Amazon Web Services ブログ
Amazon EMR で Apache Spark アプリケーションのメモリをうまく管理するためのベストプラクティス
ビッグデータの世界における一般的なユースケースは、さまざまなデータソースからの大量のデータにおける抽出/変換 (ET) とデータ分析の実行です。多くの場合、この後でデータを分析してインサイトを取得します。このような大量のデータを処理するための最も人気のあるクラウドベースソリューションのひとつが Amazon EMR です。
Amazon EMR は、AWS での Apache Hadoop および Apache Spark などのビッグデータフレームワークの実行をシンプル化するマネージドクラスタープラットフォームです。Amazon EMR は、組織が複数のインスタンスを持つクラスターをほんの数分でスピンアップすることを可能にします。また、並列処理を使ってさまざまなデータエンジニアリングとビジネスインテリジェンスのワークロードを処理できるようにもしてくれます。こうすることで、クラスターの確立とスケーリングに関わるデータ処理の時間、工数、およびコストを大幅に削減することができます。
Apache Spark は、オープンソースで高速な汎用目的のクラスターコンピューティングソフトウェアで、ビッグデータの分散処理で広く利用されています。Apache Spark は、タスクの I/O と実行時間を削減するためにノード全体のメモリで並行コンピューティングを実行することから、クラスターメモリ (RAM) に大きく依存しています。
一般に、Amazon EMR で Spark アプリケーションを実行するときは、以下の手順を実行します。
- Spark アプリケーションパッケージを Amazon S3 にアップロードする。
- 設定済みの Apache Spark で Amazon EMR クラスターを設定し、起動する。
- Amazon S3 からクラスターにアプリケーションパッケージをインストールし、アプリケーションを実行する。
- アプリケーションが完了したら、クラスターを終了する。
Spark アプリケーションを成功させるには、データと処理の要件に基づいて Spark アプリケーションを適切に設定することが大切です。デフォルト設定では Spark が利用できるクラスターのリソースのすべてを使用しない場合があり、物理メモリまたは仮想メモリの問題、あるいはその両方が発生する可能性があります。Stackoverflow.com では、この特定のトピックに関連する何千もの質問が提起されています。
このブログ記事の目的は、Amazon EMR 上の Apache Spark でのメモリ関連の問題を防ぐためのベストプラクティスを詳しく説明することによって、読者の皆さんを支援することです。
デフォルト設定または不適切な設定の Spark アプリケーションにおける一般的なメモリ問題
以下にリストされているのは、デフォルト設定または不適切な設定の Spark アプリケーションで起こり得るメモリ不足エラーサンプルの一部です。
メモリ不足エラー、Java Heap Space
メモリ不足エラー、物理メモリの超過
メモリ不足エラー、仮想メモリの超過
メモリ不足エラー、エグゼキュータメモリの超過
これらの問題はさまざまな理由で発生しますが、以下はその理由の一部です。
- Spark エグゼキュータインスタンスの数、エグゼキュータメモリの量、コアの数、または並列性が、大量のデータを処理するために適切に設定されていない場合。
- Spark エグゼキュータの物理メモリが YARN によって割り当てられたメモリを超過する場合。この場合、Spark エグゼキュータインスタンスのメモリとメモリオーバーヘッドの合計が、メモリ集約型の操作を処理するために十分な量ではありません。メモリ集約型の操作には、
reduceByKey、groupByなどを使用したキャッシング、シャッフリング、および集約が含まれます。または、Spark エグゼキュータインスタンスのメモリとメモリオーバーヘッドの合計がyarn.scheduler.maximum-allocation-mbで定義されている量を超えている場合もあります。 - ガベージコレクションなどのシステム操作の実行に必要なメモリが Spark エグゼキュータインスタンスにない。
以下のセクションでは、前述のものを含む (ただし、これらに限定はされません) メモリ不足問題を防ぐために適切な設定を行う方法を説明します。
Amazon EMR で Spark アプリケーションを成功させるための設定
以下の手順は、Amazon EMR で Spark アプリケーションを成功させる設定を行うために役立ちます。
1.アプリケーションのニーズに基づいてインスタンスのタイプと数を判断する
Amazon EMR には 3 つのタイプのノードがあります。
- マスター: EMR クラスターには 1 個のマスターがあり、これはリソースマネージャーとして機能し、クラスターとタスクを管理します。
