Amazon Web Services ブログ
Amazon Neptune と Amazon Redshift を使用して顧客 360 のナレッジリポジトリを構築する
Organizations は、データレイク、データウェアハウス、レイクハウスなどの大規模なデータプラットフォームを構築してデプロイし、顧客移動の全体像を捉えて分析します。このようなデータプラットフォームの目的は、満足度に影響を与え、エンゲージメントを促進する顧客の行動パターンを理解することです。今日のアプリケーションは顧客との各連絡先をキャプチャしますが、そのデータはさまざまな場所 (外部パートナー、チャットボットやコールセンターなどのアウトソーシングされた SaaS、オンプレミスシステム、Google Analytics などのパブリッククラウドなど) に分散しており、データ間のリンクはほとんどないか、まったくありません。したがって、顧客が最初の接触から現在の体験状態になるまでにこれらの異なるデータソースを接続することが課題になります。顧客体験の主な属性と詳細データを指すリンクを含むナレッジベースを通じて、顧客を 360 度見渡す必要があります。このナレッジベースは、データランドスケープの進化に合わせて新しいデータパターンをサポートするために、柔軟で機敏性があり、拡張可能でなければなりません。
Amazon Neptune は、接続されたデータパターンを保存するために作成された専用のグラフデータベースです。これを使用して、顧客体験のデータをほぼリアルタイムでキャプチャすることにより、360 度の顧客ビューを構築できます。接続されたデータソリューションは、顧客サービス担当者にビジネスインサイトを提供し、新規販売を支援し、顧客に推奨事項を提供し、顧客 360 ダッシュボードを強化し、機械学習 (ML) ベースの分析を実行するためのデータリポジトリとして機能します。
この記事では、Neptune を使用した住宅保険についての顧客体験を以って顧客 360 のナレッジベースソリューションを構築する方法を示します。次の手順を説明します。
- 接続されたデータプラットフォームの価値実証 (POV) を示すサンドボックス環境を構築する
- 最初の接触から熱心でアクティブな顧客に至るまで顧客体験のステップを定義する
- Amazon Redshift SQL と分析機能を使用し、顧客体験に関与するさまざまなソースから得たデータ間のデータパターンと関連リンクについて理解する
- エンティティ関係 (ER) 図でビジネス状態エンティティと関連する関係を定義する
- ER 図とサンドボックスデータから頂点、エッジ、プロパティを識別するグラフモデルを作成する
- Amazon Redshift から Amazon S3 に Neptune ロードファイルを生成する
- Neptune で接続されたグラフデータの一括読み込みを実行する
- 接続されたデータのビジネス価値を証明する顧客 360 アプリケーションを構築する
- Neptune をデータパイプラインと統合して、データストアを接続し、専用のデータベースで新しいファクトを公開する
次の図は、そのプロセスを示しています。

ソリューションの概要
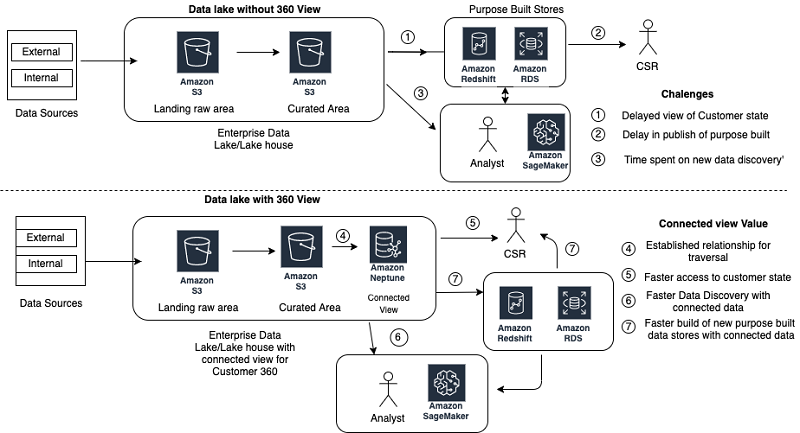
エンタープライズデータプラットフォームは、さまざまなデータキャプチャメカニズム (ウェブフロントエンド、モバイルアプリケーション、コールセンター、外部フィード、外部データ代理店とパートナー、クラウドフロント、内部ホストアプリケーション) を使用して、顧客体験データを取り込みます。従来のデータプラットフォームでは、顧客の行動パターンを理解するために、さまざまなタイプのデータストアにあるさまざまなデータを取り込み、変換し、キュレートします。データソースパターンは、大きく外部構造化、外部非構造化、内部構造化、および内部非構造化に分けられます。新規顧客または変更顧客中心の製品でデータパターンに拡大や変更が加わると、顧客体験データは複数のデータストアでばらばらになります。顧客に関連付けられたすべてのデータを接続して全体的なデータ状態を提供するのは困難な場合があります。洞察が古くなり、顧客中心の最新洞察を提供するためのレイテンシーが増大し始めています。データレイクがデータスワンプになったため、未解決のビジネス課題に対する顧客の不満を減らすために、新しい専用ストアをクリーンアップして構築する必要があります。
Tinkerpop プロパティグラフを使用して、エンタープライズデータレイクでキュレートされたレイヤーの頂点および関連するエッジとしてデータエンティティ間の関係をキャプチャできます。変数スキーマ (新規プロパティ) の Neptune 機能と、新しいエンティティ (頂点とエッジ) を追加する拡張性により、新しいフィードから顧客データをほぼリアルタイムで保存し、顧客の 360 ビューをより速く公開できます。次の図は、これらのアーキテクチャを比較しています。
