Amazon Web Services ブログ
機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築する
このブログ記事では、Amazon Translate、Amazon Comprehend、Amazon Kinesis、Amazon Athena、Amazon QuickSight を使用して、自然言語処理 (NLP) を採用した、ツイートのソーシャルメディアダッシュボードの構築方法をご案内します。
各企業がお客様とソーシャルメディアでやりとりすることで、ブランドの認知度が高まります。ツイートによる情報の拡散は、それほどコストがかからないにもかかわらず、お客様候補を獲得し、ウェブサイトのトラフィックを増やし、お客様との関係を構築し、顧客サービスを改善するのに役立ちます。
このブログ記事では、サーバーレスのデータ処理と機械学習 (ML) パイプラインを構築し、Amazon QuickSight でツイートの多言語ソーシャルメディアダッシュボードを提供する方法を紹介します。API 駆動型 ML サービスを活用すると、可用性が高くスケーラブルでセキュアなエンドポイントを呼び出すだけで、開発者はインテリジェンスをコンピュータビジョン、音声、言語分析、およびチャットボット機能など、あらゆるアプリケーションに簡単に追加できるようになります。これらの構築ブロックは、AWS のサーバーレス製品を活用することで、ごくわずかなコードで構成できます。このブログ記事では、システムを通じてのツイートフローに、言語翻訳と自然言語処理を行っていきます。
ソーシャルメディアダッシュボードを構築するだけでなく、生データセットとエンリッチなデータセットの両方をキャプチャし、データレイクに永続的に格納できます。データアナリストは、このデータで新しいタイプの分析や機械学習をすばやく簡単に実行できます。

このブログ記事を通じて、以下のことをどのように行うことができるかをご案内します。
- Amazon Kinesis Data Firehose を活用すると、リアルタイムのデータストリームを容易にキャプチャおよび準備して、データストア、データウェアハウス、データレイクに読み込むことができます。この例では、Amazon S3 を使用します。
- AWS Lambda をトリガーして、AWS の完全に管理された 2 つのサービス、Amazon Translate と Amazon Comprehend を使用してツイートを分析します。これらのサービスでは、ほんの数行のコードだけで、言語間の翻訳が可能となり、ツイートの自然言語処理 (NLP) を実行できます。
- Amazon Kinesis Data Firehose の個別の Kinesis データ配信ストリームを利用して、分析されたデータをデータレイクに書き戻します。
- Amazon Athena を利用して、Amazon S3 に格納されたデータのクエリを実行します。
- Amazon QuickSight を使用して、ダッシュボードのセットを構築します。
以下の図は、インジェスト (青) とクエリ (オレンジ) フローの両方を示しています。

注意: このブログ記事の時点では、Amazon Translate はまだプレビュー中です。生産ワークロードでは、Amazon Translate が一般的に利用可能になるまで、Amazon Comprehend の多言語機能を使用します (GA)。
このアーキテクチャを構築する
AWS Lambda の Amazon S3 通知 (青い点線) を除く、前の図に示されているすべてのインジェストコンポーネントを作成する AWS CloudFormation テンプレートが提供されています。
AWS Management Console で、CloudFormation Template を起動します。
![]()
これにより、CloudFormation スタックが us-east-1 Region に以下の設定で自動的に起動します。
| 入力 | 値 |
| リージョン | us-east-1 |
| CFN テンプレート: | https://s3.amazonaws.com/serverless-analytics/SocialMediaAnalytics-blog/deploy.yaml |
| スタックの名前: | SocialMediaAnalyticsBlogPost |
以下の必須パラメータを指定します。
| パラメータ | 説明 |
| InstanceKeyName | Twitter のストリーミングインスタンスに接続するために使用される KeyPair |
| TwitterAuthAccessToken | Twitter Account アクセストークン |
| TwitterAuthAccessTokenSecret | Twitter Account アクセストークンシークレット |
| TwitterConsumerKey | Twitter Account コンシューマキー (API キー) |
| TwitterConsumerKeySecret | Twitter Account コンシューマーシークレット (API シークレット) |
Twitter でアプリを作成する必要があります。コンシューマーキー (APIキー)、コンシューマーシークレットキー (APIシークレット)、アクセストークン、およびアクセストークンシークレットを作成し、CloudFormation スタックのパラメーターとして使用します。このリンクを使用して作成できます。
さらに、Twitter ストリーミング API からプルされるタームや言語を変更することができます。この Lambda 実装は、各ツイートに Comprehend を呼び出します。秒単位で数十または数百のツイートを取得できるようにタームを変更する場合は、バッチ呼び出しを実行するか、AWS Glue を利用してバッチ処理とストリーム処理を実行するためのトリガーを参照してください。
注意:このブログ記事の時点では、Amazon Translate はまだプレビュー中です。Amazon Translate にアクセスできない場合は、en (English) の値のみを含んでください。