- コア: コアノードは、マスターノードに管理されます。コアノードは、YARN NodeManager デーモン、Hadoop MapReduce タスク、および Spark エグゼキュータを実行して、ストレージの管理、タスクの実行、およびマスターへのハートビートの送信を行います。
- タスク: オプションのタスク限定ノードはタスクを実行しますが、コアノードとは違ってデータは保存しません。
ベストプラクティス 1: Amazon EMR クラスター内の各ノードタイプに正しいインスタンスタイプを選択します。これは、Amazon EMR での Spark アプリケーションの実行を成功させるための秘訣のひとつです。
AWS が提供するインスタンスには、Amazon EMR ドキュメントでも説明されているように、さまざまな範囲の vCPU、ストレージ、およびメモリを備えた多数のインスタンスタイプがあります。アプリケーションがコンピューティング集約型かメモリ集約型かに基づいて、正しいコンピューティング設定とメモリ設定を持つ正しいインスタンスタイプを選択することができます。
メモリ集約型のアプリケーションについては、他のインスタンスタイプよりも R タイプのインスタンスを選択します。コンピューティング集約型アプリケーションについては、C タイプのインスタンスを選択します。 メモリとコンピューティング間のバランスがとられているアプリケーションには、M タイプの汎用インスタンスを選択します。
AWS が提供する各インスタンスタイプについて考えられるユースケースを理解するには、EC2 サービスのウェブサイトで Amazon EC2 インスタンスタイプを参照してください。
インスタンスタイプを決定したら、各ノードタイプのインスタンスの数を判断します。これは、入力データセットのサイズ、アプリケーションの実行時間、および頻度の要件に基づいて行います。
2.Spark 設定パラメータを決定する
Spark 設定の詳細に進む前に、以下の図を使って、エグゼキュータコンテナのメモリがどのように組織されてるかの概要を確認しましょう。
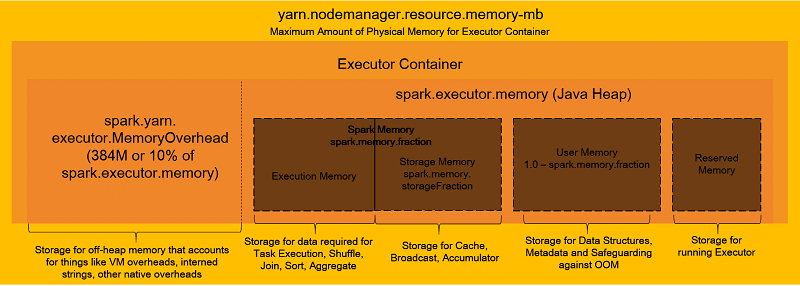
上記の図からわかるように、エグゼキュータコンテナには複数のメモリコンパートメントがあります。これらの中で、タスクの実行のために実際に使用されるのはひとつだけです (実行メモリ)。これらのコンパートメントは、タスクを効率的に失敗することなく実行するためにも、適切に設定されている必要があります。
Spark アプリケーションが正常に実行されるように、以下の Spark 設定パラメータを慎重に計算し、設定してください。
spark.executor.memory– タスクを実行する各エグゼキュータのために使用するメモリのサイズ。spark.executor.cores– 仮想コアの数。spark.driver.memory– ドライバーのために使用するメモリのサイズ。spark.driver.cores– ドライバーのために使用する仮想コアの数。spark.executor.instances– エグゼキュータの数。spark.dynamicAllocation.enabledが true に設定されている場合以外は、このパラメータを設定します。spark.default.parallelism– ユーザーによってパーティションの数が設定されていない場合に、join、reduceByKey、およびparallelizeなどの変換によって返された RDD (Resilient Distributed Datasets) 内のパーティションのデフォルト数。
このリリースガイドでは、Amazon EMR がどのように Spark パラメータのデフォルト値を設定するかについてのおおまかな情報が提供されています。これらの値は spark-defaults 設定内で、クラスター内のコアインスタンスとタスクインスタンスのタイプに基づいて自動的に設定されます。
クラスター内で利用できるリソースのすべてを使用するには、maximizeResourceAllocation パラメータを true に設定してください。この EMR 固有のオプションは、コアインスタンスグループ内のインスタンスにあるエグゼキュータが利用できる最大のコンピューティングリソースとメモリリソースを計算してから、spark-defaults 設定でこれらのパラメータを設定します。この設定を使っても、ほとんどの場合デフォルトの数は少なく、アプリケーションはクラスターの力を完全に使用しません。例えば、並列性は規模が大きいクラスターのために高くできるにもかかわらず、spark.default.parallelism のデフォルトは利用可能な仮想コアの数の 2 倍に留まります。
YARN 上の Spark は、ワークロードに基づいて Spark アプリケーションに使用されるエグゼキュータの数を動的にスケールします。Amazon EMR のリリースバージョン 4.4.0 以降を使用すると、dynamic allocation がデフォルトで有効化されています (これは Spark ドキュメントで説明されています)。
