Amazon Web Services ブログ
AWS Batchを用いた大規模ベイズ機械学習モデルトレーニングソリューション
この記事はAmpersandのシニア機械学習エンジニアJeffrey Enos, データサイエンス担当シニアディレクターDaniel Gerlanc、データサイエンスリードBrandon Willardによる寄稿、Bayesian ML Models at Scale with AWS Batchを翻訳したものです。
Ampersandはデータ駆動型のテレビ広告テクノロジー企業で、4200万世帯、すべてのメディア市場、165以上のネットワークとアプリ、すべてのデイパーツ(放送日区分)に関する集約されたテレビ視聴者のインプレッションに関するインサイトとプランニングを提供しています。Ampersandは、プライバシーを重視した形で視聴者プロファイルを構築します。これは広告主が、彼らがターゲットとする顧客に対して、どのネットワークを用いてどの時間帯で広告を提示すれば、広告が見られる可能性が高いか理解し、ターゲット顧客に対してリーチすることを可能とする統計モデルです。
Ampersandデータサイエンスチームの見積もりによると、この統計モデルの構築には最大60万CPU時間が必要であり、クラウドの超並列大規模アーキテクチャを用いない限り実現不可能でした。いくつかのソリューションを試した後、AmpersandはAWS Batchに着目しました。AWS Batchは高度にスケーラブルなバッチ処理基盤であり、機械学習処理のスケジューラやオーケストレーターを備えています。ユーザーはAWS Batchを用いることにより大量の計算リソースを利用でき、CPU、メモリ、GPUリソースを最適に配置して、コンテナ化されたジョブを実行することができます。AWS BatchのスケーラビリティによりAmpersandはAmazon ECスポットインスタンスを用いてコストを最適化しながら、計算時間を500分の1以下に圧縮することができました。
この投稿では、まずAmpersandがどのようにテレビ視聴者インプレッション(以下インプレッション)モデルを大規模にAWS上で構築したかについて概説します。その後、採用されたアーキテクチャを紹介し、最後にAWS Batch上でワークロードを効率的に実行するためにAmpersandが行った最適化について議論します。
大規模なTVインプレッションの数理モデル化
Ampersandデータサイエンスチームは、インプレッションを予測する統計モデルを構築しています。これらのモデルから得られた知見をもとに、Ampersandは成功する見込みの高い広告キャンペーンを顧客に対して提供します。
Ampersandデータサイエンスチームは、ベイズ法を用いることで異なる組み合わせ、地域、人口統計、ケーブルテレビネットワーク(CNN, ESPN, AMCなど)の様々な組み合わせに対して将来のインプレッションを時系列で予測します。1つの地域(Region)、人口統計(Demographic)、ネットワーク(Network)の組み合わせはDNRと呼ばれます。
それぞれのDNRに対して、各時刻の視聴者数を予測する単一のモデルが構築されます。 各モデルは、インプレッションの状態を明示的に特徴づける完全ベイジアン隠れマルコフモデル(HMM)です。インプレッションの最も基本的な状態は「視聴」と「非視聴」です。各状態にはパラメーターが設定されており、これによって任意の時刻における状態遷移を予測することができます。 これらパラメーターはマルコフ連鎖モンテカルロ法(MCMC)によって推定されます。推定されたモデルからサンプルを抽出することにより、インプレッションの予測を行い、かつ各状態の予測の不確実性がどのように伝搬するかを把握することができます。より具体的には、それぞれのモデルから得られたサンプルを組み合わせて、より上位の集計カテゴリに対する予測を行います。HMMはこちらのPython notebookからお試しいただけます。
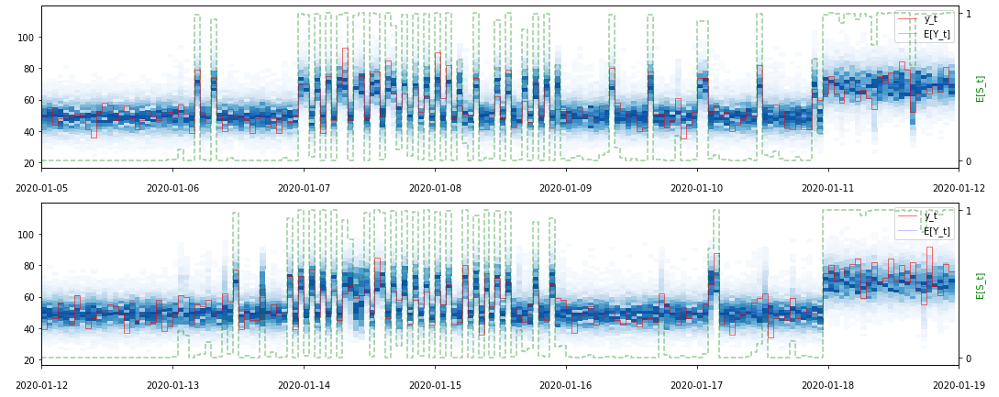
図1: 上のプロットは、観測値の集合(赤)にフィットしたHMMの事後予測サンプル(青)と、状態サンプルの標本平均(緑)を示します。観測値とサンプルされた予測値の値は左側のY軸に、サンプルされた状態値(0ないし1)の平均は右側のY軸に示されます。このプロットでは、2週間分の結果を1週間分ずつ上下に分けて表示しています。(図引用元)
AWS上でのAmpersandのML計算アーキテクチャ
Ampersandデータサイエンスチームのデータアーキテクチャは、集約されたインプレッションに関する情報を取り込み、それを変換し、大規模な統計モデルのパラメータを推定するために複数のAWSサービスを利用しています。
まず、Ampersandデータサイエンスチームはプロバイダーの入力データをAmazon Redshiftのデータウェアハウスに取り込み、前処理を行います。次に、データをS3上のバケットにParquet形式で保存し、下流のプロセスが1回のモデルのパラメータ推定のために最小限のデータをロードできるようにデータをパーティショニングします。モデルの更新が必要な場合、スポットインスタンスを使用するように設定されたAWS Batch Compute Environmentを用いてパラメータの再推定処理を開始します。モデルのパラメータ推定が完了すると、予測サンプルをEKS上に配置されたClickHouseデータベースクラスタにロードします。同じくEKS上に配置されたFastAPIベースのアプリケーションが、インプレッションの推定結果を集計し、Ampersandの営業チームに提供します。