注意:このブログのコードは、Twitter で使用されている言語コードが Amazon Translate と Comprehend で使用されている言語コードと同じであることを前提としています。コードは簡単に拡張できますが、新しいラベルを追加する場合は、この前提が満たされていることを確認してください。(AWS Lambda コードも更新しない限りにおいて。)
CloudFormation コンソールで、AWS CloudFormation が IAM リソースとカスタム名でリソースを作成することを許可するチェックボックスをオンにできます。CloudFormation テンプレートは、サーバーレス変換を使用します。[Create Change Set (変更セットの作成)] を選択し、変換が追加するリソースを確認して、[Execute (実行)] を選択します。
CloudFormation スタックが起動したら、完了するまで待ちます。

起動が終了すると、このブログ記事全体で使用する出力のセットが表示されます。

S3 通知をセットアップする – 新しいツイートで Amazon Translate/Comprehend を呼び出す:
CloudFormation スタックの起動が完了したら、ダイレクトリンクと情報の出力タブに進みます。次に、LambdaFunctionConsoleURL リンクをクリックして、Lambda 関数に直接起動します。
Lambda 関数が Amazon Translate と Amazon Comprehend を呼び出し、ツイートの言語変換と自然言語処理 (NLP) を実行します。この関数は、Amazon Kinesis を使用して、分析されたデータを Amazon S3 に書き込みます。

この大部分は、CloudFormation スタックですでにセットアップされていますが、新しいツイートが S3 に書き込まれたときに Lambda 関数が呼び出されるように、S3 を追加できるようにします:
- [Add Triggers (トリガの追加)] で、S3 トリガを選択します。
- 次に、CloudFormation で 「raw /」のプレフィックスに作成された新しい S3 バケットのトリガーを設定します。イベントタイプは、[Object Created (All)] にしてください。
最小権限パターンに従って、Lambda 関数が割り当てられている IAM ロールは、CloudFormation テンプレートが作成した S3 バケットにのみアクセスできます。
以下の図に例を示します。

残りのコードを調べるのに少し時間がかかります。数行のコードで、Amazon Translate を呼び出して、アラビア語、ポルトガル語、スペイン語、フランス語、ドイツ語、英語、およびその他の多数の言語間の変換を行うことができます。
Amazon Comprehend を使用して、自然言語処理をアプリケーションに追加する場合も同じです。Lambda 関数内でツイートのセンチメント分析とエンティティ抽出をとても簡単に実行できるようにしたことに注目してください。
Twitter stream producer を開始する
この例では、Kinesis Data Firehose からの実際のインジェストフローの外部にある、単一のサーバーを使用しました。これは、Twitter からツイートを収集して、Kinesis Data Firehose にプッシュするのに使用されました。今後の記事で、このコンポーネントをサーバーレスにどのように移行できるかについてもご案内します。
SSH を使用して、CloudFormation スタックで作成した Amazon Linux EC2 インスタンスに接続します。
CloudFormation スタック出力の一部には、多くのシステムでインスタンスに接続するために使用できる SSH スタイルのコマンドが含まれています。
注意: Windows または Mac/Linux マシンからの接続方法の詳細については、Amazon EC2 のドキュメントを参照してください。
以下のコマンドを実行します。
これで、ツイートのフローが開始されます。フローを実行し続けたい場合は、バックグラウンドジョブとして実行できます。簡単なテストのために、SSH トンネルを開いたままにしておくこともできます。
数分後に、作成された CloudFormation テンプレート S3 バケットで各種のデータセットを確認できるようになります。