チュートリアル
この記事のユースケースでは、最新のアプリケーションを使用して住宅またはアパートの保険に新規顧客を登録する新しい保険パラダイムにおいて、住宅保険会社が顧客の行動を理解したいと考えています。顧客がたどった道筋 (ウェブブラウザ、モバイルアプリ、またはコールセンター) に応じて現在の顧客状態を把握し、適切な価格と対象範囲で保険証券を販売する必要があります。これにより、長期にわたって熱心な顧客の満足度が高くなります。
この記事では、4 つの異なるデータ取り込みパターン (関連のないデータを分析するための関連する課題、Amazon Redshift を使用してグラフデータを分析および作成する方法、および Neptune がデータ間のドットを接続してほぼリアルタイムで全体的な顧客 360 ビューを提供して価値を足す方法) について説明します。次の表は、4 つの取り込みパターンをまとめたものです。
| ソースの発生元 | データタイプ | ソースタイプ | データの説明 |
| 外部 | 構造化データ | コールセンターデータ |
SAAS ソリューションでサポートされるコールセンター。ベンダーは、顧客との通話およびエージェントと顧客との対話に関連する毎日の通話ログを提供します。 このシステムは、顧客の通話処理効率に焦点を当てています。 |
| 外部 | 非構造化データ | ウェブ分析データ |
サードパーティーが収集したウェブ解析。毎日のページビューとイベントのプル。 データは顧客のウェブパターンを理解し、ウェブアプリケーションの使用を改善するために収集されます。 |
| 内部 | 構造化データ | コアトランザクションデータ |
リレーショナルデータベースに取り込まれた見積もり、保険証券、顧客情報における保険データ。 データは、新しいポリシーに関するメトリックと顧客体験の放棄に関するメトリックを生成するために使用されます。 |
| 内部 | 非構造化データ | アプリケーションサーバーログ |
主なアプリケーションエンティティ追跡を含むブラウザ情報を含む、Amazon CloudWatch でキャプチャされたアプリケーションサーバーイベント。 ログ分析を使用して、データがスキャンされ、ウェブアプリケーションの信頼性と可用性が向上します。 |
サンドボックス環境の構築
AWS プラットフォームコンポーネント (Amazon S3、Amazon Redshift、Neptune) を使用してサンドボックス環境を構築し、接続されたデータプラットフォームの価値実証を作成します。コマンドと手順の詳細については、AWS ドキュメントを参照してください。
環境を構築するには、以下の手順を実行します。
- 次のフォルダを使用して S3 バケット (
cjsandboxpov<アカウントの最後の 5 桁>) を作成し、既存のデータプラットフォームからのサンプルデータを保存します。- /landingarea – 4 つのソースすべてから CSV または Parquet 形式でデータを収集するためのランディングエリアフォルダ
- /neptune_vertex – グラフ頂点に関するダンプデータの CSV ロードファイルをダンプするための Neptune ロード頂点フォルダ
- /neptune_edge – グラフエッジに関するダンプデータの CSV ロードファイルをダンプする Neptune ロードエッジフォルダ
この記事では、S3 バケット名
cjsandboxpov99999を使用しています。 - すべてのセキュアバケットポリシーをデフォルトのままにします。
- VPC サンドボックス環境で Amazon Redshift クラスターを作成して、ソースデータをアップロードします。
- クラスターサイズは、生データサイズの 2 倍のデータストレージをサポートする必要があります (たとえば、最大 2 TB の生データでは、2 つのノードの ds2.xlarge クラスターを選択します)。
- Amazon Redshift の IAM ロールを関連付けて、S3 バケットの読み込みと書き込みを行います。
詳細については、IAM ロールを使用した COPY、UNLOAD、および CREATE EXTERNAL SCHEMA 操作の承認をご覧ください。
- Amazon Redshift クエリエディタを使用して Amazon Redshift データベースに接続し、サンドボックススキーマ
cjsandboxを作成して、受信ソースオブジェクトを定義します。 - Neptune クラスターを作成してグラフの属性をとらえ、ナレッジベースを構築します。
- リードレプリカのない db.r5large クラスターで最新バージョンを選択する
- データベース識別子で
