Amazon Web Services ブログ
Terraform で Step Functions プロジェクトを記述するためのベストプラクティス
Terraform は、HashiCorp が提供する、もっとも人気のある infrastructure-as-code (IaC) プラットフォームの 1 つです。AWS Step Functions は、開発者が AWS のサービスを利用して分散アプリケーションを構築したり、プロセスを自動化したり、マイクロサービスをオーケストレーションしたり、データと機械学習 (ML) のパイプラインを作成できるよう支援するビジュアルワークフローサービスです。
このブログでは、Terraform を利用してワークフロー (Step Functions ステートマシン) をデプロイするユーザーのためのベストプラクティスを紹介します。AWS Step Functions の Workflow Studio を使用してステートマシンを作成して Terraform でデプロイする方法と、プロジェクト構造、モジュール、パラメータの代入、リモートステートなど、運用に関するベストプラクティスを紹介します。
このブログを読み進める前に、Terraform と Step Functions の両方について十分に理解しておくことをお勧めします。Step Functions や Terraform が初めての場合は Introduction to Terraform on AWS Workshop や、AWS Step Functions Workshop の中の Managing State Machines with Infrastructure as Code セクションの 「Terraform」オプションを参照してください。
Step Functions と Terraform のプロジェクト構造
ソフトウェアプロジェクトにおいてもっとも重要なことの1つは、その構造です。自分自身やチームの他のメンバーが効率的にコーディングを開始できるように、わかりやすく整理されている必要があります。
Terraform を使用した Step Functions プロジェクトでは、多くの可動部分やコンポーネントが含まれる可能性があるので、可能な限りモジュール化してラベルをつけることがとても重要です。モジュール化され、再利用性や拡張性に優れたプロジェクト構造を見ていきましょう。
mkdir sfn-tf-example
cd sfn-tf-example
mkdir -p -- statemachine modules functions/first-function/src
touch main.tf outputs.tf variables.tf .gitignore functions/first-function/src/lambda.py
tree先に進む前に、上記のコマンドで作成したディレクトリ、サブディレクトリ、ファイルを確認してみましょう。
/statemachineには、Step Functions のステートマシン定義を記述した Amazon States Language (ASL)の JSON コードを配置します。ここがオーケストレーションロジックの配置場所となるので、インフラストラクチャコードから分離しておくことをお勧めします。プロジェクトで複数のステートマシンをデプロイする場合は、その定義ごとに JSON ファイルが必要になります。必要に応じて、ステートマシンごとにフォルダを分けて、ロジックをさらにモジュール化して分離することもできます。/functionsサブディレクトリには、ステートマシンの中から利用される AWS Lambda 関数の実際のコードが含まれています。このコードをここに保持しておくと、main.tfファイル内にインラインで記述するよりもはるかに読みやすくなります。- 最後のサブディレクトリは
/modulesです。Terraform モジュールは、アーキテクチャの新しいコンセプトを表現する、高レベルの抽象的概念です。ただし、すべてのものにカスタムモジュールを作成するという罠にはまらないでください。そうするとコードのメンテナンスが難しくなってしまうことが考えられます。 多くの場合は AWS provider リソースで十分です。Terraform AWS modules など、 Terraform Registry から利用できる人気の高いモジュールもあります。プロジェクト内でコードが冗長にならないように、可能な限りモジュールを再利用しましょう。 - プロジェクトのルートにある他のファイルは、すべての Terraform プロジェクトに共通のものです。
terraform initの実行後に Terraform プロジェクトによって隠しファイルが作成されるので、.gitignoreを追加します。.gitignoreの中に何を記述するかは、コードベースやお使いのツールがバックグラウンドでサイレントに作成するものに大きく依存します。後のセクションで、.gitignore内で*.tfstateを指定して Terraform State を安全にリモート管理するためのベストプラクティスについて説明します。
初期コードとプロジェクトのセットアップ
単一の Lambda 関数のみを実行するシンプルな Step Functions ステートマシンを作成します。
