- 次に、CloudFormation が作成し、クラスターにそれを適用する IAM ロールを選択します。

統合のテスト
- phpMyAdmin ウィンドウに戻って、もう一度 SQL オプションを選択して、次のとおり貼り付けます。

- ここで、comprehend_demo.Tables.ReviewInfo の下のテーブルを選択します。センチメントを入力しませんでしたが、すでに入力されていることに気が付きます。これは、Amazon Comprehend を通じて自動的に判別されます。

その他のサンプルエントリの入力
SQL ウィンドウで次のコマンドを実行します。すべてを貼り付けて、Go を選択します。

この時点で、AWS Lambda とトリガーを使用して、Amazon Comprehend を Aurora データセットに統合しました。
対象範囲の確認
このセクションでは、Lambda 関数が行っていることを確認します。最初に気が付くことは、すべてのインポートされたステートメントを含めて、16 行のコードしかないことです。
Lambda 関数は、上記で作成されたストアドプロシージャから呼び出されます。具体的には、次の行がその呼び出しを行います。
このプロシージャは ID とテキストを取得し、AWS Lambda を通過する単純な JSON オブジェクトを作成することに気が付くはずです。これは lambda_sync メソッドではなく、lambda_async メソッドを使用しているため、非同期コールです。
注記: Amazon Aurora バージョン 1.16 以降、ストアドプロシージャ mysql.lambda_async は廃止されました。Aurora バージョン 1.16 以降を使用している場合は、代わりにネイティブ Lambda 関数を使用することを強くお勧めします。詳細については、「Lambda 関数を呼び出すためにネイティブ関数で操作する」を参照してください。
Lambda の中では、以下が渡されます。
ここでは、Boto3 ライブラリを使用して、Amazon Comprehend をコールする Python を使って Lambda 関数を実装しました。
次の 4 行は、Amazon Comprehend をコールし、テキストで NLP を実行し、センチメントを引き出すために必要なすべての行です。
この関数が Amazon Comprehend サービスからのセンチメントを取得すると、関数はその情報を取得してデータベースに返して保存します。 これは、次の数行で実行することができます。
代替オプション
Lambda を呼び出すためにトリガーを使用することは、非常に高速の Insert ワークロード (1 秒間に数十を超える行数の挿入) を対象としているわけではありません。トリガーは非同期ではないため、一般的にはアドホック操作にのみお勧めします。Lambda のコールを INSERT ステートメントの後に置くことにより、各ステートメントに数十ミリ秒を追加します。トラフィックの多いデータソースの場合は、poll-aggregate-push アプローチを使用して、主たる INSERT 書き込みパスから Lambda コールを削除する必要があります。
クリーンアップ
このソリューションのテストを終了した後で、料金の発生を停止するために、CloudFormation スタックが削除されます。 CloudFormation スタックを削除して、このブログ記事で作成されたすべてをクリーンアップしてください。
CloudFormation スタックの削除方法に関する詳しい手順は、以下の指示を参照してください。https://docs.thinkwithwp.com/AWSCloudFormation/latest/UserGuide/cfn-console-delete-stack.html
一部の希なケースでは、ENI が Lambda 関数に割り当てられたままで、削除がタイムアウトすると、VPC の削除が失敗します。その場合は、約 15 分間待ってから、再度削除してください。すると、コストが発生するすべてのことも削除されます。
コストは?
このサンプルを us-east-1 AWS リージョンで 1 時間実行した場合、コストは 0.50 USD 未満です。 実際に活用されているサービスのほとんどは、無料利用枠に分類されますが、最悪の場合を想定して、次の計算を行います。
| 項目 | 単位 | コスト (USD) |
| EC2 for phpMyAdmin t2.medium | 1 時間 @ 0.0464 / 時間 | 0.0464 USD |
| EBS for phpMyAdmin | 8 GB gp2 @ GB 月あたり 0.10 USD -プロビジョニングされたストレージ (1 秒ごとに課金) | 0.00109589041 USD |
| Aurora MySQL の計算 | db.t2.small @ USD 0.041 時間 | 0.041 USD |
| Aurora MySQL ストレージ | GB 月ごとに 0.10 USD | 0.10 USD |
| Aurora MySQL IOs | 100 万個のリクエストごとに 0.20 USD | 0.20 USD |
| Lambda リクエスト | 8 個のリクエスト @ リクエストごとに 0.0000002 USD | 0.0000016 USD |
| Lambda 計算時間 | 1 秒 * 8 個の呼び出し @ 100 ミリ秒ごとに 0.000000208 | 0.00001664 USD |
| 合計予想額: | ~ 0.38 USD | |
まとめ
この簡単なアプローチで、テキストとして保存されたフィードバックは自動的に翻訳されるか、高度な Amazon AI サービスにより加工されます。 ここではセンチメントのコールを利用してこれをデモンストレーションしましたが、トピック、キーフレーズ、翻訳などの機能を抽出するように、容易に拡張することができます。
サンプルコードの既知の限界:
現在、このブログ投稿のストアドプロシジャでは、JSON メッセージを作成するときに、ストリング値で予約文字をエスケープしません。必要に応じて、コールでこれを変更することができます。
今回のブログ投稿者について
 Ben Snively は。AWS パブリック・セクター・スペシャリスト・ソリューション・アーキテクトです。 同氏は、政府機関、非営利団体、教育機関のお客様のビッグデータ/分析や AI/ML 分析プロジェクトに協力して、AWS を使用するソリューションの構築を支援しています。
Ben Snively は。AWS パブリック・セクター・スペシャリスト・ソリューション・アーキテクトです。 同氏は、政府機関、非営利団体、教育機関のお客様のビッグデータ/分析や AI/ML 分析プロジェクトに協力して、AWS を使用するソリューションの構築を支援しています。
 Natasha Alexeeva は、AWS シニア・ビジネス開発マネージャで、人工的なインテリジェンスと機械学習に焦点を当てています。主たる専門分野は、健康とライフサイエンス産業です。 AI の能力を探究することに興味をもつ AWS クライアントの POC を構築することに力を発揮しています。
Natasha Alexeeva は、AWS シニア・ビジネス開発マネージャで、人工的なインテリジェンスと機械学習に焦点を当てています。主たる専門分野は、健康とライフサイエンス産業です。 AI の能力を探究することに興味をもつ AWS クライアントの POC を構築することに力を発揮しています。