Amazon Web Services ブログ
Amazon SageMakerを使ってノーコードでリスクマネジメントに機械学習を適用する
この記事は Build a risk management machine learning workflow on Amazon SageMaker with no code (記事公開日: 2022 年 5 月 19 日) を翻訳し、一部内容を追加したものです。
背景
世界範囲の金融危機以来、リスク管理は、潜在顧客のローン返済状況の予測など、銀行の意思決定を形作る上で大きな役割を果たしてきました。これは多くの場合、機械学習 (ML) を必要としますが、すべての組織がリスク管理 MLワークフローを構築するためのデータサイエンス部隊と専門知識を持っているわけではありません。
Amazon SageMakerは、データエンジニアやビジネスアナリストがMLモデルを迅速かつ簡単に構築、トレーニング、デプロイできるようにする、完全マネージド型のMLプラットフォームです。データエンジニアとビジネスアナリストは、SageMakerのノーコード/ローコード機能を使用してコラボレーションできます。データエンジニアは、Amazon SageMaker Data Wranglerを使用して、コードを記述することなくモデル構築用のデータを迅速に集約して準備できます。その後、ビジネスアナリストは、Amazon SageMaker Canvasの視覚的なインターフェイスを使用して、正確なML予測を独自に生成できます。Canvasで生成されたMLモデルはSageMaker Studioと連携し、データサイエンティストに渡すこともできます。
この投稿では、データエンジニア、ビジネスアナリストが協力して、データの準備、モデルの構築、推論を含むMLワークフローをコードを書かずに構築することがいかに簡単かを示します。
ソリューション
ML開発は複雑で反復的なプロセスですが、MLワークフローをデータ準備、モデル開発、およびモデル デプロイの段階に一般化できます。

Data WranglerとCanvas は、データ準備とモデル開発の複雑さを抽象化するため、コード開発の専門家でなくてもデータからインサイトを引き出すことで、ビジネスに価値を提供することに集中できる、ノーコードやローコードのソリューションです。

Amazon Simple Storage Service (Amazon S3) は、生データ、特徴量データ、機械学習モデルアーティファクトのデータのリポジトリとして機能します。Amazon Redshift、Amazon Athena、Databricks、Snowflakeからデータをインポートすることもできます.
データサイエンティフィックとして、探索的なデータ分析と特徴量エンジニアリングにData Wranglerを使用します。Canvasは特徴量エンジニアリングタスクを実行できますが、特徴量エンジニアリングは通常、データセットをモデル開発に適した形式に充実させるために、ある程度の統計および専門知識を必要とします。Data Wranglerを使用してコードを記述せずにデータを変換できるように、データエンジニアにこの仕事を任せます。
データ準備後、モデル構築はデータアナリストの仕事になります。データアナリストは、コードを記述せずにCanvasを使用してモデルをトレーニングできます。
最後に、モデルエンドポイントを自分でデプロイすることなく、結果のモデルから直接 Canvas 内で単一予測とバッチ予測を行います。
データセット
SageMakerの機能を使用して、Lending Clubの公開されているローン分析データセットの修正版を使用して、ローンのステータス(返済済みか、デフォルトかなど)を予測します。データセットには、2007 年から 2011 年までに発行されたローンのデータが含まれています。 ローンと借り手を説明する列はこれから利用する特徴量になります。列loan_statusは、予測するターゲット変数です。
データセットは2つの CSVファイルで構成されます: パート 1とパート 2。このデモを簡素化するために、Lending Clubの元のデータセットからいくつかの列を削除しました。説明したように、データセットには37,000を超える行と21の特徴列が含まれています。
| 列名 | 説明 |
loan_status |
ローンの現在のステータス (ターゲット変数)。 |
loan_amount |
借り手が申請したローンの金額。ある時点で信用部門が融資額を減額すると、それがこの値に反映される。 |
funded_amount_by_investors |
その時点でそのローンに対して投資家がコミットした合計金額。 |
term |
ローンの支払い回数。値は月単位で、36 または 60 のいずれか。 |
interest_rate |
ローンの金利。 |
installment |
ローンが発生した場合に借り手が負う月々の支払い。 |
grade |
LC が割り当てたローングレード。 |
sub_grade |
LC が割り当てたローンのサブグレード。 |
employment_length |
雇用期間 (年数)。0から10までの値が指定可能で、1年未満は0、10年以上は10となる。 |
home_ownership |
登録時に借り手によって提供された住宅所有状況。値は、賃貸(RENT)、所有(OWN)、抵当権付き住宅ローン(MORTGAGE)、その他(OTHER)。 |
annual_income |
登録時に借り手が提供した自己申告の年収。 |
verification_status |
収入が LC によって確認されたか、確認されていないか、または収入源が確認されたかを示す。 |
issued_on |
ローンが資金提供された月。 |
purpose |
貸出依頼に対して借り手が提供するカテゴリ。 |
dti |
住宅ローンと要求された LC ローンを除く債務総額に対する借り手の毎月の債務支払い総額を、借り手の自己申告月収で割って計算した比率。 |
earliest_credit_line |
借り手の最も早い報告されたクレジットサービスを利用した日付。 |
inquiries_last_6_months |
過去 6 か月の問い合わせ数 (自動車および住宅ローンの問い合わせを除く)。 |
open_credit_lines |
現在利用中のクレジットサービスの数。 |
derogatory_public_records |
公的記録に記録された信用違反の数。 |
revolving_line_utilization_rate |
リボ払いの利用率、もしくは借り手が利用可能なクレジット金額に対するリボ払いクレジット金額の比率。 |
total_credit_lines |
利用したのクレジットサービスの合計数。 |
事前準備
次の事前準備の手順を完了します。
- 二つのローンファイルを選択した S3 バケットにアップロードします。
- 必要なアクセス許可があることを確認します. 詳細については、Data Wranglerの使用開始を参照してください。
- Data Wrangler を使用するように構成された SageMakerドメインをセットアップします。手順については、Amazon SageMaker ドメインへのオンボードを参照してください。
データのインポート
Amazon SageMaker StudioのUI画面 からData Wranglerデータフローを作成します 。