そのためにはステートマシンが参照する Lambda 関数を作成する必要があります。まず Lambda 関数のコードを用意し、前述のディレクトリ構造の中のファイルに保存する必要があります。
functions/first-function/src/lambda.py
import boto3
def lambda_handler(event, context):
# Minimal function for demo purposes
return TrueTerraform では、メインの設定ファイルの名前は main.tf です。 Terraform CLI はこのファイルをローカルディレクトリから探します。 テンプレートを複数の .tf ファイルに分割できますが、 main.tf はそのうちの1つである必要があります。 このファイルでは、テンプレートのリソース定義とともに、必要なプロバイダとその最小バージョンを定義します。(翻訳者補足: provider のバージョン制約の指定については Terraform 公式ドキュメントも参照してください)
以下の例では、Lambda 関数を 1 つ実行するだけのシンプルなステートマシンに必要な最小限のリソースを定義しています。 Lambda 関数とステートマシンがそれぞれ使用する 2 つの AWS Identity and Access Management (IAM) ロールを定義しています。 Lambda 関数コードを ZIP 圧縮する data リソースを定義し、Lambda 関数の定義で使用します。 また、全体を通して aws_iam_policy_document データソース を使用していることにも注目してください。この公式データソースを使用することで、統合開発環境 (IDE) と Terraform の両方が terraform apply を実行する前に、ポリシーが不正な形式でないかを確認できます。
最後に、Lambda 関数が実行ログを保存するために使用する Amazon CloudWatch ロググループを定義しています。
Terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~>4.0"
}
}
}
provider "aws" {}
provider "random" {}
data "aws_caller_identity" "current_account" {}
data "aws_region" "current_region" {}
resource "random_string" "random" {
length = 4
special = false
}
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
]
}
}
resource "aws_iam_role" "function_role" {
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"]
}
# Create the function
data "archive_file" "lambda" {
type = "zip"
source_file = "functions/first-function/src/lambda.py"
output_path = "functions/first-function/src/lambda.zip"
}
resource "aws_kms_key" "log_group_key" {}
resource "aws_kms_key_policy" "log_group_key_policy" {
key_id = aws_kms_key.log_group_key.id
policy = jsonencode({
Id = "log_group_key_policy"
Statement = [
{
Action = "kms:*"
Effect = "Allow"
Principal = {
AWS = "arn:aws:iam::${data.aws_caller_identity.current_account.account_id}:root"
}
Resource = "*"
Sid = "Enable IAM User Permissions"
},
{
Effect = "Allow",
Principal = {
Service : "logs.${data.aws_region.current_region.name}.amazonaws.com"
},
Action = [
"kms:Encrypt*",
"kms:Decrypt*",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:Describe*"
],
Resource = "*"
}
]
Version = "2012-10-17"
})
}
resource "aws_lambda_function" "test_lambda" {
function_name = "HelloFunction-${random_string.random.id}"
role = aws_iam_role.function_role.arn
handler = "lambda.lambda_handler"
runtime = "python3.9"
filename = "functions/first-function/src/lambda.zip"