spark.dynamicAllocation.enabled プロパティの問題は、これがサブプロパティの設定を必要とすることです。サブプロパティの例には、spark.dynamicAllocation.initialExecutors、minExecutors、および maxExecutors などがあります。サブプロパティはほとんどの場合、そして特に複数のアプリケーションを同時に実行する必要があるときに、アプリケーションのクラスターで正しい数のエグゼキュータを使用するために必要になります。サブプロパティの設定には、正確な数を把握するまでに数多くの試行錯誤が必要です。数が正確ではないと、キャパシティーが確保されていても、実際に使われることはありません。これはリソースの浪費、または他のアプリケーションに対するメモリエラーにつながります。
ベストプラクティス 2:
spark.dynamicAllocation.enabledは、spark.dynamicAllocation.initialExecutors/minExecutors/maxExecutorsパラメータに対して数が適切に決定されている場合にのみ true に設定します。それ以外の場合は、spark.dynamicAllocation.enabledを false に設定して、ドライバーメモリ、エグゼキュータメモリ、および CPU パラメータを自分自身で制御してください。これを行うには、各アプリケーションについてこれらのプロパティを手動で計算し、設定してください (以下の例を参照)。
Amazon S3 に保存されている何千ものファイルに分散された 200 テラバイトのデータを処理するとしましょう。さらに、1 個の r5.12xlarge マスターノードと 19 個の r5.12xlarge コアノードを持つ Amazon EMR クラスターを使ってこれを行うと仮定します。各 r5.12xlarge インスタンスには 48 個の仮想コア (vCPU) と 384 GB の RAM があります。これらすべての計算は、AWS が本番使用向けに推奨する --deploy-mode クラスターのためのものです。
以下のリストは、前述のケースを例として使って、いくつかの重要な Spark プロパティを設定する方法を説明しています。
spark.executor.cores
エグゼキュータに多数の仮想コアを割り当てることは、少数のエグゼキュータと低並列性につながります。少数の仮想コアを割り当てることは多数のエグゼキュータにつながり、大量の I/O 操作の原因になります。過去のデータに基づいて、あらゆるサイズのクラスターで最適な結果を得るためには各エグゼキュータに 5 個の仮想コアを割り当てることを提案します。
前述のクラスターについては、spark.executor.cores プロパティを以下のように割り当てる必要があります。spark.executors.cores = 5 (vCPU)
spark.executor.memory
1 エグゼキュータあたりの仮想コアの数を決定した後のこのプロパティの計算は、非常にシンプルです。まず、仮想コアとエグゼキュータ仮想コアの合計数を使って、1 インスタンスあたりのエグゼキュータの数を求めます。Hadoop デーモン用に確保しておくため、仮想コアの合計数から仮想コアを 1 個差し引きます。
Number of executors per instance = (total number of virtual cores per instance - 1)/ spark.executors.cores
Number of executors per instance = (48 - 1)/ 5 = 47 / 5 = 9 (rounded down)次に、1 インスタンスあたりの合計 RAMと 1 インスタンスあたりのエグゼキュータの数を使って、エグゼキュータメモリの合計容量を求めます。Hadoop デーモン用に 1 GB を残しておいてください。
このエグゼキュータメモリの合計容量には、エグゼキュータメモリとオーバーヘッド (spark.yarn.executor.memoryOverhead) が含まれます。このエグゼキュータメモリの合計容量の 10 パーセントをメモリオーバーヘッドに割り当てて、残りの 90 パーセントをエグゼキュータメモリに割り当てます。
spark.driver.memory
これは、spark.executors.memory と等しくなるように設定することをお勧めします。
spark.driver.cores
これは、spark.executors.cores と等しくなるように設定することをお勧めします。
spark.executor.instances
これは、エグゼキュータの数とインスタンスの合計数を乗じて計算します。ドライバー用にエグゼキュータを 1 個残しておいてください。
spark.default.parallelism
このプロパティを以下の式を使って設定します。
警告: この計算の結果は 1,700 個のパーティションになりますが、各パーティションのサイズを見積り、coalesce または repartition を使ってこの数値を適切に調整することをお勧めします。