注意 (3つのプレフィックスがすべて表示されない場合): データが表示されない場合は、Twitter リーダーが正しく読み込みを行い、エラーが発生していないことを確認してください。raw プレフィックスのみが表示され、その他は表示されない場合、S3 トリガが Lambda 関数にセットアップされていることを確認してください。
Athena テーブルを作成する
Amazon Athena テーブルを手動で作成していきます。これは、データレイクアーキテクチャで AWS Glue のクロール機能を活用する最適な機会です。クローラは、Amazon S3 (ならびにリレーショナルデータベースとデータウェアハウス) に存在する異なるデータセットのデータフォーマットとデータタイプを自動的に検出します。詳細については、Crawlers with AWS Glue のドキュメントをご覧ください。
Athena で以下のコマンドを実行して、Athena データベースとテーブルを作成します。
これにより、新しいデータベースが Athena に作成されます。
以下のステートメントを実行します。
重要: <TwitterRawLocation> を CloudFormation スクリプトの出力として表示するものに置き換えてください。
これで、ツイートテーブルが作成されます。次に、同じようにエンティティとセンチメントテーブルを作成します。これらの両方を、CloudFormation 出力にリストされている実際のパスで更新することが重要です。
まずこのコマンドを実行して、以下の例で強調表示されているパスを置き換えて、エンティティテーブルを作成します。
これで、このコマンドを実行して、センチメントテーブルを作成できます。
これらの4つのステートメントを実行し、create table ステートメントの場所を置き換えたら、ドロップダウンリストで socialanalyticsblog データベースを選択して、3つのテーブルを表示できるようになります。

収集しているデータを調べるために、クエリを実行できます。まずテーブルを見てみましょう。
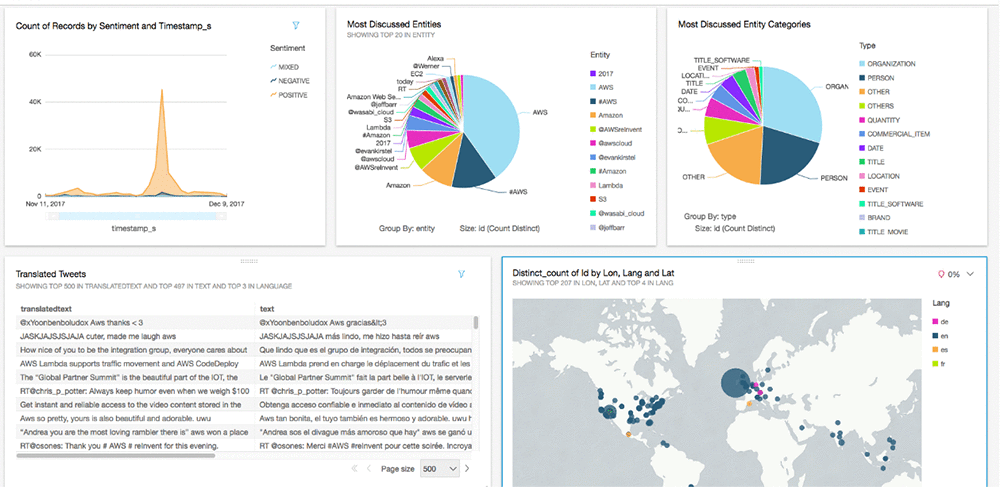
20 個のツイートのサンプルを見てみましょう:
一番上のエンティティタイプをプルします:

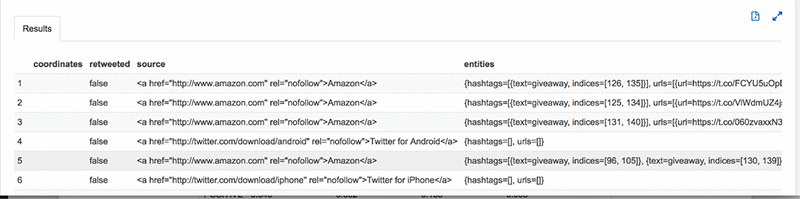
上位 20個 のコマーシャルアイテムをプルできます:

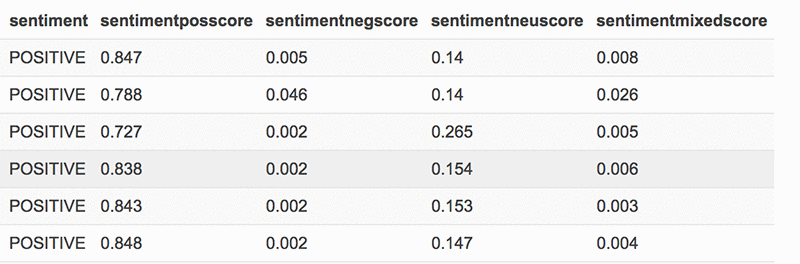
20 個のポジティブツイートをプルして、センチメント分析から、それぞれのスコアを見てみましょう:
翻訳詳細のクエリを開始することもできます。靴をドイツ語で何というのか知らなくても、以下のクエリを簡単に実行できます:
翻訳されたテキストに基づいて、靴について語られているツイートが結果に表示されます:

