Amazon Web Services ブログ
Amazon Rekognition Video を使って、スケーラブルかつ適応性のある動画処理パイプラインを構築する
VidMob のシニアソフトウェアエンジニア、Joe Monti 氏の投稿記事です。彼らの言葉を借りれば、Vidmob とは「革新的テクノロジーソリューションを備えた、世界をリードするビデオ作成プラットフォームです。高度にトレーニングしたクリエイターネットワークを使って、予測に重点を置き、自分用にカスタマイズしたり拡張もできるマーケティングコミュニケーションの開発を可能にします。VidMob のクリエイターは、ソーシャルあるいはデジタルチャンネル、フォーマット、および言語にわたるあらゆるビデオコンテンツが制作できるようにトレーニングされています。」
動画は、特に複雑で大規模なリアルタイムアプリケーションで使用する場合、自動化したコンテンツ認識を行うのに、特徴的な課題が生じます。例えば、ディープラーニングアルゴリズムを実装し使用するのは、面倒な作業だけでなく、大きな動画ファイルや大きな出力ファイルを処理するために膨大なコンピューティングパワーを必要とします。Amazon Rekognition は AWS 上で利用可能な数多くのツールとサービスを組み合わせることで、こうした難しい部分をより簡単に行えるようにします。そのため、価値ある、そして洗練されたアプリケーションの構築だけに、総力をあげることができるのです。
この記事では、動画ファイルに対してコンテンツ認識を実行する、スケーラビリティおよび適応性が高い処理パイプラインの重要なコンポーネントについて説明します。
アーキテクチャの概要
次のアーキテクチャは、コンテンツ認識を通じて動画を処理し、使用可能なデータセットを構築するために、多くの AWS サービスを統合します。
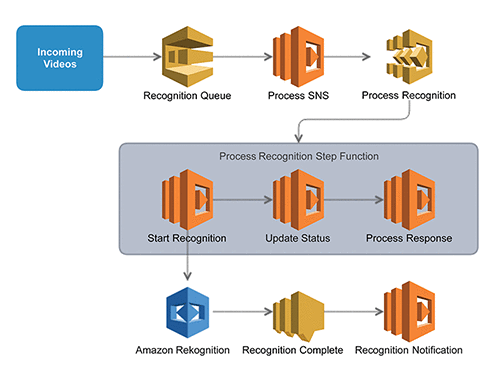
システムが新しい動画を取り込み、保留中のメディア認識のため Amazon SQS キューへメッセージが送信されると、このプロセスが開始されます。このキューは、Amazon Rekognition API のスループットを管理するためのバッファとして機能します。次のステップで、SQS キューを処理し、Process Rekognition Step Function を開始するため、固定料金スケジュールで設定した Amazon CloudWatch イベントが起動します。このステップ関数は、複数の AWS Lambda 関数を調整し、後に続く Amazon Rekognition リクエストとデータ処理を管理します。
Amazon Rekognition によるリクエスト処理のためのステップ関数
ステップ関数は、コードの実行を調整するシステムで、次に行うことを決定する制御フローロジックを提供します。ですので、ステップ関数を使えば、動画処理パイプラインの機能を迅速に開発、テスト、デプロイ、および向上することができます。この例では、AWS Step Functions で作成したステップ関数を使用して、複数の コンテンツの Amazon Rekognition API 操作による動画処理を可能にします。次の画像は、Amazon Rekognition リクエストを開始、待機、および処理する簡単なステップ関数を表しています。

このステップ関数の状態は、次の通りです。
- 認識の開始 – Amazon Rekognition ジョブを開始および追跡する Lambda 関数。動画のための Amazon Rekognition API 操作は非同期であるため、Amazon Rekognition ジョブを開始して終了するまで待機する必要があります。