cjsandboxを選択し、オプションでデフォルトを選択する - Neptune クラスターの作成を開始する
顧客体験の発見と主な状態の把握
次の図は、顧客体験におけるさまざまなパスを示しています。

住宅保険、アパート保険、または損害保険といった住宅保険には、個人が保険供給者と契約するための複数のオプションがあります。保険契約を結ぶための個々の体験は、アパートのモバイルアプリケーションを使用して単純かつ高速にすることも、さまざまな対象範囲のニーズを備えた物件の規模と場所に基づいて複雑にすることもできます。
保険会社は、潜在顧客との最初の接触に向けて複数のオプション (モバイル、ウェブ、またはコールセンター) を提供することにより、成長を続ける多様な市場をサポートしています。お客様の目標は、最高の顧客体験を提供し、顧客が課題に直面する、または問い合わせを放棄することを決めたときにすばやく支援を行うことです。
最高の顧客体験を実現するには、顧客体験の状態をできる限りすばやく取得する必要があるため、顧客がポリシーに署名することにつながる迅速な決定を行うためのオプションを提供できます。目標は、貧弱なユーザーインターフェイス体験、補償対象を選択する際の複雑さ、最適な選択肢とコストオプションの非可用性、または提供されたインターフェイスでのナビゲーションの複雑さによって顧客が保険加入を放棄する事例を減らすことです。また、企業の代表者 (営業担当者、サービス担当者、またはアプリケーション開発者) に顧客の状態と測定基準に関する最新のトレンドを提供して、顧客が適切な保険証券を購入できるように導く必要もあります。
顧客体験から、次の主な状態を把握します。
- 最初の顧客情報 – E メール、住所、電話
- コールセンターデータ – 電話、エージェント、州
- ウェブアプリケーションログ – セッション、見積もり、最新状態
- ウェブ分析ログ – 訪問、ページビュー、ページイベント
- コア体験データ – ポリシー、見積もり、顧客の放棄または拒否
顧客体験の ER 図、および頂点とエッジを含むモデルグラフのキャプチャ
顧客体験の状態を定義したら、インタラクション用にデータがキャプチャされる主要なトランザクションエンティティを特定します。既知のエンティティと関連する相互関係の ER 図を作成します。次の図は、4 つの独立した顧客ビューを示しています。

各データストアは、主なファクトテーブルで構成されています。次の表は、ファクトテーブルとそれに関連する主な属性をまとめたものです。
| データストア | テーブル | キー ID 列 | 主な属性 | 他のファクトへのリファレンス列 |
| ウェブ分析 | VISIT | VISIT_ID | 訪問時間、ブラウザ ID | アプリケーションによって生成された SESSION_ID (SESSION) |
| PAGE_VIEW | PAGE_ID | VISIT_ID、PAGE INFO | VISIT_ID から VISIT | |
| PAGE_EVENTS | EVENT_IG | PAGE_ID、EVENT_INFO | PAGE_ID から PAGE_VIEW | |
| コールデータ | CALL | CALL_ID | AGENT_ID、PHONE_NO、CALL_DETAILS |
PHONE_NO から CUSTOMER AGENT_ID から AGENT |
| AGENT | AGENT_ID | AGENT_INFO | AGENT_ID から CALL | |
| ログデータ | SESSION | SESSION_ID | QUOTE_ID、EMAIL、CUSTOMER_INFO |
QUOTE ID から QUOTE EMAIL から Customer SESSION_ID から VISIT |
| コアデータ | CUSTOMER | CUSTOMER_ID |
PHONE、EMAIL、DEMOGRAPHICS、 ADDRESS_INFO |
PHONE から CALL EMAIL から SESSION ADDRESS_ID から ADDRESS |
| ADDRESS | ADDRESS_ID | 都市、郵便番号、州、不動産の住所 | ADDRESS_ID から CUSTOMER | |
| QUOTE | QUOTE_ID |
見積もり情報、E メール、 CALL_ID、SESSION_ID |
Email から CUSTOMER CALL_ID から CALL SESSION_ID から SESSION SESSION_ID から VISIT |
|
| POLICY | POLICY_ID |
ポリシー情報、QUOTE_ID、 CUSTOMER_ID |
CUSTOMER_ID から CUSTOMER QUOTE_ID から QUOTE |