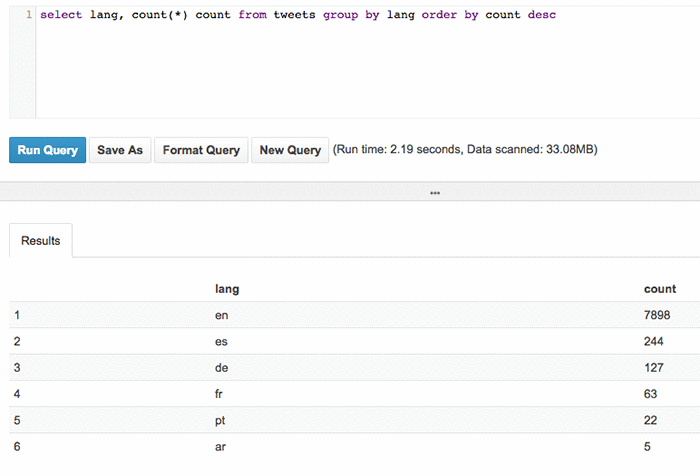
Kindle が NLP を通じて抽出した英語以外のツイートも見てみましょう:
注意: 技術的には、データベースが Athena で選択されている場合は、完全な修飾テーブル名を使用する必要はありませんが、最初に socialanalyticsblog データベースを選択しなかった場合に発生する問題を制限するためにあえて使用しました。
QuickSight ダッシュボードを構築する
- QuickSight を起動します – https://us-east-1.quicksight.thinkwithwp.com/sn/start。
- 右上の [Manage data (データの管理)] を選択します。
- [New Data Set (新規データセット)] を選択します。
- 新しい Athena Data Source を作成します。
- 「Socialanalyticsblog」データベースと 「tweet_sentiments」テーブルを選択します。
- 次に、[Edit/Preview Data (データの編集/プレビュー)] を選択します。

- テーブルで [Switch to custom SQL tool (カスタム SQL ツールに切り替え)] を選択します。

- クエリに名前を付けます (「SocialAnalyticsBlogQuery」など)。
- 以下のクエリにプットします。
- 次に、[Finish (完了)] を選択します。
- これで、クエリが保存され、サンプルデータを表示できます。
- timestamp_in_seconds のデータタイプを日付に切り替えます。

- 次に、[Save and Visualize (保存して視覚化)] を選択します。
これで、ダッシュボードを簡単に作成できます。
注意: カスタムクエリを作成した方法で、別個の tweetid を値としてカウントできます。
ダッシュボードを作成する手順を説明します。
- まず最初のビジュアルを、ディスプレイの左上クワドラントに作成します。

- ビジュアルタイプを選択して、フィールドリストから [tweetids] を選択します。
- [Field Well] の右横にある二重矢印ドロップダウンを選択します。

- tweetid を値に移動します。
- 次に、Count Distinct を実行するように選択します。

- ビジュアルタイプで、円グラフに切り替えます。

別のビジュアルを追加してみましょう。
- [Add (追加)] (ページの左上) を選択します:ビジュアルを追加します。
- サイズを変更して、最初の円グラフの横に移動させます。

- ここで、timestamp_in_seconds センチメントを選択します。
- [Field wells] または図の上で、時間のズームイン/アウトができます。時間をズームインしてみましょう:

- タイムラインで、ポジティブ/ネガティブ/ミックスのセンチメントのみを表示してみます。私の Twitter タームでは、ニュートラルラインの残り部分が見えにくくなっています。

- ニュートラルラインをクリックしてボックスを表示して、[Exclude Neutral (ニュートラルを除外)] を選択します。


もうひとつのビジュアルをこの分析に追加して、翻訳されたツイートを表示してみましょう。
- [Add(追加)] で、[Add Visual (ビジュアルを追加)] を選択します。
- スペースの下半分に収まるように、サイズを変更します。
- [Table View (テーブルビュー)] を選択します。

- 以下を選択します:
- language (言語)
- text (テキスト)
- originalText (元のテキスト)
- 次に、左側で [Filter (フィルター)] を選択します。

- ひとつの言語を作成します。
- 次に、[Custom filter (カスタムフィルター)]、[Does not equal (同じでない)] を選択し、en の値を入力します。

注意: 最後の列を表示するには、ご使用の画面解像度に基づいて、テーブルビューで列幅の調整が必要な場合があります。
これで、エンティティ、経時センチメント、および翻訳されたツイートのサイズを変更して表示できます。

