Amazon Web Services ブログ
Amazon Redshift にストアドプロシージャを導入する
Amazon は、常にお客様のニーズに基づいて働いています。お客様は、レガシーのオンプレミスデータウェアハウスから既存のワークロードを簡単に移行できるように、Amazon Redshift でストアドプロシージャを使用できることを強く要望しています。
この大切な目標を念頭に置いて、AWS は PL/pqSQL ストアドプロシージャを実装して、既存のプロシージャとの互換性を最大限に高め、移行を簡素化することを選択しました。この記事では、運用の効率性とセキュリティを向上させるためにストアドプロシージャを使用する方法と場合について説明します。AWS Schema Conversion Tool でストアドプロシージャを使用する方法も説明します。
ストアドプロシージャとは
ストアドプロシージャとは、一連の SQL クエリと論理操作を実行するためにユーザーが作成するオブジェクトです。プロシージャはデータベースに保存され、実行するのに十分な権限を持つユーザーが利用できます。
ユーザー定義関数 (UDF) とは異なり、ストアードプロシージャーは SELECT 照会に加えてデータ定義言語 (DDL) およびデータ操作言語 (DML) を組み込むことができます。ストアドプロシージャは値を返す必要はありません。ループや条件式を含む PL/pgSQL 手続き型言語を使用して論理フローを制御できます。
ストアドプロシージャは通常、データ変換、データ検証、およびビジネス固有の操作のためのロジックをカプセル化するために使用されます。複数の SQL ステップをストアドプロシージャに結合することで、アプリケーションとデータベース間のラウンドトリップを減らすことができます。
また、委任アクセス制御にストアドプロシージャを使用することもできます。たとえば、基になるテーブルへのアクセスをユーザーに許可せずに機能を実行できるストアドプロシージャを作成できます。
ストアドプロシージャを使う理由
Amazon Redshift に移行する多くのお客様は、従来のデータウェアハウスプラットフォーム上にストアドプロシージャで構築された複雑なデータウェアハウス処理パイプラインを持っています。 複雑な変換や重要な集計はストアドプロシージャで定義され、処理の多くの部分で再利用されます。外部のプログラミング言語または新しい ETL プラットフォームを使用してこうしたプロセスのロジックを再作成すると、プロジェクトが大きくなる可能性があります。Amazon Redshift ストアドプロシージャを使用すると、より迅速に Amazon Redshift に移行できます。
他には、セキュリティを強化し、データベースユーザーの権限を制限したいと考えているお客様がいます。ストアドプロシージャは、DBA が必要以上の権限を与えることなく必要な操作を実行できるようにする新しい選択肢を提供します。ストアドプロシージャの security definer の概念により、ユーザーが実行権限を持たない操作を実行できるようになりました。
さらに、この方法でストアドプロシージャを使用すると、操作の負担を軽減できます。経験豊富な DBA であれば、何らかの管理上または保守作業のために十分にテストされたプロセスを定義できます。そうすれば、他の経験の浅いオペレータも、クラスタに対するスーパーユーザのフルアクセス権を委任することなく、プロセスを実行できるようになります。
最後に、シェルスクリプトや複雑なオーケストレーションツールの代わりに、ストアドプロシージャを使用して ETL/ELT 操作を管理することを好むお客様もいます。シェルスクリプトが ETL/ELT プロセスの各操作の状態を正しく取得して解釈することを保証するのが困難な場合があります。また、小規模のデータウェアハウスチームがオーケストレーションツールの運用および保守を引き継ぐことが困難な場合もあります。
ストアドプロシージャを使用すると、ETL/ELT 論理ステップを、完全に成功するか、副作用なくクリーンに失敗するように書かれたマスタープロシージャで完全に囲むことができます。ストアドプロシージャは、cron のような単純なスケジューラから安心して呼び出すことができます。
ストアドプロシージャを作成する
Amazon Redshift でストアドプロシージャを作成するには、以下の構文を使用します。
ストアドプロシージャを設計するときは、カプセル化された機能、入力パラメータと出力パラメータ、セキュリティレベルについて検討します。例として、動的 SQL を使用して、スキーマ、テーブル、プライマリキー列の名前を指定して、プライマリキーの違反をチェックするストアドプロシージャを作成する方法を以下に示します。