図2: Ampersandの計算アーキテクチャ図
新しいインプレッションの情報が利用可能になると、Ampersandデータサイエンスチームはすべてのモデルのパラメータを再推定します。各モデルは推計で、1時間ごとに最大1万点のデータを使用します。再推定全体では、毎回に20万個のモデルのパラメータが必要となります。AmpersandのHMMのサイズと必要なサンプル数のため、各モデルのパラメータ推定には1~3物理CPU時間がかかります。つまり、20万個のモデルを再計算するためには、観測値の数に応じて、合計20万から60万の物理CPU時間が必要になります。
仮に、1台のc5.24xlargeのAmazon EC2インスタンスを使用したとすると、そのインスタンスの物理コアをすべて使って、すべてのモデルを再計算するのに170~520日かかることになります。AWS Batchを用いた5万vCPUまで使用可能なCompute EnvironmentによってAmpersandは1日以内にすべてのモデルのパラメーターを推定することができるようになりました。
異なる計算バックエンドオプションの検討
Ampersandデータサイエンスチームは、スタックを構築する際に以下のような要件を持っていました。
- 計算機資源を自動的にゼロ台から複数台へスケールアウト、もしくはゼロ台へスケールインさせる
- コスト削減のため、全てスポットインスタンスで実行する
- 最小限のカスタムコードでスケジューリングとリソース管理を実現する
- ジョブ間の分離を実現する
チームは様々なフレームワークやツールを評価しましたが、要件を満たし、さらに他の利点もあることから、AWS Batchに決定しました。主な利点は
- マネージドサービスであるため、計算クラスタとジョブスケジューラの管理を簡素化できる
- 配列ジョブの使用により、問題を自明な並列計算問題に落とし込むことができる
- SPOT_CAPACITY_OPTIMIZED配分戦略を使用してスポットインスタンスとネイティブに統合できる
などです。
アーキテクチャとワークフローの最適化
上記のアーキテクチャを使用する中で、Ampersandデータサイエンスチームはインスタンスの選択を洗練させ、データパイプラインを最適化することによって、さらなる最適化を実現することを目指しました。
この最適化についての議論の前に、AWS Batchの主要な概念をおさらいしておきましょう。サービスのキーコンポーネントは、Job QueueとCompute Environmentです。Job Queueは、ジョブ投入時にジョブを配置する場所であり、ジョブが完了するまで滞在する場所です。Compute Environmentは、その構成によって1つまたは複数の種類とサイズのインスタンスをサポートできる計算クラスタと見なすことができます。1つのJob Queueを複数のCompute Environmentにアタッチすることが可能です。AWS Batchは定期的にキューの状態を見て、実行可能なジョブを実行するために所定のCompute Environmentをスケールアップする必要があるかどうか判断します。
Ampersandデータサイエンスチームはデプロイを最適化するために、AWS Samplesリポジトリにあるオープンソースの監視ソリューションを使用して、Compute Environmentのスケーラビリティとインスタンスの選択を監視しました。 その結果、スポットインスタンスとして小さいインスタンスサイズのものばかりが選択されており、AWS Batchとして必要なだけのキャパシティを十分に確保できない場合があったことが分かりました。 この問題を解決するために、第4世代と第5世代のC/M/Rファミリーのインスタンス(c5.4xlarge以上)を選択的に用いるよう変更を加えました。これにより、AWS Batchはより大きなスポットインスタンスのみを使用することになり、スケーラブルに大容量を獲得することが可能となりました。
Ampersandデータサイエンスチームが実施したもう1つの最適化は、データパイプラインに関するものです。先に共有したように、集約されたインプレッションに関する情報は、前処理のためにAmazon Redshiftに取り込まれます。Ampersandデータサイエンスチームはコンピュートバックエンドを用いた実験の際、ワークロードの高い並行性と使用量の急激な増加により、同社のRedshiftクラスタに大きな負荷がかかっていることに気が付きました。このボトルネックを克服するため、RedshiftからAmazon S3にデータをParquetフォーマットとしてエクスポートし、データパーティションをアプリケーションの取り込み方法に合わせて変更しました。
結果と今後の展望
Ampersand Data Scienceチームは、AWS Batchで効率的に実行できるスケーラブルなアーキテクチャを構築しました。また、ワークロード全体をAmazon EC2スポットインスタンスで実行することで、大規模なコスト削減を実現することができました。過去の請求書から、サービス使用の費用が掛からないAWS Batch, そしてオンデマンドインスタンスではなくスポットインスタンスを活用することで、78%もの費用節減に成功したと試算しています。今後は、Gravitonベースのインスタンスでさらにコスト削減を図り、現状より50%、コスト節減を目指す方針です。
本ブログの内容や意見は、第三者である筆者のものであり、AWSは本ブログの内容や正確さについて責任を負うものではありません。
翻訳は Solutions Architect の渡辺が担当しました。原文はこちらです。