データセットを配置した S3バケットから CSVファイルを選択して、Amazon S3からデータをインポートします。両方のファイルをインポートすると、データフロービューに 2 つ別々のワークフローが表示されます。
Data Wranglerフローでデータをインポートするときに、いくつかのサンプリングオプションを選択できます。サンプリングは、データセット内のデータ特徴を維持し、データセット (Data Flow) が大きすぎてインテラクティブにデータの前処理ができない場合に役立ちます。今回のデータセットが小さいため、サンプリングは使用しません。
データの準備
このユースケースでは、共通の列idを持つ2つのデータセットがあります。データ準備の最初のステップとして、これらのファイルを結合します。手順については、データの変換をご参照ください。

結合データ変換ステップを使用し、id列で内部結合 (Inner Join) を使用します。

結合変換の結果として、Data Wrangler はid_0とid_1の 2 つの追加列を作成します。ただし、これらの列はモデル構築の目的には不要です。列の管理変換ステップを使用して、これらの列を削除します。
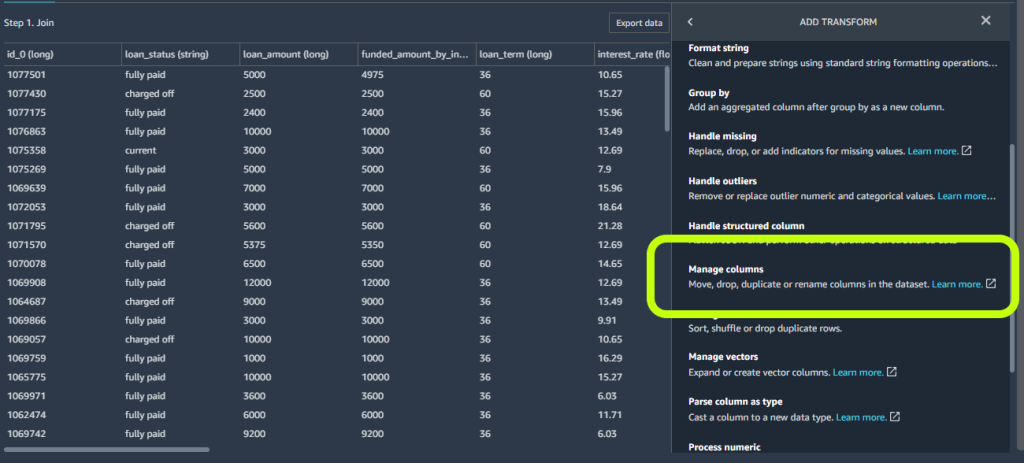
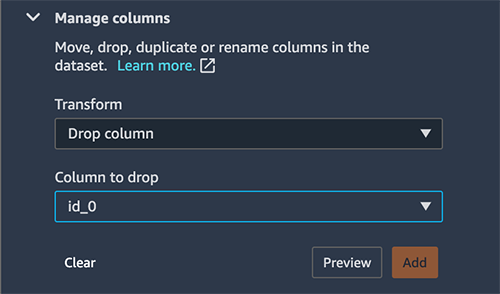
データセットをインポートして結合し、不要な列を削除したので、特徴量エンジニアリングとモデル構築の準備が整いました。
特徴量エンジニアリング
データの準備には Data Wranglerを使用しました。Data Wranglerのデータ品質とインサイトレポート機能を使用して、データの品質を検証し、データの異常を検出することもできます。多くの場合、データサイエンティストは、適切な業界専門の知識を効率的に適用するために、これらのデータ洞察機能を使用する必要があります。この投稿では、これらの品質評価を完了し、特徴量エンジニアリングに進むことができると想定しています。
これからの手順では、数値列、カテゴリ列、およびテキスト列にいくつかの変換を適用します。
最初に金利を正規化し、値を0~1の範囲でスケーリングします。これは、数値変換プロセス (Process numeric) を使用して実行し、最小-最大スケーラー (min-max scaler) を使用してinterest_rate列をスケーリングします。正規化 (または標準化) の目的は、バイアスを排除することです。異なるスケールで記録された変数は、モデルの学習プロセスに等しく貢献しません。したがって、最小~最大スケーラー変換のような変換関数は、特徴正規化に役立ちます。