データフレームの場合は、spark.default.parallelism と共に spark.sql.shuffle.partitions パラメータを設定します。
前述のパラメータはどの Spark アプリケーションについても重要なものですが、以下のパラメータもアプリケーションをスムーズに実行して、その他のタイムアウトやメモリ関連のエラーを避けるために役立ちます。これらは spark-defaults 設定ファイルで設定することをお勧めします。
spark.network.timeout– すべてのネットワークトランザクションのタイムアウト。spark.executor.heartbeatInterval– ドライバーに対する各エグゼキュータのハートビートの間隔。この値は、spark.network.timeoutよりも大幅に少ない値である必要があります。spark.memory.fraction– Spark の実行とストレージに使用される JVM ヒープ領域の割合。この値が低いほど、スピルとキャッシュデータの削除がより頻繁に発生します。spark.memory.storageFraction– spark.memory.fraction によって確保されたリージョンのサイズの一部として表されます。この値が高いほど、実行用に利用できる作業メモリが少なくなる可能性があります。これは、タスクがディスクにより頻繁にスピルする可能性があることを意味します。spark.yarn.scheduler.reporterThread.maxFailures– YARN がアプリケーションを失敗させるまでに許容されるエグゼキュータの最大失敗回数。spark.rdd.compress– true に設定すると、このプロパティは RDD を圧縮することによって、追加の CPU 時間を代償にかなりの領域を節約することができます。spark.shuffle.compress– true に設定すると、このプロパティはマップ出力を圧縮して領域を節約します。spark.shuffle.spill.compress– true に設定すると、このプロパティはシャッフル中にスピルされたデータを圧縮します。spark.sql.shuffle.partitions– 結合と集約のためのパーティションの数を設定します。spark.serializer– データをシリアライズまたはデシリアライズするシリアライザーを設定します。シリアライザーとしては、Kyro (org.apache.spark.serializer.KryoSerializer) がよいと思います。これは、Java のデフォルトシリアライザーよりも高速でコンパクトです。
前述した各パラメータについてより良く理解するには、Spark ドキュメントを参照してください。
効率的な Spark 処理のために、これらの追加のプログラミング手法を検討することをお勧めします。
coalesce– パーティションの数を減らして、データの移動を少なくすることができます。repartition–coalesceとは対照的に、パーティションの数を減らす、または増やして、データのフルシャッフルを実行します。partitionBy– データをパーティション全体に水平に分散します。bucketBy– ハッシュされた列に基づいて、データをより管理しやすいパーツ (バケット) に分解します。cache/persist– データセットを クラスター全体のインメモリキャッシュにプルします。これは、小規模のルックアップデータセットをクエリする、または反復アルゴリズムを実行しているときなど、データが繰り返しアクセスされる場合に便利です。
ベストプラクティス 3: アプリケーション要件に基づいて、前述の追加プロパティを慎重に計算します。Spark アプリケーションをサブミットするとき (
spark-submit)、またはSparkConfオブジェクト内において、Spark-defaultsでこれらのプロパティを適切に設定します。
3.適切なガベージコレクターを実装してメモリを効率的にクリアする
ガベージコレクションは、特定のケースでメモリ不足エラーを引き起こす場合があります。これには、アプリケーション内に複数の大規模な RDD が存在するケースが含まれます。他のケースは、タスク実行メモリと RDD キャッシュメモリの間に干渉がある場合に発生します。
古いオブジェクトをエビクトして、メモリ内に新しいオブジェクトを設置するために、複数のガベージコレクターを使用することができます。ただし、最新の Garbage First Garbage Collector (G1GC) は、古いガベージコレクターのレイテンシーとスループットの制限を克服します。
ベストプラクティス 4: Spark で大量のデータを処理するときは、常にガベージコレクターを設定します。
-XX:+UseG1GC パラメータは、G1GC ガベージコレクターを使用するべきであることを指定します。(デフォルトは -XX:+UseParallelGC です。) ガベージコレクションの頻度と実行時間を把握するには、-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps パラメータを使用してください。ガベージコレクションをより早く開始するには、InitiatingHeapOccupancyPercent を 35 に設定します (デフォルトは 0.45)。これは、膨大な時間がかかる場合がある、全メモリに対するガベージコレクションの可能性を避けるために役立ちます。 以下がその例です。