テーブルのデータとそれに関連する関係を確認したら、グラフモデルの主なエンティティの ER 図を分析します。キーテーブルの各ファクトは、CUSTOMER、ADDRESS、CALL、QUOTE、SESSION、VISIT、PAGE_VIEW、および PAGE EVENT などの主な頂点からのソースとして機能します。他の主なエンティティを頂点として識別します。頂点は、PHONE や ZIP などの異なるエンティティを接続するための主な属性です。テーブル間の関係を参照して、頂点間のエッジを特定します。次のグラフモデルは、特定された頂点とエッジに基づいています。

次の重要なステップは、Neptune Tinkerpop プロパティグラフの要件をサポートするグラフモデルを設計することです。Neptune データベースには、その頂点エンティティとエッジエンティティのそれぞれに一意の ID が必要です。エンティティのプレフィックス値と現在の一意のビジネス識別子を組み合わせて ID を生成できます。次の表は、Neptune データベースの一意の ID を作成するために使用される頂点およびエッジの命名基準の例をいくつか示しています。頂点エンティティは、データベースの一意の識別子と連結された 3 文字の頭字語に関連付けられています。エッジ名は、2 つの頂点間の 1 対多関係を記述するエッジ <from vertex>_<to_vertex_code>_<child unique id> の方向によって導出されます。プライマリキーの値はエンティティごとに一意であるため、プレフィックスと連結すると、Neptune データベース全体で値が一意になります。
| エンティティ | エンティティタイプ | ID 形式 | サンプル ID |
| 顧客 | 頂点 | CUS|| <CUSTOMER_ID> | CUS12345789 |
| セッション | 頂点 | SES||<SESSION_ID> | SES12345678 |
| 見積もり | 頂点 | QTE||<QUOTE_ID> | QTE12345678 |
| VISIT | 頂点 | GAV||<VISIT_ID> | GAEabcderfgtg |
| PAGE VIEW | 頂点 | GAP||<PAGE_ID> | GAPadbcdefgh |
| PAGE EVENT | 頂点 | GAE||<PAGE_EVENT_ID> | GAEabcdefight |
| ADDRESS | 頂点 | ADD||<ADDRESS_ID> | ADD123344555 |
| CALL | 頂点 | CLL||<CALL_ID> | CLL45467890 |
| AGENT | 頂点 | AGT||<AGENT_ID> | AGT12345467 |
| PHONE | 頂点 | PHN||<PHONEID> | PHN7035551212 |
| ZIP | 頂点 | ZIP||<ZIPCODE> | ZIP20191 |
|
Customer->Session (1 -> 多数) |
エッジ | CUS_SES||<SESSION_ID> | CUS_SESS12345678 |
|
Session-> Customer (多数 -> 1) |
エッジ | SES_CUS||<SESSION_ID> | SES_CUST12345678 |
|
ZIP->ADDRESS (1 -> 多数) |
エッジ | ZIP_ADD||<ADDRESS_ID> | ZIP_ADD1234567 |
|
ADDRESS-> ZIP 多数 -> 1) |
エッジ | ADD_ZIP||<ADDRESS_ID> | ADD_ZIP1234567 |
Amazon Redshift の関係用にキュレーションされたデータを分析する
Amazon Redshift は、大量のデータのデータパターンを確認するための超並列処理 (MPP) プラットフォームを提供します。AWS Glue などの他のプログラミングオプションを使用して、Amazon S3 でキュレートされたデータレイクに保存されているデータ用の Neptune 一括ロードファイルを作成できます。ただし、Amazon Redshift は、データパターンを分析して異種のソース間の接続を見つけるデータベースプラットフォームと、一括ロードファイルを生成する SQL インターフェイスを提供します。データベース中心のアナリストには SQL インターフェイスが推奨され、PySpark ベースのライブラリを構築するための学習曲線を回避します。この記事では、データストアのキュレーションされたデータが、CSV または Parquet 形式で Amazon S3 ベースのデータレイクに公開されていると想定しています。COPY コマンドを使用して、データレイク内のキュレートされたデータを Amazon Redshift データベースにロードできます。