カテゴリ変数を数値に変換するには、ワンホットエンコーディングを使用します。カテゴリ変数のエンコード (Encode categorical) 変換を選択してから、ワンホットエンコード (One-hot encode) を選択します。今回はpurpose列に対してワンホットエンコーディング変換を行います。
ワンホットエンコーディングは、1 または 0 のバイナリ値を特徴に割り当てることによって、カテゴリ値を新しい特徴に変換します。簡単な例として、yesまたは noのいずれかの値を保持する1つの列がある場合、ワンホットエンコーディングはその列を 2 つの列 (『はい』列と『いいえ』列) に変換します。yes の値は、『はい』列に1があり、『いいえ』列に0があります。数値は予測の確率をより簡単に決定できるため、ワンホットエンコーディングはデータをより有用なものにします。
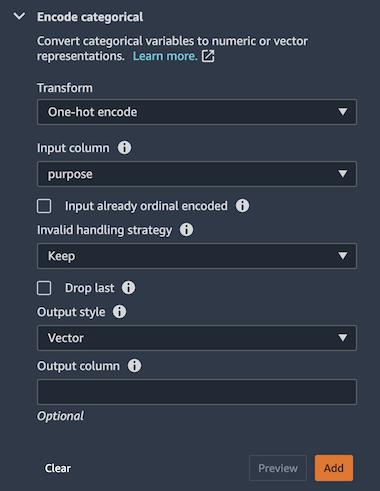
最後に、employer_title列を特徴付けて、その文字列値を数値ベクトルに変換します。 ベクトル変換内で回数ベクトル化 (Count Vectorizer) と標準のトークナイザーを適用します。トークン化は一連のテキストを単語に分解します、ベクトライザーはテキストデータを機械可読形式の数値に変換します。これらの単語はベクトルとして表されます。

すべての特徴量エンジニアリングの手順が完了したら、データをエクスポートして結果を S3 バケットに出力できます。または、フローをPythonコードまたはJupyterノートブックとしてエクスポートして、Amazon SageMaker Pipelinesを使用してビューでパイプラインを作成することもできます。特徴量エンジニアリングのステップを大規模に、または ML パイプラインの一部として実行する場合はご検討ください。

Data Wranglerの出力ファイルをCanvasの入力として使用できるようになりました。これをCanvasのデータセットとして参照して、MLモデルを構築します。

この場合、前処理済みのデータセットをoutputプレフィックス付きで、デフォルトの Studio バケットにエクスポートしました。次にモデルを構築するためにデータをCanvasにロードするときに、このデータセットの場所を参照します。
Canvas で ML モデルを構築してトレーニングする
SageMakerコンソールで、Canvasアプリケーションを起動します。前のセクションで準備したデータから ML モデルを構築するには、次の手順を実行します。
- 準備したデータセットをS3バケットからCanvasにインポートします。