4.YARN 設定パラメータを設定する
すべての Spark 設定プロパティが正しく計算され、設定されているとしても、OS によって仮想メモリが積極的に増やされるときに、まれではありますが、仮想メモリ不足エラーが生じる可能性があります。これらのアプリケーションの失敗を防ぐには、YARN サイト設定に以下のフラグを設定します。
ベストプラクティス 5: 仮想および物理メモリのチェックフラグは常に false に設定します。
5.デバッグとモニタリングを実行する
Spark 設定オプションがどこからきているかの詳細を得るには、–verbose オプションを付けて spark-submit を実行することができます。また、Ganglia および Spark UI を使ってアプリケーションの進捗状況、クラスターの RAM 使用率、ネットワーク I/O などを監視することができます。
以下の例では、Ganglia グラフを使って、設定済み、および未設定の Spark アプリケーションの結果を比較します。
説明されている方法に従って設定されると、Spark アプリケーションは、以下の仕様の Amazon EMR クラスターで、メモリ問題を生じることなく 10 TB のデータを正常に処理できます。
- 1 個の r5.12xlarge マスターノード
- 19 個の r5.12xlarge コアノード
- 合計 8 TB の RAM
- 合計 960 個の仮想 CPU
- 170 個のエグゼキュータインスタンス
- 5 個の仮想 CPU/エグゼキュータ
- 37 GB のメモリ/エグゼキュータ
- 並列性は 1,700 と同等
参照のため、以下の Ganglia グラフをご覧ください。


同じクラスターで同じ Spark アプリケーションをデフォルト設定で実行すると、そのアプリケーションは物理メモリ不足エラーで失敗します。デフォルト設定 (2 個のエグゼキュータインスタンス、es, 並列性 2、1 個の vCPU/エグゼキュータ、8 GB のメモリ/エグゼキュータ) は 10 TB のデータを処理するには不十分だからです。クラスターには 7.8 TB のメモリがありましたが、デフォルト設定は 16 GB のメモリしか使用しないようにアプリケーションを制限したため、以下のメモリ不足エラーが発生しました。
また、大規模のデータセットでは、デフォルトのガベージコレクターがタスクを並列的に実行するために十分な効率性でメモリをクリアしないため、頻繁な失敗の原因になります。以下のグラフは、デフォルトのガベージコレクターと G1GC ガベージコレクターを使ったときの RAM の使用率とガベージコレクションを比較するために役立ちます。G1GC では、使用された RAM が 5 TB 未満に維持されています (グラフの青色の部分を見てください)。

デフォルトのガベージコレクター (CMS) では、使用された RAM が 5 TB を超えています。これは、多数のタスクを連続して実行するときにおける Spark ジョブの失敗につながります。

例: 設定付きの EMR インスタンステンプレート
Spark と YARN の設定パラメータを設定するには、異なる方法があります。その 1 つは、EMR クラスターの作成時にこれらを渡す方法です。
これを行うには、Amazon EMR コンソールの [ソフトウェア設定の編集] セクションで、適切に更新された設定テンプレートを入力できます ([設定の入力])。または、S3 から設定を渡すこともできます ([S3 からの JSON のロード])。

以下は、サンプル値を使った設定テンプレートです。Spark アプリケーションを成功させるには、少なくとも以下のパラメータを計算して設定してください。
結論
このブログ記事では、考えられるメモリ不足エラー、それらの原因、および Amazon EMR で Spark アプリケーションをサブミットするときにこれらのエラーが発生することを防ぐためのベストプラクティスのリストについて詳しく説明しました。
私の同僚たちと私は、綿密な調査を行い、さまざまな Spark 設定プロパティを理解して、複数の Spark アプリケーションをテストしてから、これらのベストプラクティスを策定しました。これらのベストプラクティスはほとんどのメモリ不足シナリオに当てはまりますが、まれにこれらが当てはまらないシナリオもあるかもしれません。しかし、私たちはこのブログ記事が、パラメータを調整して Spark アプリケーションをうまく実行するために必要な詳細のすべてを提供すると確信しています。
著者について
 Karunanithi Shanmugam は AWS Tech and Finance のデータエンジニアです。
Karunanithi Shanmugam は AWS Tech and Finance のデータエンジニアです。