source_code_hash = data.archive_file.lambda.output_base64sha256
}
# Explicitly create the function’s log group to set retention and allow auto-cleanup
resource "aws_cloudwatch_log_group" "lambda_function_log" {
retention_in_days = 1
name = "/aws/lambda/${aws_lambda_function.test_lambda.function_name}"
kms_key_id = aws_kms_key.log_group_key.arn
}
# Create an IAM role for the Step Functions state machine
data "aws_iam_policy_document" "state_machine_assume_role_policy" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["states.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
]
}
}
resource "aws_iam_role" "StateMachineRole" {
name = "StepFunctions-Terraform-Role-${random_string.random.id}"
assume_role_policy = data.aws_iam_policy_document.state_machine_assume_role_policy.json
}
data "aws_iam_policy_document" "state_machine_role_policy" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogGroups"
]
resources = ["${aws_cloudwatch_log_group.MySFNLogGroup.arn}:*"]
}
statement {
effect = "Allow"
actions = [
"cloudwatch:PutMetricData",
"logs:CreateLogDelivery",
"logs:GetLogDelivery",
"logs:UpdateLogDelivery",
"logs:DeleteLogDelivery",
"logs:ListLogDeliveries",
"logs:PutResourcePolicy",
"logs:DescribeResourcePolicies",
]
resources = ["*"]
}
statement {
effect = "Allow"
actions = [
"lambda:InvokeFunction"
]
resources = ["${aws_lambda_function.test_lambda.arn}"]
}
}
# Create an IAM policy for the Step Functions state machine
resource "aws_iam_role_policy" "StateMachinePolicy" {
role = aws_iam_role.StateMachineRole.id
policy = data.aws_iam_policy_document.state_machine_role_policy.json
}
# Create a Log group for the state machine
resource "aws_cloudwatch_log_group" "MySFNLogGroup" {
name_prefix = "/aws/vendedlogs/states/MyStateMachine-"
retention_in_days = 1
kms_key_id = aws_kms_key.log_group_key.arn
}Workflow Studio と Terraform の統合
Step Functions のステートマシンを作成するためには様々なツールが利用できるので、状況に応じて適切な開発手法を理解することが重要です。今回の場合は、Workflow Studio と Terraform でのローカル開発を組み合わせる手法が良いでしょう。このワークフローは、アプリケーションのすべてのリソースを同じ Terraform プロジェクト内で定義し、 AWS リソースの管理に Terraform を利用することを前提としています。

図1 – Terraform で Step Functions ステートマシンを作成するワークフロー
- Lambda 関数や Amazon S3 バケット、Amazon DynamoDB テーブルなど、ステートマシン で呼び出す予定のリソースの Terraform の定義を記述し、