前のセクションでData WranglerからエクスポートしたファイルのS3 パスを参照します。 - Canvasで新しいモデルを作成し、
loan_prediction_modelという名前を付けます。 - インポートされたデータセットを選択し、モデルオブジェクトに追加します。

Canvasにモデルを作成させるには、ターゲット列を選択する必要があります。 - 私たちの目標は、借り手のローン返済能力の確率を予測することであるため、
loan_status列を選択します。
Canvasは、ML問題のタイプを自動的に識別します。執筆時点では、Canvasは回帰、分類、および時系列予測の問題をサポートしています。問題のタイプを指定するか、Canvasにデータから問題を自動的に推測させることができます。
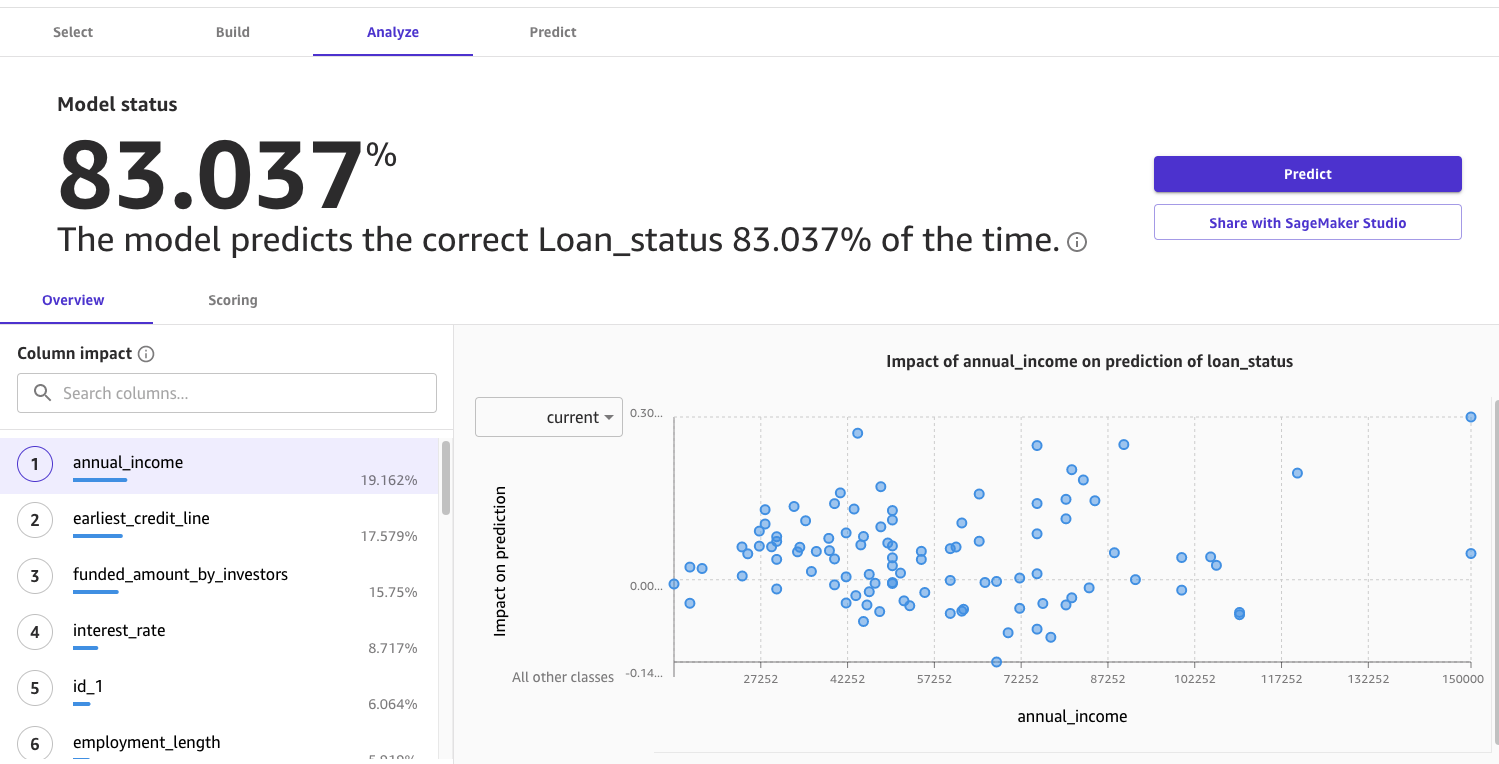
- モデル構築プロセスを開始するオプションを選択します: クイック構築 (Quick build) または標準構築 (Standard build)。クイック構築オプションでは、データセットを使用して2~ 15分以内にモデルをトレーニングします。これは、新しいデータセットを試して、現在のデータセットが予測を行うのに十分かどうかを判断する場合に役立ちます。標準構築オプションは、速度よりも精度を選択し、約250のモデル候補を使用してモデルをトレーニングします。このプロセスには通常1~2時間かかります。この投稿では、このオプションを使用します。モデルが構築されたら、モデルの結果を確認できます。Canvasは、モデルが83%の確率で正しい結果を予測できると推定しています。トレーニング モデルのばらつきにより、独自の結果が異なる場合があります。
 さらに、モデルの詳細分析を深く掘り下げて、モデルについて詳しく知ることができます。