ストアドプロシージャ内で使用できる SQL クエリと制御フローロジックの種類についての詳細は、Amazon Redshift でのストアドプロシージャの作成を参照してください。
ストアドプロシージャを呼び出す
ストアドプロシージャは、プロシージャ名と入力引数値を受け取る CALL コマンドで呼び出す必要があります。CALL を、通常のクエリに含めることはできません。例として、前に作成したストアドプロシージャを呼び出す方法は次のとおりです。
Amazon Redshift ストアドプロシージャ呼び出しは、出力パラメータまたは結果セットを通じて結果を返すことができます。入れ子の呼び出しや再帰呼び出しもサポートされています。詳細については、CALL コマンドを参照してください。
security definer プロシージャの使い方
これでストアドプロシージャを作成して呼び出す方法がわかったので、次はセキュリティの側面について詳しく説明します。プロシージャを作成するときは、所有者 (作成者) だけがそれを呼び出すまたは実行する権限を持ちます。他のユーザーまたはグループに EXECUTE 権限を付与することで、それらのユーザーはプロシージャを実行できます。EXECUTE 権限は、呼び出し元がストアードプロシージャーで参照されているすべてのデータベースオブジェクト (テーブル、ビューなど) にアクセスできることを自動的には意味しません。
ユーザー Mary によって作成されたプロシージャ sp_insert_customers の例を見てみましょう。これには、Mary が所有するテーブル customers に書き込む INSERT ステートメントがあります。Mary がユーザー John に EXECUTE 権限を付与した場合でも、John が customers に対する INSERT 権限を明示的に付与されていない限り、John はテーブル customers に INSERT することはできません。
ただし、customers に対する INSERT 権限を付与せずに、John がストアドプロシージャを呼び出すことを許可することは意味があるかもしれません。これを行うには、Mary は、プロシージャーを作成するときにそのプロシージャーの SECURITY 属性を DEFINER に設定してから、EXECUTE 権限を John に付与する必要があります。この設定で、John が sp_insert_customers を呼び出すと、Mary の権限で実行され、そのテーブルに対する INSERT 権限が付与されていなくても customers に挿入できます。
プロシージャの作成時に security 属性が指定されていないと、その値はデフォルトで INVOKER に設定されます。つまり、プロシージャはそれを呼び出すユーザーの権限で実行されることになります。security 属性が明示的に DEFINER に設定されていると、プロシージャはプロシージャの所有者の権限で実行されます。
Amazon Redshift でのストアドプロシージャのベストプラクティス
ストアドプロシージャを使用する場合のベストプラクティスは次のとおりです。
ストアドプロシージャがソース管理ツールにキャプチャされていることを確認する。
データ処理の重要な要素としてストアドプロシージャを使用する予定の場合は、すべてのストアドプロシージャの変更をソース管理システムにコミットする方法も確立する必要があります。
また、重要なストアドプロシージャの所有者である特定のユーザーを定義し、プロシージャを作成および変更するプロセスを自動化することを検討することもできます。
次のコマンドを使用して、既存のストアドプロシージャのソースを取得できます。
SHOW procedure_name;
それぞれのプロシージャのセキュリティ範囲と、それを呼び出す人を検討する
デフォルトでは、ストアドプロシージャはそれらを呼び出すユーザーの権限で実行されます。ストアードプロシージャーを異なる権限で実行できるようにするには、SECURITY DEFINER 属性を使用します。たとえば、重要なテーブルから DELETE へのアクセスを明示的に取り消し、セーフリストをチェックした後に削除を実行するストアドプロシージャを定義します。
SECURITY DEFINER を使用するときは、以下の点に注意してください。
- プロシージャの