サンドボックススキーマに顧客テーブルを作成するには、次のコードを入力します。
Amazon S3 から顧客テーブルにデータをコピーするには、次のコードを入力します。
頂点とエッジのダンプファイルを Amazon S3 にダンプする
Neptune データベースは、CSV ファイルを使用した一括ロードをサポートしています。各ファイルにはヘッダーレコードが必要です。頂点ファイルには、必要に応じて頂点 ID 属性とラベル属性が必要です。残りのプロパティ属性は、ヘッダーでの各属性の属性形式を指定する必要があります。エッジダンプファイルには、頂点 ID から頂点 ID までの ID、および必須属性としてのラベルが必要です。エッジデータは、追加のプロパティ属性を持つことができます。
次のコードは、セッション頂点ダンプレコードのサンプルです。
次のコードは、セッション見積もりエッジダンプレコードのサンプルです。
すべての関連データは Amazon Redshift に存在するため、ビュー定義を使用して、Neptune 一括ロード用ダンプファイルの作成を簡略化できます。ビュー定義は、ヘッダーレコードが常にダンプファイルの最初のレコードであることを確認します。ただし、Amazon S3 へのダンプファイルの作成にはいくつかの制限があります。
- 列の
NULL値は、文字列全体を null にします。ビューはNVL関数を使用して、属性の 1 つがNULLの場合に頂点をスキップするという課題を回避します。 - 属性データ内のカンマまたは他の一意の文字は、ダンプファイルのデータ形式を無効にします。ビューは
replace関数を使用して、データストリームにあるこれらの文字を抑制します。 unloadコマンドには、単一のダンプファイルを作成するための 6 GB の制限があります。オーバーフローファイルにはヘッダーレコードがないため、Neptune の読み込み形式が無効になります。ビューを使用すれば、キー列でデータを並べ替えてチャンクでデータをアンロードできます。各チャンクには Neptune 形式のヘッダーがあります。
次のコード例は、頂点ソースビュー向けのビュー定義です。
次のコード例は、エッジソースビュー向けのビュー定義です。
頂点およびエッジダンプファイルを作成するには、Amazon Redshift で UNLOAD コマンドを使用します。次のコードを参照してください。
頂点とエッジのダンプファイルを Neptune データベースにロードする
頂点ダンプファイルとエッジダンプファイルが、2 つの異なる Amazon S3 フォルダに作成されます。頂点ダンプファイルは、最初にエッジとしてロードされます。これには、エッジがデータベースに存在するための from および to が必要です。ファイルは一度に 1 つずつ、またはフォルダをロードできます。次のコードは Neptune のロードコマンドです。
ロードジョブは、ジョブごとに異なるローダー ID を作成します。ローダー ID を変数として wget コマンドに渡すことにより、ロードジョブの進行状況をモニタリングできます。
ロードステータスの状態を確認するには、次のコードを入力します。
エラーのあるロードステータスを確認するには、次のコードを入力します。
接続されたデータベースの価値実証の実行
ビジネス成果に対応するには、実装した新しいソリューションの価値を検証する必要があります。接続された Neptune データベースは、カスタマーサービス担当者の全体像を作成できるようになりました。この記事には、接続されたデータの顧客 360 をエンドユーザーと共有する方法について説明する Python コードの例が含まれています。次の手順を実行します。
- E メールなどの顧客 ID を使用して、開始頂点を特定します。たとえば、次のコードは Gremlin クエリです。
- 顧客の頂点に接続されている住所の頂点に移動し、関連するすべての住所情報を取得します。たとえば、次のコードを参照してください。
- すべての電話の頂点に移動し、すべての通話データを時系列でキャプチャします。
- セッションおよびウェブ分析の訪問に移動して、すべてのウェブアクティビティをキャプチャします。
- 関連する見積もりに移動し、保険選択のパターンを確認します。
- 現在の顧客状態を特定します。
顧客データ用に接続されたユニバースの視覚化は、Neptune グラフデータベースに最大の価値を与えます。グラフを分析して、新しいデータセットとデータパターンを見つけることができます。次に、これらの新しいパターンを ML の入力として使用して、顧客体験の最適化を支援できます。グラフデータベースは、ML モデルを構築するためのシードデータのデータパターンを理解するための発見時間を短縮します。