さらに、モデルの詳細分析を深く掘り下げて、モデルについて詳しく知ることができます。
特徴量の重要度は、ターゲット列の予測における各特徴量の推定重要度を表します。この場合、顧客がローン金額を返済するかどうかを予測する上で最も重要な影響を与えるのは年収の列で、次に初めてのクレジットサービス利用開始日が続きます。
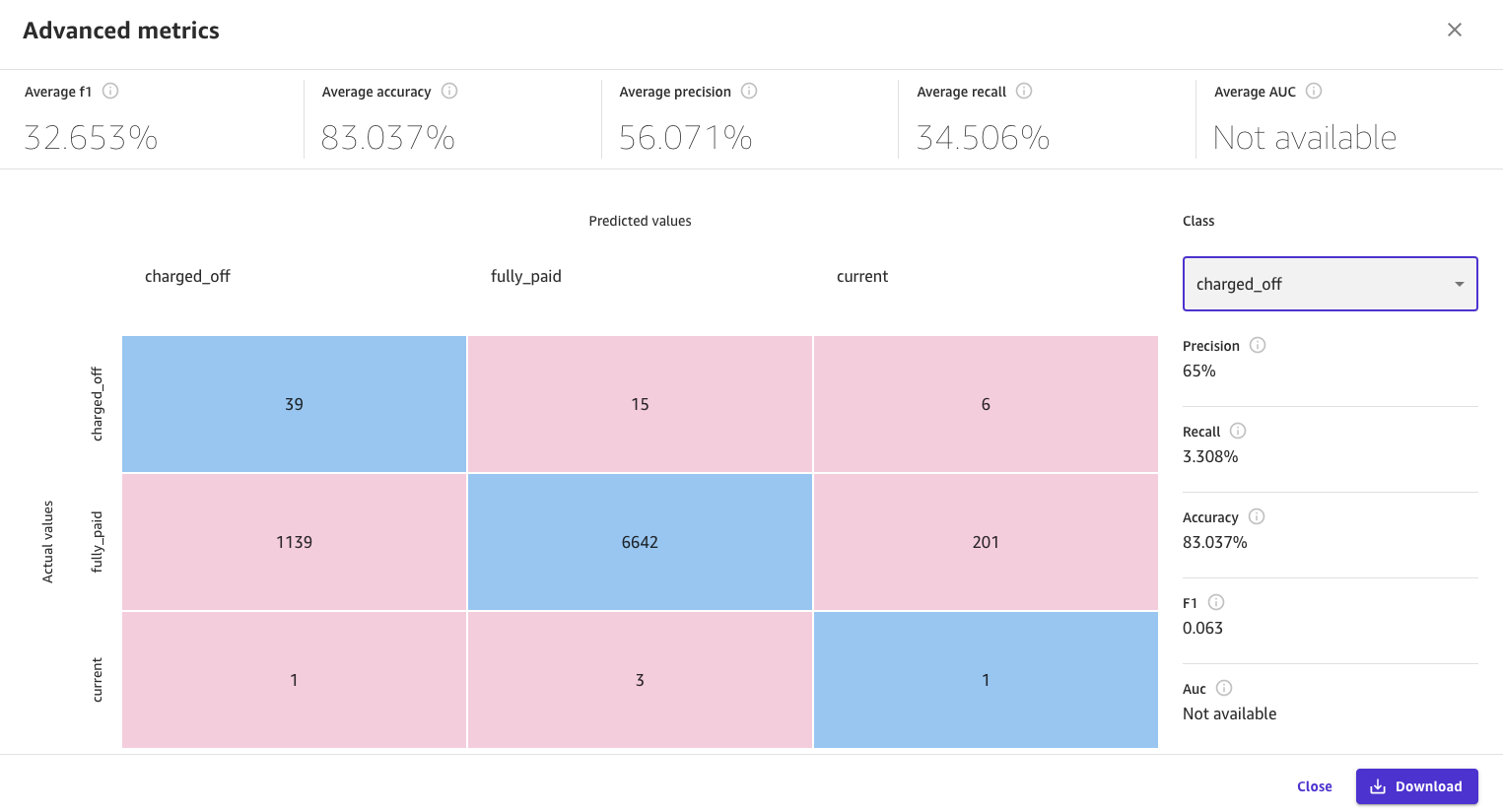
高度なメトリクス (Advanced metrics) セクションの混同マトリックス (Confusion matrix) には、モデルのパフォーマンスをより深く理解したいユーザー向けの情報が含まれています。ここまでで、生成されたモデルの精度が82.9%であることが分かったかと思います。機械学習では、モデルの精度 (Accuracy) は『すべての予測のうち、正しく分類できたものの割合』として定義されます。混合行列の上部の青いボックスは、正しいクラスがわかっているテストデータの一部に対してモデルが生成した正しい予測の数を表しています。
しかし、より関心があるのはモデルがどの程度よく債務不履行者を予測していたかの測定値です。この例では、モデルは75人の借り手がローンを返済すると正しく予測しました。これを真陽性(TP)と呼びます。
ここで、このモデルでは~1000人の借り手が全額返済したにも関わらず、誤って貸倒償却されたと予測したことに注意してください。これを偽陰性(FN)として呼びます。機械学習では、 TP / (TP + FN) という比率が使用されます。これを Recall と呼びます。Advanced metricsページではこのモデルに対してRecallスコアは35%計算し表示しています。混合行列に関しては、こちらの記事を参考にしてください。