EXECUTEをPUBLICではなく特定のユーザーに付与します。これにより、一般のユーザーがこのプロシージャを誤用することがなくなります。 - 可能であれば、プロシージャがアクセスするすべてのデータベースオブジェクトをスキーマ名で修飾します。たとえば、単に
mytableではなくmyschema.mytableを使用します。 - SET オプションを使用して、プロシージャを作成するときに
search_pathを設定します。これにより、同じ名前を持つ他のスキーマ内のオブジェクトが重要なストアドプロシージャの影響を受けることを防ぎます。
セットベースのロジックを使用し、大規模なデータセットを手動でループしないようにする
ストアドプロシージャ内でデータを操作するときは、可能な限り通常のセットベースの SQL (INSERT、UPDATE、DELETE など) を使用します。
ストアドプロシージャは、FOR や WHILE ループなどの新しい制御構造を提供します。これらは、テーブルのリストなど、少数の項目を反復処理するのに役立ちます。ただし、セットベースの SQL 操作の代わりにループ構造を使用しないでください。たとえば、1 つずつ更新するために何百万もの値を繰り返すことは非効率的で遅くなります。
REFCURSOR の制限に注意し、より大きな結果セットには一時テーブルを使用する
結果セットは、REFCURSOR として、または一時テーブルを使用してストアドプロシージャから返されます。 REFCURSOR はメモリ内のデータ構造であり、多くの場合最も単純なオプションです。
ただし、ストアドプロシージャごとに 1 つの REFCURSOR という制限があります。複数の結果セットを返す、複数のサブプロシージャからの結果を操作する、または数百万行 (以上) の結果行を返すことができます。そのような場合、結果を一時テーブルに転送し、ストアドプロシージャの出力としてその一時テーブルへの参照を返すことをお勧めします。
プロシージャを単純に保ち、複雑なプロセスではプロシージャを入れ子にする
それぞれのストアドプロシージャのロジックは可能な限り単純にします。単純にしておくことによって、柔軟性を最大化し、ストアドプロシージャをよりわかりやすくします。
ストアドプロシージャのコードは、改良され拡張されるにつれて複雑になる可能性があります。長くて複雑なストアドプロシージャがあった場合、サブ要素を元のプロシージャから呼び出される別のプロシージャに移動することで単純化できます。
AWS Schema Conversion Tool を使用したストアドプロシージャの移行
Amazon Redshift がストアドプロシージャのサポートを発表したことで、AWS も AWS Schema Conversion Tool を拡張して、ストアドプロシージャを従来のデータウェアハウスから Amazon Redshift に変換するようにしました。
AWS SCT は、Microsoft SQL Server データウェアハウスストアドプロシージャの Amazon Redshift への変換をすでにサポートしています。
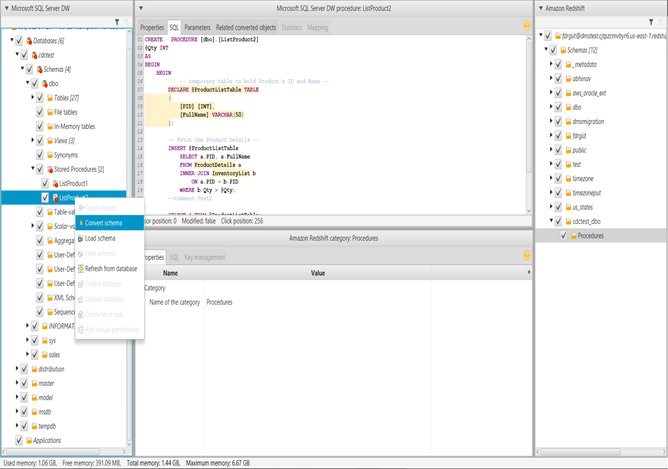
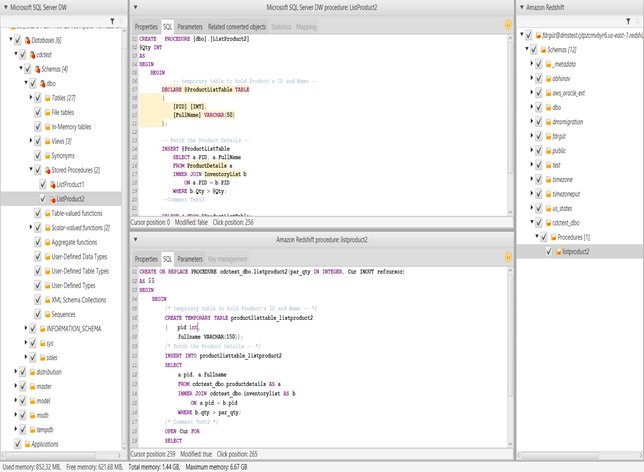
ビルド 627 で、AWS SCT は Microsoft SQL Server データウェアハウスストアドプロシージャを Amazon Redshift に変換できるようになりました。AWS SCT での手順は以下のとおりです:
- SQL Server データウェアハウス (DW) から Amazon Redshift への変換用の新しい OLAP プロジェクトを作成します。
- SQL Server DW および Amazon Redshift エンドポイントに接続します。
- ソースツリー内のすべてのノードのチェックを外します。
- Schemas のコンテキスト (右クリック) メニューを開きます。
- Stored Procedures ノードのコンテキスト (右クリック) メニューを開き、[Convert Script] を選択します (データベースオブジェクトを変換するときと同じです)。
- (オプション) 評価レポートを確認して、変換を適用することもできます。
SQL Server DW ストアドプロシージャ変換の例を次に示します。
結論
Amazon Redshift でのストアドプロシージャのサポートは、現在すべての AWS リージョンで利用可能です。皆様が、Amazon Redshift でストアドプロシージャを実行することを堪能されるよう期待しています。