グラフデータベースのグラフィカルブラウザインターフェイスを使用して、さまざまなエンティティ間の接続を探索できます。ほとんどのグラフブラウザでは [近辺を表示] オプションを使用すると、顧客がたどるさまざまな経路を追うことができます。次の手順を実行します。
- 顧客の頂点を取得するための gremlin クエリから始めます。
- 関連する電話、住所、ウェブセッション、および見積もりを表示するには、顧客の頂点の [近辺を表示] を選択します。
- セッションのすべての訪問を表示するには、セッションの [近辺を表示] を選択します。
- 顧客に関連付けられているすべての通話を表示するには、電話の [近辺を表示] を選択します。
- 見積もりに関連付けられているすべてのポリシーを表示するには、見積もりの [近辺を表示] を選択します。
- 関連するすべてのページビューを表示するには、訪問の [近辺を表示] を選択します。

接続された顧客体験ビューを使用して、ユーザーインターフェイス (モバイルまたはウェブ) を拡張し、人口統計 (ワンクリック保険) で最も広く選択されたオプションを使用してデフォルトのカバレッジオプションを設定できます。郵便番号または都市の場合、グラフをトラバースするときに、顧客および関連する見積もりとポリシーを特定して、顧客が満足した控除額と補償範囲のパターンを特定できます。放棄分析の場合、ポリシーのない見積もりを選択してウェブ分析に移動し、複雑なユーザーインターフェイスのせいで顧客が放棄するようトリガーするフォームまたはイベントを見つけることができます。コールセンターへの通話量を減らすには、グラフをトラバースして、顧客への通話をトリガーするイベントの傾向をとらえます。
データレイクと Neptune の統合
接続されたデータの価値を引き出した後、接続された Neptune データベースを含めるように毎日のデータパイプラインを拡張できます。データをキュレートしてデータレイクに公開した後、接続されたデータを収集して、新しい頂点、エッジ、プロパティを追加できます。AWS Glue ジョブをトリガーして、新しい顧客をキャプチャし、新しいアプリケーションセッションを顧客に接続し、増分ウェブ分析データをセッションおよび顧客情報と統合できます。この記事には、頂点とエッジを維持するための AWS Glue ジョブの例が含まれています。
キュレートされた新規データファクトを公開した後、AWS Lambda 関数をトリガーして AWS Glue ジョブを開始し、追加または変更された最新のエンティティをキャプチャします。さらに、それらの依存データが既に公開されていることを確認してから、頂点、エッジ、またはプロパティ情報を追加または変更します。たとえば、新しいセッションデータがデータレイクのキュレートされた領域に達したら、ジョブを開始して、顧客のセッション関連エンティティを Neptune データベースに追加します。
コード例
次のコード例は、Python と Gremlin を使用する顧客 360 向けとなります。
次のコード例は、増分データがキュレートされると Neptune CSV ファイルを作成する AWS Glue プログラムです。
まとめ
Neptune を使用して、顧客 360 ソリューションのエンタープライズナレッジベースを構築し、顧客状態のダッシュボード、拡張分析、オンライン推奨エンジン、コホートトレンド分析の異種データソースを接続できます。
Neptune データベースを備えた顧客 360 ソリューションには、次の利点があります。
- 顧客がほぼリアルタイムで経験するすべてのアクティビティへのアクセス。グラフをトラバースして、顧客をより良くサポートできます。
- 人口統計、場所、および好みに基づいて、同様のコホート設定に基づいたフィードバックを使用して、顧客が支援する推奨エンジンを構築する機能
- 現在の市場での課題と新しい市場での機会について把握するための地理と人口統計に基づくセグメンテーション分析
- ビジネスに影響を与えるファクトをトリアージするために近辺をたどることによって課題を絞り込むビジネスケース分析
- 顧客体験を改善するための新しいアプリケーションの導入効果におけるテストと検証
このソリューションは、車両やアカウントなどの同様のナレッジベースに適用できます。たとえば、車両 360 ナレッジベースは、事前販売、ディーラーインタラクション、定期メンテナンス、保証、リコール、および再販から自動車顧客の体験を追跡して、車両において最良のインセンティブ値を計算できます。
著者について

Ram Bhandarkar は、AWS プロフェッショナルサービスのシニアデータアーキテクトです。Ram は、大規模な AWS データプラットフォーム (Data Lake、NoSQL、Amazon Redshift) の設計とデプロイを専門としています。彼はまた、従来の大規模な Oracle データベースと DW プラットフォームを AWS クラウドに移行するよう支援します。