- モデルを本番ワークロードにデプロイする前に、Canvasを使用してモデルをテストします。 Canvasはモデル エンドポイントを管理し、Canvasユーザーインターフェイスで直接予測を行うことができます。
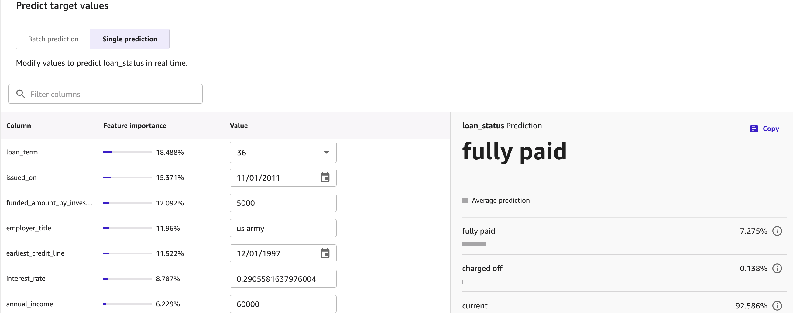
予測 (Predict) を選択し、バッチ予測 (Batch prediction) タブまたは単一予測 (Single prediction) タブで結果を確認します。
次の例では、値を変更してターゲット変数loan_statusをリアルタイムで予測することにより、単一の予測を行います。
より大きなデータセットを選択して、Canvasにバッチ予測を生成させることもできます。

Sagemaker StudioでCanvasのモデル詳細を確認する
標準構築オプションでモデルを作成した場合、Share with SageMaker Studioを選択して、トレーニング済みモデルをSageMaker Studioと共有し、データサイエンティストに渡すことができます。
CanvasでSageMaker Studioのリンクを作成し、そのリンクにアクセスするとSageMaker Studioが開き、SageMaker Canvasで作成した機械学習モデルに伴う情報が共有されています。Canvasでのモデルトレーニングが採用しているアルゴリズム、トレーニングの回数と精度などモデルトレーニングに関する情報が出力されています。