Amazon Redshift でのストアドプロシージャのサポートと AWS Schema Conversion Tool により、ストアドプロシージャを別の言語またはフレームワークでエンコードすることなく Amazon Redshift に移行できるようになりました。この機能により、移行作業が軽減されます。より多くのオンプレミスのお客様が、Amazon Redshift を利用して、データベースの自由のためにクラウドへ移行できることを願っています。
著者について
 Joe Harris は、AWS のシニア Redshift データベースエンジニアであり、Redshift のパフォーマンスに重点を置いています。彼は 20 年間にわたり、さまざまなプラットフォームでデータを分析し、データウェアハウスを構築してきました。AWS に入社する前は、2013 年の開始日から Redshift のお客様であり、Redshift フォーラムの最大の貢献者でした。
Joe Harris は、AWS のシニア Redshift データベースエンジニアであり、Redshift のパフォーマンスに重点を置いています。彼は 20 年間にわたり、さまざまなプラットフォームでデータを分析し、データウェアハウスを構築してきました。AWS に入社する前は、2013 年の開始日から Redshift のお客様であり、Redshift フォーラムの最大の貢献者でした。
 Abhinav Singh は、AWS のデータベースエンジニアです。彼は、データベース移行プロジェクトの設計と開発の仕事をすると同時に、顧客と協力してデータベース移行プロジェクトに関する助言や技術支援を行い、AWS を使用する場面でソリューションの価値を向上させる手助けをしています。
Abhinav Singh は、AWS のデータベースエンジニアです。彼は、データベース移行プロジェクトの設計と開発の仕事をすると同時に、顧客と協力してデータベース移行プロジェクトに関する助言や技術支援を行い、AWS を使用する場面でソリューションの価値を向上させる手助けをしています。
 Entong Shen は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。彼は 6 年以上 MPP データベースの仕事をしており、クエリの最適化、統計、SQL 言語の機能に重点的に取り組んでいます。余暇は、あらゆるジャンルの音楽を聴いたり、多肉植物庭園で庭仕事をして過ごします。
Entong Shen は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。彼は 6 年以上 MPP データベースの仕事をしており、クエリの最適化、統計、SQL 言語の機能に重点的に取り組んでいます。余暇は、あらゆるジャンルの音楽を聴いたり、多肉植物庭園で庭仕事をして過ごします。
 Vinay は、アマゾン ウェブ サービスの Amazon Redshift 担当プリンシパルプロダクトマネージャーです。以前は、Teradata でプロダクト担当シニアディレクター、Hortonworks でプロダクト担当ディレクターを務めていました。Hortonworks で、彼は Data Science、Spark、Zeppelin、および Security の各製品を立ち上げました。仕事以外では、ヨガやハイキングをするのが好きです。
Vinay は、アマゾン ウェブ サービスの Amazon Redshift 担当プリンシパルプロダクトマネージャーです。以前は、Teradata でプロダクト担当シニアディレクター、Hortonworks でプロダクト担当ディレクターを務めていました。Hortonworks で、彼は Data Science、Spark、Zeppelin、および Security の各製品を立ち上げました。仕事以外では、ヨガやハイキングをするのが好きです。
![]() Sushim Mitra は、Amazon Redshift クエリ処理チームのソフトウェア開発エンジニアです。彼は、クエリ最適化の問題、SQL 言語の機能、およびデータベースセキュリティに焦点を当てています。余暇は、世界中のフィクションを読んで楽しんでいます。
Sushim Mitra は、Amazon Redshift クエリ処理チームのソフトウェア開発エンジニアです。彼は、クエリ最適化の問題、SQL 言語の機能、およびデータベースセキュリティに焦点を当てています。余暇は、世界中のフィクションを読んで楽しんでいます。