terraform applyコマンドを使用してデプロイします。これを Workflow Studio を使用する前に行うことで、ステートマシンの最初のバージョンの設計がしやすくなります。ステートマシンをローカルの Terraform プロジェクトにインポートした後、追加のリソースを定義できます。 - Workflow Studio を使用して、ステートマシンの最初のバージョンを視覚的に設計できます。必要なリソースはすでに作成済みなので、すべてのアクションとステートをドラッグアンドドロップしてリンクし、どのように見えるかを確認できます。最後に、実際にステートマシンを実行して動きを確認できます。
- ステートマシンの最初のバージョンの設計が完了したら、ASL ファイルをエクスポートして、Terraform プロジェクトに保存します。Terraform リソースタイプ
aws_sfn_state_machineを使用し、保存した ASL ファイルをdefinitionフィールドで参照します。 - Terraform がリソースを動的に命名し、それに伴って Amazon Resource Name (ARN) が最終的に変化することを想定して、ASL ファイルをパラメータ化しておく必要があります。コードの更新やリファクタリングが困難になるため、ASL ファイルに ARN をハードコーディングすることは避けましょう。
- 最後に、
terraform applyを実行し、Terraform 経由でステートマシンをデプロイします。
シンプルな変更の場合は Workflow Studio での作業からやりなおすよりも、 Terraform プロジェクト内のパラメータ化された ASL ファイルを直接変更したほうが良いでしょう。
ASL ファイルをプロジェクトの一部としてバージョン管理することで、手動での変更作業によって意図せずステートマシンが破壊されてしまうことを防止できます。仮にステートマシンが破壊されてしまったとしても、以前のバージョンに簡単にロールバックできます。
ステートマシンに大規模な変更を加える場合は、コンソールで Workflow Studio の利点を活用することが望ましいでしょう。
しかし、ローカルで開発している間もステートマシンの視覚的な表現を継続的に確認したいと考えることがほとんどでしょう。幸いにも、Visual Studio Code (VS Code) に直接統合されている別のオプションがあり、Workflow Studio と同様にステートマシンを視覚的にレンダリングできます。この機能は、AWS Toolkit for VS Code の一部です。AWS Toolkit for VS Code とのステートマシンの統合の詳細については、こちら を参照してください。以下は、パラメータ化された ASL ファイルと VS Code でのレンダリングによる視覚化の例です。
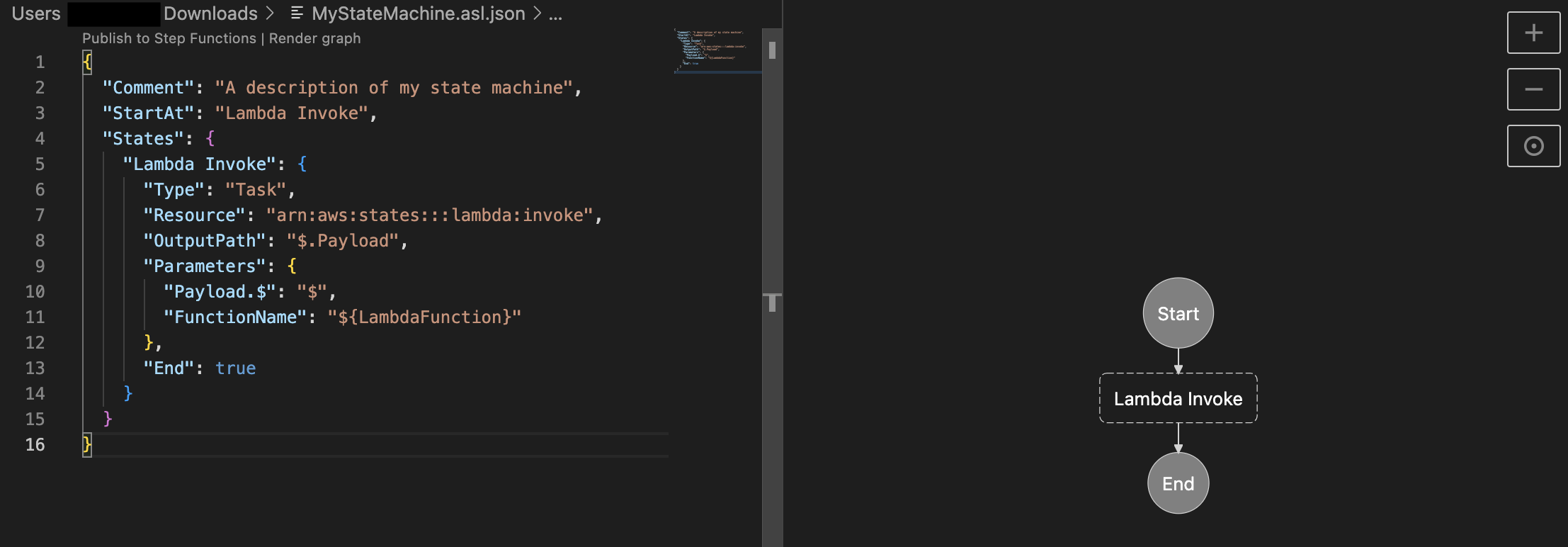
図2 – VS Code 内で可視化された Step Functions ステートマシン
パラメータの代入
Terraform テンプレートで Step Functions のステートマシンを定義する際は、その定義をテンプレート内に記述することも別のファイルに記述することもできます。テンプレート内にステートマシンの定義を直接記述すると可読性が低下し、管理が難しくなる可能性があります。 ベストプラクティスとして、ステートマシンの定義を別のファイルに記述しておくことをお勧めします。ステートマシンの定義にパラメータを渡すためには、Terraform の templatefile 関数 を利用できます。templatefile 関数はファイルを読み取り、指定された変数セットを使用してコンテンツをレンダリングします。 以下のコードスニペットで示すように、 templatefile 関数を使用して、Lambda 関数の ARN やステートマシンに渡すその他のパラメータとともに、ステートマシン定義ファイルをレンダリングします。
resource "aws_sfn_state_machine" "sfn_state_machine" {
name = "MyStateMachine-${random_string.random.id}"
role_arn = aws_iam_role.StateMachineRole.arn
definition = templatefile("${path.module}/statemachine/statemachine.asl.json", {
ProcessingLambda = aws_lambda_function.test_lambda.arn
}
)
logging_configuration {
log_destination = "${aws_cloudwatch_log_group.MySFNLogGroup.arn}:*"
include_execution_data = true
level = "ALL"
}
}ステートマシンの定義内で、${ … } で区切られた補間シーケンスを使用して文字列テンプレートを指定する必要があります。
以下のコードスニペットのように、templatefile 関数によって渡される変数名を使用してステートマシンを定義します。
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "${ProcessingLambda}"
},
"End": true
}templatefile 関数が実行されると、変数 ${ProcessingLambda} が、デプロイ時に生成された実際の Lambda 関数の ARN に置き換えられます。