更なる情報を確認したい場合はView model detailsを選択して、特徴量の重要度などの情報も確認できます。
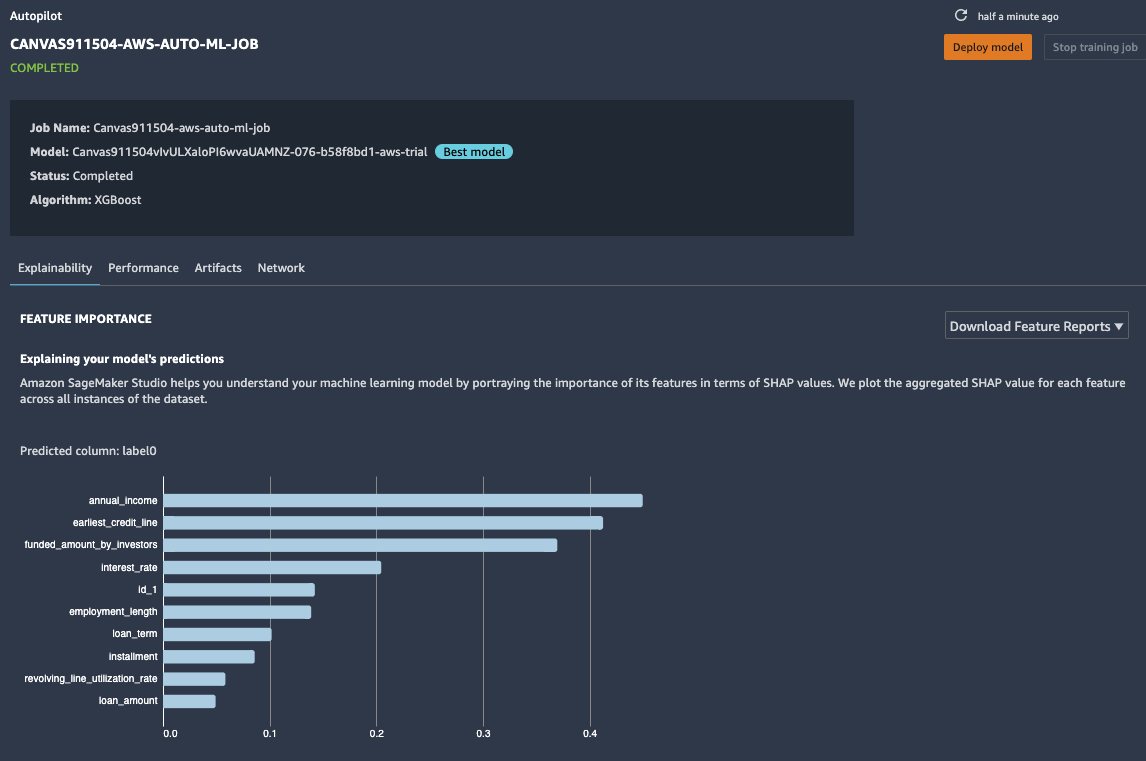
Canvasの推論機能は、バッチ予測または単一予測しかサポートしていませんが、SageMaker Studioに連携する場合、モデルの詳細画面でDeploy Modelを選択して、トレーニングされたモデルをSageMakerリアルタイムの推論エンドポイントとしてデプロイすることもできます。アプリケーションに組み込むやAPIとして提供するニーズがある場合は推論エンドポイントの利用もご検討ください。

まとめ
エンドツーエンドの機械学習は複雑で反復的であり、多くの場合、複数のペルソナ、テクノロジ、およびプロセスが関与します。 Data WranglerとCanvasを使用すると、チームがコードを書く必要なく、チーム間のコラボレーションが可能になります。
データエンジニアは、コードを記述せずにData Wranglerを使用して簡単にデータを準備し、準備したデータセットをビジネス アナリストに渡すことができます。ビジネスアナリストは、Canvasを使用して数回クリックするだけで正確な MLモデルを簡単に構築し、リアルタイムまたはバッチで正確な予測を取得できます。SageMaker Studioとの共有機能を利用して、データサイエンティストにトレーニング済みモデルを渡して更なるモデルの分析と利用拡大に繋がります。
インフラストラクチャを管理する必要なく、これらのツールを使用してData Wranglerを開始します。Canvasをすばやくセットアップして、ビジネスニーズをサポートするMLモデルの作成をすぐに開始できます。