- 認識の待機 – Amazon Rekognition プロセスを完了させるために一定の時間スリープする待機状態。
- 認識ステータスの交信 – 非同期 Amazon Rekognition タスクが完了したという通知を監視する Lambda 関数。その後、継続が可能になった時、ステップ関数に信号を送ります。
- 確認完了のチェック – 前の手順を見て、待機を再試行するかどうか、Amazon Rekognition リクエストが失敗したかどうか、または続行するかどうかをを決定する選択状態。
- プロセス承認の応答 – 動画がリクエストする全てのジョブからの応答データを、アプリケーションに適したデータセットへと処理を行う Lambda 関数。
ステップ関数での Lambda 関数の使用
動画認識処理のための Lambda 関数は、3 つの主要な AWS サービスを利用します。
- Amazon Rekognition – 個々の認識ジョブから開始し、それらからステータスと結果を取得するのに使用します。
- Amazon S3 – 動画ファイルと Amazon Rekognition の未加工出力は Amazon S3 に保存されます。
- Amazon RDS – Amazon Rekognition のリクエストと関連データは、MySQL RDS インスタンスに格納されます。
以下の例は、ステップ関数で使用する Lambda 関数をサポートするために必要となるコードです。Lambda 関数の例は全てPython で書かれています。
Amazon Rekognition の開始
次のコードで DetectLabels 操作への Amazon Rekognition のリクエストが開始します。
Amazon SNS 通知を受信する
Amazon Rekognition API は、与えられた通知チャネルに Amazon SNS トピックを送信します。この SNS トピックを Lambda 関数にフックすると、完了したジョブに応答して処理を続行できます。次のコードは、Amazon SNS 通知を受信してAmazon Rekognition 結果を取得、Amazon S3 に保存、結果をデータベースに更新する方法を示しています。
動画処理とデータ構造
動画のタイムライン上で、データを処理し相関させることは簡単ではありません。動画では、時間が経過するとともに、ラベル間の関係を作れたらと思うことはありませんか?これを実現するには、Amazon Rekognition API から得られるフレームベースデータを、ラベルベースデータセットに変換するのです。
こちらの例は DetectLabels 操作で戻されたデータです。
ラベル ”Baseball” はタイムスタンプ 0、200、400 に表れるため、ラベルは動画全体に表示されます (Amazon Rekognition は通常、約 200 ミリ秒ごとにフレームを検出します)。連続するフレームに現れるタグを圧縮し、次のデータセットを生成します。
この変換を実行する Python 関数の例は、次のようになります。
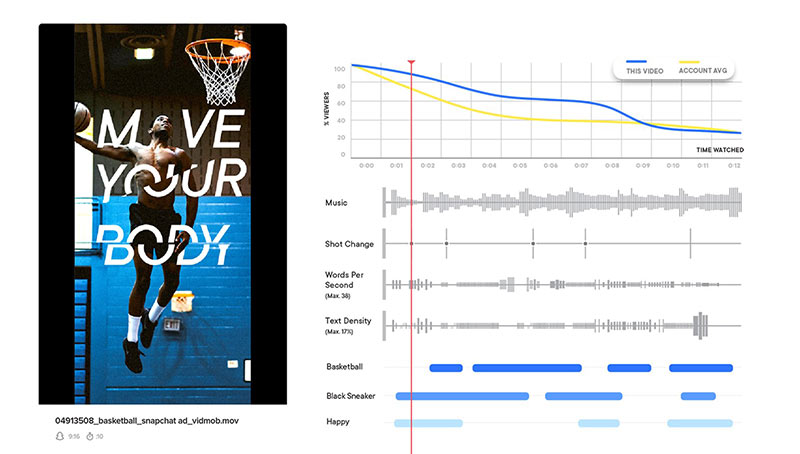
次に、圧縮したラベルをデータベースに格納して、アプリケーションを使用できるようにします。VidMob では、このデータと他のデータを使って、コンテンツ認識データを表示できるパワフルな視覚化が可能です。その例がこちらです。
まとめ
完璧なシステムの構築を目指すなら、情報は他にもたくさんあります。ですがこの記事では、AWS ツールボックスのツールを使用して、スケーラビリティと適応性の高い動画処理パイプラインを構築する方法に関して、一般的な考え方に焦点を当てていることをご了承ください。