Terraform State のリモート管理
Terraform を実行するたびに、管理対象のインフラストラクチャと構成に関する情報が State ファイルに保存されます。デフォルトでは、Terraform はローカルディレクトリに terraform.tfstate という State ファイルを作成します。
前述したように、.gitignore ファイルに .tfstate ファイルを含めることをお勧めします。これによりソース管理にコミットすることがなくなり、意図せず機密情報が露出してしまうことを防ぎ、 State に関するエラーが発生してしまう可能性を低減することができます。
このローカルファイルを誤って削除すると、Terraform は以前に作成されたインフラストラクチャを追跡できなくなります。その場合、更新された設定で terraform apply を実行すると、Terraform がインフラストラクチャを新しく作成するため、作成済のインフラストラクチャとの間で競合が発生します。
バージョン管理や暗号化、共有を可能にするため、Terraform の State をリモートのセキュアなストレージに保存することをお勧めします。Terraform は、backend 設定ブロックを使用した S3 バケットへの State の保存をサポートしています。Terraform が State ファイルを S3 バケットに書き込むように設定するには、バケット名、リージョン、キー名を指定する必要があります。
また、State ファイルを誤って削除してしまうことを防ぐために、S3 バケットで バージョニングを有効 にし、 MFA 削除 を設定することをお勧めします。
さらに、ターゲットの S3 バケットに対して適切な IAM 権限 が Terraform に付与されていることの確認が必要です。
複数の開発者が同じインフラストラクチャを操作する場合は、Terraform は State ロックを使用して、同じ State に対する同時実行を防止することもできます。ロックの制御には DynamoDB テーブルを使用できます。使用する DynamoDB テーブルは、LockIDというパーティションキー (String 型) が必要があり、Terraform はそのテーブルに対する適切な IAM 権限 を持つ必要があります。
terraform {
backend "s3" {
bucket = "mybucket"
key = "path/to/state/file"
region = "us-east-1"
attach_deny_insecure_transport_policy = true # only allow HTTPS connections
encrypt = true
dynamodb_table = "Table-Name"
}
}この リモートState の設定により、 S3 で State を安全に保存し、維持できます。
インフラストラクチャに変更を適用するたびに、Terraform は S3 バケットから最新の State を自動的に取得し、DynamoDB テーブルを利用してロックを取得します。変更を適用した後、最新の State を S3 バケットにプッシュし、その後ロックを解除します。
クリーンアップ
terraform apply を実行して Lambda 関数、Step Functions ステートマシン、バックエンドの State ストレージの S3 バケット、その他の関連リソースをデプロイした場合は、AWS アカウントで料金が発生しないように、terraform destroy を実行してこれらのリソースを削除して環境をクリーンアップしてください。
まとめ
このブログでは AWS Step Functions ステートマシンのデプロイに Terraform を活用するための包括的なガイドを提供しています。適切に構造化されたプロジェクト、コードの初期セットアップ、 Workflow Studio と Terraform の統合、パラメータの代入、 State のリモート管理の重要性について説明しました。
これらのベストプラクティスに従うことで、開発者はクリーンでモジュール化された再利用可能なコードを維持しながら、ステートマシンをより効果的に作成および管理できます。
infrastructure-as-code (IaC) を導入し Workflow Studio 、 VS Code 、 Terraform などの適切なツールを使用すると、スケーラブルでメンテナンスしやすい分散アプリケーションを構築したり、プロセスを自動化したり、マイクロサービスをオーケストレーションしたり、AWS Step Functions を使用したデータと機械学習 (ML) のパイプラインを作成できます。
Step Functions を Terraform と共に利用する方法をより深く学習したい場合は、Serverless Land で公開されている パターン や ワークフロー をご確認ください。また、 Step Functions 開発者ガイド も参照してください。
著者について
本記事は 2023/09/18に投稿された Best Practices for Writing Step Functions Terraform Projects を翻訳したものです。翻訳は Solutions Architect : 国兼 周平 (Shuhei Kunikane) が担当しました。