複数のダッシュボードを構築して、ズームイン/アウトして、別の方法でデータを表示することができます。たとえば、センチメントの地理空間図は、以下のように表示されます。
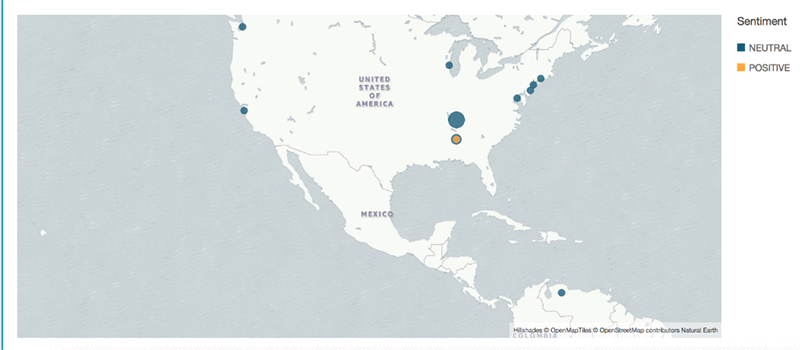
このダッシュボードを展開して、以下のような分析を構築できます:

シャットダウン
作成したリソースは、以下の手順に従って削除できます。
- Twitter ストリームリーダーを停止します (実行中の場合)。
- CTRL-C キーを押すか、バックグラウンドで起動している場合は終了させます。
- CloudFormation テンプレートで作成した S3 バケットを削除します。
- Athena テーブルデータベース (socialanalyticsblog) を削除します。
- テーブル (socialanalyticsblog.tweets) を削除します。
- テーブル (socialanalyticsblog.tweet_entities) を削除します
- テーブル (socialanayticsblog.tweet_sentiments) を削除します。
- データベース (socialanalyticsblog) を削除します。
- CloudFormation スタックを削除します (スタックを削除する前に、S3 バケットが空であることを確認してください)。
まとめ
Amazon Kinesis で開始する処理、分析、機械学習のパイプライン、Amazon Translate でデータ分析してツイートを言語間で翻訳、Amazon Comprehend を使用してセンチメント分析を実行、QuickSight でダッシュボードを作成するなど、すべてをサーバーをスピンアップせずに構築できました。
高度な機械学習 (ML) サービスをフローに追加し、AWS Lambda でいくつかの簡単な呼び出しを通じて、Amazon QuickSight で多言語分析ダッシュボードを構築しました。また、すべてのデータを Amazon S3 に保存しているので、必要であれば、Amazon EMR、Amazon SageMaker、Amazon Elasticsearch Service やその他の AWS サービスを使用して、他の分析をデータに行うことができます。
Twitter の Firehose を読み取る Amazon EC2 インスタンスを実行する代わりに、AWS Fargate を利用して、コードをコンテナとしてデプロイすることができました。AWS Fargate は、Amazon Elastic Container Service (ECS) と Amazon Elastic Container Service for Kubernetes (EKS) のためのテクノロジーで、サーバーやクラスターを管理しなくてもコンテナを実行できます。AWS Fargate を使用すると、コンテナを実行するために仮想マシンのクラスターをプロビジョニング、構成、およびスケーリングする必要はありせん。これにより、サーバーのタイプを選択したり、クラスターのスケーリングをいつ行うのかを決めたり、クラスターのパッキングを最適化する必要がなくなります。AWS Fargate は、サーバーやクラスターについてやり取りしたり考える必要性をなくします。AWS Fargate を使用すれば、アプリケーションを実行するインフラストラクチャを管理する必要はなく、その代わりに、アプリケーションの設計と構築に専念することができます。
今回のブログの投稿者について
 Ben Snivelyはパブリック・セクター・スペシャリスト・ソリューション・アーキテクトです。 彼は、政府機関、非営利団体、教育機関のお客様のビッグデータや分析プロジェクトに協力して、AWS を使用するソリューションの構築を支援しています。趣味は、家中に IoT センサーを追加して、その分析を実行することです。
Ben Snivelyはパブリック・セクター・スペシャリスト・ソリューション・アーキテクトです。 彼は、政府機関、非営利団体、教育機関のお客様のビッグデータや分析プロジェクトに協力して、AWS を使用するソリューションの構築を支援しています。趣味は、家中に IoT センサーを追加して、その分析を実行することです。
 Viral Desai は、AWS のソリューションアーキテクトです。 お客様がクラウドで成功することを支援する、アーキテクチャ・ガイダンスを行っています。趣味は、テニスと家族たちと一緒に時間を過ごすことです。
Viral Desai は、AWS のソリューションアーキテクトです。 お客様がクラウドで成功することを支援する、アーキテクチャ・ガイダンスを行っています。趣味は、テニスと家族たちと一緒に時間を過ごすことです。